

Mellroth
-
Posts
602 -
Joined
-
Last visited
-
Days Won
16
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Mellroth
-
-
I always use the way Ben mentioned, but on machines with multiple network cards, I first set the Str2IP primitive to return multiple.
This way I can get IP addresses of all my cards.
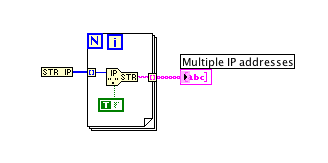
/J
-
QUOTE (maybe @ Aug 20 2008, 09:52 AM)
...I still cannot get an image with the blue cloud. Any ideas?I would say that this is a bug. Since NI is allowing us to set a background picture, that background should also be present when we capture the FP picture.
Workaround?
Do you really have to put the picture as background? If not, then just paste the picture on the FP (becomes a decoration) and send it to the back. Now the FP picture should include the picture, since it is included as a decoration on the FP. You might also want to consider locking the picture on the FP, so that you don't move it around by mistake.
/J
-
QUOTE (normandinf @ Aug 13 2008, 02:38 PM)
I don't think this was possible in LabVIEW 7.1 (assuming goran is using 7.1)?
QUOTE (goran @ Aug 13 2008, 10:49 AM)
...How can I do this?...So to implement this in LabVIEW 7.1, you would either have to create your own drag'n'drop; using mouse down events, copying data, tracking where mouse was released etc., or go for another solution
If you only have an ActiveX component as the target for the drag and drop (i.e. only one target), you could probably use double-click in the listbox instead as a trigger to copy data from the listbox to the ActiveX component.
/J
PS. I decided to make a small VI for you that makes a quick and dirty drag-n-drop possible in LabVIEW7.1.
It also shows how to use double-click instead.
-
QUOTE (Omar Mussa @ Jul 8 2008, 06:58 PM)
This is actually a really useful feature of enabling the conditional terminal in certain cases (for example, autoindexing an array of strings UNTIL an empty string is found, etc).I agree, this feature is really handy.
I was just trying to point out that I have seen strange bugs, because people don't use the output iteration correctly,
and thought this was a good place to stress this difference from an ordinary FOR loop.
/J
-
I really like the conditional terminal of FOR loops, but I have seen a number of implementations where the programmer uses auto indexing outputs just as on an ordinary FOR loop.
Causing all kind of strange errors in the program, errors that can be quite hard to find.
Using conditional terminal;
Length of the indexing input is not necessary equal to the Length of the indexing output, unless all iterations are completed.
Not using conditional terminal;
Length of the indexing input is equal to the Length of the indexing output.
/J
-
QUOTE (blueguard @ Jul 8 2008, 01:42 AM)
QUOTE (Aristos Queue @ Jul 8 2008, 02:08 AM)
Those are part of the LabVIEW DSC package, not part of LabVIEW itself.As Aristos said, these specific controls are part of an add-on package, but you can change the appearance of existing LabVIEW controls as well;
* If you only need to change the looks of a control, use the control editor.
* If you need to change the behaviour, e.g. to use specific formatting depending on the value, use Xcontrols.
/J
-
QUOTE (prads @ May 28 2008, 05:31 AM)
H05/27/2008 15:10:1200101111000 --as seen here the bits(00101111000) are written adjacent to the Timestamp but I want it to be written in the next line!!!Hi prads,
it is always easier to get good answers if you can post a picture, or a piece of code, to show us what you have done.
If you want the bits to be written on the next row, add a newline '\n' at the end of the timestamp.
Appending data to a file does not require the Set Write Position to explicitly tell LabVIEW to append the data at each write operation, it is only necessary to do this before you start writing data to the file.
Hope this helps
/J
-
QUOTE (prads @ May 16 2008, 09:03 PM)
...Do you have any idea how to proceed with this task...Prads,
When you say you don't use any packaging, do you mean that you only want to;
1. read the contents of a file (raw format, i.e. byte by byte)
2. transfer the content to another computer (e.g. using TCP/IP)
3. write content to a new file (basically making a file copy over the network)
You will probably get more/faster help if you could show us what you have done so far, and perhaps also show the contents of the file.
