Taylorh140
-
Posts
97 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Taylorh140
-
So I have a serious question. Does LabVIEW have a way (built in or library) of calculating the next larger or next smaller floating point value. C standard library "math.h" has two functions: nextafter, and nexttowards. I have put together a c function: that seems to do the trick nicely for single floats (well only for stepup): #include <math.h> #include <stdint.h> uint32_t nextUpFloat(uint32_t v){ uint32_t sign; = v&0x80000000; if (v==0x80000000||v==0){ //For zero and neg zero return 1; } if ((v>=0x7F800000 && v<0x80000000)||(v>0xff800000)){ //Check for Inf and NAN return v; //no higher value in these cases. } sign = v&0x80000000; //Get sign bit v&=0x7FFFFFFF; //strip sign bit if(sign==0){ v++; }else{ v--; } v=v|sign; //re merge sign return v; } I could put this in labVIEW, but these things are tricky and there are some unexpected cases. So its always better to use a reference.
-
@hooovahh I have to agree, some UI's just do fancy things, and I am a sucker for a good looking UI. Keeping them synchronized with scrolling can definitely be a challenge. (Mouse Move and Wheel Scroll event update like crazy, Do you Limit the maximum events?) Let me know if you find a perfect way to handle scroll synchronization. I've used the picture control in the past to draw run-time configurable controls. It can be a resource hog if not carefully pruned. (I always hear about how the picture control is so fast and lean, but In my experience its only true for simple items with only a few <100 draw instructions.) So many UI things. It is usually the most time consuming part. (for the people and the CPU)

-
@LogMAN Good basic info. I think perhaps the biggest item on that list against property nodes was: Negatives Required to update the front panel item every single time they are called. But this is the same as a changing value. And Dereferences would be hardly noticeable as a speed impact. I think there is more here than the kb lets on.
-
So, for me it is not just about response time. but CPU usage. We do development on laptops and keeping things below 10% usually prevent the fan from turning on. for some reason using property nodes to do things is very cpu intensive. It is curious to me that the property node takes so much effort to get things working. Changing property node use (in my case) brought cpu usage from 16-21% down to around 0.2-1.0% I believe the LabVIEW UI is based on an older version of Qt. (i might be wrong), which is a retained mode GUI. I theorize the cost of setting UI properties is that they are expected to be immediately present on the User interface. theorizing again that it could be possible to access a retained property and have much lower cost to this method of UI update. But, ehh old UI's don't change easy, and I'm sure they have good reasons for picking the things they do. The hard part for me is that it is hard to make educated decisions on how to interact with UI elements. Strange caveats exist, like @mcduff explained above. It would be interested if there is somewhere more of the caveats are collected.
-
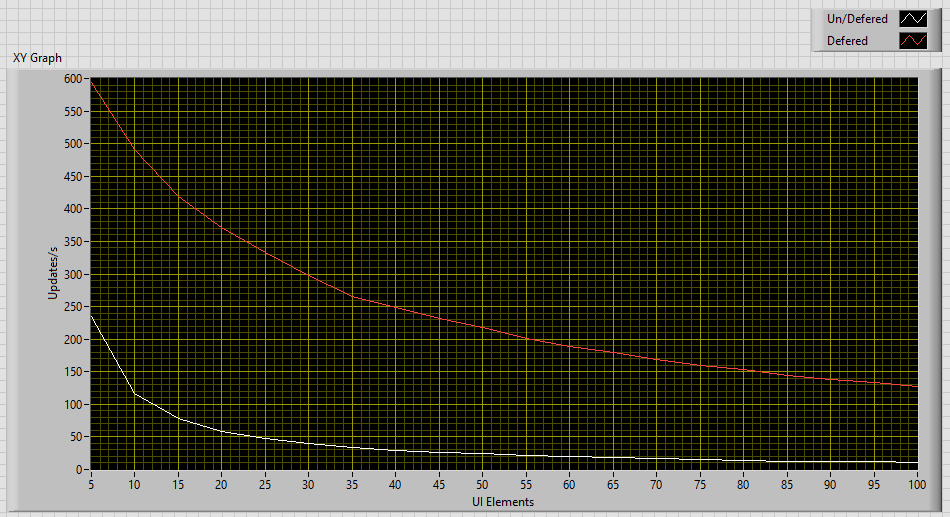
So i took, some time to do some research here. I believe my method will have to be reviewed for fairness. So ill upload the two VIs i used. It looks to me that if you have less than 10 elements update on average. than you'll probably get decent performance. but after looking at this i would probably recommend always deferring front panel updates, if managing property nodes in any way. MethodPerformance.vi TestRunner.vi
-
So, I wanted to get an opinion here? I'm Pulling new values in from a device, and have UI elements change color depending on their value. This is of course done through property nodes. My question is what is better: A. Updating UI element only on value change (checking for value changes) B. Updating all UI elements all at once within a Defer front panel updates segment? ( and not checking for value changes) Thats all.
