

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
So does this not conflict with advise earlier to share the registration handle of B with A1, which is what I did, so that A1 can directly ask B for it's required info. This is working well for me, B is unaware of any other actor so it's at the bottom of the chain and cannot demand anything synchronously of any other component.
No, no, I was just trying to stress that one is making a conscious decision to make B a “serviceâ€, and thus “lower†than A, and you shouldn’t make the service dependance go both ways. Also, though I do this kind of stuff, it is not the technique I reach for first. However, it’s a great technique when one is working with plugins, where the top-level calling actor may know less about a subactor than another subactor knows. For example, one might have multiple plugin UI actors that are designed to interact with a plugin equipment actor; these UIs know more about the Equipment than the Top-level actor, so it makes sense for the Top-Level to just hand-off the Equipment actor to the UI.
-
What gives?
A bug, I assume. Either in your code or the digital waveform chart.
-
Here is an extension of the above to a tree of actors: Main has launched A and B, A has launched A1 and A2, and B has launched B1. At this point, the following is true:
— Main can send commands (including registration messages to receive notifications) only to A and B. It cannot communicate with the sub-subactors A1, A2 or B1. Main can direct replies to commands (or notifications) from A to either itself or B, but no-one else.
— A can send commands/registrations to A1 and A2, but not to any other actor, including Main, or any subactors that may have been launched by A1 or A2. A can direct replies or notifications from A1 to either itself or A2
— B can only send to B1, and can only direct replies/notification from B1 to itself.
— A1, A2 and B1 can’t send commands or registration messages to anyone.
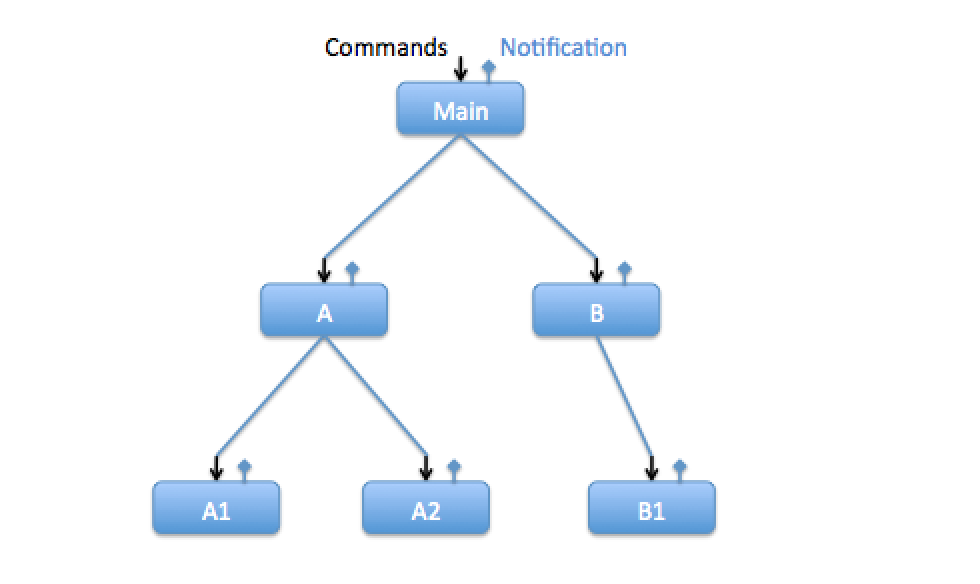
Note that, though we can establish direct communication between actors (across the tree) using registration messages, we can only do this between “siblings", not “cousins". So this system is not the same as one where any actor can be connected to any other actor by something global (as in named Queues). The actors cannot "see through" the levels: Main cannot interact directly with A1/A2/B1. Thus there is significant “encapsulation" in this system. “Main", as an encapsulated component, consists of the Main, A and B actors, and all there interconnecting messages. Component “A" is A, A1 and A2 and their interconnections.
It would be possible for Main to pass the address of B to A in a message. In which case, A can use B as if it were a subactor, like A1 and A2. But this should be rarely used. Main should never pass itself to A, or pass A and B to each other, as this makes actor subcomponents of each other, and that can lead to problems.