/J
-
QUOTE (prads @ May 16 2008, 01:19 AM)
2. No, Encoder/Decoder for ASN.1 does not exist in standard LabVIEW as far as I know.
QUOTE (tcplomp @ May 16 2008, 05:21 AM)
For instance what is ASN.1?ASN.1 is a way to describe packaging of data in communications.
http://en.wikipedia.org/wiki/Abstract_Syntax_Notation_One
/J
-
QUOTE (cheekychops @ Apr 30 2008, 04:43 PM)
...I need to find the exact index of the leading edge and exact index for the falling edge...Maybe like this
1. A = your array
2. Check A greater than t, where t is a threshold value (i.e. use A > t), gives you a boolean result array B.
3. Search B for value of TRUE, this gives you the index of the leading edge.
4. Use the leading edge index as start index and search B for a value of FALSE, gives you the trailing edge index.
/J
-
QUOTE (minority @ Apr 23 2008, 08:51 AM)
... writing strings to a device works fine when run on LabVIEW but when running the standalone application it stops working (no response). Anyone that might have any ideas on that?One thing that comes to mind, is to check the build specification, so that VISA is included in the build.
Other than that, I think you'd have to post some code for us to look at to get more help.
/J
-
-
Put on some headphones and goto
[/url] to get a virtual haircut./J
-
QUOTE (souske @ Apr 14 2008, 09:40 AM)
To enable MHz support, have a look at these links on NI.com:
http://digital.ni.com/public.nsf/allkb/0C0...6256F6700061790
http://digital.ni.com/public.nsf/allkb/5B1...13?OpenDocument
Please note that enabling MHz support will also take a lot more CPU, and that is the reason that it is not enabled by default on some RT targets.
/J
-
QUOTE (souske @ Apr 10 2008, 03:18 PM)
With TimedLoop on cRIO I also get nice 1.01 ms, but even cRIO can't squeeze 1ms from a standard "while" (with RT version of "wait until..." ).If you enable us support on the cRIO you can probably get closer to the 1ms target, by using the RT specific "Wait until next multiple" with 1000us as input.
/J
-
QUOTE (rolfk @ Apr 10 2008, 08:22 AM)
But it does do so very fast then without any other means of throttling the loop iteration...Throttling does not seem to be the goal here, but to run each iteration as fast as possible (a calculation loop maybe?).
If the loop would only perform an action when the RT FIFO was set, then I would also go for the event, but in this case the RT FIFO is used to check a STOP condition.
/J
-
QUOTE (crelf @ Apr 9 2008, 03:38 PM)
Nothing like a hijacked thread before first cup of coffee...
I agree with you, in the end it is up to the user to understand how to use the tools.
QUOTE (orko @ Apr 9 2008, 04:19 PM)
Personally, I think the above behavior isevil. Sorry, but I don't care if it makes sense that it happens procedurally... can someone tell me why in Pete's sake I wouldeverwant to select "no" in this situation...?What really bugs me is that there is no information that you might loose your block diagram if you select no.
The choice of Yes or No is like to ask if you want to keep your orange or get an apple, but there is no information telling you that if you select the orange the only thing you'll get left is the peel.
/J
-
QUOTE (rpodsim @ Apr 9 2008, 10:14 PM)
QUOTE (Eugen Graf @ Apr 9 2008, 11:10 PM)
...And I think to use "0"-timeout is not really good. I preffer "-1" as timeout value...Most times I would agree with you, but in this case where Ryan is trying to minimize overhead using RT FIFOs, timeout 0 is OK (and preferable).
The reason is that with timeout = 0, the read operations just polls the buffer instead of waiting for an event.
/J
-
QUOTE (Aristos Queue @ Apr 8 2008, 11:07 PM)
QUOTE (Justin Goeres @ Apr 8 2008, 11:49 PM)
May I suggest a?We actually filed a bug report about this a while back (2003?), but found out that it was the way some users used ClearCase that caused the removal of the block diagrams (on VIs as well as controls/typedefs).