-
 Could you save for previous verison of LabVIEW, maybe I'm slow but I'm still back in 2017.
Could you save for previous verison of LabVIEW, maybe I'm slow but I'm still back in 2017. -
Started some work on a simple C code generator for LabVIEW. https://github.com/taylorh140/LabVIEWCGen I was working on some ideas to handle some more complex Items. Had some thought about using https://github.com/rxi/vec To handle strings and other arrays/vectors, I would like to pass these more complex data types by pointer. However I am looking for some ideas as to when to make a copy. I know LabVIEW has some internal item that manages this but I haven't found a way of accessing it quite yet. Let me know if you think this is worth some effort. Or if you have any ideas about the architecture that you think would be helpful. Also i imagine that this will still only ever support a small subset of LabVIEW, the languages are quite a bit different, and i prefer that the code be as clean as possible.
-
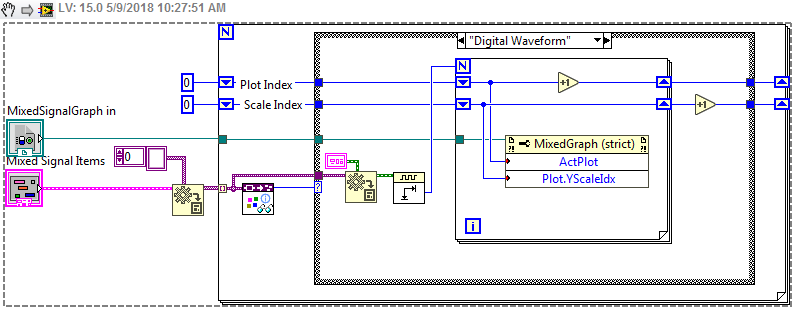
I found some information on how to set the group. Since the input types could change it would be good to auto configure the types based on the inputs to the mixed signal graph. I have a basic configuration VI that should do the trick in most cases. It iterates through the cluster items on the input type and based on the types sets the group by setting the Plot.YScaleIdx of the active plot(it also sets the active plot). It does assume that input arrays will be xy time data in the format: 1D array of (cluster of two elements(1D array of Timestamp),(1D array of double)) //because why wouldn't it? AutoGroupInputs.vi
-
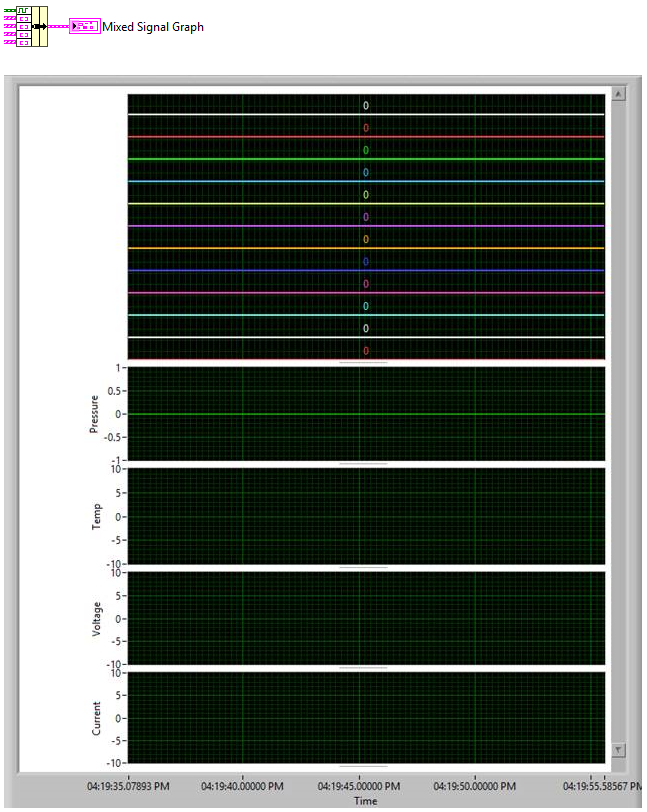
I am trying to use a mixed signal graph to plot a set of digital data (12 lines) and 4 arrays of analog data in XY format. For the analog data I want each array to be assigned to a different group in the graph, but at runtime they seem to all default to Group 1 (the Pressure graph shown below). I have been able to change them using the legend or the graph properties for each plot, but cannot find a way to do it programmatically. Is there a property node that can be used to set this?
