John Lokanis
-
Posts
798 -
Joined
-
Last visited
-
Days Won
15
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by John Lokanis
-

Feedback Requested: Daklu's NI Week presentation on AOD
John Lokanis replied to Daklu's topic in LabVIEW General
Good. I'm glad I got one right! So, if the MHL does not trigger the next step in the sequence by sending itself a message, are you saying that the 'helper loop' should send the MHL a message to do the next step in the sequence? And if so, wouldn't that mean that the helper loop would be less useful since it would always trigger the next step even if you only wanted to repeat a single step? It seems to me that since the state data of the actor lives in the MHL loop, that it should be making the logic decisions about what step to do next in the sequence or to abort the sequence altogether if some error or exit condition has occurred. You are making me sorry I used a database as an example. Yes, databases support multiple connections. And opening a connection and closing it for every transaction is expensive. And I understand your point about pooling connections and opening a new one if two transactions are called at the same time. You don't actually have to do that as you can execute two transactions on the same connection at the same time (the database will sort it out). But what you are missing is the real world fact that databases often stop working. They become too busy to respond because some IT guy's re-index process is running. They because unreachable because some IT guy is messing with the network routing or a switch has gone down, been rebooted or is overloaded. They disappear altogether when some IT guy decides to install a patch and reboot them. If your system is dependent on continuous access to the database, you must do everything in your power to correct or at least survive any of these scenarios as gracefully as possible. So, let's look at your pooling idea: Actor A requests data from the DB Actor. The DB actor spawns a helper to execute the transaction using the available connection. The database is unreachable so the helper loop closes the connection, sleeps, reestablishes the connection (the ref has now changed value) and retries the transaction. It repeats this process 10 times over a periods of 15 minutes, hoping the DB comes back. Each attempt is logged to the error log. At the same time, Actor B requests data from the DB Actor. The DB actor adds a new connection to the pool, giving Actor B's request the new connection. A second helper is spawned to execute this request and runs into the same problem, closing the connection and then reopening and retrying. More errors pile up in the error log. This is repeated many more times, resulting in a bunch of connections being added to the pool just so they can fail to connect, the error log is so convoluted with messages that it because nearing impossible to untangle the threads of errors, and all for what? So you can call two database transactions at the same time? Not worth it. But I digress from the topic. The point I was trying to illustrate was an example where something other than an actor was the best solution. If you don't like my example, think of a different one. I just think your presentation would benefit from a discussion of where it is appropriate and not appropriate to use actors. -
Feedback Requested: Daklu's NI Week presentation on AOD
John Lokanis replied to Daklu's topic in LabVIEW General
Ok, I am not going to quote a bunch of posts but I am going to try to respond to your points above and try to get this back on the topic of how to improve your presentation. But first a slight deviation off topic to clarify the point about making a singleton object vs an actor: I used database access as an example but I think this can apply to other shared resources. Here are the things I am trying to consider: 1. There is overhead to opening and closing a connection to a database. So, caching a connection is preferred. 2. A database connection reference can go stale for many reasons. Also, the database can go down and be restarted. To be immune to these situations, error handling code needs to be able to reestablish connection to the database and reattempt the execution of a database call before issuing a critical error to the rest of the system. 3. Some database operations do not require a response and therefore should not block the caller. Other operations require a response before the caller can continue and are therefore blocking. The ability to have both options is desirable. 4. Having a central actor handle all database operations can work in some messaging architectures but is problematic in hierarchical systems (like AF). By having a object handle database communication (instead of an actor), you can call methods inline (the callers thread is used to execute the operation) when you require the response to continue the work of the caller OR you can spawn a dynamic daemon and have it call the database when you simply want to write data and do not require a response (unless there is an unrecoverable error). By making the database object a singleton, you can reuse a connection between calls (saving the open-close overhead). This makes most sense if you anticipate making a lot of calls but not a lot of simultaneous calls. Also, by having a single object, when there is an issue that can be resolved by retries and reestablishing the connection, you block other callers while working the issue. When you