Christian Butcher
-
Posts
24 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Christian Butcher
-
KJK@GPower reports on the NI Forums (link unavailable without tech preview, but posting here because largely unrelated to tech preview and so perhaps not covered by non-disclosure?) that: "I know that the GCentral will be the place to go for finding reuse code what I'm not sure about is if there will be an active forum where [users] can get help and support from the G-Community." So perhaps: As a user of GCentral, I (might, if I were KJK@GPower, or the person they responded to) want to discuss using a package with the creator of that package (and/or other users) via a discussion page or forum system.
-
Relating to this, as a developer who might use open source code, I would like to be able to avoid installing (potentially obscure) test frameworks and similar to test code that I for whatever reason (author, company, etc) implicitly trust. I suspect this has a lot more to do with the packaging chosen though, and may not be easily manipulated by GCentral...
-
As a user with a CI-system based on building my packages, I want to be able to programmatically update the package version on GCentral (or notify of a new package, or however this might work). This might involve something like a POST request.
-
As a developer working on multiple machines, I'd like to be able to save a (personal) configuration file of "IDE-improvement" style packages to install on every machine.
-
Thanks for the quick response - sorry I didn't see this straight away. I've implemented something a little like your first suggestion: I now have DiskLoggerTestSuite -> LoggingSharedTestCase -> PathGenTestCase (this is another shared component used by the logging classes and then DiskLoggerTypeATestSuite -> DiskLoggerTestCase DiskLoggerTypeBTestSuite -> DiskLoggerTestCase with the case shared between multiple suites. I need to create a new suite for a new class to test, but the suite is fairly simple and so quick to create. At present, I have an ugly setUp for my DiskLoggerTestSuite (the shared code suite) since I'm writing a directory to private data of each TestCase, but adding in inheritance for these cases would solve that problem very easily (and I'll presumably do that next time I need to add something, or when I rework this project a bit more). I'm holding off only because of a blog post I read regarding malleable VIs in 2017 SP1 and the possibility of matching without inheritance (but I'll have to wait and see there). Thanks for your thoughts on this - I'll no doubt reference it again next time I stumble into this issue and hopefully can take your advice to heart a little more fully.

-
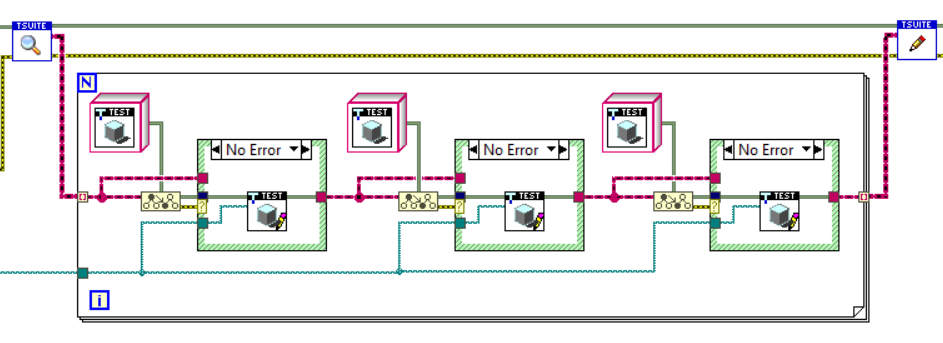
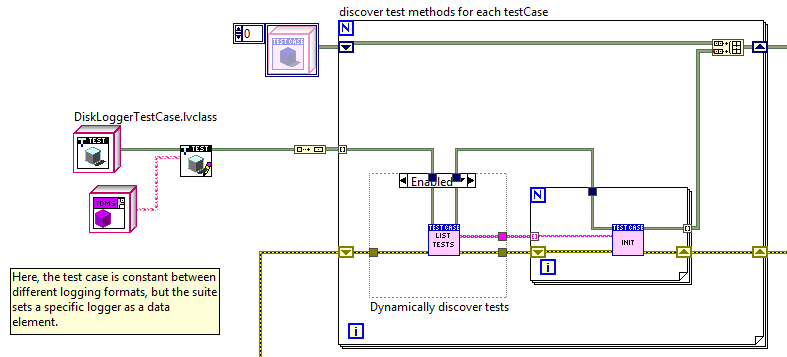
Hi, I'm writing unit tests for some logging code (OK... so I suppose testing the actual logging class would be integration testing, but...) and have (at present) two disk logging classes and an in-memory test implementation. My test suite/case arrangement is currently a bit of a mess (understatement) and what I really want to do is run the same set of tests using each logging implementation. Obviously I don't want to code up the same tests repeatedly (and have to maintain a set of multiples). The solution as I understand it is to store a class object of the type to test in either the Suite or the Case (or both?) and then always read from private data when running a test. Writing the individual tests in this way is fine. My confusion lies in the best way to arrange the Suites and Cases to do this. In particular, if I have some DiskLoggerTestCase containing a collection of tests (for simplicity, all of my tests) and with the Logger object as private data of the Case, then I can create a Suite with code like below in New.vi (duplicatedCasePerSuite.png). Here, I build an array of each Logging object, then use a Write accessor and an autoindexing For loop to build the Suite. Problem: In the VI Tester UI, I see "DiskLoggerTestSuite:DiskLoggerTestCase, DiskLoggerTestSuite:DiskLoggerTestCase". There appears to be no way to distinguish or add names separately (if this is incorrect, I'd love to know how to change it). My second attempt (SuitePerImplementation.png) was to create a new Suite for the single TestCase, with each suite having a new name but the same TestCase (and using the write accessor, without a For loop). This works out, but means I now need to create a new suite for each additional implementation. It's not so terrible, but changes have to be reproduced in each suite if I want to modify something. Further, if I have more than one TestCase, it isn't possible to place them in a loop without reorganising them to inherit from a shared class providing the "Write Logging Object" VI as Dynamic Dispatch. Adding cases that don't use this require a new loop to discover their test methods. Duplicate code again rears its head. My next attempt will be to create one Suite of TestCases, in which the Suite has a Logging object, and it passes the object to the necessary cases, whilst allowing me to then create a set of owning Suites that each contain the first Suite. This is probably more or less the same as the second approach, but should at least compartmentalise some of the changes needed when adding Test Cases and separate adding Test Cases (change to the first Suite) from adding implementations (add a new Suite of the second type). Does anyone know the way this should really be done? I feel l'm missing a good solution and just creating difficult-to-maintain messes.
-
Thanks! As you said, the ban was short-lived and now I am being more careful.
-
Thanks for this! Even though I was there, it's great to be able to catch some of the talks that were in parallel with others I attended. I wonder if you could tell us the conditions to use the server? My careless attitude managed to get my IP blocked this morning and so now I'm using my phone and being a little more cautious, but if you could tell us for example, "no more than N simultaneous downloads" then I can avoid being banned for abusive downloads again.
-
Firstly, I'm reposting from the NI Forums here: Programatically reinsert an ActiveX Container TL;DR: My goal is to programmatically carry out whatever happens when I right click on an ActiveX container and choose the option 'Insert ActiveX Object...'. Ideally, I would like to avoid using VI Scripting to do this, but I haven't gotten anywhere so far and so really any solution will be a step forwards. My most recent attempt (I'm using NI's Actor Framework) has been to place the ActiveX container on an Actor Core panel, then use Pre-Launch Init to open a Static VI Reference, and resize the front panel, with the container set to scale with the front panel. This doesn't work, because the static reference doesn't refer to the same thing that the AF then opens using the Launch Actor VI, but ignoring that problem, it also doesn't help with resizing the container. Previously, I manually resized the container, but this I could only do after it was in existence, and so the object was already inserted. My current observation seems to be that after I choose the ActiveX object to insert, there is little/nothing I can do to change the size of the object (I can change the container, but this doesn't do anything to the object - probably the object isn't very friendly-ly coded, but I can't do anything about that...). Consequently, I come back to my goal, which is to call some Invoke Node or similar, to 'Insert ActiveX Object...'. Is there some way to do this? I don't intend to do it often, so long execution times, recompilation of VIs, shooting a cow over the moon are all fine if needed.
-
Probably just one per graph, so one. Guess that's XControls out? I'm pretty sure I could make the things I want nicely inside a class, but don't know how I'd then run it. I saw in what I expected to be an unrelated thread here mention of transparent VIs, and looking at those makes me tentatively hopeful, but will take a bit more thinking to work out if that's what I want (especially given communication between the two VIs needed). A separate popup is I suppose possible, since then I can use the VI appearance or property nodes or whatever to have it appear (and a button to end the VI to make it disappear), and that would allow reading of the 'results', I guess. But I was hoping to use it as a 'legend' of sorts, pop it up when I wanted to check which colour line was which result, that kind of thing. If I use a modal popup, then my graph presumably won't update (?) and if I have the VI run asynchronously with call-and-collect, I'm probably adding a few different types of execution (Actor, reentrant subVI, maybe notifier/queue into async subVI, results from async subVI), which seems likely to cause problems (especially because I'm bound to mess it up the first N times).
-
I'm writing some LabVIEW software to store and display data from a variety of data sources, mostly through an NI DAQ board. I'm displaying the data (stored in an SQLite database) on an XYGraph. I would like to have a toggle-able, probably semi-transparent box listing each of the plots on the graph, with the option to turn the plots on/off by clicking, along with some grouping of similar plots (all temperature measurements, or all measurements from experiment #5, etc). The Bloomy post at http://www.ni.com/newsletter/51918/en/ gives me semi-transparent panels pretty easily (in fact, this can conceivably be tri-state, since I have on, off and invisible :D) I've already programmed a simple multi-column listbox for something else in this project that switches symbols and handles double-click, mouse up/down, etc, so I could maybe use a modified version of that to hold my plots. I have never successfully used an XControl for anything, but when I come to problems involving collections of strange custom controls, I always think, is this what an XControl is for? So, do I need an XControl here? Or will I just be diving into another rabbit-hole leading to yet another unsuccessful XControl attempt? If so, what should I be using instead? In case it matters, the bulk of the project uses NI's Actor Framework to handle separate sections, and the graph is inside a subpanel, inside another subpanel. Some images of current pieces. The parent holds the scrollbar, and my current no-op (except show/hide on the little menu button bottom left) overlay (not at all transparent). The child holds the actual graph, and an ugly global variable mean (I needed it quickly for a colleague's use...). The child is embedded in a subpanel of the parent (above the scrollbar) and the parent is embedded in a subpanel of the MainUI's 'Actor Core.vi'.
-
Resource usage for inactive tabs on a Tab control
Christian Butcher replied to Christian Butcher's topic in User Interface
I also tried a radio control with the 'OK Button' placed for each item and customised but couldn't rotate the boolean text, and using a label was difficult(/impossible?) to keep in position. I considered custom graphics via gimp but my miserable gimp skills make this a very undesirable option and mean that changes require quite considerable extra time to implement. That being said, your image looks perfectly nice, and so maybe I should just use slightly larger buttons and multi-line boolean text as needed, and then I can use controls for the purposes they're intended rather than having a tab control with effectively no tab panel. Thanks for these links - I took a look at them and the example seems very much like what I imagined reading about the listbox->subpanel arrangement described. I've not used a listbox yet, but I assume it's fairly straightforward. I'll certainly read through the article more closely when I have LabVIEW in front of me (LV is only licensed for my institution's machines, not private use as far as I know) and consider this implementation for the settings 'tab' (which is unlikely to be a tab anymore, but rather a subpanel-embedded VI (I'd guess the 'Actor Core' for a 'Settings Manager' actor, or similar)). -
Resource usage for inactive tabs on a Tab control
Christian Butcher replied to Christian Butcher's topic in User Interface
Ah, seems I failed to manage to get this site to post my reply again. I found that a tab control with minimal (5px) width (it's vertical) next to a decoration covered by a subplot allows me to use a nice looking tab control (your opinions may vary) for choices without having to actually use a tab control. Probably it's more expensive than a menu ring (no evidence but seems plausible to me) but I doubt it's hugely so and I quite like the interface. Meanwhile, I can take onboard suggestions about using subplots to improve scalability since I only have one 'panel' rather than an actual tab control -
Resource usage for inactive tabs on a Tab control
Christian Butcher replied to Christian Butcher's topic in User Interface
