drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-

sqlite SQLite Library 1.6 beta: Attributes lookup table
drjdpowell replied to drjdpowell's topic in Code In-Development
The JSON SQL functions should be working in this beta (I think it includes the 3.9.0 dll with those functions). I’ve only played around with them a little, but they do work. -
Oh, I’m not even talking about a framework. Just a hook that allows someone to connect such a thing to the JSON-Variant tools without modifying JSON.lvlib. Then CharlesB could provide his object serializer as an addon library.
-
I suggest you just decimate your data after the filter.
- 3 replies
-
- 2
-

-
- peak detection
- fir
- (and 1 more)
-
Note: I’m thinking of putting in an abstract parent class with “To JSON†and “From JSON†methods, but I’m not going to specify how exactly objects will be serialized. So Charles can override with his implementation (without modifying JSON.lvlib) without restricting others from creating classes than can be generated from different JSON schema. I could imagine use cases where one is generating objects from JSON that is created by a non-LabVIEW program that one cannot modify, for example. Or one just wants a different format; here’s a list of objects from one of my projects: [ ["SwitchRouteGroup",{"Connect":"COMMS1"}], ["DI Test",{"IO":"IO_ID_COMMS_1_PRESENT","ON=0":false,"Value":true}], ["Set DO",{"IO":"IO_ID_COMMS_1_EN","ON=0":true,"Readable?":true,"Value":false}], ["Wait Step",{"ms":2000}], ["DMM Read Voltage",{"High":2,"Low":-2}], ["Set DO",{"IO":"IO_ID_COMMS_1_EN","ON=0":true,"Readable?":true,"Value":true}], ["Wait Step",{"ms":500}], ["DMM Read Voltage",{"High":13,"Low":11}], ["AI Test",{"High":3600,"IO":"IO_ID_COMMS_1_V_SENSE","Low":3400}], ["SwitchRouteGroup",{"Disconnect":"COMMS1"}] ]
-
I could easily make a “JSON serializable†class with abstract “Data to JSON†and “JSON to Data†methods, and have the JSON-Variant tools use them. Then you could inherit off this class and not have to modify JSON.lvlib.
-
I would Google “CRC16 LabVIEW†first, if I were you, and see if you can find it already done for you.
-
Problems show up in the unflattening part. Flattening, the part you are trying, is strait forward, because you are going from strongly-typed LabVIEW to weakly-typed JSON. The other way is harder. You don’t need to make your class a child of JSON Object; just have your class have “To JSON†and “From JSONâ€. You won’t be able to use these objects in the JSON-Variant tools, but you will be able to handle things with the other methods. This involves more coding, but is faster. And it allows one to get away from the monster config cluster and towards a distributed config, where different code modules supply different parts of the config.
-
The current JSON-Variant tools will store objects as flattened strings. Not human-readable, but flattened objects have a mutation history so you can freely rearrange things inside the class private data (but not on any condition re-namespace the class). I find that mixed-mode quite useful and easy. Alternately, to serialize objects as JSON I usually just have methods in the class to convert to/from JSON and I use them as I build up the JSON explicitly (i.e. without using the shortcut of the JSON-Variant tools on a cluster). There is a possibility that one could make one’s LVOOP classes children of “JSON Valueâ€, and then override “flatten†and “unflattenâ€. Then your objects would serialize to JSON even inside a cluster using the JSON-Variant tools (those tools recognize “JSON Value†objects and flatten/unflatten them). But there is a technical issue that I have to look into to make that work. [Never mind, this won’t work.] Adding or removing is fine, but don’t rename or move things, unless you want to have a “schema version†attribute and mutation code than coverts from older schema.
-
Ah, I see. We need something like Error 402864, SQLITE_BUSY(5), occurred at redacted.lvlib:redacted.vi on "INSERT OR IGNORE INTO redacted ( redacted, redacted, redacted) VALUES (?, ?, ?);" Possible reason(s): database is locked. See https://www.sqlite.org/rescode.html#busy. Edit> can’t do the above, but how about: Error 402864 occurred at redacted.lvlib:redacted.vi on "INSERT OR IGNORE INTO redacted ( redacted, redacted, redacted) VALUES (?, ?, ?);" Possible reason(s): SQLITE_BUSY(5) database is locked (see https://www.sqlite.org/rescode.html)
-
I add 402859 to the SQLite error code (apologies for that number, but those are the range of codes assigned to me by NI). I’m currently calling sqlite2_errmsg() to get an error description from the SQLite dll itself. And the message should have also contained either the database file, or SQL statement on which the error occurred. Was this information not in the error?
