

jdunham
-
Posts
625 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by jdunham
-
-
QUOTE (benjaminhysell @ Feb 26 2009, 01:55 PM)
Thanks! I'm glad it's getting used.
QUOTE (benjaminhysell @ Feb 26 2009, 01:55 PM)
... it runs the false conditional disable case runs on the first run through. If I run the unit test again this time the conditional disable will run the true case.It appears that what ever the conditional disable symbol that is set to before I start a run is the one that is actually executed, however if you look at the block diagram this isn't the case. i.e. the conditional disable I want to run is actually 'enabled' yet doesn't run.Well I think that makes sense. These symbols affect how your VI is compiled, but if your VI is part of a running hierarchy, it can't be recompiled. Once your VIs stop, the new symbol is imposed, and then you run again and see the results you expected. Basically you are going to have to impose all of your symbols before any execution of your unit tests, which may require some dynamic VI invocations.
-
-
QUOTE (crelf @ Feb 26 2009, 11:50 AM)
I was thinking "I'll post a reply agreeing with that", but by the time my browser came up I think I'd changed my mind
Well I agree with you! :thumbup: My examples were just off the top of my head, since I have (*gasp*) other work to do.
The 'overwrite/append' example is straight from the old file I/O VIs and I have to say, the the new version that always overwrites is a big step backward (getting off topic...)
I would agree that if an input requires a lot of explanatory labeling, there's probably a bad design somewhere around there.
What this thread is really about is that words that add no extra value should not be on your VIs, and I get peeved by style guides that apply those kind of rules like "Always put the default value in parens in the label" or "always make inputs required rather than recommended" or always use "error in/error out" [even when it's totally unnecessary].
-
QUOTE (crelf @ Feb 26 2009, 10:26 AM)
That's a really good point. I only use the default value in parentheses if the default value of the control isn't the default value of the datatype.Well it's also fine if the default needs clarification or has a special meaning like
filter coefficient(0:no filtering)
overwrite?(F:Append to file)
While I'm on my soapbox, making inputs "required" is a really good thing, and for the most part, required inputs don't need to have their defaults mentioned at all. But that has the same exception, where you may need to clarify a special interpretation of the default value for that data type.
-
QUOTE (PJM_labview @ Feb 26 2009, 09:01 AM)
I actually do not mind the "(no error)", but I do mind the size of the error cluster. I change them back to the size they use to be in older LV version (significantly smaller) using the same procedure Jason described.It's not such a big deal on the front panel, but I believe its removal makes the Context Help window (Ctrl-H) look a lot better. I'm fine with default values in parentheses when they are useful, but when they don't add any information, then they shouldn't be there. Maybe the original idea was that first time users might think that wiring anything into that input would signify an error, but it's more likely that "it seemed like a good idea at the time".
-
QUOTE (gleichman @ Feb 25 2009, 01:56 PM)
I would like to see the default label "(no error)" part of the error in go away.It takes about a minute to go into C:\Program Files\National Instruments\LabVIEW 8.6\vi.lib\errclust.llb and remove the annoying "(no error)" part of the label (don't forget to fix both the classic and the 3D version). That's just about the second thing I do to a fresh copy of LabVIEW after turning off 'Lock Automatic Tool Selection', 'Automatic Wire Routing', and AutoGrow.
-
QUOTE (gleichman @ Feb 25 2009, 01:56 PM)
I would like to see the default label "(no error)" part of the error in go away.It takes about a minute to go into C:\Program Files\National Instruments\LabVIEW 8.6\vi.lib\errclust.llb and remove the annoying "(no error)" part of the label (don't forget to fix both the classic and the 3D version). That's just about the second thing I do to a fresh copy of LabVIEW after turning off 'Lock Automatic Tool Selection', 'Automatic Wire Routing', and AutoGrow.
-
QUOTE (mesmith @ Feb 23 2009, 11:46 AM)
I'm not sure what your actual application is but if I had a C++ app already written and I wanted to use the NI display widgets (graphs, buttons, etc like in LabVIEW) I would use Measurement Studio.I would agree with this. I think LabVIEW is an awesome system, but it's not that great at creating GUIs. I know that sounds like heresy, but if the LabVIEW-supplied graphs and controls don't do what one needs right out of the box, then it can get difficult in a hurry. For example if you want to add right-click menu items to your graph, or change the plot colors based on the input data values. The OP apparently sounds like he hasn't looked at LV before today, so I don't see the sense in learning LabVIEW just to use its built-in graph when he or she could get very similar results from Measurement Studio using his native programming environment.
arif215, what do you want to do that you can't do in Excel, gnuplot or Matlab? If you answer that, we could be more helpful in telling you whether it's worth the trouble to buy and learn LabVIEW?
