joerghampel
-
Posts
50 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by joerghampel
-
Yes, I was quite excited about that! But last time I checked, there was no way for private or local repositories. Is that still the case? Thanks for rephrasing. Yes, I think this is what I'm saying.
-
The second discussion started - again, with Fab - after James' and my presentation on Open Source and Inner Source with LabVIEW. With Github, for example, it seems rather easy to a) publish an open source project and b) contribute to it, once you've learned the very few steps needed to fork a repo and create a pull request. I have no idea how that aligns with what you guys have in mind, but it would be great if there was a way to combine the ease of use of existing platforms with a central repository of LabVIEW code and tools greatness.
-
The first discussion with Fab, Dani and Jerzy Kocerka was about where to keep the code. We quickly came to the conclusion that it would be great if GCentral did not host their own repositories on their own servers, but rather was able to tap into existing services like Github, Gitlab, Bitbucket and so on. That might also help with acceptance. Personally, I would like to keep our code in our own repos at gitlab.com. We have our readme's, our documentation platform, etc etc. But if there was an easy way to plug into the GCentral website of available code, I'd love to register our offerings (whatever that might be worth!) and see it featured there. And also the other way around: I'd like it if I could find not only properly packaged code from the three main repositories (VIPM, NIPM, GPM) on GCentral, but also other offerings in other formats. We like to keep as many dependencies as possible inside our project directories, so we work a lot with packages that are not installed via a package manager but either extracted/copied into the project directory or maybe sometimes linked as git submodules.
-
As a community member just wanting to drop my thoughts and ideas for further discussion, I want to give my feedback in a more colloquial way (hence I created this thread).
-
After discussing with some of the GCentral team and other community members at NIDays Europe in Munich yesterday, I would like to give feedback here so you guys can make of it what you will. Frankly, I didn't really understand that the "User Personas and User Stories" thread is meant for that - I wouldn't have looked into it if Fab had not pointed me towards it. I would like to suggest to rephrase the title of the feedback thread to something that is more easily understood by the majority of people, not only by the top notch of LabVIEW software developers. Moreover, I don't feel comfortable giving user stories for my feedback. That feels to me like phrasing requirements, and at this stage, I only have vague ideas. If those undeveloped musings are not of interest to you, then just ignore this 🙂
-

Where to start when LabVIEW Crash Reporter is displayed
joerghampel replied to takanoha's topic in LabVIEW General
To ensure NIER collects the most useful information, you need to set a few INI keys on the process that is executing the LabVIEW code (Development System: LabVIEW.ini in the LabVIEW directory; Run-Time Engine: in a [LVRT] section within the .ini file next to the executable). INI keys: NIERDumpType=full LVdebugKeys=True DWarnDialog=True DPrintfLogging=True promoteDWarnInternals=True Of these keys, you should always set the NIERDumpType=full key when debugging an issue, because this key will cause a larger crash dump with more debugging information to be created. The other INI keys can be used to gather more information, but they have the caveat that they will slow execution of the code down, which can be a problem for certain types of issues. It is also important to note that when NIER creates a full crash dump, it should not be submitted to NI through the NIER crash dialog. The NI system is not prepared to handle crash dumps as large as those generated by NIER with the INI key enabled. (I got this information from an NI support person long time ago, I'm not really sure if all of this still applies. But perhaps it helps?) -
database What Database Toolkit do you use?
joerghampel replied to drjdpowell's topic in Database and File IO
I've been using ADO.NET in the last years for Windows applications, and the NI DCT before that. I did one project on RT with the MySQL TCP connector, but as mentioned by @smithd it was difficult getting it to perform well enough. Recently, I've been working with SQLite (with your toolkit as well as directly using the DLL). Next will be to try and get SQLite running on real-time, on linux first, then Phar Lap and perhaps VxWorks - again like @smithd ;-) -
I'm using git, but all of my customers who go with SVN use the Tortoise SVN client and are happy with it.