-
Opinions on the CVT Client Communication (CCC) Reference Library?
Taylorh140 replied to drjdpowell's topic in LabVIEW General
I just installed DCAF through the VIPM. Interestingly enough it uses the NI Current Value Table as a dependency. So maybe there is no worries after all to your initial post.
-
Opinions on the CVT Client Communication (CCC) Reference Library?
Taylorh140 replied to drjdpowell's topic in LabVIEW General
Is it just me or is NI really bad at actually describing what their products do? I had no Idea that DCAF even fell in the same realm of function as CVT. I thought it was some kind of generic configuration distribution tool thing. I have mixed guess about the variant support, on one hand its nice to know the specific type (of course you could query this with variants), they use variant attributes for the back end so i don't see any reason they the couldn't have included them. -
Actually the fact that the data is a string of commands makes a lot of sense. When I did not use smooth display I saw the individual elements being drawn even when i had Front panel updates defered. Since i Used bunches of static text I decided to only draw it the first time. by using the erase first and setting the value to 2(erase every time) and then to 0(Never erase). I tried to use the 1 setting (erase first time) but it always erased the stuff i wanted to draw the first time. I notice that if i use a sub-VI to do operations like erase first and such that it didn't propagate up a level and the same operations needed to be done on the top level picture control. After those things I went from 30 fps to 120 fps which i find more acceptable. The control only used the Picture Palette drawing functions and looked somewhat like the image attached except with real information:
-
I have never gotten the performance that I desire out of the 2D picture control. I always think that it should be cheaper than using controls since they don't have to handle user inputs and click events etc. But they always seem to be slower. I was wondering if any of the wizards out there had any 2d picture control performance tips that could help me out? Some things that come to mind as far as questions go: Is the conversion to from pixmap to/from picture costly? Why does the picture control behave poorly when in a Shift register? What do the Erase first settings cost performance wise? Anything you can think of that are bad ideas with picture controls? Anything you can think of that is generally a good idea with picture controls?
-
I typically view the conditional disable as a different kind of item. Not really that different from a case structure with a global written to the conditional terminal. Run this code or that code depending on the configuration of the system. But code is still run on the production environment. This idea is a bit different because the code is run only on the development environment. The idea is in some ways a very convenient prebuild step. Also it increases consistency. Why do prebuild on pc and vi memory initization on FPGA when you could do it in a uniform fashion. Why not use LabVIEW as its own pre-processor? Value would be for things like reading configuration files from the development PC, that i don't want editable in production. Easily Labeling the front panels SVN REV and build time. Perhaps event reducing startup time for LV apps by preprocessing startup code. To me I feel like this would be a great additional structure. I do appreciate your thoughts on the topic, thanks.
-
I posted This on the Idea exchange a few days ago. I have been wondering why no-one sees the need for constant generation at compile time. I think this would be especially useful in FPGA, but also for constants that need data from the build environment. Perhaps there is just a better way of doing these types of operations? Let me know what you think?
