John Lokanis
-
Posts
798 -
Joined
-
Last visited
-
Days Won
15
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by John Lokanis
-
 Updated the thread on the NI site. Please reply there.
Updated the thread on the NI site. Please reply there. -
Updating a middle element of a variant tree
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
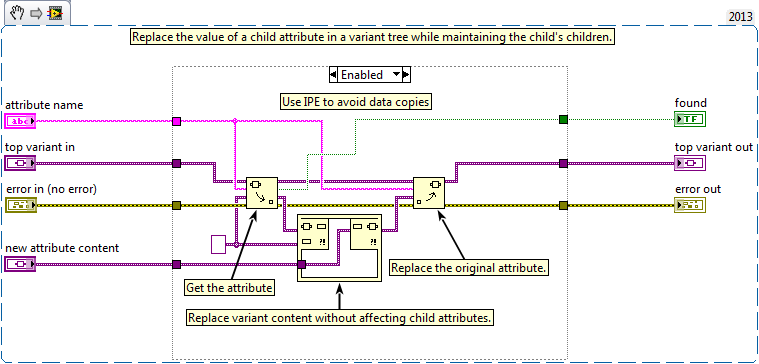
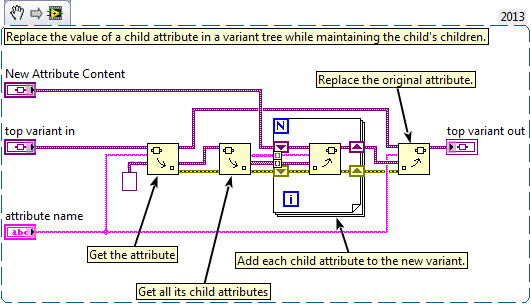
Yup. That thread is exactly what I am doing. Wish I would have seen that first. It would have saved me a lot of time. Still agree that we need IPE support for attribute access. That would still improve my solution. Well, I am now off to find other places to use DVRs in my message system. I bet there are a few more places I can improve things... -
Updating a middle element of a variant tree
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
Funny you mention that. As I attempted to re-factor this problem away, I ended up trying two things. 1. Store the node values in a separate variant. 2. Store a DVR of the node data in the attributes of that separate variant instead of storing the node data directly in the attribute. In my case, I am implementing a subscription message system. The system needs to allow for multiple subscriptions and each subscription needs to keep track of all of its subscribers and the last message sent. That allows me to broadcast to all active listeners and for new listeners to request the current value of they subscribe between broadcasts. The benefits: I can add subscribers and remove them from a variant tree that contains no data other than the attribute names. I expect to have under ~500 subscriptions in the system at max load and each subscription would have under 10 subscribers. So the tree is not too big. Having the data stored as DVRs allows me to avoid that massive copy when I extract the node data tree from the system (I store system data in a DVR itself so all processes have access to it). The other benefit is I no longer need to write back any changes to the node data in the tree. I just update the DVR's content. The variant tree never changes. One caveat: My node data is a message. All messages inherit from a common ancestor. I tried to create a DVR of this ancestor and use that as my node data type, but LV will not let you modify the data in a DVR if the type is a class, even if the new data is a child of that class. Not sure I fully understand the reason for this, but the workaround is to store the data in the node ad a DVR of a variant. That just means an extra cast when I want to access the data. Seems kinda silly to have this limitation but I am sure they have their reasons. Anyways, problem solved and speed is no longer an issue. Now to add some cleanup code to free all those DVRs on shutdown... Thanks for all the help and tips. This is why I love LAVA! -John -
Updating a middle element of a variant tree
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
Ok, new version isolating the node data to a separate attribute produces and 8% overall speed increase. The original copy of the branch from the main tree seems to be the overwhelming issue. Here is the new code: I did not include a snippet of the other changes I needed to make: Populate the top child with an empty NodeData Attribute when adding that branch. Deleting the NodeData attribute from the array when getting the list of branch children. At this point, I am wondering if I could get a speed improvement from redesigning this using LVOOP objects instead of variants.
-
Updating a middle element of a variant tree
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
Kinda. I had to cast the generic variant to a variant using the 'to variant' prim when I added the child to the top variant. After that, it allowed me to use the IPE to update it. Not sure if that is what you mean. It is not possible to make the first 'get attribute' inplace since I am getting an attribute value by name and replacing it. The IPE only provides access to the node data, not its attributes, as pointed out in the Idea Exchange link you provided in your first comment to the thread. -
Updating a middle element of a variant tree
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
where? -
Updating a middle element of a variant tree
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
Thanks for the trick. I will try that next. I just tried the re-factor using the IPE instead of the for loop to preserve the child attributes. The result is a 31% DECREASE in performance. I must admit I am very surprised by this. Assuming I did this right, I think your other solution sounds better. I'll post my results once I complete the edits...