If you follow this structure, and set up notification-based direct communication between “sibling" subactors, you get the benefit that actors can act synchronously on their subactors, sending commands and waiting for reply, without the potential for deadlock or other “blocking" problems. Synchronous is much simpler (and easier to debug) than asynchronous for doing the complex work of initialization, shutdown or other multi-step actions, so this is a major benefit.
— James
-
Here is a slide for a talk I gave a couple of years ago that shows an actor’s relationships, as see them:
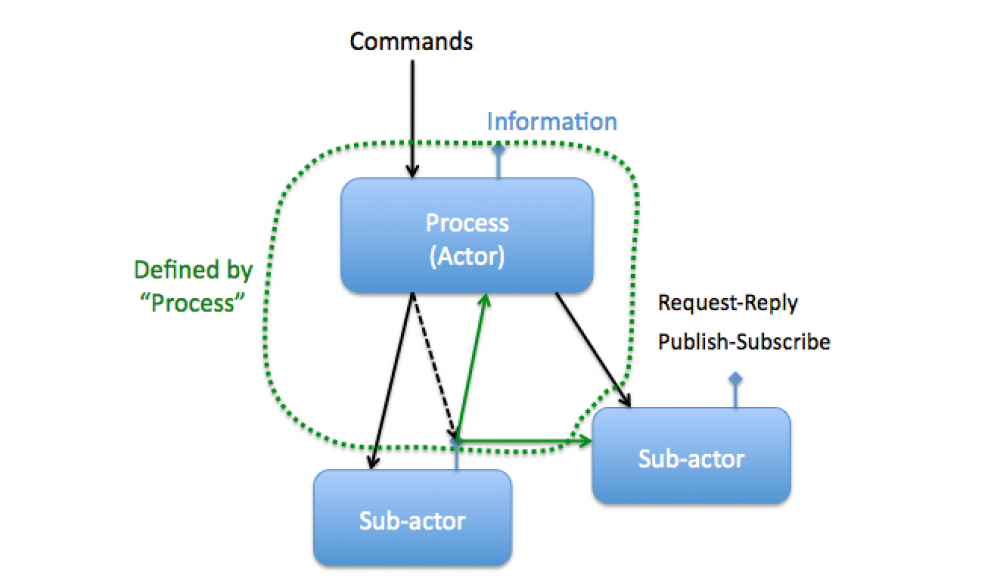
My notes from the Powerpoint slide:
Processes (or “Actors) respond to commands from, and make information available to, higher calling code. But do not explicitly require information messages to go anywhere.
Calling code initiates information messages by request-reply or publish-subscribe mechanisms.
Calling code can direct information messages to third parties, or to multiple parties.In this diagram, none of the three actors “know†about their calling code. The main “Process†actor knows about the two sub-actors, but not about the code that is calling it. One sub-actor is sending a message to the other, but neither sub-actor knows the other exists. It is the main actor that is directing one sub-actor to message the other, which is why the diagram places a dashed line that include the sub-actor communication as being “part†of the main actor.
If this seems strange, let me try and list the benefits of having an actor not know anything about or explicitly depend on it’s calling code:
1) Lower-level actors are simpler; one doesn’t have to understand the higher level code while debugging the lower level actors. Often, low-level actors can run by themselves for testing, or run from a simple test harass.
2) Lower-level actors are more cohesive, modular, and reusable, as they aren’t coupled into the higher-level design. One can re-architect the high-level design without redoing all the sub-components.
3) Actor interactions can often be understood by only looking at one block diagram, the caller’s, as this is where all the interactions are specified. One can know, for sure, what messages one subactor can send to who, without needing to dive into that subactor’s code, because it can only send the notifications the calling code has registered for. This greatly aids debugging.
4) Because sub-actors do not require anything from their caller, and the caller sets up direct communication between subactors, the calling actor is free to use synchronous, wait-for-reply messaging with the subactors.
Number (4) is actually very valuable, because synchronous interaction is simpler than asynchronous, and complex initialization, shutdown, or reconfigurations of the actor system are much easier with synchronous interactions. Having the calling actor not itself participate in the asynchronous message flow between subactors means that it is fully free to setup and shutdown that flow.