-
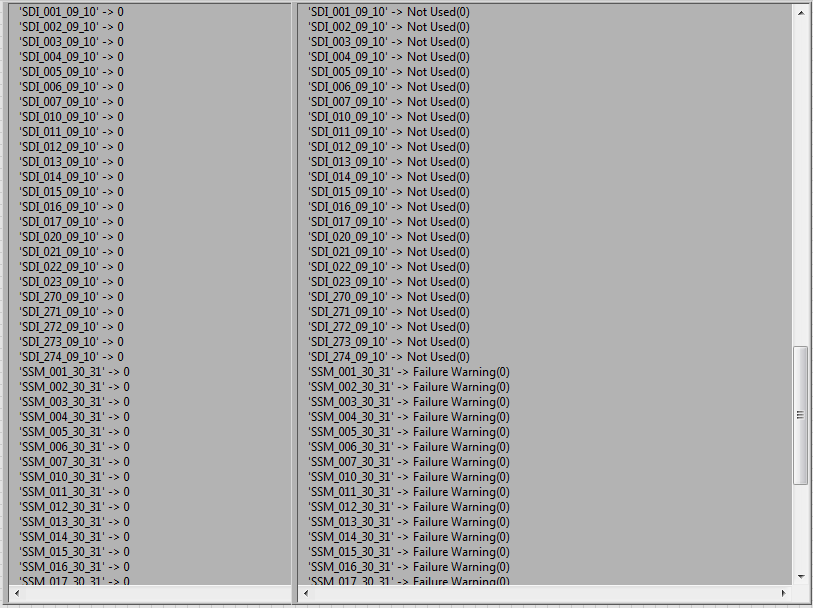
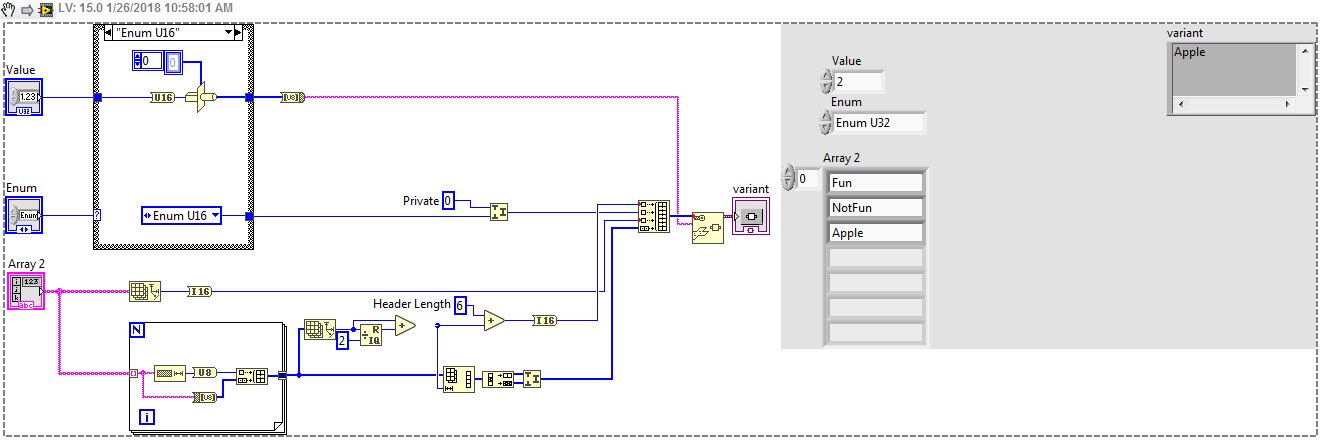
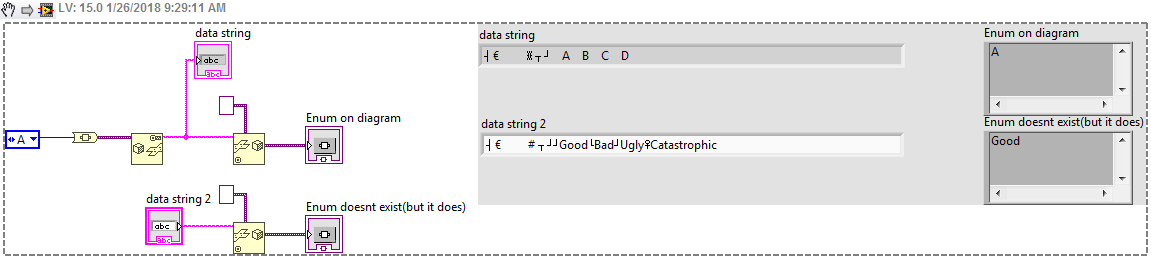
Yeah, I was actually doing the opposite. Using an array of strings and a value generating a enum at runtime. I was afraid what i was trying to do might be confusing. I might be getting encoded data from a device and to decode it instead of using a cluster (which contains a great deal of useful information apart from the values) using variant attributes. Since the specification is sometimes in a document it is easier to pull from that source as apposed to decoding everything using LV wires and clusters. However when looking at variant attributes especially for enumerations its hard to see what the value actually means. this allows me to have a probe view of the data that looks like the right as apposed to the left.