-
QUOTE (LVBeginner @ Feb 23 2009, 09:03 AM)
I have a program that asks the user for input and then the input is converted to xml format. I was wondering, because I have to send the saved xml file to a specific web address, does the other computer need to have LabVIEW on it or not. Basically the program takes information about an assembly line, for example parts produced, hits on tools and others, right now that data is entered in by hand and processed by the company that handels our servers. But none the less all I wanted to know is if the other computer is required to have LabVIEW or not.Well no and yes.
XML is just text, so there's nothing to stop you from writing a program in any language and running it on the machine that is receiving the data.
However if your using the LabVIEW schema, which was written for NI's convenience more than for yours, then writing that program gets a lot easier if you are using LabVIEW on both ends.
-
QUOTE (Ic3Knight @ Feb 23 2009, 01:24 AM)
I tried again this morning with a real DAQ device (NI USB6211) and an external signal generator, and saw the same results as above. I then tried again, adding a semaphore to the code to protect the "Read property node and Read.VI" combinations in each loop. This worked a treat...I guess, thinking about it, it makes sense. All I'm doing in my code is sending a DAQmx task NAME reference to each loop. There is still only one DAQ task... Its also quite possible, with the two parallel loops, that the top loop's read property node may be called after the bottom loop's property node but before the bottom loops Read VI, hence changing the properties for the bottom loop read... (which would explain what I was seeing in my graphs).
Using semaphores to protect each "property - read" combination seems to work fine and I presume won't affect performance significantly (unless, I suppose, the bottom loop is doing a particularly long read or having to wait for new samples to be acquired into the buffer...)
Great. I think your analysis is spot-on. Note that you can use a common subvi in place of semaphores, but they should both be fast
-
The old NI File functions used to append data by default, and now the new ones overwrite by default. NI are you listening? Its sucks! (Sorry to be so grumpy)
-
QUOTE (Ic3Knight @ Feb 22 2009, 03:40 AM)
QUOTE (Ic3Knight @ Feb 22 2009, 03:40 AM)
This works to an extent, however in the version I posted, the lower tends to produce a reasonable sinusoid with occasional "glitches", but the top loop produces a sinusoid but with lots of "glitches" which, if observed over a long enough period of time, show that its actually reading back the wrong data:...The graphs are very interesting, and obviously show that something is wrong. What I can tell you is that I have an application at 1kHz that has been using this technique, with one thread logging to disk for up to a few hours during a run, and another thread doing event-based real-time analysis on the same channel, and it has never shown any kind of data corruption.
-
QUOTE (Ic3Knight @ Feb 21 2009, 08:10 AM)
What I wanted was one DAQ task - in my example, a simple AI read, continuous sampling, but I wanted to read the data back in two parallel loops... I set up the attached VI as a test... what should happen is the top loop simply reads back the most recent sample available and places it in a shift register (building an array - not the most efficient method I know). The second loop should read back all of the data (in blocks of 20), but I've delayed the loop so the read will ulitmately fall behind the buffer.In this case, what you should see is the two waveform graphs "oscillating at different rates"... but there seesm to be some kind of "cross talk" going on... like the two "reads" and property nodes are interfering with each other... Is what I want to do actually possible? Or did I miss understand what was said above:
How can you tell there is cross-talk? Your top loop should be producing an essentially random graph. It's just taking the last sample periodically, but with software timing, so there's no strict periodicity to your reading. how could you tell if it's not actually reading the last sample? Without seeing the data, it's hard to know whether it's DAQmx or just your program which produces the aberrant results.
The lower loop should be reading continuous data, so if it looks wrong, that's a stronger indicator that you are having problems.
It's certainly possible, and maybe even likely, that the property node just affects the task and when you call the DAQmx read VI, it's going to use the effect of the last property node that executed, regardless of which loop that was in.
The easiest way to check that is to put the property node and the DAQmx Read VI into a new subvi, and it has to be the same subvi and not reentrant, and then the subvi calls will block each other and you can guarantee that the property node and DAQmx Read are called in the order you are expecting. You could also use a semaphore to do the locking, but a subvi is usually easier. After that, if the output still doesn't look right to you, it's probably not DAQmx's fault.
BTW you've made me wonder if the last program I wrote using this kind of trick needs to have some semaphores added!!