-
 1
1
-
-
I suspect I'll be advised to try a different approach, such as explicitly sharing the caller's message queue so that the child actor can directly post messages to its caller. Is that better, or does it have other drawbacks?
Never sharing the Caller’s Queue with a subactor is a guiding principle of how I program actors. I was trying to get this across on your conversation on the AF group when I talked about a “Service hierarchy". Just don’t do it!
Three solutions:
1) An immediate solution to your problem is to use a State Notification rather than an Event Notification (call it something like “Project Data Requiredâ€). It’s a weakness of the current framework that one cannot receive events from actor initialization, because the actor hasn’t processes any incoming messages yet, including the Registration messages. However, this doesn’t affect State Notifications. A quick summary of the difference between Event and State Notification:
Event: “Something Happenedâ€; everyone now registered for this event is notified.
State: “This is now the current stateâ€; everyone registered is notified, and anyone registering for this State in the future is notified of the last recorded state.
Basically, State Notifications keep a copy of the message, in order to inform future people registering of the current state. This avoids all race condition issues in startup, and allows one to hook up new actors to existing state without needing to have observed actors keep re-notifying their (unchanging) state. A very valuable simplification. But it does mean more overhead, so one wants to avoid using State Notification with large data messages. Most of my notifications are State Notifications.
2) If the Caller has the “Project Data†just send it to the subUI; why does the subactor need to Request it? Or Register the subUI to receive the Project Data from whoever has this info (published as a State Notification, or course).
3) Give the subUI the address of a third party (“DataSourceâ€) from which it can request the data (request directly, not by notification, synchronous or asynchronous). Note that this address cannot be the Caller, as we are placing the subUI above DataSource in the service hierarchy (subUI is below Caller by definition).
— James
-
If drjdpowell is watching, any input on that regard?
Difficult to say. There is caching by the OS, caching by SQLite (though 50,000 pages isn’t that much for a multi-GB file), and also the Query Planner that can greatly affect things. Have you run Analyze? There is a custom probe for Prepared Statements that runs “EXPLAIN†to help debug Planner issues. The Query Planner is upgraded with newer versions of SQLite so that could be an issue. Or OS caching can have a big effect on reads.
-
Just playing around, you can simplify the INSERTs by using an INSTEAD OF trigger on the View:
CREATE TRIGGER NewValue INSTEAD OF INSERT ON OrderedBuffer FOR EACH ROW BEGIN INSERT OR REPLACE INTO Buffer (rowID, Value) Values ((SELECT I FROM BufferIndex),NEW.Value); END;
Then you can insert into the View with a simpler statement that avoids referring to the index at all:
INSERT INTO OrderedBuffer (Value) Values (time('now'))-
1
-
-
This schema seems to work (I did a 10-element buffer instead of 1000):
CREATE TABLE Buffer (Value); CREATE TABLE BufferIndex (I); CREATE TRIGGER BufferIncr BEFORE INSERT ON Buffer FOR EACH ROW BEGIN UPDATE BufferIndex SET I = ((SELECT I from BufferIndex)+1)%10; END; INSERT INTO BufferIndex (I) VALUES (-1) -- Initial index is -1
Then insert data (the current time in this example) into the buffer with:
INSERT OR REPLACE INTO Buffer (rowID, Value) Values ((SELECT I FROM BufferIndex),time('now'))The Trigger serves to increment the index before the INSERT.
To get the ordered elements one can use a View:
CREATE VIEW OrderedBuffer AS SELECT Value FROM Buffer,BufferIndex WHERE Buffer.rowID>I UNION ALL SELECT Value FROM Buffer,BufferIndex WHERE Buffer.rowID<=I;
-
1
-
-
But you don't have to add an index and the bit I'm really not getting is how WITHOUT ROWID enables you to store "in order of Time and WN". Insertion order is the same with or without a rowID, is it not?
The point of a WITHOUT ROWID table is when you want a primary key that is non-integer or composite, so the alternative is a regular rowID table with an index. Re the “order†stuff I was being sloppy; rather, I mean the primary data B-tree uses Time,WN as it’s index (rather than rowID), so one can directly search on Time,WN without needing an separate index.
