John Lokanis
-
Posts
798 -
Joined
-
Last visited
-
Days Won
15
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by John Lokanis
-
 I guess no one at NI want to chime in here with some tips about avoiding the root loop issue. I know some other architectures use VI Server for messaging. There must be some ways to avoid these issues or at least mitigate them.
I guess no one at NI want to chime in here with some tips about avoiding the root loop issue. I know some other architectures use VI Server for messaging. There must be some ways to avoid these issues or at least mitigate them. -
Yes. But I ran into this again when working on my architecture. I really want to keep this simple. That is why I want the VI Server implementation to work. It lets me do messaging without having any code on the reciver side specific to the transport. I just call the local vi and stuff in the message. Simple and elegant, but not bulletproof unfortunately...
-
If I can get this all sorted, I will post the example. It is part of an architecture I am trying out where each process in an application registers a transport with which to receive messages. So, when a message is sent, the system determines what process owns it and then uses the selected transport to send it. The cool thing is, both the sender and receiver contain each process's class and all its messages. For networked messages, the sender simply registers the process with a network transport and does not implements a process loop to handle messages. On the receiver side, the same process is set to use a local queue for messages and we do implement a loop to handle messages. The sender's transport code simply puts the message into the receiver's local queue. The neat part is any process can receiver local and remote messages. And I can move a process from the receiver to the sender by simply implmenting a process handler loop for it and by changing its transport from remote to local. The idea is to treat the messages as an API for each process. But, since I am still working out the details, I have not shared any of it yet. This VI Server issue came up as I was implementing my idea for the remote transport. But, I could easily replace that code with something else that gets the message from the sender to the receiver's queue. One drawback is each application instance can only own one copy of a process type. (messages determine their destination by process type, not the actual owning process object) Also, I have not sorted out a clean way to deal with local data within a process loop. But I think this can be done elegantly. thanks for the ideas. I will see if I can make something workable. That just creates a single point of failure. Something I cannot do in this system as the cost of it failing is expensive. I can live with one server going down or one client, but not something central to everything.
-
In my application, The client would open a connection to the server using VI server (open app ref, open VI ref, call VI). The server would have been up and running for some time before this so it is not in the startup state. The client too could have been up for some time and was making the connection due to some user actions. The server is unlikely to block the root loop since it is headless. But the client could easily block messages from the server by the user taking an action (drop down a menu) or a system dialog box being active. This would cause the server to be hung while it waits to execute the send message operation. I was planning to have the server cache the client machine name and port for sending replies, but I suppose I could cache a reference instead so the only block-able action would be the initial connection establishment. Now it becomes a problem of risk and mitigation. Still, I would like to eliminate the risk altogether.
-
The end goal is a system where there are N servers and N clients. Each client can connect to N servers at the same time. Servers support N connections from clients simultaneously Servers 'push' data changes to the clients. Clients send commands to servers to control them. The data is mostly small but there are some circumstances where it could be around 1M. But that would not be continuous. Only once a minute or less. Most of the time the messages will contain a few k of data at most. Clients will drop off from time to time and the servers will automatically detect this and stop sending to them. Clients will know the machine names of the servers and will contact them to start a connection. I really wish the VI Server method was feasible. It is by far the simplest and cleanest. I will look at those examples. thanks, -John
-
Do you have an example? Seems I would have to create a listener on the receiver side for every 'potential' sender. Since the receiver does not know who the senders might be, I can't think of how to do that.
-
See reply above. :-) Guess we posted at the same time.
-
Since the Send function is self contained, I designed it as a fully encapsulated function. I pass it the machine name, port and VI to call. It then does everything in one shot. If I was to cache the VI Server ref and the VI ref, I would have to devise some sort of FGV mechanism and then find a way to deal with multiple calls to this re-entrant VI that are directing the message to different targets. Oh, and I would love to hear a detailed explanation of the similarities and differences between the root loop and UI thread, including all the potential blocking operations. The reason I went with this message architecture is it was the only one I could think of that did not require any polling on the receiver's part.