-
Build Number
joerghampel replied to Neil Pate's topic in Application Builder, Installers and code distribution
Good point, Shaun. In fact, SingleBoard-RIOs made me think about generating a readme file, so that I could easily find out about the version of the application when connecting only via FTP. -
Build Number
joerghampel replied to Neil Pate's topic in Application Builder, Installers and code distribution
I agree with everything you write, hoovah. But ;-) Customers tend to copy directories and store and reuse projects from time to time. I don't see any reliable way to clearly identify one VI outside of version control other than writing some kind of identifier or history to the VI (be it block diagram, VI properties, front panel, whatever). -
Build Number
joerghampel replied to Neil Pate's topic in Application Builder, Installers and code distribution
I agree that the version information should be (at least also) stored in the .exe file properties, that's what I do as well. But: There is a good reason to store version info on the block diagram. Everybody can identify the version of the VI itself, not the executable, even if it's not under version control any more. I do have customers that don't use their own version control system, and I have no internet access to use mine. So, what I ended up with, is generating an .exe with my build script at the end of the work day, writing the version info also to the readme textfile (which might or might not get lost down the road) and to the block diagram of the main VI. Then I copy everything, take it home with me, and put it in my own version control system. -
Build Number
joerghampel replied to Neil Pate's topic in Application Builder, Installers and code distribution
I create tags for each build. That way, I have "names" for my releases, like for example "v1.2.3". You can easily automate the creation and publishing of tags from within a pre-build VI or a build script. This might help you with naming your installers? I also used to modify the source of a VI to store version information, and sometimes still do (it's an optional part of my build script now). What I like better, and what I do more often now, is create a text file which contains all sorts of information (kind of a readme file for the application). When run from an .exe, I read the version information from the .exe file properties and additional information from the readme file. When running the application from the development environment, I read version information only from this readme file. For libraries, I write the version information (the tag name) to the VI description, so that every VI can still be identified after release. PS: For my older projects, I do just as Thomas suggested: Modify the VI before executing the build spec, then revert afterwards. -
Build Number
joerghampel replied to Neil Pate's topic in Application Builder, Installers and code distribution
True that. Even before LV2014 and this very handy VI... It was the fact that you can't modify the version from the pre-build VI that made me look into automating the whole process. -
Build Number
joerghampel replied to Neil Pate's topic in Application Builder, Installers and code distribution
No need to get jealous. The whole process only works on some of my projects. With our own framework and reuse libraries, there's still some manual work involved, but it gets better all the time... I'm not ready yet to just share the whole code, but you can definitely PM me if you have any specific questions. -
Build Number
joerghampel replied to Neil Pate's topic in Application Builder, Installers and code distribution
LabVIEW 2014 also introduces a VI for editing the build spec version (which was possible before, but not as intuitive): Set Build Specification Version VI -
Build Number
joerghampel replied to Neil Pate's topic in Application Builder, Installers and code distribution
I'm using git, and because of its decentralized nature, there is no one incrementing commit number that I could put into the "build number" field. What I decided to do instead is: Create a tag in the VCS (which is just a named pointer to a commit) which is following the semver notation If building a Windows applicationWrite the tag info into the major / minor / patch fields of the build spec Write the build timestamp into the description field of the build spec If building a source distributionAppend tag label and build timestamp to each VI's description (so it shows up in context help) Automatically create a readme file that is distributed together with the built package (.zip in my case) that shows project name, version info, changelog (all commit messages since last tag) etc. After playing around with pre-build VIs for some time, I decided that I wanted more of a continuous integration type of tool / process, so I started automating the whole build process (I wrote about that here, amongst other places). Executing a build specification has always the purpose of releasing an application or source distribution. So I made the creation of the tag in the VCS the starting point of my build process (my gitlab repository will then trigger a Jenkins task on my local build server, but manually invoking the build tool does just the same). The build tool will first check the working copy for changes (or rather, the absence of any), then run some VI analyzer tests, read the tag name associated to the latest commit, update the build spec fields and/or VI descriptions, create the readme file, execute the build spec, create the release package (.zip), and copy that package to a local directory which is synchronized with my web server. I run Dokuwiki and created a plugin that uses the gitlab API to read all tag labels for a given repository, and then automatically displays all available files for that tag label as download links. -
I haven't used this VI much myself. I agree that name conflicts are the most obvious reason for wiring an application instance. Also, it probably won't work in the Run-Time Engine. And if you call it from the Tools menu, you might or might not want it to run in that application instance (NI.LV.Dialog). Perhaps someone else with more experience can chime in?
-
You can read up about application instances here. If you don't wire the terminal, it most probably uses the instance of your calling VI.