I see the problem - for each control or indicator, I get a new terminal on my BD which I have to place somewhere, and wire appropriately, handling in a case and so on. By moving these into subVI's embedded (whilst needed) in subpanels, I delegate handling of the controls/indicators to the VIs that have some interest in the controls, rather than having a spaghetti mess looming in the future on my GUI's BD. I thought about using a subpanel for config based on something I read here written by Hoovaah (spelling? :s) about his method to register different modules' settings pages. So whilst the collection of settings a module needs probably won't change (much..., and at least not in general) the collection of modules/actors that are running might. By having a subpanel, I can use some sort of selection (I've previously implemented an array of buttons - it wasn't great but it worked. Some thought needed for a better idea here maybe) to choose which module's settings to edit. I think I should have this covered with the Actor Framework I'm using (based on the version that ships with LabVIEW, i.e. AQ's framework, I think). Still takes me some thought to work out who is responsible for sending messages where, but I'm catching on. Another week or so and I should have it down. (Previously I used QMH based on the Continuous Measurement and Logging example project) -
Resource usage for inactive tabs on a Tab control
Christian Butcher replied to Christian Butcher's topic in User Interface
Perhaps my problem is that the solution I've envisaged is so unwise that more experienced developers like yourselves can't imagine what I meant (or maybe, can imagine but immediately discard the idea as stupid and assume I meant something else...) My starting idea was to contain as the bulk of my main FP a Tab Control, with around 5 tabs. The default tab might contain a graph, a second tab might contain a subpanel to a settings configuration VI (this would in my imaginary implementation send messages on value changes within it's own embedded front panel to the main VI/controller), a third tab might contain some series of indicators describing the system status, and so on. I chose a Tab Control on the basis that this was the control meant to handle a set of controls/indicators which were grouped, but where I didn't need simultaneous access/views of multiple groups. I suppose one possible variation might be to have a tab control (or custom control that looked like a tab control) and then just one subpanel drawn over the top of it, and switch the subpanel's contents based on the value of the tab control (/ series of buttons with some decorations making them look like tabs). I already have some VIs which implemented a subpanel with contents controlled by a menu ring, so it shouldn't be hard to apply the same idea to my UI (he said, having not tried it) Thanks for the tip. The cost you describe is basically what I imagined seemed reasonable, but I'm glad to have it confirmed (since I'm not certain I could easily test it conclusively) So true... -
Ah, thanks. The table clears this up a lot for me. I tried testing what you labelled as 'error before loop' with a stop control for a While loop or a constant wired to a For loop, and so (unwisely) never saw any difference. On the other hand, I did know that a For loop with 0 iterations will provide default outputs, so should have understood the problem with that row. I'm now only confused by your 'error in loop execution x of n', 'with shift register' cell. Why would the loop stop executing in subsequent iterations? Is this different behaviour to passing an error into a shift register (from outside the loop, i.e. the (1,1) cell? I tried running this VI, but the indicator showed '4' (seemingly unlike what the table describes) and the error was shown in the indicator (as expected, and listed by the table) https://s10.postimg.org/ejdr13o2h/err_test.png (I can't seem to add an image. Not sure why - maybe new user restriction?)
-
A quick test using ShaunR's API and 'Speed Test' example VI with 100000 records, 4 columns and 10 iterations gave me (write) times on the order of 1000ms (per iteration, as approximately expected). Creating a VI which called the 'Speed Test' twice in parallel (after modifying the speed test to be preallocated-reentrant and changing the path to accept a string control) gave two sets of ~1350ms, finishing at nearly the same time (when I first called it, before realising the test was non-reentrant, both VIs returned times of ~1000ms, but the calling VI took twice as long, with one set of indicators updating halfway through.) Presumably if I check, I'll find some more VIs which are non-reentrant, which might account for the 30% increase in write time. However, the conclusion I'm drawing (perhaps wrongly) is that by writing to multiple (2,3, not 20,30) databases I can increase the total number of records I can INSERT in a given time. This clearly isn't desirable when I want all the data to be in the same table, but perhaps I can write a master database with some less frequently written tables and then ATTACH single table databases containing data from the more high-throughput sensors? Here, tables can be distinguished by sensor source, which seems not too illogical to me. My hope (perhaps supported by my quick test) is that by opening parallel connections to different database files (i.e. distinct databases) I can write more quickly if needed. This would seem to be useful in the case that my data rates slightly exceed what I can INSERT into one database but not by so much that the system becomes entirely unworkable. Is it then possible to select from a master database, with child databases ATTACHed, whilst separately writing to each database? Apologies if I dropped off the deep end somewhere, and completely screwed up.
