

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
I note that the SQL code to do arbitrary planer cuts through a 3D cube seems relatively straightforward, with a single large table and a simple WHERE statement ("SELECT … WHERE ABS(1.2*X+0.3*Y+.9Z) < tolerance", for example). So you should prototype that with a large dataset and see if the performance is sufficient. Also, don’t neglect the 3D picture control for visualization.
-
Which LabVIEW version? According to my own tests some time ago, there was no way to get lvlib, lvclass or similar >= LabVIEW 8.x files into an LLB.
I think they mean creating Destinations set to LLB on the Destinations tab of the EXE build spec. I tried putting LVLIBs in these Destinations and it seems to work.
Added later>> shoneil posted while I was experimenting.
-
- Popular Post
- Popular Post
Some of the presentations at the recent CLD Summit in Newbury, UK, were recorded by Steve Watts and are available on the CSLUG YouTube Channel.
-
 3
3
-
Each plot can only be associated with one X scale; I’m not sure what the “normal†your referring to is.
-
Both your plots are on the same X scale, so the second X scale has nothing to autoscale to.
-
Bug still present in LabVIEW 2015. I have reports of this issue in an app of mine, though I don’t touch the Yaxis properties at all. Does anyone know of other properties that trigger this issue?
— James
-
Notes on the 1.6 version:
1) there is a “Create Actor From Template†option under the Tool>>Messenger Library menu.
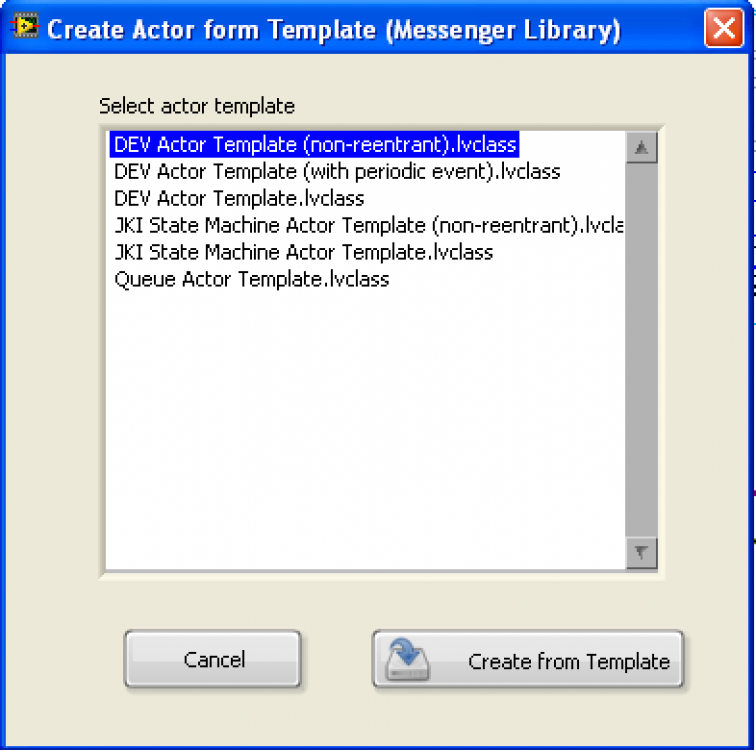
the DEV template is what I mostly use, though there is also a JKI “Statemachine" version.
2) One can now make actors non-reentrant. To do this one must rename the “Actor.vi†to “ActorNR.vi†in addition to making it non-reentrant.
-
1
-
-
Did you wire up the minus as 2-(shift reg), then move the wires around to make it look like (shift reg)-2?
Then the shift reg would go 10, -8, 10, -8,… and never be less than -10.
-
1
-
-
One is a framework intended to be developed and modified, the other is a more or less closed module that the user is never intended to open, just use it. One is feature complete, the other is a shell of an application.
Well, the internals of the framework are not intended to be modified (or at least that would be a very advanced use). Application-specific code is meant to just be simple message-handling loops, with an API for passing messages. No LVOOP beyond copying a template class containing one “actor.vi†method. That those “actor.viâ€s are forced to be shared reentrant, with a resulting learning curve, is a problem. This conversation has lead me to reattempt a way to allow non-reentrant actors and I think I have a solution that works well, with the ability for a CLAD to more easily find his way through the code. I’m going to try it out in my current projects.
-
You can't easily just open an XNode.
Exactly. They seem to me to be much harder for a CLAD to get to grips with than my async-called, shared-reentrant actors (though I am an XNode novice).
Yeah that's part of the problem, the only "standard" on making an actor design at the moment is the NI Actor Framework.
Poor wording on my part. I don’t mean community standardization; I mean developer or team standardization on using a limited set of ways of doing things, so that one be expert in those techniques, and one can read and understand code quicker. I use my actors extensively, at multiple levels in my code. I don’t use techniques like “Action Engines†or any asynchronous calls of custom VIs, because I’m standardizing on Messenger Library actors.