unblock them, you are passing them a repaired connection or you have issued a critical stop because the database is down. Either way, you avoid the issue of multiple callers attempting to talk to a dead database and filling up the error log with redundant information. And yes, this could be achieved with an actor but then you lose the ability to inline the calls and add the need to have reply messages from the database actor. Finally, you have to break the hierarchical messaging architecture in AF to do this. So, my point of using this example was to talk about some cases where an actor might not be the best choice. If you are designing a system and you want to use actors, there are still going to be cases where you want to use other techniques as well. Your presentation should address this in some ways. Maybe give a few examples of places where an actor is not the most efficient solution. Ok, back to the main discussion. Making actors that do not block. I have given this some more thought and I think I now understand what you are saying but let me state it in my own words and you can confirm. The message handler of an actor should not be blocked but the overall actor 'system' (the message loop and all helper loops) can be in a busy state. So, if you have some process that can take an undefined amount of time (let's use the database call again as an example) then you should call that process from the helper loop of an actor and have the message handler respond with a status while the helper loop is busy. If another request comes in, it should queue that job until the helper loop is available again and (if required by your design) reply with a status (ie: I'm busy, you are in the queue). This should leave the actor always able to respond. For example, it could receive a message asking for status and response with how many jobs are in the queue. So, to summarize If you send a message to the actor telling it to do something that takes time, it should hand that off to a helper loop and go back to listening for more messages. Lengthy processes should never be done by the message handler. One point: you sometimes say that your helper loops are like actors, but I think you need to make the point that they do not need to adhere to the rule that they are always ready to receive a message. Otherwise, they would need to be wrapped by a MHL and you start getting into that turtles reference you made earlier. As for sequencing, I think the actor should encapsulate the sequence from the caller but I am less clear on why it is bad to call itself. For example, if you need to initialize a system with several steps, I would anticipate a design like this: 1. Actor is asked to initialize system. 2. Actor calls helper loop to perform first step of initialization and sets state data to indicate what phase of the initialization it is in. 3. Helper loop responds that first step is complete. Actor updates state and calls helper loop to perform next phase of initialization. 4. Process repeats until all steps completed. Actor responds to caller with message that initialization is complete. At any time during the above process the caller can ask the actor what its status is and it can response with what phase of the process it is performing. This could then be used by the caller to update progress in the GUI. In this example, it seems to me that it would make the most sense to make each phase of the initialization process a separate message that the actor responds to. That would allow the developer to easily rearrange the order in the future and it would allow the caller to request re-initialization of a single phase at a point in the future. So, that is why I thought having an actor message itself was a good idea. Expanding your presentation to include some common real world scenarios (like executing a sequence) would be helpful. I would include a discussion of the pitfalls in this example and how to avoid them. I still think it would be best to use simple diagrams to illustrate your examples instead of actual G code. I hope this is helpful. I know this discussion has helped me in better understanding actor programming (or at least shown me what I do not understand about actor programming! ) -
Feedback Requested: Daklu's NI Week presentation on AOD
John Lokanis replied to Daklu's topic in LabVIEW General
It seems to be that in some cases, when a message is executed, the last step of the execution may be to execute another message (send to self) to continue some sort of sequence. This could be dependent on some state data (check if we performing a multi-step process) so that you could still execute the step independent from a sequence. Also, this gives you the ability to interrupt the process with exit messages. I am really leaning towards the DVR idea. Here is my reasons why: I can allow multiple actors access to the database without them having to message a central DB actor. They can still serialize their execution using an inplace structure. I can perform error handing and retries within the DVR class and all actors can benefit from this (if I have to drop and reconnect the DB handle, when I release the DVR, the next actor gets the new handle because it is in the class data of the DVR wrapped class). If at some point I do not want to do a DB operation inline, I can simply alter the class to launch a dynamic actor to process the call and then terminate when complete. Since the state data is in the DVR wrapped class, It will work the same. What