-
Resource usage for inactive tabs on a Tab control
Christian Butcher posted a topic in User Interface
This is almost certainly a case of premature optimization, but in the interests of learning something useful: If I create a front panel containing a tab control, and each tab has some controls or indicators on it (or a subpanel, perhaps...), what is the runtime cost associated with the inactive tabs? If I insert a subVI as a subpanel, should I remove the vi when the tab is not active, or will LabVIEW's clever handling of inactive parts of a front panel extend to this? -
A little off topic, but a few posts here describe loops behaving differently if an error is passed in by a shift register. Some quick tests with both for and while loops showed no change for me. Is this just a reflection of the fact that most things inside a loop will check for an error and behave differently (often becoming no-op/passthrough)?
-
Doesn't look like I need to worry about the level of documentation for HDF5 either. Now just to read it.
-
Thanks again for all the advice. I took a look at the graphs I found on the left side of the page, under the Performance heading. It looked like you'd managed around 400k records inserted in 1 second, but for around 10 columns a time of about 0.75ms. Is this difference due to transaction grouping (no idea if that's the right term - I mean making multiple changes in one write)? In the case of 400kHz, that's around 4 times higher that what I'd previously seen described in threads on this forum (around 100kHz) and what I calculated from your earlier description (0.5-1 MB/s -> ~65.5kHz-130kHZ assuming doubles inserted). Obviously there are some presumably suspect assumptions here - perhaps when profiling you inserted 4B values, for example. The comment on the bottom half of this image seems to exactly describe my worries. (Quoted below for forum readers unable/uninterested/unwilling to open the link and read the picture) Is this (1%) an approximate order of magnitude? Or just an example? Currently have an SSD drive with external drives to backup older data. I suppose if I wanted to keep to this plan, I'd have to be careful with a monolithic database like SQlite, but I don't imagine it's an impossible problem. In any case, I have enough local storage for my immediate needs. (I hope...) So here you're describing storing data as a (2D?) array of SGL values in each write, as [[TimeA_1, TimeB_1, TimeC_1, Val_1, Val_2, ..., Val_N]; [TimeA_2, TimeB_2, TimeC_2, ...]; ...] where Time_i = (TimeA_i * A) + (TimeB_i * B) + TimeC_i or similar? What I'm meaning to ask is, you write an XY-array style, rather than using the waveform data type or an array of waveforms? I've seen similar comments on the Matlab file exchange's TDMS reader tools - this is potentially a problem for me but if I need to use TDMS I can try working through this as it happens, so long as I can get some preliminary tests working to make me believe it will. I already tried opening data from an SQlite database in Matlab and after some confusion over why I couldn't use their 'sqlite' function (answer: It's a new feature for 2016a and my machine has 2015b) installing a java plugin got me a database connection reasonably easily and then I could execute statements with 'fetch' well enough to feel reassured over plausibility. My only experience with HDF5 has been installing it, for use with other programs such as ParaView on Linux. I've generally found it to be a frustrating experience, no doubt because I choose all the wrong configure flags, but I suppose finding prebuild libraries and so on for Windows would be reasonably straightforward. I'd guess the attributes are in the same style as TDMS properties? Data spaces sound useful from your description here but I'll have to take a look at HDF5's documentation in order to work out exactly what you mean. (Also, both SQlite and LabVIEW/Diadem have really detailed documentation so there's that to consider if HDF5's is less complete.)