-
Updating a middle element of a variant tree
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
Thanks for the tips! I will see if I can re-factor my code to avoid the copy. I do have a few questions: 1. Using the IPE, it appears that I still need to do the copy to extract the first attribute. But it does eliminate the need to reattach the children of the attribute. 2. If I move the node data to an attribute, there would be no need to use the IPE as far as I can see. 3. I often extract all child attributes from one of the top attributes and then perform an action on each of those. If the node is now an attribute, I would need to remove that item from the array of attributes before I process them. There are two ways I can think of doing this. The first is to test the attribute name inside the process loop and skip the one named 'NodeContent'. The second is to search the array of attribute names for the element named 'NodeContent' and then delete it from the array before I process the array in a for loop. Any opinion on which solution would be faster? I expect most attribute arrays to have less than 100 elements. thanks again. -John -
Does anyone know a faster way to accomplish this? The profiler marks this as one of my top hits for VI time. I wish I could speed it up but I cannot think of a better way. Thanks for any ideas. (Even if that idea is to not use variant trees for storing data. But if so, please offer a faster data store method.) -John
-
Are you sure you meant to say "turn on icon view for terminals" and not to "turn off icon view for sub-vis"? I honestly cannot see any benefit to making the terminal take up more space. I do agree with your point of spreading things out and leaving room to grow if necessary in the future. But, I have seen benefit to turning off icon view for a sub-vi on occasion. Especially for situations where you cannot keep the con pane down to 4224. But now with LVOOP, that seems to be less of a problem. I do agree that accessors have no good reason to have FPs. For that matter, they really don't even need BDs. Maybe I am in the minority but I never edit 99.9% of the ones I auto-create and they mainly mess up my VI analyzer tests because the scripting that creates them does not deal well with long class names. (terminal labels tend to overlap the case structure) Seriously, icon view terminals? The next thing you will suggest is using Express VIs!
-
I am not sure I would want to support the idea of eliminating the FP from sub-vis. While I agree that it's layout does not serve any functional purpose in the code and is just another time consuming step to deal with, i feel it still has value as a unit test interface. That is one of the best things about LabVIEW that text based languages lack. So, Jack, if you want to kill off the FP, you need to tell me how to debug my sub-vis just as easily as I can now. I would support some way to auto arrange the FP in a sensible way. One thing I would love to see is the controls being limited to the visible space on the FP. For example, when you copy some code containing control terminals from one VI to another, those new controls should be placed within the visible portion of the destination VI's FP. Currently, I often have to hunt down where they landed far off screen and move them back into place. I think we have a pretty solid basic agreement on sub-vi FP layout. I would be satisfied if we could simply designate a VI as a sub-vi when we create it and then the IDE would auto-place/move controls to meet those guidelines. The rules I follow are: All controls must be visible on the FP (within the current boundaries. No scrolling allowed) Controls must be laid out to match the connector pane orientation. Error clusters are always in the lower left/right corners. When possible, references are passed in/out the upper left/right corners. All controls snap to the grid (I use the graph paper grid) with at least one grid block separation. There is a minimum margin of one grid block around the perimeter of the FP. The FP is positioned so the origin is precisely in the upper left corner. Bonus things I do:The minimum size of the FP is set so the entire toolbar is visible. Even if this means a lot of white (grey) space on the FP. The VI description is copied to the FP in a comment block at the bottom of the FP. Even if we just had some scripting example to accomplish most of this that would be a step forward. I know many people have made their own version. I would prefer an official solution so we could have some continuity between developers.
-
type def automatic changes not being saved in LV2013
John Lokanis replied to John Lokanis's topic in LabVIEW General
Thanks for the thread-jack guys. I seem to have triggered some deeply suppressed feelings about LabVIEW. Back on topic: I just hope someone at NI can get to the bottom of this and fix it in the next release. (I did report this to tech support) -
I am not sure I can totally prove this but here is what I have seen: In a large project built in LV2012 and then loaded into LV2013, I recompiled and saved all files. Now every time I open the project, a bunch of VIs want to be saved because they claim a type def was updated. I go ahead and save them then close the project and reopen it. Again the same VIs want to be saved. There seems to be no way to get them to save the change once and for all. (Oh, and of course it never says WHICH type def changed!) After fighting this for weeks I finally opened the project and then opened one of the types defs used in one of the files wanting to be saved. I nudged the control by one pixel and saved the type def. I then saved the calling VI. I closed and reopened the project and now the number of VIs wanting to be saved was smaller (and the one I 'fixed' was not among them). I then repeated this process with every type def in the project and saved (individually) each calling VI. Finally, now when I open the project there are no VIs that want to be saved. So, my theory is when LabVIEW converts from LV2012 to LV2013, it changes the type def files and triggers the need to save the calling VIs but for some reason that change is not saved in the type defs so each time I open them, they again convert from LV2012 to LV2013 and re-trigger the change. By editing them I forced something to permanently alter them into LV2013 type defs and that fixed the issue. Anyone else see something similar to this? ps. I have all code set to "separate compiled code from source file". -John Oh, and 'mass compile' did not fix this issue.