-
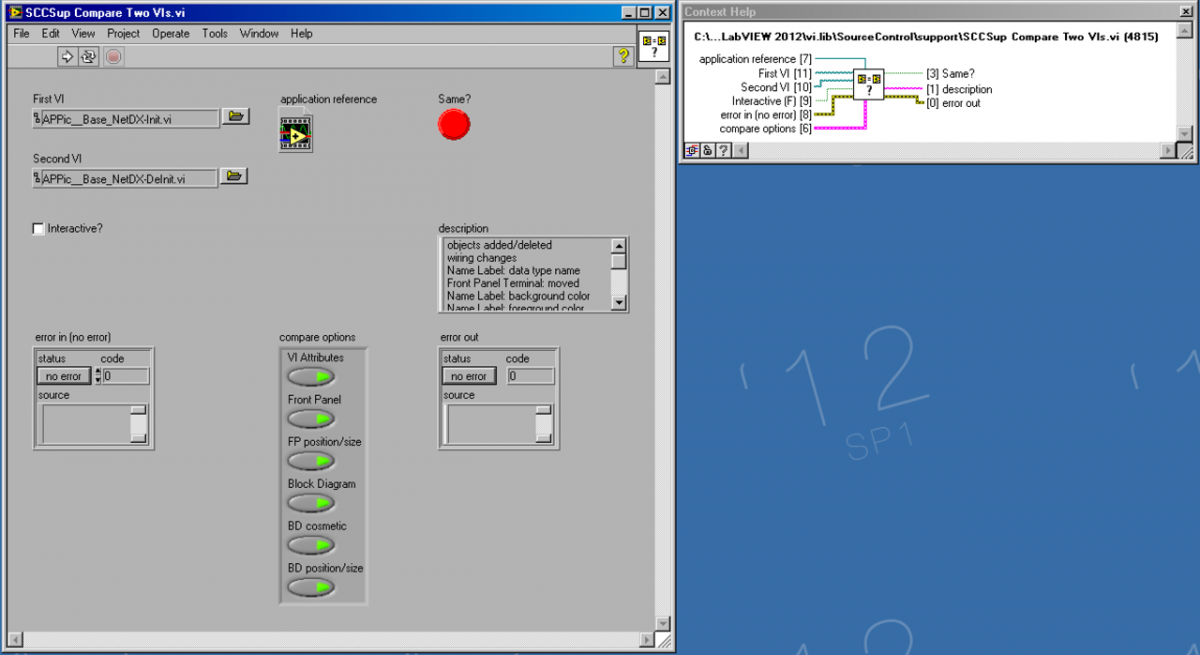
\vi.lib\SourceControl\support\SCCSup Compare Two VIs.vi seems to do what you ask for (see screenshot).

-
With the last post being nearly 5 years old, perhaps someone has found a ways to achieve something like this? I'm using vi.lib\AppBuilder\AB_API_Simple\Build.vi for programmatically building stuff, and I'd really like the possibility to register for a user event, similar to the NI System Configuration Toolkit (vi.lib\nisyscfg\Register User Event.vi). (cross-posted here)
-
Get all installed LabVIEW Versions
joerghampel replied to QueueYueue's topic in Development Environment (IDE)
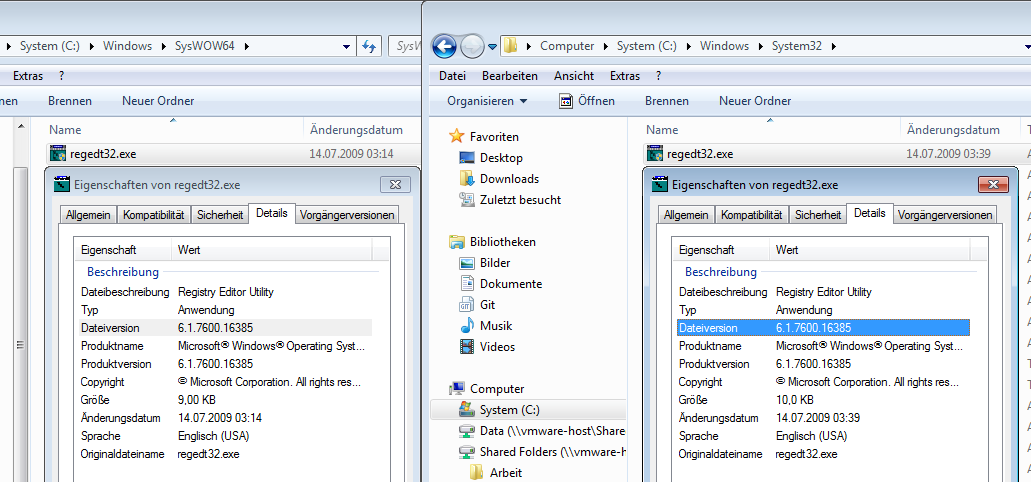
For future reference: Don't use the 64 bit version of the registry editor if you want to see entries for 32 bit applications (I tripped over the same thing some time ago with the ODBC Manager). 64 bit: C:\Windows\system32\regedit32.exe 32 bit: C:\Windows\SysWOW64\regedit32.exe Really, Microsoft?