good is a MHL that is always waiting if it is waiting for a child actor to shut down? It seems that it is still being blocked in that case. I just do not see a way to truly free up all actors at all times when there are processes in an application that take unknown amounts of time to execute. I keep thinking that actor programming is somehow different from other ways of designing applications and that it is supposed to make things more adaptable and maintainable, like OOP does. But I just can't seem to wrap my head around how to do this for applications with a lot of sequenced steps. The 'actor is always waiting' and 'actor can handle any message at any time' rules just seem impossible to adhere to when there are so many preconditions that need to be met before many operations can be performed and many operations can cause blocking. -
Feedback Requested: Daklu's NI Week presentation on AOD
John Lokanis replied to Daklu's topic in LabVIEW General
Perhaps I was not being clear. What I meant was to design the system so the Actor that had the ability to tell an actor to do something with data was the one that also sent the data needed. So, in theory, you would not get in a situation where an actor get a message it could not act on because the message was designed to include the data in the first place. But the more I think about this, the more I am unsure if this is even possible. I need an actor to have state data to act on. I need to have multiple messages that command it to do something with that state data. Somehow I need to have the actor load the state data in the first place. And I need the ability to re-load that state data in the future. More thought required... -
Feedback Requested: Daklu's NI Week presentation on AOD
John Lokanis replied to Daklu's topic in LabVIEW General
Would you dynamically create an actor to handle each DB request and have it destroy itself after it completed and returned the results? What if you wanted to share a DB connection, to avoid the expense of opening and closing the connection for each transaction? You could wrap the DB class in a DVR and then have each DB actor use that object. This would have the effect of serializing your DB calls (if you needed logic to do error retries and restore the connection if it goes bad). Would that be a bad implementation? (this could apply to any shared resource like a file or some hardware) It seems to me that it might be best implemented as an actor or helper that has limited lifespan and is exclusive the caller. But, my only concern is cleanly shutting down the system if we try to exit while the DB actor/helper is in the middle of processing. If we are going to call it an actor, then it is already violating the principle that its MHL is always waiting, right? I understand this but I am not sure I like it. I am thinking it might be better design for Actor B to send the data to Actor A along with the next step it should do. That way Actor A only knows two things: How to ask for data and how to process data when received. This sounds kinda like what you say below with your sequencer. I want to design it such that an Actor is never asked to do something it is not ready to do. It seems like it might be best to divide the flow logic up between multiple actors. I like this concept. I am going to see if I can do something similar. 1. I think you answered this above already. I was referring to the case where Actor A needs data from Actor B before it can process a message from Actor C. Mainly, the point was some messages are acted on differently based on the current state of the actor. I think your discussion should have some example of this and how to deal with it. 2. All good points. 3. Your description of the sequencer answered this. As to your overall presentation, I still feel you should avoid actual LabVIEW code examples and instead use pseudo code or pseudo-block diagrams (not 'G' block diagrams!). I would not waste your time on fancy animations. They rarely do much to communicate information and mainly just entertain the observer. (I'm not saying that your presentation should not be entertaining.) Just focus on putting up pictures with very few words. Maybe just add arrows between slides to emphasize portions of a diagram. If you dont have a lot of text on your slide, then you cannot make the mistake of reading your slides aloud for the audience! For making your diagrams, I recommend you check out yEd. http://www.yworks.com/en/products_yed_about.html -
Feedback Requested: Daklu's NI Week presentation on AOD
John Lokanis replied to Daklu's topic in LabVIEW General
Well, I am struggling with a few actor programming challenges.You state in your presentation that the message handler should always be waiting. Therefore, it needs to hand off action to another actor or a helper loop ASAP when it receives a message. This sounds a lot like the producer part (UI Event loop, for example) of a standard producer-consumer architecture. The goal is to always be ready for the next message. In command pattern message systems like AF, what do you do if the message says to do something that takes an unknown amount of time? For example, what if the message requires the actor to access a database? That database call can take significant amount of time depending on what the call is doing and if there are retry-able errors. Should that be handed off to a helper loop? Or should it be handed off to another actor?If you say helper loop, then do you create a helper loop for every potentially slow action that acting on a message can instantiate? That seems like a lot of loops that could be hard to maintain.If you say, create a DB handler actor, then what is there to stop that actor from backing up with requests for database calls if the database is running slow? (a very common real-world occurrence) My next challenge is dealing with state. Actors in AF (and in other actor based implementations) often have state data associated with them. This can be set at initialization or can be changed by a message at some point in the life of the actor. This state data can also affect how an actor responses to message. In the example above with the database, let’s say an actor is sent a message that says 'do this action' but that action requires information contained in a database. The actor needs to get the data before it can fully process the message. How do we best handle this?Do we do the DB call in-line and wait for the data, then take the requested action? That would block the actor.Do we hand the DB call off to the helper loop or DB handler actor and have it populate the state data with a later message that then also triggers the action?What if the actor receives another message that depends on that state data from the database but the helper loop/DB actor has not returned it yet? Do we save that message for later? Do we ignore it? Seems complicated. The last challenge is how to get state machine behavior out of an actor. If you have a series of steps that need to happen and are set off by a specific message (like 'run this script'), how to you construct a set of actors and helper loops to accomplish that? You want your actors to not be blocked. You want to be able to interrupt the process at any point with an outside message. You want to be able react to state changes between messages and change the order of the steps (say, the script has a 'goto' or an abort or pause step in it). So, you do not want to queue up a bunch of messages like your favorite QMH. But you do need to have the system react to changes and take appropriate actions. Does all of this belong in a single actor with helper loops or a set of actors or something else entirely? Boiling this down to some fundamental questions:How do you deal with data dependencies between messages (state)?How do you decide when to in-line, when to make a helper loop and when to create another actor?How do you implement state machine behavior in an actor based architecture? -
Are the NI Week 2012 vids gone? I was looking back (after showing some of the new ones to co-workers) at my collection and wanted to grab a few more but they appear to be gone.
-
thanks for the explanation. I suspected something like that but now it is more clear to me. Always good to understand what is going on behind the scenes. I read somewhere that the compiler will try to parallelize the for loop even if you don't turn on loop parallelization. If that is true, the main reason I can see to turn it on is to have the IDE detect if the loop is not parallelizable based on its design (like iteration-to-iteration dependencies). One place this can bite most people is passing something through a loop using a shift register. In the past, I am sure we have all made the mistake of passing something through a for loop without using a shift register (simply using tunnels) and having the data on the wire get lost because in one situation the for loop executed zero iterations. Once you get bit by this, you learn to always use a shift register to prevent that data (perhaps a reference or something that does not get modified in the loop) from being lost. But this then makes the loop un-parallelizable (is that even a word?) because the shift register implies that there can be an interation-to-iteration dependency. The better design is to branch the wire before the for loop and send the new branch on to later functions, letting the other branch that enters the for loop die there. This of course causes a data copy and we have been taught to avoid those when possible. But, in this case I think it is the best solution if you wish to take full advantage of loop parallelization. Did that all make sense? Or am I off in the weeds on this?
-
I was not really trying to benchmark anything. I actually came across this when trying to determine if turning on loop parallelization was worth while in a separate project. I have a broadcast method that sends a message to multiple listeners. It does this in a for loop (looping through the various transports and putting the message on each one). I added some code to time when the message was received at each destination. I then compared the times. After that, I turned on parallelization in the for loop and ran it again. From what I could see in this limited test, there was no noticeable difference. That is what led me to the VI posted here and the observation I made. I know that the OS gets in the way and messes things up. This is quite clear if you run my VI multiple times and see the varying results. I was mostly just curious to understand what was going on behind the scenes that could explain the patterns that emerged. The randomness can be explained by the OS but the patterns seem to indicate some underlying behavior. I read a bit about 'chunking' in the LV help but am not sure if that is what I am seeing in the patterns. Anyways, just some curiosity, that is all. At least I have learned from this thread that posting VI snippets is a bad idea...
-
Feedback Requested: Daklu's NI Week presentation on AOD
John Lokanis replied to Daklu's topic in LabVIEW General
How about creating examples of how to use Actors to solve common programming challenges or implement different architectures without using LV code? Instead use pseudo-code or maybe simple block diagrams to illustrate what actors and messages would be created to implement the solution. You should also include some diagrams that shows both how the parts interact and how they are (or are not) coupled together. No need for LabVIEW code since your discussion is about theory and not G programming tips and tricks. If you can give your presentation to a Java or C++ programmer and they understand it, you have done your job. -
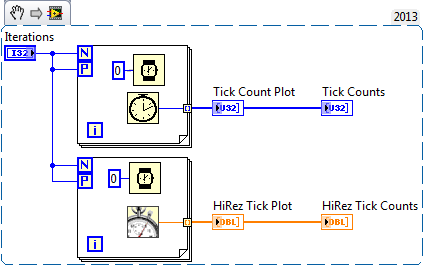
Yes, with multiple CPUs, you get some parallelism. The interesting thing is how you sometimes get a jagged line as some elements that come after others were created earlier in time. I expected more of a staircase effect where the first 4 elements (I have 4 CPUs) would have the same time-stamp and the next 4 would have a later time stamp, and so on. It appears that instead the compiler is breaking the loop up into sections of some predetermined length and then giving those sections to different CPUs. The length of the sections also appears to decrease with each iteration of processing as the jagged line become less pronounced as you approach the end. It also appears that the processing on each CPU does not start at the same time but is rather staggered, as if the sections were determined and the first CPU started working on its section while the second section for the second CPU was still being handed off for processing. Adding the 0ms delay did allow the CPU's processing to line up, or so it appears. This is, of course, all conjecture from just observing the output. I just found this very curious. I have tried dragging the original PNG to a LV diagram and it generated code just fine. But saving to disk from LAVA and doing the same did not work. So, the stripping might have happened on my end (using Chrome browser). Here are the VIs, FWIW. loop parallelization.vi loop parallelization with delay.vi
-
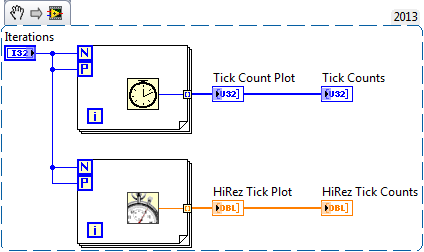
Just playing around with loop parallelization (sp?) and the hi-rez tick counter. I got some interesting results. Looks like loop iterations can execute out of order (parallel loops are not really parallel (of course) since the CPU must serialize them at some level) Not sure if this is all that meaningful but I found it interesting. Here are some code snippets to play with.

-
I don't disagree with this but my point was the use of property nodes to access data in a DVR wrapped class (via their accessors) opens you up to the same race conditions that FGVs (with only get and set operations) have. So, whenever someone says how cool it is that you can do this, I think 'yeah, but what about read-modify-write issues?'. Of course you can use the IPE structure to unwrap the class and safely use its methods to modify class data, but that is not using the property nodes. I do use DVR wrapped classes to implement singleton objects, but I am careful to only use the property node feature to read current value and not read-modify-write. I suppose you could pull some tricks to overload the read accessor to modify the data (ex: increment a counter) but I generally would consider that a bad practice. But, if your goal is a "GLOBAL" then that implies 'by-ref' to me and therefore the better choice for replacing a FGV with a class that uses a DVR is to put the DVR in the class private data and protect it with methods for access and modification. I just don't see the point in making something you intend to be a "GLOBAL" have the ability to be a by-val class. That said, I complete agree that if you are making a class that might be used by-val or by-ref in the future, then wrapping it in the DVR for those by-ref cases is preferable, as long as you keep the property node race issue in mind. Now, if only we could wire a DVR wrapped class into an invoke node to access the class methods, we could do some cool stuff!