-
I So it wasn't so bad to put this together. I hope it ends up being useful! Variant_Scoped_Enum.vi
-
So sometimes when you do protocol decoding it is convenient to use a variant to store decoded data. For example you might have a 2 bit enumeration that is decoded like this: 00 -> Good 01 -> Bad 10 -> Ugly 11 -> Catastrophic If you cast the value to an enumeration that contains these values before hand you can see them on the variant control. If you use a Ring you will only see a value. I know that the LV flatten to string contains the enumeration strings but the encoding is a bit of a mystery, although it looks like the openg palette has figured some of it out to some degree. But to me it doesn't look like there is any reason i couldn't generate an enum to use inside the scope of a variant. Has anyone done this, or know how to generate the string for this purpose.
-
Start LabVIEW exe in background without stealing focus
Taylorh140 replied to Taylorh140's topic in LabVIEW General
I found this gem! Strange that that isn't the recommended setting in the tutorial. http://digital.ni.com/public.nsf/allkb/4A8B626B55B96C248625796000569FA9- 1 reply
-
- 3
-

-
I am attempting to use a LabVIEW executable as a background service. I had two good pieces of information from these sources: http://digital.ni.com/public.nsf/allkb/4A8B626B55B96C248625796000569FA9 http://digital.ni.com/public.nsf/allkb/EFEAE56A94A007D586256EF3006E258B And now the window does not flicker or appear really at all, also it doesn't show up on the task bar. However IT STEALS FOCUS from other applications when it starts. This interrupts data entry. I am using some .net code to start up my processes (I was hoping that this would do most of the work for me) I was curious if anyone had any other suggestions?
-
I see what your saying now. When looking at a single ASCII character it would make sense to include the last point just like they do with integers. however there is not a character type only a character array type (string), and in an effort to make the case statement ranges more useful in the string realm they made a notation that is essentially a begins with function. (regex would probably be more useful/but slightly slower). This does explain it a bit though. @ShaunR I am also glad it is not C++.
-
Absolutely, I find it weird. It doesn't match the Integer notation and even more so it includes the first item but not the last. I was using to match numeric 0-9 which yes you could use a regex but its a range 0-9 simple case statement should work. its weird to put "0"..":" I had to reference my ASCII table just to know which one to use. And I do agree it is stated in the reference above, but I generally dislike inconsistency especially with logical concepts that should be transferable; just because something is known doesn't mean it cannot be incorrectly inferred or forgotten. That being said, I would really like to know the rationale, however if there has to be a discussion it doesn't bode well for the "feature".
-
I noticed something inconsistent today with case selector, specifically the inclusion of the sequence terminators. Guess the outputs for Q1-4. The purpose of this post is mostly to help others not make this (seemly easy) mistake. Also to ask how is this discrepancy useful?
-
So I did a quick run, and I probably need to state that the above methods cannot really be compared apples to apples. Partially for the following reasons: Some methods only support one element at a time input. If you need to enter 1000 pts at once these methods will probably be slower and involve more operations. Some methods like the circular buffer are much more useful in certain situations like where the buffer is needed in different loops or are acquired at different rates. here are numbers for single point(one element at a time) inputs: How long does it take to process 10000 input samples with a buffer size of 1000 on my computer?: Taylorh140 => 8.28579 ms infinitenothing => 2.99063 ms (looks like shifting wins) Data Queue Pt-by-pt => 9.03695 ms (I expected that this would beat mine) hooovahh Circular Buffer => 8.7936 ms (Nearly as good as mine and uses DVR) I would consider all these to be winners, except maybe the Data Queue pt-by-pt (but it is available by default which gives it a slight edge), Perhaps ill have to do another test where inputs are more than one sample. Note: if you want to try the source you'll need the circular buffer xnodes installed. buffer.zip