-
1
-
-
Can you explain that? I thought "WITHOUT ROWID" was purely an optimisation.
It is, but it’s a big one in this case. Compare it to a regular table which is:
rowID, Time, WN, Y
Along with an index on (Time,WN) which is a second table, equal number of rows, of
Time, WN, rowID.
The index table is a significant fraction of the primary table in size. The Without RowID table eliminates the need for this index.
-
Of course it may be my mistake that I created an Index on X, an Index on Y an Index on Z AND and Index on X,Y,Z.
Remember that indexes take up memory, and memory/disk-access can be bottlenecks. If your table rows are just is X,Y,Z,Float then you may be losing out by indexing everything. How many points can you store per GB?
I actually am working on a similar SQLite application at the moment. Here is my “big†table, which stores spectrometry spectral points:
CREATE TABLE IF NOT EXISTS SpecPoints ( -- Individual points in the spectra
Time INT, -- Time in ms, Relative to Time_Offset Attribute (allows 4-byte Integers to store +-24days)
WN INT, -- Wavenumber, in units of 0.005 cm^-1, offset 40,000 cm^-1 (this makes it three bytes up to 125nm)
Y INT, -- y= 0.5-Transmission, units of 0.0000001 (allows -0.34 to 1.34 Transmission range to fit in 3 bytes)
CONSTRAINT pk PRIMARY KEY (Time,WN) ON CONFLICT REPLACE
) WITHOUT ROWID;
I’m using a “WITHOUT ROWID†table to physically store the rows in order of Time and WN and I’m not creating any extra indexes. I’m also using scaled integers to pack things tighter than 8-byte Floats (SQLite store integers in the smallest size of I8, I16, I24, I32, I48, or I64). I’m doing averaging over Time bins and Wavenumber regions-of-interest, rather than decimation, so this may not apply to you, but note that a smaller database file makes everything faster.
-
Here is an illustration of what Thoric is discussing. Calling code starts two actors: an “Instrument" actor that is publishing a “Readingâ€, and a “Furnace†actor that expects to receive “Furnace Temperature†messages. If the two messages both use the same data format (a numeric in Kelvin, say) then we use the code on the left to connect the two actors directly. We configure the messages to be relabelled with the “Translate†polymorphic VI. Looking inside that API call we see that we are providing a “Translator†child class to actually do the relabelling.
However, if Instrument publishes its “Reading†as Kelvin, but the Furnace expects “Furnace Temperature†to be in Fahrenheit (horror!) then we can supply a custom child Translator class. This class only needs one method, an override of “Translate.vi†(shown), which adapts the messages to the form required by Furnace. We provide this as a second translator as shown in the code at right.
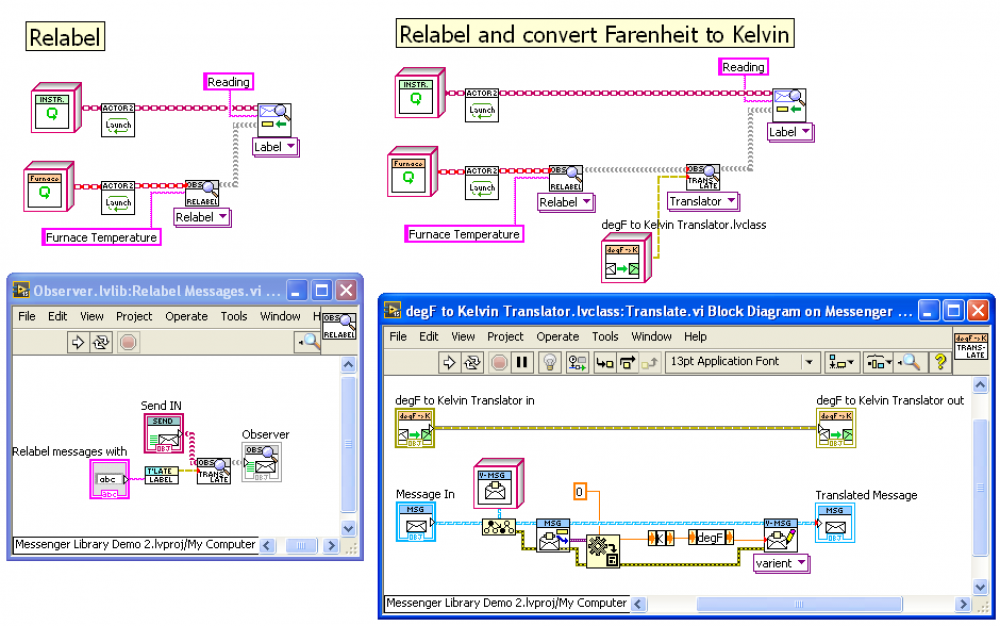
[Opps: just noticed I misnamed the Translator child class as degF to Kelvin when it is really Kelvin to degF]
-
2
-
-
nono, i DO want to reference a pool of clones.