-
Get all installed LabVIEW Versions
joerghampel replied to QueueYueue's topic in Development Environment (IDE)
If you're working in Windows XP, you might want to try the registry (Source: http://digital.ni.com/public.nsf/allkb/DEDEC3074C17323086256A29005BC543): For Windows 7, I just had a look and couldn't find the information at the same keys? Edit: Wow, only two hours on the phone with a customer while in the middle of typing, and the answer's posted... -
I've been using gitlab for some time now (hosted on gitlab.com), and mentioned it just a few days ago here and also on the NI LAF. Although I'm still far from 100% build automation, I can happily share my experiences so far. FYI: Some of my process and structure decisions are due to the fact that I'm a 100% Apple guy, working on Apple computers. As all of my customers are using Windows, I do the LabVIEW programming itself in VMware virtual machines. I try to keep these Windows machines disconnected from the internet to keep things simple and secure. The directories containing the LabVIEW projects are accessible both from Windows and Mac OS. Now, back to the topic: Gitlab itself is great IMHO. I chose it for its web interface, its integrated issue tracker and its API (which I use to connect from my Dokuwiki), and all of that is working very well for me. I use the Tower Git Client in Mac OS for pushing/pulling/publishing. In Windows, I use the git binaries, calling them automatically from LabVIEW build scripts. Concerning the continuous integration: I have a Jenkins CI server running on Mac OS The Gitlab CI service seems to work best for me for triggering the Jenkins server. I've also tried web hooks and the Jenkins CI service, with varying results. As to the periodicity, I'm still running the build scripts manually for most of my customer projects. For some internal tools (our "products"), I configured gitlab to trigger the Jenkins server whenever I pu(bli)sh a new tag. Jenkins then in turn calls the same build scripts automatically that I run manually - more or less ;-) As mentioned above, my working environment doesn't allow Windows to connect to the internet, so I have configured Jenkins as a Master/Slave system, with the master running on Mac OS, and the slaves running inside the Windows virtual machineThe master pulls the latest revision from gitlab.com, to a directory that is accessible from the slave in Windows As a post-build action, the master calls a job that is configured to be executed on the slave, running the actual LabVIEW build script ("Execute Windows Batch Command" in Jenkins) The build script runs some VI Analyzer tests, handles tag / version numbers, modifies the build spec to have the version information in the .exe, and does a bit of other fancy stuff.You may want to take a look at the VeriStand Jenkins-Autobuild Add-On which Stephen Barrett shared / point me to. ​All of the above works quite well already. What's next on my agenda is to get the build result (most of the times a .zip archive, created by the build script) to our release server via FTP. This would have to be another post-build action, as it has to be executed by the master. Also, what I'm still very unclear about is how to best do automatic builds for different LabVIEW versions when having source distributed libraries without block diagram in a project.
-
I used to work with subversion before I started programming in LabVIEW, and it worked very well for me. With LabVIEW, we did and still do a lot of off-line, on-site work together with our customers, and I tried to introduce them to subversion. However, we never managed to get our customers to accept it. Many of them couldn't even get around the point that there are a lot of hidden .svn folders, and there was a lot of export/import activities, so we finally abandoned it. Recently, we started using git (hosted on gitlab.com), and together with the Tower GUI (www.git-tower.com) it does really work like a charm for us. Agreed, merging still doesn't work the way one would expect (or hope), but that was no more or less true for subversion, at least for me. Installation at the customer site (SourceTree) is also a big pita, but it's doable. On a sidenote, Gitlab offers some additional benefits for me: - Integrated issue tracker & API access: I created a Dokuwiki plugin that shows certain issues within a customers' namespace in our Dokuwiki which makes issue tracking much more usable for my customers - Release management & API access: I created another Dokuwiki plugin that shows the available tags (and related download packages on our webserver), again within a customers' namespace in Dokuwiki, which standardizes and automates software releases and makes it quite easy for my customers to find the latest version - Continuous Integration: Gitlab commit hooks trigger a Jenkins server to execute build specifications All of those things are most certainly available for any given (D)VCS, and/or can be achieved in other ways. Still: For us it's a nice package.
-
Build Scripts
joerghampel replied to Daklu's topic in Application Builder, Installers and code distribution
With LabVIEW 2013 and LabVIEW 2014, it seems that the tag names have changed again: Bld_version.major Bld_version.minor Bld_version.patch Bld_version.build