-
I still think there should be an option to show the class data rather than the object icon, at the very least on private VIs, and maybe on all VIs which are members of the class. The ability to test VIs by setting the front panel values is so useful in LabVIEW and its so glaringly absent from the LVOOP world.
-
QUOTE (dblk22vball @ Feb 19 2009, 08:44 AM)
i had the array/cluster idea too, but wasnt sure if there was another way.If you use an array of clusters, hide the index element (which hardly any non-labview programmer can understand) and show the vertical scrollbar. It's still confusing for people to use the concept of right-clicking on the border of cluster to delete it.
If it were me, I would implement a listbox with 1 element selected, and then you could edit the IP address of the selected listbox item in a separate control, and you could have a delete button, and you can show the checkmark symbols to show which ones are enabled. You have to code up all the handling yourself, but it should only take a half day or so.
-
-
I hate to open up yet another discussion of licenses, but can we add the MIT license to the CR submission form. It's pretty similar to BSD from what I read, but I use that license for all my stuff and I'd like to submit a few things under it to the LAVA CR.
-
- Popular Post
- Popular Post
QUOTE (turbophil @ Feb 18 2009, 10:06 AM)
I know I could use conditional disable structures to select the calling method, but that would require me to change the conditional disable symbol(s) each time I want to build the executable or run in development mode. Is there any way to set a conditional disable symbol based on the application type, or set the symbol from within the build specification? Or is there another (better) way to do it besides conditional disable?I think you are on the right track; using CD is the way to go. Presumably you know you can have some symbols which are for the whole project, and other symbols that are per-target (it depends where you right-click). You may be able to do what you need by putting the symbol only in the RT target, so that whenever you run on the local machine, it will use a different conditional symbol case.
If you need more complex behavior than that, I wrote a VI to change the symbols programmatically, which may help you switch back and forth. I was going to put this in the LAVA code repository, but I can't deal with the bureaucracy today, so here it is, attached (labview 8.6.1). Hopefully later I can submit it the right way.
-
 4
4
-
QUOTE (torekp @ Feb 16 2009, 04:48 AM)
Well that works, but the error exception part of it should just be a separate VI. I find that I don't want to clear errors in the same place as I want to tell the user about errors. And then the Clear Errors.vi clears all errors which I feel is dangerous because the code will silently suppress any errors, not just the ones you anticipate. It's all fixable with your own code, I just think NI should improve the API so everyone uses the same stuff instead of rolling their own.
QUOTE (torekp @ Feb 17 2009, 09:59 AM)
OK not ALL file functions, just half. The reading half. Read spreadsheet file, read tdms file, read binary file, etc. (I speak loosely - some of these include the opening of the file, some require a separate opening action, but you get the point.)Well a lot of the new functions already have the functionality you crave (they include the file name in the error message).
-
QUOTE (Ic3Knight @ Feb 16 2009, 02:35 PM)
QUOTE (Ic3Knight @ Feb 16 2009, 02:35 PM)
One more question (sorry!!), if I set up a continuous acquisition task, like the one in the picture I posted last, but never read back any data, will DAQmx throw up an error? Or will it only give the error if I try to read back samples its over-written in the circular buffer? For example, could I set up the continuous task, and then wait an hour (or whatever) and then use the "DAQmx read" property node to get the most recent sample? (I'm not sure why I'd want to do this, but it helps me build a better picture of how it all works!)Yes, absolutely. The circular buffer can acquire just about forever, and it never cares whether you read the data. But as you are finding, if you wait a long time and read with the default read function, you'll get data not found. A corollary to that, never adequately explained by NI, is that just because your read function throws an error, doesn't mean the acquisition is harmed, and you are perfectly free to try a different read from a different position.
You could easily have a system which is acquiring very fast, but you are only interested in the data when some other external event happens, like your motion control system gets everything aligned. Then you could record several seconds on either side of the event since your continuous acquisition was buffering the whole time. There is also a 'pretrigger' mode which does pretty much the same thing, but you would have to re-arm the acquisition to do it more than once. Once you have mastery over the buffer you can do anything you want.
QUOTE (Ic3Knight @ Feb 16 2009, 02:35 PM)
Thanks again for the help! I'm glad I found these forums!Glad to help. I find it frustrating that DAQmx is so powerful, and there are a great many examples, but some of the coolest stuff you can do is entirely missing from any examples.
-
QUOTE (Daklu @ Feb 13 2009, 01:16 PM)
I don't believe this is an intractable problem. http://joelonsoftware.com/articles/fog0000000356.html' rel='nofollow' target="_blank">This article from joelonsoftware is somewhat helpful.