-
I have been working on an architecture that uses VI Server to send messages between application instances, both local and across the network. One of the problems I have run into is the fact that VI Server calls are blocked by activity in the root loop (sometimes referred to as the UI Thread). There are several things that can cause this: other VI server calls, system dialogs (calls to the one and two button dialog functions), if the user drops down a menu but does not make a selection... (I'm sure there are more...) Since this is a pretty normal way of communicating between applications, I was wondering if anyone had any ideas for a work around. Here is a basic description of my architecture: Message is created and sent to local VI that sends to outside application instance. Local sending VI opens VI server connection to remote instance. It then calls a VI in the remote instance that takes the message as input. This remote VI them places the message in the appropriate queue on the remote instance so it gets handled. If the remote instance root loop is blocked, the sending VI on the local machine is also blocked. I could try to eliminate all system dialogs from the remote application, but that only partially addresses the issue. I really wish a future version of LabVIEW would eliminate this problem with the root loop and VI Server all together. BTW: using LV2012 but this issue exists in all versions. -John
-
Yup. I love to see new devs scratch their head when they see that in my code...
-
Know what this does?

-
Wizard for the new Project Template feature
John Lokanis replied to John Lokanis's topic in Development Environment (IDE)
Thanks Darren. I will give that a try. Any speculation if a wizard will be forthcoming in a future release? -
Was looking into creating a project template for our team using the new features added to LV2012. Before I dive in an start hacking away at it, I was wondering if anyone has created or found a wizard to automate the process a bit. The only doc on NI's site (http://www.ni.com/white-paper/14045/en) I could find made it looks like a rather tedious process to do this manually. I was actually surprised they would create this feature and not build a tool to guide you through the process of making your own template. thanks, -John
-
Organizing your projects on disk
John Lokanis replied to John Lokanis's topic in Development Environment (IDE)
Wire Warrior - That is exactly how I am setting up my reuse code now. Glad you are having success with it. Paul - I see why that would be good in your case. My reasoning is I want to have visibility to dependencies to in-house code. I want to hide dependencies to 3rd party (NI, OpenG, general purpose re-use) code. This is because I will need to trigger a build if my in-house code changes so I want everyone to be thinking about that and know where things are used. The other code is not likely to change much so I worry less about that. But this may not be an issue to you or you might have other ways of dealing with it. As to the re-use code I do put in user.lib via VIPM, I also want that code to be available via the palettes when editing. The re-use code that is more specific to our company's projects is not something I feel the need to have available via the pallet and can store in our separate area on disk. Also, we are calling it directly from that separate area, where as the stuff in user.lib is never edited there but instead its source is kept separate and it is installed to user.lib where it is called from. I hope that last paragraph made sense! -
Organizing your projects on disk
John Lokanis replied to John Lokanis's topic in Development Environment (IDE)
Thanks for the reply. In the case of reusable code, such and the XML libraries, I was planning to have thing in their own project along with their unit tests and keep that physically in a shared code area (not user.lib) along side the projects that use this code. Then, in the main project, I would have virtual folders that point to the folder where the shared XML code is. I was mainly asking if all the class folders should be at the same physical directory level or if it was an ok practice to nest them (not by inheritance, but by some common area of responsibility, like dealing with XML or a database or an instrument). I prefer to limit the code in user.lib to reuse code that is very generic, like OpenG type stuff and to install it using packages only. Also, I prefer to not have anything in the dependencies other than vi.lib, user.lib and OS files (.NET DLLS). I make a virtual folder for everything else called external code or shared code so I can see that when looking at a project. The dependencies are just too out of sight, out of mind for me. -
Organizing your projects on disk
John Lokanis replied to John Lokanis's topic in Development Environment (IDE)
What about groups of classes? Like if you made several classes that deal with reading and writing XML. Would you put those into a separate folder under your classes folder in your project? -
I am looking into better ways to organize my project files on disk. The existing setup I have used for many years is not conductive to LVOOP classes or easy code reuse. So, I am looking for some 'best practices' information on how to layout my various project folders and organize the classes and VIs and support files within. I need to get this correct upfront before I start building and committing anything to SCC, as rearranging it later is a pain. I did some searches for information on this but came up empty. I am hoping someone can post their thoughts or a link to a good article or thread on this subject. thanks for any help, -John
-
Coordinating Actions Across a Network
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
