Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
206
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Aristos Queue
-
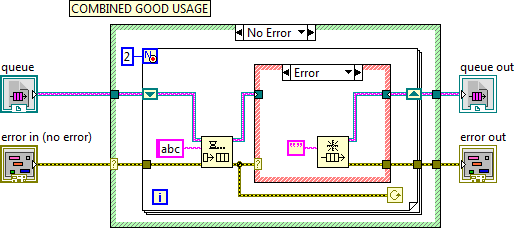
 You're right... I need to flip the combined case to the Error case instead of No Error. I took the screenshot before fixing that. Corrected image (I'll ask Moderator to move this image into the original post)
You're right... I need to flip the combined case to the Error case instead of No Error. I took the screenshot before fixing that. Corrected image (I'll ask Moderator to move this image into the original post)
-
Register & Unregister or just Register?
Aristos Queue replied to Aristos Queue's topic in Application Design & Architecture
Todd: Bingo. Those names don't imply "if I use one, I'll use the other." But I'm kind of afraid that Register and Unregister do. But I really like the verb in this particular context. -
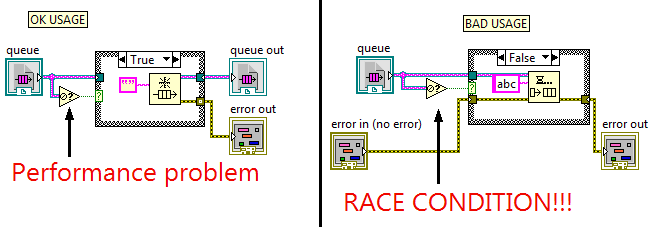
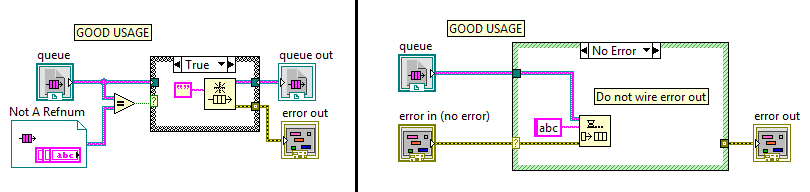
Just so everyone is clear: Using the Not A Refnum function to decide to create a refnum is ok because the zero refnum cannot be destroyed/released in a parallel thread. But since the primitive does the extra work of validating the refnum, you take a performance hit on the cases that are going to succeed. Using the Not A Refnum function to decide to do an action or not is a race condition because a parallel thread could be destroying that refnum in between the test and the action. If you need to actually do an operation, do one of these: If you need the combined behavior of "if the refnum is bad, allocate it, and do some operation on it", then do this: What is an acceptable use case for the Not A Refnum primitive? When you're evaluating the status of one refnum before taking an action on another refnum! Or if you're just displaying information in a Custom Probe. Or if you have absolutely nothing happening in parallel (in which case, you might reconsider your use of references anyway). (For advanced users who suggest the use of semaphores to protect the access, that counts only as an OK usage because you still have a performance hit of unlocking and locking the refnum twice.) If you ever are tempted to file a bug report that the LabVIEW queue functions are broken, please check your use of Not A Refnum first. I guarantee I will when the bug report gets to me. 🙂 And, for the record, all of the above also applies to using "Get Queue Status" and "Get Notifier Status" functions. And any other similar "is this refnum still valid" functions that you are using to make decisions in code.
-
I have functionality where I want to fill in a table that maps one value to another value. I have named the function that adds to this table Register XYZ.vi (where XYZ is my key type). I have a second function Unregister XYZ.vi that removes a key from the table. Register and Unregister, however, create an expectation in LabVIEW that if a user of my API calls Register that somewhere in the code he or she should call Unregister for good coding practice. But I do not expect that to be the common case. There's no need to do an Unregister the vast majority of the time -- this table is rarely unregistered item by item and instead the table itself just stops being used. And it's a by value table, not a reference whose lifetime has to be tracked. So I am strongly contemplating just having one function "Register XYZ.vi", and if the user passes zero for the value to register, that just removes the item from the table (registering zero and not having an entry in the table are functionally equivalent). "Register" is definitely the verb I want to use -- I gave a lot of thought about that before even asking this question, though perhaps a complete rephrasing of the name. So my question: Which of these APIs would be, in general, more intuitive to you? A) A Register and Unregister pair of VIs but where Unregister is almost never used and it is not considered a bug or a leak or otherwise a problem. B) A single Register VI whose behavior when you register a particular value is to remove the item from the registration. C) I have a third solution (please post comment below)
-
I created two new nodes in LabVIEW. Really neat, eliminated a problem I was having where the existing G solution was too slow. Then I discovered that one of the nodes inadvertently created a hole in the protections of both VI Server security and library encapsulation. So I patched that. And now it was slower than the original solution. I feel like Dr. Frankenstein having to shoot his own creation just because it started eating a few villagers. *sigh* Back to the drawing board...