-
If you look in the latest beta version you’ll find it (though it’s not in the palettes, it is in the Connection class). PS> Some notes: — one can also use the last_row_ID() SQL function — Be careful that you aren’t executing multiple INSERT statements in parallel on the same Connection, as you might mixup the rowIDs. — note the existence of WITHOUT RowID tables, which avoids the need to determine the auto assigned rowID.
-
Here is a beta version with changes aimed at performance, particularly for large arrays of data. I managed to eliminate an O(N^2) performance issue with parsing large JSON strings. I also improved the Variant tools’ speed with one- and two-dimensional arrays. See the new example “Example of an Array of XY arrays.viâ€. lava_lib_json_api-1.4.1.33.vip Please give this a test and let me know of any issues before I place it in the CR. I’m also thinking of submitting to the LabVIEW Tools Network. — James
-
Sorry, forgot to push the changes. It’s there now.
-
Here is a Beta version with a new “Treatment of Infinity/NaN†terminal on the JSON write functions. Three options: -- Default JSON: write all as nulls. -- Extended: use JSON strings for Infinities ("Infinity", "-Infinity"); NaN still null. -- LabVIEW extentions (compatable with the LabVIEW JSON primatives): Infinity, -Infinity, NaN (not in quotes) Note that the LabVIEW extentions are not valid JSON. The Extended option IS valid JSON, but not all JSON parsers will process strings as numeric values. lava_lib_json_api-1.4.0.28.vip
-
I mean alternate treatments of Inf, -Inf, and NaN. I can think of alternatives that are arguably better than the choice made in the LabVIEW primitive. Personally, I would choose NaN==Null, Inf/-Inf==“Infinityâ€/“-Infinity†(strings), as this would be valid JSON. The LAVA JSON package should already be able to read this (I think). Regardless, other JSON packages that we may want to interact with may have made other choices.
-
It looks easy enough to add a Boolean to enable use of NaN, Infinity, -Infinity. It will have to be default False, though, as the default should be to meet the JSON standard. I would like to see this myself, as I use JSON mostly LabVIEW-to-LabVIEW. Maybe this should be an enum instead of a boolean, in case we want an alternate extension in the future? Not sure we can get default values of clusters in arrays (also, which array element should be used? First? Same Index?). As a work around, you can just index over the JSON Array elements in a FOR loop and convert each to a Cluster individually. Then you can either provide the same cluster as default, or have an array of different default clusters.
-
sqlite SQLite Library 1.6 beta: Attributes lookup table
drjdpowell replied to drjdpowell's topic in Code In-Development
No, but I’ll add the same NI off-pallet VIs used elsewhere in the library to convert to/from Mac paths: “Path to Command Line String†and “Command Line String to Pathâ€. Thanks. Do you use LabVIEW on the Mac? I haven’t in a long while and I could do with someone testing it. — James -
A beta version of 1.6 is posted here. If you ignore the newest features, you could use this in production code; it has the latest SQLite 3.9.2, including the interesting JSON1 extension.