Well, the only way for my 'server farm' to be aware of each other is to have this central coordination application that they can register with. If I do not implement that, then I cannot transfer data from one instance to another. This is not central to my overall goal of separating my view from the model and making my system 'client-server'. It just would have been a more flexible and 'clean' system if I could have decoupled this so asynchronous processes that needed to coordinate actions could live withing different app instances. Perhaps I will pursue this again in the future. Thanks everyone for the input. It was all helpful. -
Coordinating Actions Across a Network
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
Having a central server can lead to a single point of failure for the entire system. So, I think I may have to back off on this goal and do something more rudimentary, like having the coordination restricted to an app instance and not allow networked coordination. Since that solution already works well, I am inclined to stick with it. That just means my load balancing will have to be more granular and controlled at the client level and not by the server. And fail-over will not be a possibility. I think I can live with that more than I can live with the risk that all my systems go down if the single coordinating server goes down. -
Coordinating Actions Across a Network
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
I've never really used SVs before so I suppose I need to do some reading and experiments. But, the problem I need to solve is all the machines on the network will be siblings with no central server, so they all need to be servers to each other. I really want more of a peer-peer network where they can automatically find each other and coordinate. As to UDP, the solution has to be 100% bulletproof, so perhaps that is too risky. -
Coordinating Actions Across a Network
John Lokanis replied to John Lokanis's topic in Application Design & Architecture
The answer to #4 is yes, in one circumstance. I have other use cases as well but that is the basic one. So, it seems you are saying that using the low level UDP and TCP functions is the way to go, vs using some sort of share variables or network streams. I figured the network streams were the wrong path, but I was hoping there was a way to do this with shared variables. Since each machine will be running the LabVIEW Runtime, each one could host a shared variable. The question becomes: can I create and destroy these variable at runtime? Can others find them at runtime? If not, then your suggestion of using UDP and TCP seems like the only way. As for the number of systems, currently we can have up to 50 'siblings' using the same shared rendezvous at a time. And there could be 10s of these type of groups operating independently So, the code would need to be able to differentiate between these groups and allow a sibling to join the right group, without affecting the others. All machines would be on the same local private network, but not necessarily the same sub-net. There would no no firewall issues as this is a closed private network. To address the issue you listed, I would need to support a sibling leaving the group either in the controlled way or if it crashed, having timeouts to deal with that. I already do this in the code that uses queues to accomplish this. My biggest concern is how to broadcast a unique named connection and have others join that connection while ignoring other simultaneous broadcasts. -
I am designing a method for multiple application instances to coordinate an action across a network. I have previously implemented this using queues for coordination of asynchronous VIs within a single application instance. I now need to make this work across a local network. I have been looking at network shared variables, network streams, TCP/IP, UDP. I would like to know if anyone else has accomplished this and what you learned along the way. The basic requirements are: N number of independent applications need to coordinate some action (essentially a rendezvous). No one application knows if the others exist. (don't know their IP or anything about them) No one application knows if it will be the first to join or will join later. All applications will share a common name for the rendezvous. The first application should create the rendezvous As other join, they should see that the rendezvous already exists and join it instead of creating a new one. All applications should be able to see how many have joined. When all applications depart, the rendezvous should be destroyed by the last one to leave. Thanks for any tips or examples you can share. -John
-
Well given that this 'trick/feature' was used in the Core3 materials and WAS NOT EXPLAINED, it is going to lead to misuse and abuse. When my coworker asked me to explain it, I could not and told him he was right to think this was bad form. I prefer any such operation to be explicit. The implicit nature of this will lead to confusing bugs in the future.
-
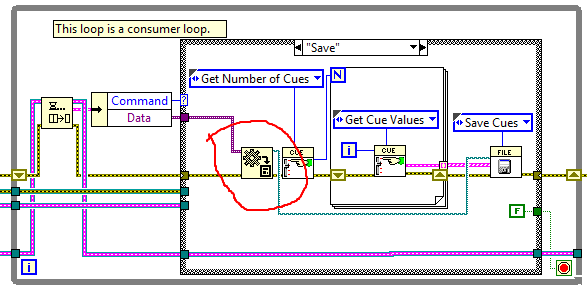
One of my minions is working thought the online Core3 course and showed me some code that made no sense to me. I am wondering it this is a bug or some little known feature. In the code, he was told to wire a variant to the 'variant to data' function and wire in a path constant so the output would be a path. This was later wired to a function needing a path input. So far so good. But later in the same code (in a different case) he was instructed to do the same thing but this time there was no input to the 'variant to data' function to tell it what to cast the variant data to. But for some reason, the output was still a path and he could still wire it to another function that needed a path as input. Here is a screen grab of the magical code: So, what is going on here? Bug?
-
One of my ideas finally made it to 'In Development'! WooHoo! http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Detect-runtime-installers-needed-for-installed-components/idi-p/960679