-
Speaking as someone who often sees LV from the underside, I think of this as "Get Data Type Name". The name returned is the name that was part of the data type at the time we compiled this VI for the wire that created the variant. That's the nearest named terminal upstream, but the name is preserved as you pass through tunnels, so it isn't necessarily the name of the nearest terminal. Having said that, "Get Data Type Name" is a terrible name for the VI for most people because it is not the same as "Get Name of Data Type", which would be "Int32" or "Double". :-) So "Get Terminal Name" is the nearest to technically accurate that doesn't mislead people further. When you start dealing with LV classes, the problem gets even ickier because the name of the data type is always "LabVIEW class instance", the name of the class of the data type is "your class.lvclass", and the data type (terminal) name is "whatever you typed on the nearest upstream non-tunnel terminal". Summary: I can see why "Get Terminal Name" would be a better name for this VI, and I cannot propose a better one.
-
It takes time to press physical DVDs. We can get the downloads up a lot sooner for those who need the fixes. Pressing the individual DVDs just doesn't make economic sense these days.
-
If you're arriving in Austin tomorrow, the Austin Kite Festival is in Zilker Park. 11am to whenever people get tired of flying. http://www.zilkerkitefestival.com/ I might be there... I just saw this post and have to coordinate plans with people tomorrow before I can say for certain.
-
LV OOP Kd-Tree much slower than .Net, brute force
Aristos Queue replied to jkflying's topic in Object-Oriented Programming
Hi, jkflying. Welcome to LabVIEW. You've now heard the position of the "OO is bad" crowd. If you'd like to rewrite without classes, go for it, but that's not the bulk of your performance problem. If you're like 90% of the world's programmers, you'd probably prefer some help getting the OO solution up to speed. So let's look at what you've got. There's a lot of text in this post, but I've tried to break it into short paragraphs -- each one is independent, so you can read each one and absorb it by itself without having to take in all of this in one go. First of all, remove the Timed Loops from your test harnesses. Timed Loops have side effects on the thread scheduling and prioritization of LabVIEW. Lots of things that could be faster are not in order to get determinism within the timed loop (in other words, repeatable schedule is more important than fast schedule on any given iteration). I do not understand the details well enough to teach them to you -- it's an area of LV outside my normal baliwick -- but the long and short of it is that Timed Loops are meant to provide fixed scheduling for real-time deployments, and using them for other purposes will have undesirable side-effects. Instead of timed loops, you can use a Flat Sequence Structure, with a Get Date/Time In Seconds node in the first frame, your code in the second frame, and another Get Date/Time In Seconds node in the third frame. Now, about the benchmark itself... any language has problems where it just cannot outcompete another given language, but I do not think we are dealing with one of those in your case. One major item to consider: is the .NET implementation thread safe? A lot of the overhead in your code implemented in LV is going into thread safety for that kd tree to be used in parallel branches simultaneously... I'm going to guess that the .NET code is not thread safe if only because almost nothing that C# programmers write is thread safe (haven't looked at your implementation). Unless the .NET solution is doing the same level of mutex locking, you're benchmark comparisons are skewed. We can get the LV implementation up to speed, but this is one of the common problems with comparisons between LV and other languages: as long as everything is dataflow, our compares match theirs. Once you introduce references, we implicitly buy the cost of thread safety, where as they leave you to implement that yourself if you decide you need it. What that often means is that small test apps used for benchmarks suffer because we've got overhead, but real world apps are faster because we then use that thread safety to achieve parallel performance. Please keep that in mind when evaluating. Looking at your code... you use LabVIEW Object as the type of your DVRs, which is the reason you need all the To More Specific and Preserve Run-Time Class primitives. Introduce a parent class (kdtreeparent.lvclass) that has the methods on it that you need (dynamic dispatch). Have kdtree.lvclass inherit from it, and use kdtreeparent.lvclass inside the DVRs. Now when you access a DVR inside the Inplace Element (IPE) structures you avoid the fairly expensive dynamic type checking. The dynamic type checking is getting a speed boost in