-
sqlite SQLite Library 1.6 beta: Attributes lookup table
drjdpowell posted a topic in Code In-Development
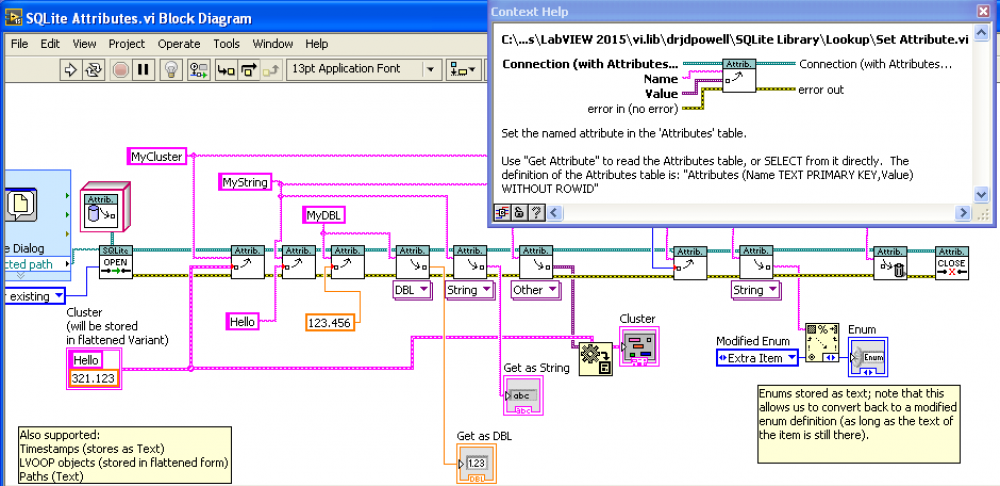
Attached is a beta version of the latest 1.6 version of SQLite Library, for anyone who like to give feedback. A major addition (not yet well tested) is “Attributesâ€, modeled on Variant Attributes or Waveform Attributes, but stored in any SQLite db file. The idea is to make it easy to store simple named parameters without much effort. See the example “SQLite Attributes.viâ€. A more minor upgrade is making “Execute SQL†polymorphic, so as to return data in a number of forms in addition to a 2D-array of strings. See the upgraded example “SQLite Example 1 — Create Table.vi†which uses the new polymorphic VI, including showing how to return results as a Cluster. For Attributes, I had to make some choices in how to store the various LabVIEW types in SQLite’s limited number of types. The format I decided on is: 1) all simple types that already have a defined mapping (i.e. a “Bind†property node) are stored as defined (so strings and paths are Text, DBLs and Singles are Float, integers (except U64) are Integers. 2) Timestamps are ISO-8601 Text (the most standardized format of the four possibilities) 3) Enums are stored as the item text as Text, rather than the integer value. This seems the most robust against changes in the enum definition. 4) LVOOP objects are stored flattened in a Blob. 5) any other LV type is, contained in a Variant, flattened and stored in a Blob. Using a flattened Variant means we store the type information and LabVIEW version. drjdpowell_lib_sqlite_labview-1.6.0.51.vip LabVIEW 2011-2015 The Attribute stuff grew out of a project where SQLite files held the data, one for each “Runâ€, and the Runs had lots of small bits of information that needed to be stored in addition to the bulk of the data. When and where the measurement was taken, what the equipment setup was, who the Operator was, etc. I purpose-made a name-value look-up table for this, but realized that such a table could be made into reusable “attributesâ€.
-
Good eye. It’s because I had to read in the INI config file before writing this JSON, and so inherited the INI’s precision. Here is a redo where I have manually typed in 123456789 as extra digits before JSON output: "AI Bridge Torque (Poly) Setup Cluster Array": [ { "Bridge Information": { "Bridge Configuration": 10182, "Nominal Bridge Resistance": 350, "Voltage Excitation Source": 10200, "Voltage Excitation Value": 10 }, "Channel Name": "Bridge_Torq(Poly) - PCB Model 039201-53102 Serial 127511", "Channel Selected": true, "Custom Scale Name": "\u0000\u0000\u0000\u0000", "Fwd or Rev Coefs": "Use Fwd Coefs to Gen Rev Coefs", "Maximum Value": 1000, "Minimum Value": -1000, "Physical Channels": "\u0000\u0000\u0000\u000BMFDAQ-X/ai2", "Scaling Information": { "Electrical Units": 15897, "Forward Coeff": [ -1.78569123456789E-5, 0.00200225212345679, 1.20519812345679E-9 ], "Physical Units": 15884, "Reverse Coeff": [ 0.00891831812345679, 499.437812345679, -0.150142012345679 ] }, "Units": 15884 } ],
-
For comparison, here is the JSON-format of your config file: ConfigJSON.txt An excerpt: "AI Bridge Torque (Poly) Setup Cluster Array": [ { "Bridge Information": { "Bridge Configuration": 10182, "Nominal Bridge Resistance": 350, "Voltage Excitation Source": 10200, "Voltage Excitation Value": 10 }, "Channel Name": "Bridge_Torq(Poly) - PCB Model 039201-53102 Serial 127511", "Channel Selected": true, "Custom Scale Name": "\u0000\u0000\u0000\u0000", "Fwd or Rev Coefs": "Use Fwd Coefs to Gen Rev Coefs", "Maximum Value": 1000, "Minimum Value": -1000, "Physical Channels": "\u0000\u0000\u0000\u000BMFDAQ-X/ai2", "Scaling Information": { "Electrical Units": 15897, "Forward Coeff": [-1.78569E-5,0.002002252,1.205198E-9], "Physical Units": 15884, "Reverse Coeff": [0.008918318,499.437845,-0.150141962] }, "Units": 15884 } ],
-
Wow, that's really pushing the INI file format; what do the files look like? Personally, I switch to JSON format once I need to store arrays, let alone arrays within a cluster within a cluster within an array within a cluster. Note> the JSON package above saves DBLs with 15-digits.