-
Love this topic. I have been doing this since the first day I started programming in LabVIEW. I am willing to bet 20% of my coding time has gone to perfecting my BD. But I don't see it as OCD. Just like text programmers will create elaborate function comment blocks using characters to make a pretty box around them and aligning the text inside, I see a well laid out diagram as a means of communicating the operation of the code efficiently. I prefer to position things so the flow is as obvious as possible. I never run wires under objects (unlike *SOME* frequent LAVA posters I know ). I stick to 4224 connectors but I will occasionally convert one to 4124 or 4114 to allow a connection to come in from either the top or bottom, if it makes the diagram cleaner. And I do like to align object in multiple cases. Usually you get this for free when you copy one case to make alternate versions but if it gets out of alignment, I will toggle back and forth to find the issue and nudge it back. One thing I do that I am not sure others do is the wires entering and leaving the side terminals must approach and leave on the horizontal axis. I never allow a wire to connect to the sub-vi from the top or bottom unless it is going to a central terminal. The same goes for all structures. I never have wires enter or leave from the top of bottom. I will add an extra bend in necessary to achieve this. Embrace your OCD. It makes you a better wire-worker!
-
This just saved me again with a single column listbox. Thanks again Darren! (Please lobby to make this public in the next version of LV)
-
VI opens when opening project
John Lokanis replied to John Lokanis's topic in Development Environment (IDE)
Ok, this is really weird. Yes it is. And I never set that. But what is really strange is it is grayed out and I cannot figure out why or how to unselect it. ------------------------------------- Ok, sorted it out. If you accidentally select "Top level application window" and then customize it, you will get the the "Show front panel when loaded" checked and grayed out. If you instead select "Dialog" or "Default" first and then customize, you will get the "Show front panel when loaded" unchecked but still grayed out. Seems like there is no option that lets you control this manually. That could be a bug. I don't recall this being always grayed out in the past. As for the 66 VI that always want to be saved, that looks like an unrelated problem with this project. -
I am seeing some strange behavior each time I open a certain project in LV2013. For some reason a VI I was working on recently always opens its front panel when the project is opened. And it shows a broken arrow for a few seconds while the cursor is in a busy state. Then, the arrow changes to unbroken. I close the VI, I do a save all (and LV saves 66 VIs for some reason) and then I close the project. When I reopen the project, it does the exact same thing. Has anyone see this type of behavior before? Is this due to something I did or is it a bug? Any fixes/workarounds? i have not contacted NI yet since this could be my fault and it only happens with a certain project and only recently (I have been using LV2013 for awhile now without this issue). thanks for your input. -John
-
New idea about class renaming and labels: http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Update-LabVIEW-class-controls-and-labels-when-class-is-renamed/idi-p/2538984
-
Added a new idea to the exchange relating to the issue I was trying to address. Please kudo it! http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Update-LabVIEW-class-controls-and-labels-when-class-is-renamed/idi-p/2538984
-
I'm working on a large project and have run into a quandary about how to best deal with a large shared data set. I have a set of classes that define 3 data structures. One is for a script read from disk that the application executes. Another is the output data from the program, generated as the script is executed. The last is a summary of the current state of execution of the script. The first two can be significant in size and are unbounded. In my application, I have one actor (with sub actors) responsible for reading the script from disk, executing it and collecting the data. It also updates the summary status data. Let's call this the control actor. I have another actor that takes the data and displays it to the user, allowing them to navigate through it while the script is being executed. Lets call this the UI actor. The last actor is responsible for communicating the summary to another application over the network. We will call this the comm actor. So, the control actor is generating the data and the other two are consumers of the data. I had originally thought to have all the data stored as state data in the control actor and then as it is updated/created just message it to the other actors. But then they would essentially have to maintain a copy of the data to do their job. This seems inefficient. Then I thought I could wrap the data classes in DVRs and send the DVRs to the other classes. That way they could share the same data. The problem with that is they would not control when their data gets updated. And I am violating the philosophy of actors by creating what is essentially a back channel for data to be accessed outside of messages. Also, I could block the 'read' actors when I am writing to the DVR wrapped class. I would have to be careful when updating subsections to lock the DVR in an in-place structure to do the modify and write. Then comes the question of how to best alert the readers to changes made to the data by the writer. Simpy send them a message with the same DVRs in it? Or send a data-less message and have them look at the updated values and take appropriate action? So, any best practices or thoughts on how to resolve this issue? I appreciate any feedback.. -John
-
Thanks! That did it. There are so many helpful things hidden away in vi.lib... Here is my cleanup VI, if anyone else needs to do the same. Class Label Cleanup.vi
-
I am trying to automate some housekeeping tasks and have run into a problem. I decided to rename some classes in my project. In several VIs, I place those classes as block diagram constants. I usually display their labels when I do this for readability. Unfortunately, when I rename the class, the labels do not update. (Fixing this would be a nice Idea Exchange feature). So, I decided to write a little scripting VI to go though my BDs and find all objects of type LabVIEWClassConstant and then extract their new class name and use it to change the label. I have done this in the past with front panel controls successfully by using the TypedefPath property to get the class name. So, I traversed the BD and returned an array of LabVIEWClassConstant refs. These were returned as GObjects so I had to cast them to LabVIEWClassConstant type before I can access the TypedefPath property. But when I do this, the value returned from the TypedefPath is empty. I am guessing this is because the cast loses the object's identity and makes it a generic LabVIEWClassConstant. So, now am stuck. Unless I find a way to get the actual class name, I cannot fix the label and must go manually fix it on every BD. I think I am about to add VI Scripting to the realm of regular expressions. In other words, if you have a problem and you decide to solve it using VI Scripting, now you have two problems. thanks for any ideas or pointing out obvious mistakes/misconceptions I may have made... -John
-
LabVIEW 2013 Favorite features and improvements
John Lokanis replied to John Lokanis's topic in LabVIEW General
I have created projects that would crash or warn on exit in multiple versions of LabVIEW. The most recent one turned out to be a corrupt 3rd party class file with bad mutation history. There is now a CAR to address it. So, be careful labeling version A or version B stable or unstable. It might be bad data in your source files. I have been able to build and release applications with every version going back to when the application builder was first introduced that have been stable. It all depends on what features you choose to use and what extras you bring in. I have always found the core functionality of LabVIEW to be stable. You may still run into some issues at the fringe, but NI has always been good about tracking and fixing issues in a timely manner, in my opinion. Much better that the majority of other software tool vendors. -
Feedback Requested: Daklu's NI Week presentation on AOD
John Lokanis replied to Daklu's topic in LabVIEW General
Ok, that helps understand the role of the helper loop better. But what about external Actors wanting to have the sequencing actor perform just step 5? You would have to make a separate message just for that case, but if you made each step a message, you could internally execute them in any particular order and you could externally execute them individually. A concrete example I am thinking of is reading a settings file. You need to read this file as part of the process when you init your application and configure your system. But what if the customer requested the ability to re-read the file while the application is running because they edited it with an outside tool and want the new settings to be applied? If that part of your initialization process was a separate message, you could execute just that part again. If your state data had a flag that indicated if you were doing a full initialization, you could use this to determine if the next step in the sequence should be called or skipped as appropriate. Your actor is still executing atomic steps. You just have the option to have it cascade to additional steps if in the correct mode. Why is this a bad idea? You mentioned race conditions (I understand how the QMH has those) but I think this implementation would avoid them as you are not pre-filling a queue and you have the opportunity to check for for exit conditions before started the next step. -
LabVIEW 2013 Favorite features and improvements
John Lokanis replied to John Lokanis's topic in LabVIEW General
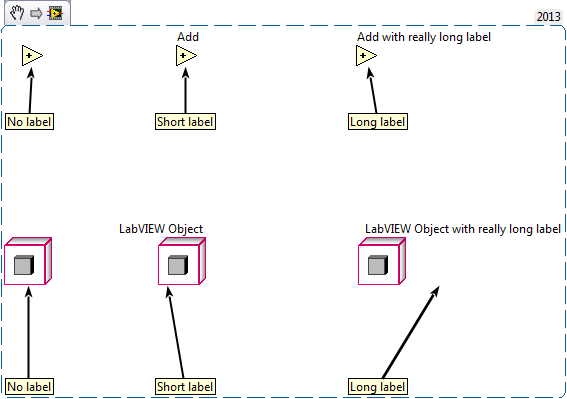
I am really liking the new labels with arrows but I think I may have found a bug. It seems that it is able to point to the diagram element correctly with primitives but if you have an object with a long label showing, it calculates the center of the item using the label and resulting in an arrow pointing in midair. Not sure if this applies to other diagram items as I have only tried it with a few.