LV 2012, but it is better to remove it entirely. Using the queues as stacks is fine... they're optimized for that use case. However, you should definitely not name the queue... you've got the name "Stack" wired in. That means that you're using the same queue as anyone else who uses the name "Stack". It's just like putting a variable in the global namespace. Bad things happen. There are legitimate reasons for using this feature -- ok, one legitimate reason -- but this isn't it. Inside addExemplar.vi, you're using Read Left.vi, Read Right.vi and other accessors. Although it is normally fine practice to use your accessors inside the other methods of your class, in this case, I suggest using a plain Unbundle node (not the IPE) to access those fields. The reason is that you're extracting multiple fields and you'll be able to unbundle multiple at once. Read Domain.vi, as written and used inside addExemplar.vi, is very expensive (and, side note to previous posters, it would also be expensive with plain clusters). You are calling Read Domain.vi and then wiring its output directly to an Index Array node. That's producing a duplicate of the array every time. Instead, create an accessor on Exemplar.lvclass that accesses the domain inside the IPE, indexes one element, and returns that out of the subVI. With that, you'll only be copying a single floating point number instead of allocating a whole array. In the isTree.vi, you are doing the "!= infinity" check outside of the IPE. This is copying the floating point integer. You can avoid that by moving the "!= infinity" computation inside the IPE. Similar performance improvement can be done in other VIs in your hierarchy. I am confused about why AddToTree is destroying the DVR and then creating a new one instead of just accessing the DVR through an IPE. If this is a trick to avoid initializing the class (which is my guess as to why you're doing that), you've just introduced a significant thread synchronization problem. If you fork your tree wire on the top-level VI, when you call Add on one branch, you'll invalidate the DVR refnum that is still inside the tree on the bottom branch. And now you'll get errors from that other branch, or just lose all your data. Probably not what you want. This should just access the DVR using an IPE and you should have a Create Tree.vi that returns the object populated with the top-level DVR and a matching Delete Tree.vi which knows how to traverse and deallocate the entitre tree and throw away the top-level DVR. On that same note, you really should include this in your test cases: That will show you a big problem with your current implementation. It is a bad idea to put the meta data about the contents of a DVR as by value fields of your top-level class (or cluster) and have the refnums shared. Putting the whole data block into a single top-level DVR makes this truly behave like a refnum type. What that means is that all of your public VIs will all start off by accessing a DVR in order to get access to all the fields that are currently in your kdtree.lvclass private data cluster. Oh... and change your wire color to refnum cyan (it's a predefined color in the color picker) to let people know that your wire contains (and therefore behaves like) a refnum. Those are the big points. You didn't pick an easy problem for your first out-of-the-gate project. A basic KD tree is kids stuff... a thread safe KD tree? That takes a bit more to reason through. You've got a good start here, though. I have seen DVR-with-classes implementations for other data structures that can beat or exceed .NET thread-safe structures performance, so if you keep chipping at it, I'm confident you can get there. Happy wiring!
-
True... and I should probably set a better example for customers who are in Beta Club... but I get some special dispensation from time to time.
-
Yep. Lovely lovely wizards. :-)
-
And for many people, that fastest route is LVOOP (especially if I'm taking the exam with LV 2012... hehehe).
-
CLD sample exam organized using LabVIEW classes
Aristos Queue replied to Aristos Queue's topic in Object-Oriented Programming
Regarding 1: I strongly disagree. That puts you right back to an enum which is what we are trying to eliminate . The current solution I posted has the message carry with it the instructions to perform so the set of actions possible is open ended. -
Ever create a queue of an error cluster? The wire is particularly pretty. Never created one of those before... or, if I did, I never paused to note its aesthetics.
-

I think my favorite is simply a numeric/enum queue/notifier/UE. Looks like a laser, and makes me wish we had a red data type.
-
-
If the Icon Editor persisted the layer information to the clipboard when you copied, then it wouldn't necessarily be a waste of time, but that's never been implemented in any of the icon editor plugins that I've seen.