-
This is both great to know and also seems to follow from the example that smithd describes (Concurrent Access to TDMS File) Yeah, this is my fear. But perhaps if I'm careful to avoid obscene data rates or overly precise storage, I can cut down the cost. Of course, I should also take care not to make 'avoid obscene data rates' or 'use only single precision data' requirements... More good things to consider. However, I expect I'm bound to come up with something new to look at fairly frequently, and so I'll have to consider most things to be future calculations if I do this. Then again, I can store the results in the same file once I've calculated them, if I go back to them later, right? Thanks for the pointer. This is very useful to know. I took a look at the example and certainly it seems worth examining in more detail. Whilst looking into data requirements, I also concluded that perhaps saving only shorter representations would be fine, and that longer representations really only enhance my recording of noise... I suppose if I know that my experimental precision is limited to eg mV, then storing with a representation covering nV is not very useful. I'll have to determine expected maximum runtime vs available memory to see how plausible this is, but as you say, also well worth examining.
-
Well, that sounds good. Either option sounds plausible from your post and the only thing I should avoid doing is investing time in a catalogue, since I can use Diadem to do that for me. Good to know! Regarding the plotting of decimated data, my previous approach was to use a data queue for logging and have decimated data passed by notifier to a graph, so the data was decimated by a fixed factor at acquisition. This seems inherently inflexible, but certainly is easy to implement (both for QMH with Continuous Measurement/Logging, and also for Actor Framework - I can just send different data via message to logging and graphing actors). The SQLite examples demonstrated for the SQLite Library, and presumably also for other implementations of the C interface, show very nicely the use of SELECT statements to plot only some subset of data. My understanding is that I can use the MAX and MIN SQL statements (probably statement is the wrong term here. Maybe function?) to create a min/max decimation step. If I want to do similar things for TDMS logged data, am I limited to holding a complete data set within LabVIEW's memory and passing only chosen data points to the graph when I want to update, or using fixed decimation regardless of e.g. graph zoom level or focus? I assume that reading from a TDMS file that is currently open for writing is likely to end badly for me...
-
Question: I'm trying to determine the 'best' way to structure my data when storing to disk. My data comes from a variety of different sensor types and with quite different rates - e.g. temperature data (currently) as a 1D array of temperatures and a timestamp [time, t1, t2, ..., tn] at maybe 1 Hz and analog waveform data from load cells at data rates ~O(kHz). I also want to be able to read back data from previous experiments and replot on a similar graph. Reading threads on this forum and at NI I'm uncertain if I'll be better pursuing a set of TDMS files, probably one per sensor type stored at the group/channel level, then at the end of an experiment, collating the TDMS files into one master file and defragmenting, or trying instead to write to a SQLite database. (I have nearly no experience using SQL, but no problem learning - drjdpowell's youtube video was already very informative.) An alternative possibility mentioned in a thread somewhere here was to write TDMS files, then store records on which files hold what data in what I understood to be a catalogue-style SQL database. Could anyone with a clearer idea/head than me comment on which avenues are dark tracks down which time will be easily lost in failed attempts, and which seem likely to be worth trying? Background: I'm currently rewriting some code I wrote last year based on the 'Continuous Measurement and Logging' template/project. The logging in that case was writing to a single, binary file. Keeping my data format in line as I changed sensor arrangement became increasingly annoying and an ever expanding series of block diagrams lead me to start on the 'Actor Framework' architecture. I have some initial progress with setting up actors and generating some simulated data, passing it around and getting it from different formats onto a waveform or XY-graph (can be chosen by choice of child class to insert into a subpanel). I'm now looking to write the logging code such that I have basic implementations of several of the components before I try and write out all of the measurement components and so on - I already have a temperature measurement library for an LTC2983 based PCB and so can use that to test (with hardware) inputting 1D arrays, whilst I'm planning to use just the sine wave VIs to test waveform input. I'm not so far into this set of coding that anything is set in stone yet, and so I want to at least try and start off in the right direction. Whilst it seems likely changes to requirements or plans will require modifications to whatever I write, it would be nice if those weren't of the same magnitude as the entire (e.g. logging) codebase. Apologies for the somewhat verbose post.