-
Nancy also mentioned the use of DVRs as a replacement for FGVs and AEs. There are two ways to make an LVOOP DVR FGV. One is to create a class with methods that operate on the data and then wrap that class in a DVR. The other is to create a class that has a DVR in its private data and then create methods that create the DVR, access the data in the DVR and destroy the DVR. My question: Which one is better? Which one do you use? One 'feature' she pointed out was if you wrap a class in the DVR, you can wire the DVR to a property node to use the accessors, This seems cool at first but don't you just introduce the same race conditions that the old get-set FGV had in the first place? After all, wiring a DVR wrapped class to a 'read' property node is simply a 'get' and wiring it to a 'write' property node is a 'set'. The operations you do in between are unprotected. Given this, I would argue the the second LVOOP DVR FGV implementation is the better choice. If you still want to wrap the class in a DVR, simply do not make any 'write' accessors and force the writes to happen in methods that use an inplace structure to protect the data.
-
Dev Suite DVDs arrived in the mail today! Now to go install all the add-ons...
-
LabVIEW 2013 Favorite features and improvements
John Lokanis replied to John Lokanis's topic in LabVIEW General
I have been immortalized in the LV2013 release notes! I am so glad they added this. Although I think it is more because I kept calling support and asking them what each installer did what and when it was needed. I was amazed that the top-tier test support guys didn't have any more clue than I did. I'm betting this feature alone reduces the number of calls they get in the future. -
LabVIEW 2013 Favorite features and improvements
John Lokanis replied to John Lokanis's topic in LabVIEW General
Try this: http://www.ni.com/pdf/manuals/371780j.pdf -
Oh well. I guess I missed it the first time. Guess my search terms were lacking before I posted this.
-
LabVIEW 2013 Favorite features and improvements
John Lokanis replied to John Lokanis's topic in LabVIEW General
Oh, I would not be switching to LV2013 yet either if my project was near completion. But in this case, I do not expect to be ready to release until well after SP1 comes out. For me, there are many compelling features in 2013 that I want for this project. Including the new web service features and the improvements to .net calls. Getting this tree control speedup is just a bonus. In the past I have always waited for SP1 before updating my projects. It is actually kinda fun to be able to jump in the pool early this time. As for upgrading my tool chains, that took all of 20 minutes to install packages from VIPM, copy reuse code, recompile and save everything. The only 'bug' I ran into is the new rule that a shared clone cannot statically link to an Application level event. Not sure why this is but the workaround was fairly painless to implement. -
LabVIEW 2013 Favorite features and improvements
John Lokanis replied to John Lokanis's topic in LabVIEW General
I too have jumped through many similar hoops over the years. But you need to embrace change! Think of it this way: the code that drew the colors when scrolling will just run 10x fast now! -
This is cool both visually and auditorily. enjoy! -John
-
Just ported my project to LV2013 (livin on the bleeding edge!) I am sure to find many cool new features and improvements but I thought I would share one with you the jumped right out at me: The Tree Control is 10x faster! (At least, when I am setting cell colors on multiple rows while updates are deferred.) In my example, it was taking 4-5 seconds to do the update for a few 100 rows in LV2012. In LV2013 it takes less than a second. This will be a big improvement for my GUIs. So, thanks to the engineer(s) who worked on this! I wonder if this is specific to the tree control or if other UI processing is also improved? I will report back with more finds but please add your own to the thread. -John
-
Activation appears to be online now. I just got mine to go through. Try it!
-
running a local VI in a remote application instance
John Lokanis replied to John Lokanis's topic in User Interface
Even the original application (now over 10 years old) uses a plug-in architecture. (LLBs created with OpenG Builder). But it is time to move on and try new and (hopefully) better things. So, I will give PPLs a whirl. But I can always fall back to LLBs if it fails. But that is a whole different can of worms I will solve later. Maybe I should call this a dynamically distributed plugin architecture! -
running a local VI in a remote application instance
John Lokanis replied to John Lokanis's topic in User Interface
At this point I am thinking of using a PPL to store the prompt and it's support files. That way, I should be able to just send the PPL across. On a side note, I am playing around with reading a VI file into LabVIEW and then writing it back to disk in a new location. (I will need to do this because I need to send the file over the network, regardless if it is a VI, PPL or ZIP.) For some reason, LabVIEW does not want to open my new copy of the VI, even though it is an exact byte by byte duplicate of the original (verified by comparing the file data in LV and with WinDiff). So that is not good. <edit: nevermind. forgot to turn of convert EOL. works fine now>