-
Here you go:
-
If you want to see a Certified LabVIEW Developer sample exam written using LabVIEW classes, I am uploading one here. I built this over the last four hours in response to comments in another LAVA thread which correctly pointed out that a sample CLD written with classes was not available for review. If you wish to comment on improving this class-based sample exam or ask questions about how it works, please post them here. If you wish to debate whether LabVIEW classes are worth using or whether they are overkill for real apps (including for the CLD exam itself), or any other philosophy, please post in the original thread that spawned this. The sample exam that I did was ATM version 2 (I am attaching the PDF to this post for ease of reference). After 4 hours, I have the solution posted below. It is not a fully fleshed out app -- it is exactly what I have finished after 4 hours and would have turned in on the exam. It is very similar to what I turned in for my actual exam, although I will note that for my actual CLD, I specifically brushed up on file handling and had that working. Tonight, I was unable to recall my cramming, so that just got dropped (but documented as a TODO!). Top level VI is ATM UI.lvclass:Main.vi. This VI takes an ATM UI object as input in case configuration options are added to this application in the future -- those options are already part of the UI loop. Issues that I know of: File I/O is not done, as I mentioned above. The display strings are placeholders ... I didn't type out all the proper strings. There's no way for the user's name to be displayed when they put in their card. Although I documented the VIs, I did not fill in documentation into the classes themselves and probably should have. Other than that, I think it all works given the limited testing I was able to do within the 4 hours. I have no idea why I felt the need to make setting the display message go through an event instead of just setting the local variable every time. I think i had it in my head to bottleneck the localization, but that doesn't work, of course, because you have to be able to format information into the strings. That should probably be removed entirely. I did build a message abstraction from ATM UI to ATM, but I didn't build a messaging abstraction from ATM to ATM UI. Why? Because I thought the data needed to respond was always the same. It wasn't until later that I decided that was a mistake, but I figured I should finish out this way. Building a true abstraction layer for completely isolating the ATM from the ATM UI is probably more than can be done in the 4 hour block unless you've got some scripting tools to back you up -- we'll have to see if it's reasonable in LV 2012 (without going into detail, assuming the beta testing goes well, there will be tools to help this exact problem in 2012). 100928-01.pdf AQ_ATM2.zip
-
Dynamic SubVI Questions
Aristos Queue replied to theoneandonlyjim's topic in Application Design & Architecture
Please define the term "dynamic VIs" ... are you talking "VIs that you load dynamically using Open VI Reference or the 'Call Setup' pop up menu option on a subVI node" or are you talking about "dynamic dispatch VIs that are members of LabVIEW classes"? The answer to your questions will vary greatly depending upon which of these two technologies you're asking about. -
Yeah, it kind of does, but I won't tell the Powers That Be if you don't...jbjorlie: Read the beta forum for comments from me about this.
-
The controller can also listen in on those same messages... as I said, there can be a bit of bleed over between the responsibilities of the view and the controller. Keeping them firmly separated is a goal needed by some applications but far fewer than the number of applications that need an absolute wall between the model and everything else. I'm probably not describing this in helpful terms. I have an example of exactly this, but it isn't something I can post at the moment... if you join the LV 2012 beta program, the beta of 2012 went live today and there's a shipping example in there for exactly this with the AF.
-
LVOOP on RT - concerns?
Aristos Queue replied to JeremyMarquis's topic in Object-Oriented Programming
This was not a known issue. I have filled CAR 337019. Do you know if it affects the Desktop Execution Trace Toolkit as well? (I told them to check both, but if you know off the top of your head, I'll add that to the CAR.) -
Daklu wrote: > I wouldn't do this. It's giving the business components (motor controller, etc.) > responsibility for deciding how the data is displayed. Totally agree. This is the basis of the separation of "model" -- the hardware/business logic/process/software simulation/whatever you're actually doing from "view" -- the UI layer or data logger system that records what's going on from "controller" -- the section of code that decides what new instructions to send to the model Model generally knows *nothing* about view or controller. Any view can connect to it. Any controller can send it orders. The model publishes a list of (events for the view to listen to OR messages sent from the model) and a list of (events for the controller to fire OR messages that can be sent to the model). The controller knows little or nothing about the view (binding these two is sometimes more acceptable). It publishes a list of events/methods for the view which tells the view what commands are available right now and lets the view command the controller.
-
closed review Suggestions for OpenG LVOOP Data Tools
Aristos Queue replied to drjdpowell's topic in OpenG Developers
This same change will have effect of removing a copy on control refnums and .NET refnums also, although the effect will be much much smaller since the maximum amount of data copied in those cases is a single int32. -
closed review Suggestions for OpenG LVOOP Data Tools
Aristos Queue replied to drjdpowell's topic in OpenG Developers
Victory! That output terminal will not be needed as of LV 2012. There was a (bug / unimplemented optimization -- depends upon your view) that made LV add a copy at certain upcast coercion dots. This compiler (fix / upgrade) will have performance benefits for a wide range of LVOOP applications. The change was implemented months ago, so this API doesn't get credit for finding the issue, but the compiler team verified your VIs do benefit from the change. I would therefore recommend not putting it into the API as removing the terminal is a possible mutation issue, and not having the output terminal for a read-only operation is a much better API overall. -
LVOOP on RT - concerns?
Aristos Queue replied to JeremyMarquis's topic in Object-Oriented Programming
The online help that ships with LabVIEW discusses this topic. Take a look at that and see if that answers your questions.