I want to open 3 clones of the same VI, and be able to run them independently, and store the references so I know which clone instance i'm talking to
That’s not a “poolâ€. That is three independent clones. A pool is when you don’t care which instance you are talking to.
-
Hi Thoric,
As a quick aside to other readers let me note that it is a goal of Messenger Library that one NOT have to be a whiz at LVOOP to use it. The standard API is meant to be used by itself to make inter-loop communication easier, without the need to create new classes. But because it is based on LVOOP internally, one can extend it powerfully using inheritance.
So with the proviso that these are “optional bonus power ups†that are rarely used, then yes, the “Translation†polymorphic VI on the “Observer†pallet is specifically intended for one to alter messages. The standard translations that I use commonly are “Relabelâ€, “Add Prefixâ€, and “Outer Envelopeâ€, but there is also “Add Translatorâ€, which allows one to provide a custom child class of “Translator.lvclassâ€. The only method that must be overriden is “Translate.viâ€, though you may want a creation method if your Translator need internal info. See the “LabelPrefix.lvclass†for an example. The “Translation†method is quite straight forward (see an example below).
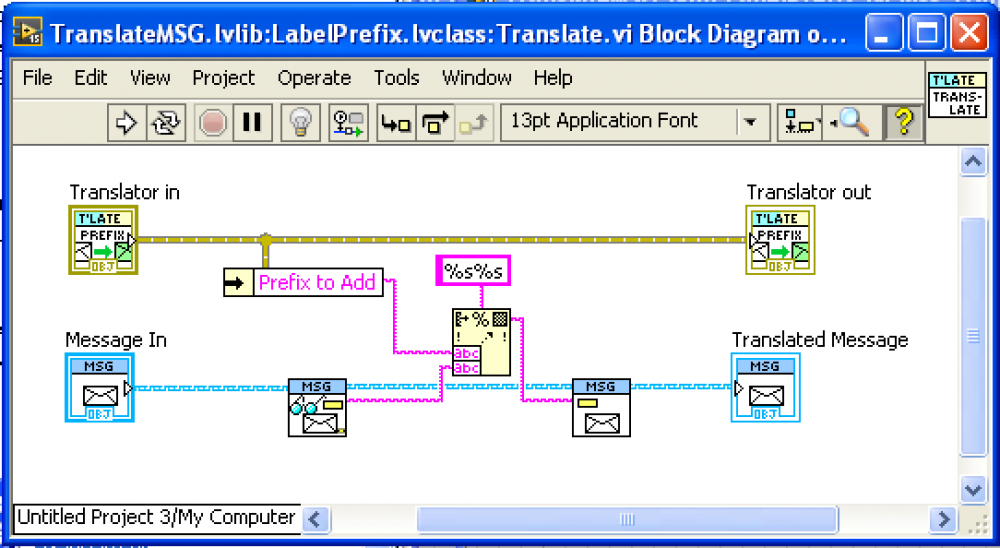
Even more generally, the “Send†parent class, usually thought of as a generic “addressâ€, can also be considered a “Callbackâ€. The “Reply†and “Notify†API methods are really callback hooks, where calling code can “hookup†functionality to an actor. The only important restriction is that the callbacks should not interfere with the operation of the actor (such as by blocking or taking an unreasonable time to execute). So one could do things like average data before it is sent, or log debugging information, for example.
BUT, don’t get too fascinated by the fancy tools in the toolbox. Most of my messages contain only one piece of data.