QUOTE (Daklu)
As an aside, I still haven't figured out how to address my problem.I thought about your issue some, but I think there's not enough information for anyone to give you a sensible reply. Not that you didn't give it a good try, but I think if it were easy, you would have solved it on your own, and no one else can know what the really hard parts are.
Like when you said "The current architecture is also limited in that multiple connections to a device are not allowed. I could not control the panel via I2C and simultaneously monitor the microwave's serial output at the same time. " It sounds like your architecture is at fault, so then you should fix it, but it's not clear whether you meant that. Is the problem that your class's private data doesn't have the right information, or do you need to add some kind of locking mechanism to your I/O methods?
OK, you also wrote "What do I do when two independent Interfaces are competing for the same hardware, such as if the IDIO Device and II2C Device both use the same Aardvark? One could change the hardware settings and put the device in a state the other doesn't expect. I think the solution lay somewhere in the Aardvark Class implementation, but I haven't put my finger on it yet. (Maybe a "Lock Settings" property?)". It seems like you should use a mutex, which in LabVIEW is called a semaphore (near the queue palette, and at some point recently they were rewritten to use LV queues).
Maybe you should try to hire a local LabVIEW consultant (obviously you'd need a really good one) just to bounce your ideas off of for a day or so. Sometimes this can be hard to explain to your boss, but it's worth a try.
Good luck,
Jason
-
QUOTE (Ton @ Feb 15 2009, 12:28 PM)
The data is stored in the on-board buffer, or in the systems ram (I am not sure). However if you wait too lang after a read you will get a buffer over-flow error.Mostly in the system's RAM, or at least that's all you have to worry about. So DAQmx has a private circular buffer system which you don't have to worry much about. Except that the buffer looks linear to you (the offset from the start mark increases infinitely and is a U64 (though you can only access it with an I32 which is just a screw-up on their part--backwards compatibility etc. etc.). But under the hood, it's a circular buffer, so if you try to access data which is too old, you will get error -10846 (which is pretty familiar to people doing a lot of DAQ). Actually that was the NI-DAQ legacy error code and I don't remember whether DAQmx uses different codes.
So here's the part you have to care about: The circular buffer size determines how far back into the past you can retrieve data. DAQmx will probably take your sample rate and give you a reasonably-sized buffer (not sure exactly how big, since I haven't mucked with it for a while). If it is not giving you enough, you can ask for more with
C:\Program Files\National Instruments\LabVIEW 8.6\vi.lib\DAQmx\configure\buffer.llb\DAQmx Configure Input Buffer.vi
I actually thought it was via a DAQmx property node, but either senility is setting in or else they changed DAQmx.
Actually I checked again, and inside that VI is simply the property node. The property node is useful because you can change it to read-mode and find out what the current buffer size is.
-
QUOTE (Ic3Knight @ Feb 14 2009, 03:22 AM)
I'm a little confused, could you post a quick example of what you mean about reading data more than once? Do you mean something like this: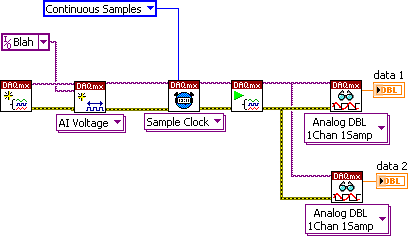
Or do you mean create two separate daq tasks for the same channel?
No it's just one task, but you need to work with the DAQmx property nodes to control where each thread is reading from. It's more complex than your sample, but nothing crazy hard. Check out this old post about a similar topic.
-
QUOTE (jaehov @ Feb 14 2009, 11:02 AM)
Essentially I want the string "1234567899" to be converted to the Integer (1234567899)I know in LV 8 this would be a breeze with U64. But how can I perform get same result in LV 7.1 ?
Umm, that number fits fine in an I32. Assuming you are really having a problem, why not use DBLs? Just because it's not limited to integers doesn't mean its a bad choice for them if U32 is too small.
 Me too - I've spent far too much time on non-billable stuff today, so can everyone stop posting such interesting and thought-provoking stuff?
Me too - I've spent far too much time on non-billable stuff today, so can everyone stop posting such interesting and thought-provoking stuff? 
New wire type, the Null wire
in LabVIEW Feature Suggestions
Posted
QUOTE (Aristos Queue @ Feb 26 2009, 07:39 PM)
It would be cool if the sequence structure could be set to 'auto-shrink' around various VIs or globals to which you just want to add an order dependency (or for whatever reason).
Jason