The actor I did just today is a small, one-VI-API “helper†that adds functionality to a WaveformGraph. It is based on the exact same actor template that is used by my “Top Level†main application, and is using the same standard techniques.
-
Just open the VI and see.
Is that how your CLAD programmer learns about your Xnodes?

But your right, it is a problem. Even though I could show someone what to do in minutes, it’s easy to have no idea what the first step to do is. Fabiola is fighting that problem by providing several instructional videos for her new Delacor framework.
I’ve been trying to develop a way to make my actors easily switched between reentrant and non-reentrant, so I can leave single-instance actors as more “just open and seeâ€. It hard, because I don’t want to give up other simplifying features, like auto-shutdown of actors.
The benefit in my mind was simple code.
As Fab points out, one can also provide a junior developer simplicity via a simple API or set of tools that encapsulates complexity. And personally, I think there is simplicity in standardization, since there is so much effort in learning code structure.
-
1
-
-
The “Popout Window†actor was a bad example; there are multiple ways to handle UI windows. I meant a more generic “thing running in parallel that receives messagesâ€. The same app with the popout windows has a reconfigurable-on-the-fly chain of analysis actors that pass data messages between them. Actors are selectable from a list of plugins, and actors must be started and stopped as the User makes changes.
Another example is a “TCP Connection†actor that is created for each connection made to a "TCP Listener†actor.
One can, of course, make custom code for each case, with an asynchronous call and the setup of some kind of communication, but using a well-tested “actor†template gets one up and running quicker and with perhaps fewer bugs.
The benefits of this type of design is the only thing that is asynchronous (and more difficult to debug) is the actual UI, not the actor it self handling all the messages. Probing and opening that actor was easy because it was on the block diagram of my main running VI and I could hold CTRL and double click to open the BD.
I don’t really understand these benefits. The major point of “actors†is to make async easier to debug, so why do I not want the actual UI to be an actor? Every time I’ve tried making a custom async thing I’ve regretted not using my actor template. And I’ve never found opening and probing async actors difficult (they have a “Show Front Panel†message)**.
— James
**Haven’t worked with actors on RealTime, so it might be different in that case.
You mean like the MDI Toolkit? That just uses a list and adding it to the list instantiates the window. Or is it something different?
No, they are just simple actors with a subpanel to hold a front panel. They allow adding behavior like adding custom right-click menu options, highlighting the window when the User hovered over an icon the represents the window in the main app, notifying a managing actor when the User closes the window, etc. All this could be done with dynamic event registration in a central component, which is why it is a poor example.
-
All this needs is the ability to specify terminal allowed types, including matching output types to inputs. For example: “A must be a string", "B must be a numeric", “output C must be the same type as input Dâ€, etc. Then it would be extremely useful (and would implement my long-declined idea).
-
I tried version 3.8.11.1 and it all seemed to work OK, but I just want to make sure I'm not doing anything wrong.
That’s fine. I include the latest dll at time of package release for convenience, but you should be able to use any version.
Also when building an installer using your SQLite Library where does the sqlite3.dll get installed - in the root directory of the executable?
When building the EXE it goes in the “data†directory of the executable, and the “Open†vi looks for it there. This should happen automatically, but if not you can mark it as “Always Include†in the EXE builder.
-
On mobile so quoting fails me. I never have an actor be killed unless they all did. But if I want an actor to restart I send a message to it telling it to restart and it is in a state machine so it just goes to the data cleanup case then the macro initialize.
Have you never had the use case of an arbitrary number of actors? “Restart†works if you want 0 or 1, but what about N, specified at run time? I made a “Popout window†UI actor just today to support an arbitrary number of independent windows in an application. The actors start as needed and shut down whenever the windows are closed.
-
Since your API provides access to SQLite from LV, as Rolf said, you have to change LV's understanding of time to match SQLite's. This allows any other APIs/apps to retrieve time from the db under the common (SQLite) definition so they can convert it to their own definitions.
Would that help you? They use Integers to store UNIX time, which has no partial seconds. I can certainly add a Bind Timestamp (Integer) and make Get Column as Timestamp accept integers.
But how common is Julian days since 4714 BC? Not sure if that should override LabVIEW’s definition of a DBL timestamp, especially as this would be a breaking change in the library.
-
Is that a “bug� I used the LabVIEW time definition, as there is no SQLite Timestamp definition. Not sure why LabVIEW doesn’t match the UNIX definition.
-
Are you sure you’re not asking for 972x768 pixels from a 768x972 image?
-
1
-
-
You definitely do not want to have you PID timing based on time delayed send or AF messages in general. Remember, a message is guaranteed to get there, but it's not guaranteed to be handled in any time. So if you have a "Check PID" message, but the "Log data" message gets in there before it, the log data will happen first, then the "Check PID" will happen as soon as it can after the logging is done. This could introduce a lot of jitter.
Another line of reasoning would be to ask why you have PID and Logging in the same actor. If a “PID actor†is only handling messages to do with PID control, then there may be advantages to keeping all actions serialized in one loop.
