
JKSH
-
Posts
497 -
Joined
-
Last visited
-
Days Won
36
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by JKSH
-
-
I would even suggest to remove this post. The list of potential actual exams shouldn't be posted anywhere.
It's fine; NI themselves published the list: http://download.ni.com/evaluation/certification/cld/cld_exam_prep_guide_english.pdf
-
Congratulations!

-
LabVIEW draws its controls, menus and most anything including the scrollbars itself in an attempt to provide a multiplattform experience that looks and behaves everywhere as much as possible the same. One of the only things where it relays heavily on the platform itself are fonts.
Do you know if LabVIEW do this for OS X menubars too? These are meant to be attached to the top of the screen, not to the application window itself (even some Linux distros follow this style).
-
On the other hand, `PostLVUserEvent()` will synchronously block until the Callback VI handler has finished executing.
TIL... this is an eye-opener. Thanks!
(Is this documented anywhere, by the way?)
-
One thing that helps is as you already noticed, writing chunks of data. Basically calling the Write function as few times as possible. If you are getting samples one at a time, put it into a buffer, then write when you have X samples. Got Y channels of the same data type which get new data at the same rate? Try writing X samples for Y channels in a 2D array. I think writing all the data in one group at a time helps too but again that might have been a flawed test of mine. I think it made for fragmented data, alternating between writing in multiple groups.
You're right, writing in chunks reduces fragmentation and improves read/write performance.
However, you can let TDMS driver handle this for you instead of writing your own buffer code:
-
Any suggestions for Chrome?
Unfortunately not... I use DownThemAll on Firefox.
-
Yeah I want to try and use FTP to download things like DAQmx without having to go through the NI downloader
NI's website provides a direct download too, bypassing the NI Downloader. For example, go to http://www.ni.com/download/ni-daqmx-15.0.1/5353/en/ and look for "Standard Download". Funnily enough, it links to "support/softlib" via HTTP: http://ftp.ni.com/support/softlib/multifunction_daq/nidaqmx/15.0.1/NIDAQ1501f3.exe
I like to Google for the version I want, and then use a download accelerator on the direct download.
Google's search operators make it easy to find things (no need navigate the folder hierarchy). For example, type "site:ni.com/download DAQmx" or "site:ni.com/download DAQmx 15" into Google and see what you get.
-
The only improvement I can suggest is to use the VI Name instead of VI Path. If you're attempting to use this on a VI that hasn't been saved yet, obviously the path will return not a path. The VI Name works because the VI is already in memory, it has to be because it is a dependency of the calling VI when you put down the static VI reference.
Ooh, is it possible to obtain a VI reference by its name? Open VI Reference has "VI Path" as a compulsory input (and no VI name input)
-
Hi all,
If I pass a static VI reference straight into Start Asynchronous Call, I get Error 1576: A Start Asynchronous Call node received a reference input that was not configured to allow asynchronous calls.
The documentation says that the reference must be "'prepared for asynchronous execution by the Open VI Reference function using either the 0x80 or 0x100 option flag". The simplest way to accomplish this (that I could find) is to first get the path from the static reference and then use that to open a new dynamic reference:
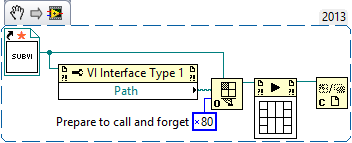
That works, but feels a bit clunky. I don't suppose there's a way to apply the option flag directly onto the original static reference?
-
Hi all,
I know that separating compiled code from source is good for a project that's in development, as it avoids the need to re-save every other VI in the project after one small change. That makes source control much saner.
What about code libraries that are distributed to other developers though (e.g. through VIPM)? The user of the library wouldn't (shouldn't) modify the library VIs, so the previous reasoning no longer applies. Is there a good reason to enforce separation (or enforce non-separation)?
-
Does anyone have a separate reliable program that converts an mp3 file to a wav file?
See hooovahh's post above.
-
 1
1
-
-
I upgraded my home PC (not my work PC yet) to Windows 10, and it's been a good experience so far except for a small annoyance with mouse wheels in LabVIEW: https://lavag.org/topic/19185-scroll-wheel-not-working-windows-10-labview-2015-parallels-vm/#entry115740
The start menu behaviour annoyed me so I installed Start10 which makes it behave more like a hybrid of Windows 7 (which I thought worked quite well) and Win 10. You can pin as normal, I have multiple versions of LabVIEW pinned.
I pin my frequently used apps to the Taskbar (one less click to open, compared to pinning to the start menu). For everything else, I treat it like LabVIEW Quick Drop: [Windows] + [First Few Letters of App Name] + [Enter]
-
Correct!

More specifically, I switched the "bounds" properties of the two input terminals.
Please ensure that your genetically-modified nodes don't escape into the wild!