— James
PS, if you want to explore another powerful LVOOP class that can be extended, look at “Async Action.lvclassâ€, which is intended to make it easy to make actions that can be run in parallel to any loop (with action results sent back in a message).
-
1
-
-
what are your workarounds? the thing that comes to mind is always do var->lvobj first, then lvobj->child class, but thats could certainly get ugly. Where specifically is this coming up in the code?
It come up in JSON to Variant, where the User of the library provides a target cluster containing their custom child classes. I need to provide a Variant that can be converted using Variant-to-Data into their cluster. My workarounds are:
1) require the User to override a “Put in Variant†dynamic dispatch method. Very simple, just puts the object in a Variant with the right wiretype, but a burden on the User.
2) get as LVObj; flatten to string; unflatten using the type descriptor from the supplied child object. This allows one to ‘transfer’ the wiretype into the Variant. But the flattening/unflattening is heavy overhead.
-
I would LIKE the answer to be "3,3,3". So the real question is... What do I have to do to this VI to achieve this?
Stop using the 0x40 pool option. You don’t want a reference to pool of clones. Try just 0x8.
-
1
-
-
Not sure how 0x8 and 0x40 options interact, but with 0x40 you are creating three shared clone pools, so the answer would be three values between 1 and 3, depending on how LabVIEW assigns idle clones in the pool. With just 0x8, you’re making three clones, and the answer is [3,3,3].
-
1
-
-
As the code grew I incidentally came across this solution. Not great, and I should make it a typedef, but it's better that it was.
Darn. I actually had a DEV template modification that demonstrates some of this, but I removed it from the published package because I thought it was too niche. See a screenshot below. I also need to use a subVI to name the event registration. You can also see a “Private Messenger†in the JKI Actor Template.
Note, BTW, that I don’t use EventMessengers in the way you are: a different Messenger for each message. Instead I have multiple messages coming in through one event case, with a case structure on the message label. The only reason I sometimes have a second EventMessenger is to separate “Public†(or “Externalâ€) messages from calling code, from “Private†(or “Internalâ€) messages coming from my subActors. So I can prevent calling code from being able to send me private messages, and I can limit what subActors can do (like not tell me to shutdown, for example).
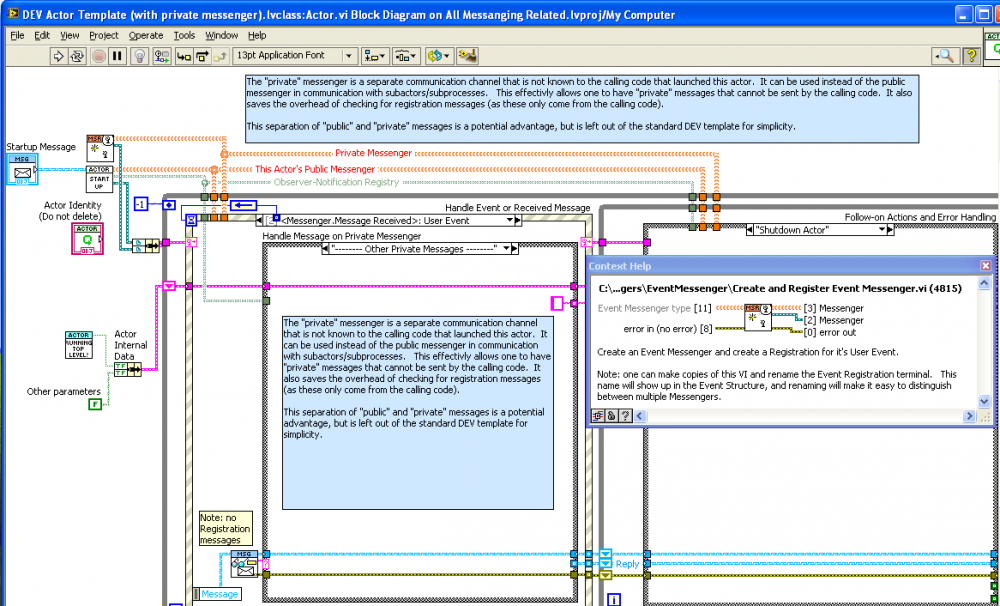
-
1
-
-
-To Json which produces a raw string
-To json which produces a json.lvlib object, which the library then flattens in the usual way into a string.
I'd prefer the second option myself...is that what you're going for?
The second option.
PS> I’m a bit stuck on this at the moment because of a problem with “Variant to Data†being too “dumb†when it comes to child classes. If one has a Variant containing a Parent-class datatype holding a child-class object, and you attempt to use "Variant to Data" to cast this to a Child-class wire, it throws a type mismatch error, even though such a conversion is easily possible. This is a problem when the library-user want to use clusters containing their own child classes. There are a couple of work around but both are ugly.
-
1
-
-
Any thoughts on incorporating the JSON1 functionality included with the latest release of SQLite ( This new functionality is quite intriguing to me as it seems to allow SQLite to be a possible "best of both worlds" solution for relational and document oriented data management situations along the lines of what the latest version of PostgreSQL has.
The JSON SQL functions should be working in this beta (I think it includes the 3.9.0 dll with those functions). I’ve only played around with them a little, but they do work.
-
Oh, I’m not even talking about a framework. Just a hook that allows someone to connect such a thing to the JSON-Variant tools without modifying JSON.lvlib. Then CharlesB could provide his object serializer as an addon library.
-
I suggest you just decimate your data after the filter.
-
2
-
-
Note: I’m thinking of putting in an abstract parent class with “To JSON†and “From JSON†methods, but I’m not going to specify how exactly objects will be serialized. So Charles can override with his implementation (without modifying JSON.lvlib) without restricting others from creating classes than can be generated from different JSON schema. I could imagine use cases where one is generating objects from JSON that is created by a non-LabVIEW program that one cannot modify, for example. Or one just wants a different format; here’s a list of objects from one of my projects:
[ ["SwitchRouteGroup",{"Connect":"COMMS1"}], ["DI Test",{"IO":"IO_ID_COMMS_1_PRESENT","ON=0":false,"Value":true}], ["Set DO",{"IO":"IO_ID_COMMS_1_EN","ON=0":true,"Readable?":true,"Value":false}], ["Wait Step",{"ms":2000}], ["DMM Read Voltage",{"High":2,"Low":-2}], ["Set DO",{"IO":"IO_ID_COMMS_1_EN","ON=0":true,"Readable?":true,"Value":true}], ["Wait Step",{"ms":500}], ["DMM Read Voltage",{"High":13,"Low":11}], ["AI Test",{"High":3600,"IO":"IO_ID_COMMS_1_V_SENSE","Low":3400}], ["SwitchRouteGroup",{"Disconnect":"COMMS1"}] ]-
1
-
-
The drawback is that I need to modify JSON.lvlib, and I didn't take the time to update my fork to stay inline with the development of JSON library.
I could easily make a “JSON serializable†class with abstract “Data to JSON†and “JSON to Data†methods, and have the JSON-Variant tools use them. Then you could inherit off this class and not have to modify JSON.lvlib.
[LVTN] Messenger Library
in End User Support
Posted
I believe for your trial project your dealing with configuration information. I was just today adding a configuration feature to a project, and the technique I used is different from the above discussed technique, so I thought I would post the relevant subVI, called from the top-level VI:
“SubMod†is cluster of subActor addresses. It is converted to an array and then I use “Scatter-Gather†to send the same message to all actors (in parallel) and wait for all responses. Each actor replies to the “Configuration: Get as JSON†message by returning a JSON value, so we extract these and build a JSON Object from them. The top-level actor saves this to a JSON file. Another subVI is used on startup (or when the User selects “Set to default control valuesâ€) to parse the JSON and send subcomponents off to the correct subactor. Note that there are no typedefs to share that increase coupling; the top-level has no dependance on the form of the Config info (other than that it is JSON).
Here’s the code in one of the subactors for replying to the “Configuration: Get as JSON†message:
This subactor has two forms of information that it wants to save: a cluster called “Limitsâ€, and an array of control references. Both are easy to convert into JSON. The JSON Object is sent back in a reply labelled “Config†(though this label isn’t actually needed).