BTW, Lewis, the AF group at NI.com is the best place to ask AF questions. More people who use the AF extensively will be watching.
-
This raises a few additional questions :-
I don’t think there is a major difference between using one or multiple connections. I’ve used either one or a few. And don’t worry about opening and closing connections, just keep them open. The issue to (slightly) worry about is Write Transactions, as these lock the db file. Other operations will block waiting for the db to stop being busy. These will throw a “busy†error after a timeout which is by default 5 seconds. So don’t BEGIN a transaction then wait for something, as you are preventing other processes accessing the db.
The worst that can happen on power failure is that the current transaction is reverted (important point: do not delete any extra files the SQLite may leave in the same directory on power failure, as these are the “journal†or “WAL†files that SQLite needs to rollback).
Finalize and Close VIs have standard error handling for “cleanupâ€-type VIs (i.e. they cleanup even on error). You do not need to use “clear errorsâ€.
Note, btw, that you can Prepare statements once and reuse them. This saves some overhead. Just Finalize them at the end of the app before Closing the connection (I’ve been thinking of making the Finalization automatic on Close, but haven’t yet).
-
A related LAVA conversation, including multiple examples of different techniques one can use. I did a “cluster of cluster†example.
-
2) top level SQLite performance evaluation code written
1) SQLite isn’t a compression format, and as a flat table won’t necessarily be any smaller on disk than a spreadsheet file. Larger actually, due to the various lookup indexes. However, you have the opportunity to use structured data, avoiding a lot of duplication, which can end up with smaller file sizes (or, at least, the freedom to add much more info at not much larger size). For example, you have “site†and “sending app†strings that repeat often. If you instead saved keys into separate “Site†and “Application†tables, you could store lots of info in them that can be “joined†in with a “VIEWâ€. Similarly you could have an “Errors†table that allowed extended error descriptions instead of just a simple error code (or error severity, etc.). The joining VIEW would look something like:
CREATE VIEW Event_VIEW AS
SELECT * FROM Application_Events
JOIN Errors USING (ErrCode)
JOIN Site USING (SiteID)
JOIN Application USING (AppID)
Your UI would then query this View, and filter on any info in all these table. Find all events whose error description contains the word “testâ€, for example.
2) Look up “LIMIT†and “OFFSETâ€, and study how they are used in the “Cyth SQLite Log Viewerâ€. In that viewer, updating the filtering of a selected UI table takes ms, not seconds. This is because only the visible rows of the UI table are actually selected. When the User moves the scrollbar, the SELECT is repeated multiple times per second, meaning that it looks to the User like a table with thousands of rows. And one is free to use a lot of slow property nodes to do things like text colour, since one is never doing more than a few dozen rows.
3) I wouldn’t bother with VACUUM in a logging application, as the space from any deletion will just get used for later inserts. Use VACUUM if you delete a large amount without intending to reuse the space.
4) You cannot unlock the file if you’ve dropped the pointer to the connection without closing it, I’m afraid. You have to restart LabVIEW to unload the SQLite dll. Your code should always call the Finalize and Close methods, even on error.
Dont suppose anyone knows why this INSERT routine is taking so long (38 ms)? My storage loop cant get anywhere near the speed of my DAQ loop and eventually I get a buffer overflow. I believe I am using the BEGIN and COMMIT correctly, the speed of DAQ is 1 kHz so this routine is executed once per cycle. (see sattached screenshot) Thanks!
Hi Rob,
You need to wrap multiple INSERTs into a single transaction with “BEGIN†and “COMMITâ€. Each transaction requires verified writing to the disk twice, and a hard disk only spins on the the order of once every 10 ms. You need to buffer your data and do a bulk insert about once a second (place a FOR LOOP between the “Prepare†and “Finalize†subVIs in you code image, and feed in an array of your data clusters).
This touches on jollybandit’s question (5): durability against power failure by confirmed writing to disk is time consuming, so you need some kind of tradeoff between immediate saving and delayed buffering. About one save per second is what I do.
-
1
-
-
OpenG’s Trim Whitespace fails on a string of all whitespace, if set to trim the front only. It returns the last whitespace character.
-
Good day to all Lava users
I am New to the envoroment of SQLite and have been experimenting with the tool kit .
Attach a zip file of your benchmark code (including a sample dataset) and I can have a look at it. In the meantime, have you studied the documentation on SQLite.org?
Also, have you seen the “Cyth SQLite Logger� Would this work as a preexisting solution for your app?
Hello,I would like to use the SQLite Library but I have an error 12 when trying to open the data base with the "SQLite open" function (screen view attached).Would you have an idea of what could be the problem ?I'm using the Labview 2012 SP1 Dev version.Thanks a lot !PierreYou’ve wired your database file to the wrong input.
DVRs for accessing class private data
in Object-Oriented Programming
Posted
Are you sure that’s true? Why do they say DVRs should seldom be used. I rarely use them, but that's because I rarely share by-ref data between loops, by any method (I use messages, instead).