-
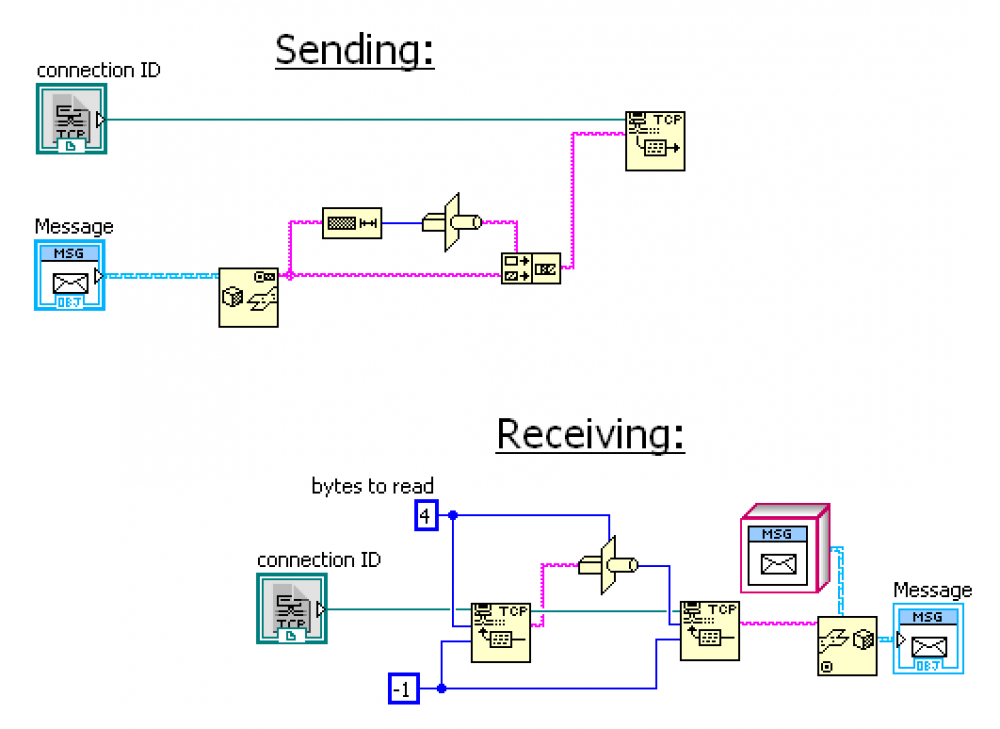
For anyone listening, here is how to send messages (or any other data type) via a TCP connection. Basically, one just puts a message length at front and reads that first. TCP handles making sure you never miss a byte, so there is no need to identify data boundaries.
-
Remember this conversation? Those examples I gave use a TCP client-server. They should work with multiple copies of the client.
-
You can cross (1) off at least, as there is no need to poll a TCP connection. Just have one loop sit waiting for incoming messages, with a second loop to do sending in parallel. TCP is bi-directional and the two directions don’t interfere with each other, just like a pair of Network Streams. But being bi-directional, you don’t need to establish a second connection from server back to client, and thus don’t need to know the client name. If the client can reach the server you are done. And the TCP Listener is exactly what you asked for as far as a server handling incoming connections. To me, TCP seems much simpler than what you described. Re (2), I don’t have experience in unreliable networks. But I have always been confused by Network Streams, as TCP is already a robust network protocol that resends lost packets; what is Network Streams able to do that TCP can’t? — James