In our case some users had a lot of code opened in LabVIEW, then when a VI was modified they tried to save the VI, but to do so they had to first CheckOut the VI in ClearCase.
The CheckOut could then in some cases (e.g. if the cs-file was changed after the VI was loaded, so that a later version was selected), cause the change on disk AQ is mentioning.
My point is that even with a Version Control system, you have to be careful. You could still lose a BlockDiagram and be forced to do the work all over again.
/J
-
QUOTE (scls19fr @ Apr 7 2008, 10:28 PM)
So my problem, is that now when I click on "STOP PROG" tge state isonly set to MANUAL ***after*** every step of the sequence are finished !
If my PROG (predefined sequence) is very long it's not very conveniant as
I have to wait the end of the sequence to abord.
Is there an easy way to solve my problem ?
You'll have to create a way to signal that a sequence is aborted, so that the main VI sets a running state and the subVIs just reads the status to see if another step should be taken. This can be done using a number of different primitives/patterns;
* using notifiers/queues/occurrences, using these primitives means that you'll have to feed every "sequence runner" with the queue/notifier reference.
* using a functional global, i.e. a VI with an uninitialized shiftregister that stores the status information you need.
* ...
/J
-
QUOTE (alexadmin @ Apr 7 2008, 02:50 PM)
...speed less than 100 kb/s. I attach the simple example (it is need to set correct file name) - it takes ~10 minutes to write 50 MB file...If you write data in larger chunks I don't think there is a problem, maybe you can buffer data instead of writing the file byte by byte?
As a test I generated 5MB of data and wrote that to the file in one shot, then the code completed in a few seconds.
/J
-
We experienced a decrease in speed using VIs with subroutine priority in two different timed loops (on a dual core machine).
Removing the subroutine priority got us back on track.
If I remember correctly, some of the VIs were reentrant, which makes it much harder to understand why the subroutine priority affected performance.
/J
-
QUOTE (Götz Becker @ Apr 1 2008, 09:26 AM)
I still don´t know why my memory consumption grows...Hi,
I think that one of the reasons your memory grows is that you start filling the Queue with elements of length 1,2,3,4 etc. this means that the queue element only allocates this amount of memory.
At some point the queue element that was once initialized with a size of 1, will get a larger buffer written to it, and will therefore keep this new larger buffer in memory. This will continue for all your queue elements.
In the end, all your queue elements will have a allocated size of 4999*8 bytes.
This could then explain an increase in memory of about 4999*8*500 ~ 20MB.
To test this, add some code right after the InitQueue primitive that adds 4999 dbl values to all buffer elements, and then removes all elements (thus pre-initializing the amount of memory the queue will use).
/J
-
QUOTE (Daklu @ Mar 31 2008, 07:53 PM)
Initially the unbundle method was faster with increased benefit if the item was near the beginning of the array. This makes sense as it will stop searching as soon as the item is found while the masking method iterates through the entire array twice before searching. However, later testing with slightly different test code had the mask method consistently faster. Odd.I think it is safe to say that the unbundle version should be faster for small arrays, and when only a few elements in the cluster is checked.
The main goal for me when I first started to use this, was not speed, but a way to easily update the code to include many cluster elements and to let a user select elements to search from a GUI. The search algorithm is pretty much unchanged regardless of the size of the cluster, making it easier to maintain.
/J


Running a VI at Windows boot up
in Development Environment (IDE)
Posted
QUOTE (Harshvardhan @ Aug 27 2008, 02:07 PM)
Hi,
If you want to run the application before any user is logged in, or for all users, you can create a NT-service of your application. A NT service runs without front panel and in the background. To communicate with the NT service you'll have to use VI-Server or UDP or TCP/IP etc.
Check out the link http://zone.ni.com/devzone/cda/tut/p/id/3185 to learn how to do this.
/J