-
I upgraded from Windows 8.1 to Windows 10, and noticed that my mouse wheel no longer scrolls combo boxes (text rings). I can still use it to scroll my front panels, front panel arrays, and block diagrams though.
Running LabVIEW 2013 on a physical machine, not a VM.
-
I'm guessing h
I guess you are right, however the wires are not wired around, the Subtract function is actually flipped horizontally
 :
:I'm still trying to figgure out how you did that, flarn2006...
Please tell me if it is not possible from within LabVIEW or I die before solving this

I'm guessing he used his backdoor VI editor (https://lavag.org/topic/19178-low-level-vi-data-editor-warning-not-for-production-use/) to create a mutant subtract node

-
2
-
-
:-S What did you DO to the subtract node?!
-
1
-
-
In the seven or so years I have been dabbling with LVOOP not once have I said, "gee I am so glad that a class maintains its mutation history". Maybe it's just the kind of applications I develop, dunno. I never serialise my classes directly to disk.
I've dabbled for about 1 year, and I haven't
neededwanted mutation history either. I have a VI that recurses through my project folders, stripping out all mutation history before I commit my files into source control.The current serialization system needs a major overhaul; AristosQueue has a side project to improve it: https://decibel.ni.com/content/docs/DOC-24015
-
The LVClass remembers its previous states in its Mutation History. If I'm not mistaken, NI designed this to help VIs that use your class to adapt to the newer version.
There is currently no way to delete mutation history via the LabVIEW IDE itself. Your options are:
- Delete it from the *.lvclass file directly (it's an XML file): See http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Add-right-click-option-to-delete-class-mutation-history/idi-p/2594921
- Use these NI-created VIs to delete the history: http://digital.ni.com/public.nsf/allkb/F0FC362A73C794BA86257C6700692B0B
-
That method will only work if I have that specific (And a few more cases) of rows/columns in the array.
I would like to find a method that would work regardless of the number of rows/columns.
That technique works for all numbers of rows and columns.
(Row Size) x (Column Size) = (Number of Elements in the 2D Array)
If the array contents was:
elephant crow dog goat seal
giraffe eagle cat fly Panda
ant pig horse bee crocodile
then multiplying the row size by the column size would not get me the linear element of crocodile, which would be 14
Do you want to start counting from 1 or 0?
- If you count from 1, then the last "index" is (Number of Elements in the 2D Array)
- If you count from 0, then the last "index" is (Number of Elements in the 2D Array)-1
Try it for different array sizes. You'll see that it always works.
-
Is there still any way to get 11 or 12 from that 2d array?
I can think of one way, using a for loop and then iterating until the end of array becomes true, and then storing that iteration outside the for loop, at least I think that will work, but I would think there would be a better way of doing it
Use the Array Size Function, and then multiply (Row Size) x (Column Size).
-
Hi,
Unlike MATLAB, LabVIEW does not use linear indexing. Since you have a 2D array, each element is indexed using 2 numbers (think of it as the row number and column number). Also, LabVIEW's indexing starts from 0.
So, the index of "bee" is (2, 3), not 11 or 12.
You can use the Array Size Function to find the dimensions of the array (3x4), and then subtract 1 from each element to get (2, 3).
-
On the computer, access to the shared variable via a shared variable node and programmatic access both work. On the cRIO, access to the shared variable via a shared variable node is functional, but programmatic access to the shared variable does not work.
I wonder if it's a race condition, since you are accessing the same variable in two places in your diagram. I'm also wondering if something got corrupted.
- What happens if you delete the SV node from your block diagram?
- What happens if you try to write to the variable without opening a connection?
- Right-click the SV node and select "Replace with Programmatic Access". Does this one work?
- What happens if you undeploy everything from your cRIO, and then deploy the variables again?
- What happens if you undeploy everything from your cRIO, and then create a new project with new variables?
- (Drastic measures) What happens if you reformat your cRIO, install your software from scratch, and try again?
-
Your code reads it row by row. I want to read it column by column.
ensegre has given you a good starting point. Would you like to try modifying his code to match what you want?
-
I think it is better to use DSNewHClr, that correctly initialized the handles to nullptr. It feels much safer, so all the if(*ptr) have predictible result.
Sounds good
Happy coding!
SCC & Libraries
in Source Code Control
Posted · Edited by JKSH
Yep, one repo per library sounds good.
This is a valid solution. It's called "bundled libraries". It works for tiny libraries, where creating release packages (described below) might be an overkill.
(I personally don't like bundled libraries because the duplication can make things messy in the long run, but it works)
user.lib was designed precisely for this purpose.
The fact that the project devs "need to know to check out the dependent libraries" should not be considered a disadvantage. After all, a project's dependencies should be part of the project documentation.
Again, I would not make individual revisions accessible. Project devs should only be allowed to choose from the (small) set of stable releases.
Furthermore, a mature library should ideally have a stable Application Programming Interface (API). Newer versions should aim to avoid changes that break compatibility with older versions. This way, you don't need to worry about juggling multiple versions -- just install the latest stable version.
Exceptions to the "minimize compatibility breaks" rule are: