

Neil Pate
-
Posts
1,187 -
Joined
-
Last visited
-
Days Won
110
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Neil Pate
-
-
That is weird. No sorry not seen that before!
So you have tried manually changing the tool?
-
@Rolf Kalbermatter the admins removed that setting for you as everything you say should be written down and never deleted 🙂
-
 1
1
-
-
2 minutes ago, ShaunR said:
1.8 MB?

yeah that is the payload 😉
-
1
-
-
23 minutes ago, ShaunR said:
Heathen

16.37 kB · 0 downloads😂😂😂
-
I also realised I messed up my benchmark and the final High Precision Time should be after the sorting. I meant to do this just forgot!
-
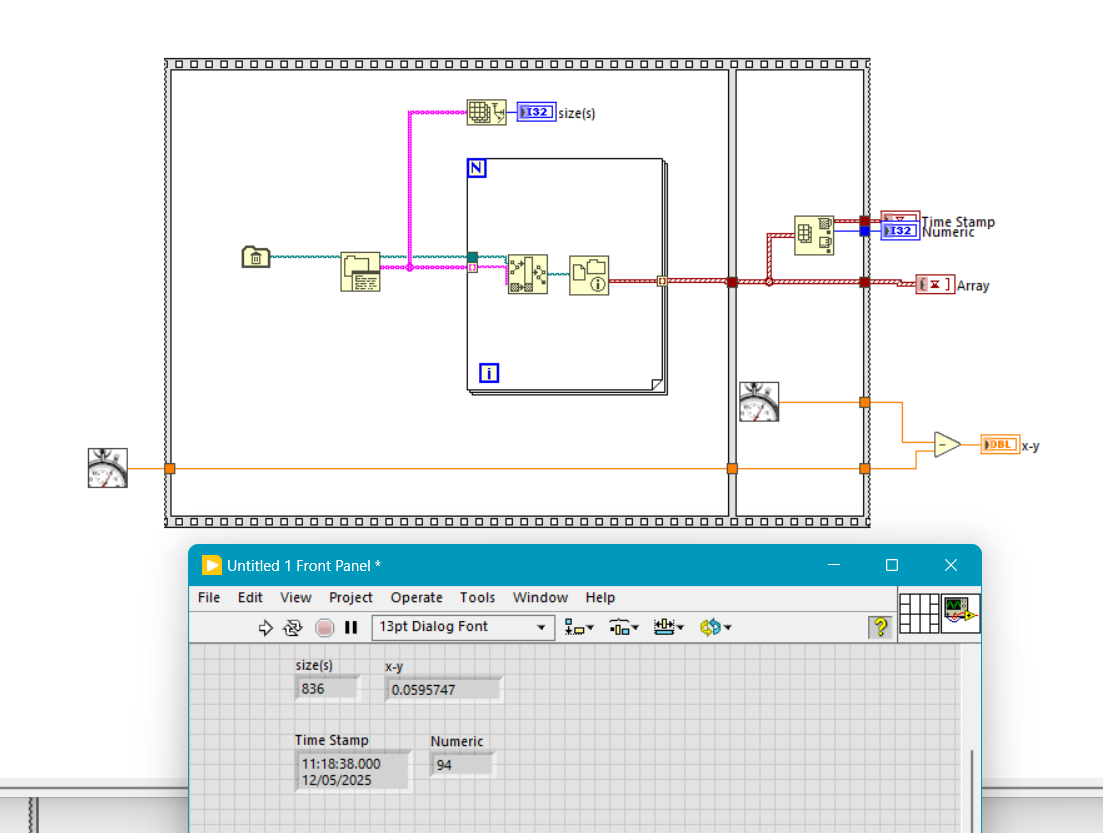
Done some simple testing.
On a directory containing 838 files it took 60 ms.

-
 1
1
-
-
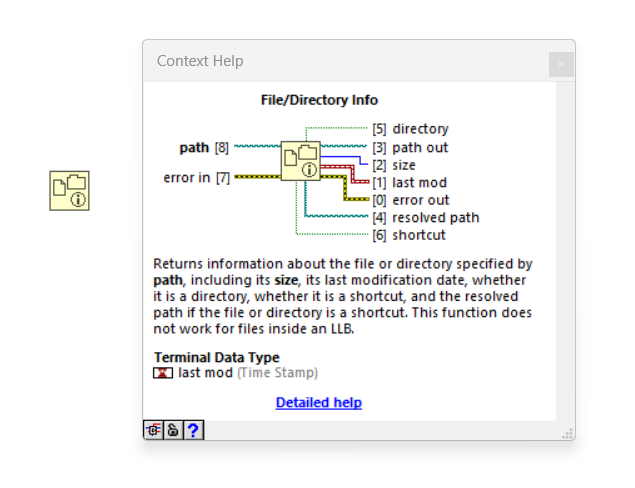
Have you tried this? The `last mod` output should hopefully give you the timestamp of the last modification, and it would then be pretty simple to find the latest.
I have no idea what the performance of this would be if you loop over 10000 files. That is something you would just have to try.
-
I actually had a similar experience when first moving everything to the new OpenG structure. It broke heaps of stuff (even inside its own OpenG stuff), so I rolled back the change.
Some time later I tried again, and think I did have to deal with a bit of pain initially with relinking or maybe some missing stuff, but since then things have been stable.
-
 1
1
-
-
Put the acquire image and save to file in the event structure timeout case, but only write to file conditionally (i.e. if the user has clicked the button)
-
1
-
-
ok, a couple of things to address. The IMAQ close error probably happens because there is no open session the first time. It would probably be fine just to silence that error by clearing it.
The first error is a bit surprising as you dont have a timeout value wired into the case-structure so I would have expect that portion of the code to never execute. Another slightly strange thing is the name of the VI in the error message does not match the name of the VI in your code (IMAQ Write BMP vs IMAQ AVI 2 Write Frame).
Try wire a value into the timeout (like 1000 ms or something like that) and move your acquisition code into that event.,
I do not currently have the vision toolkit installed so cannot test your code.
-
@Natiq this (non-functional example) should be enough to get you started. The weird arrow thing on the boundaries of the while loop is a shift register.
The event structure can also be configured to have a timeout case where you can then perform other stuff, like reading your image and writing it to the reference on the the shift register.
There is heaps of information out there (YouTube for example), a bit of searching will lead to some more details.
-
1
-
-
You have not implemented the Event Structure.
-
Close should be inside the loop. Before you start a new file you would close the old one.
The file reference you get from opening the file would be put onto a shift register so that you can access it in the next iteration of the while loop.
Can you share your code?
-
1
-
-
You are likely getting only 1 video because you are re-using the same filename.
There are a bunch of ways to solve your problem. For me the easiest would be to look to using an Event Structure as this stops you from needing to poll the button all the time. Do a bit of googling to see how the Event Structure works. (tip, you will configure an event that responds to the save button click, and in that event you will prompt for a new filename (or autogenerate with timestamp) and then open a reference to this new file).
-
 1
1
-
-
2 hours ago, Cat said:
Hellooo? Anybody home?
")
For those of you who don't remember (or weren't even born yet when I started posting here 😄), I work for the US Navy and use a whole bunch of LabVIEW code. We're being forced to "upgrade" to Windows 11, so figured we might as well bite the bullet and upgrade from LV2019 to LV2024 at the same time. And then the licensing debacle began...
Due to our operating paradigm, we currently use a LV2019 permanent disconnected license for our software development. This was very straightforward back then. But not so much with LV2024 and the SaaS situation. Add to this the fact that I can't talk to NI directly and have to go thru our govt rep for any answers. And he and I are not communicating very well.
I'm hoping someone here has an answer to what I think should be a really simple question: If I have a "perpetual" license with 1 year service duration for LabVIEW, at the end of that year, if I don't renew the service, can I still use LabVIEW like always, as if I still had my old permanent license? I realize I would not have any more support or upgrades, but that's fine.
I've read thru the threads here and in the NI forum about this, but they mostly ended back when no one really knew how it was all going to shake out. So are we locked into either our ancient LV versions forever, or are we going to be paying Emerson/NI every year for something we don't really need?
Cat
Welcome back! Yes we remember you 🙂
So I think you can now actually buy perpetual licenses again. I have not needed to do this myself as my org has an enterprise agreement with NI, but it is possible (I think...)
-
1
-
-
- Popular Post
- Popular Post
6 hours ago, ShaunR said:Nobody has met me, right? I might be A.I. without the I
A is for Argumentative, right?
-
5
-
Yeah it is getting out of hand. Like others have mentioned, I used to browse here daily (often multiple times per day) but since the spam bots took over I stopped coming altogether.
-
Back again today, new user related I think
-
On 7/7/2024 at 2:34 PM, ShaunR said:
Because I can immediately test the correctness of any of those VI's by pressing run and viewing the indicators.
Nope. That's just a generalisation based on your specific workflow.
If you have a bug, you may not know what VI it resides in and bugs can be introduced retrospectively because of changes in scope. Bugs can arise at any time when changes are made and not just in the VI you changed. If you are not using blackbox testing and relying on unit tests, your software definitely has bugs in it and your customers will find them before you do.Again. That's just your specific workflow.
The idea of having "debugging sessions" is an anathema to me. I make a change, run it, make a change, run it. That's my workflow - inline testing while coding along with unit testing at the cycle end. The goal is to have zero failures in unit testing or, put it another way, unit and blackbox testing is the customer! Unlike most of the text languages; we have just-in-time compilation - use it.
I can quantitively do that without running unit tests using a front panel. What's your metric for being happy that a VI works well without a front panel? Passes a unit test?
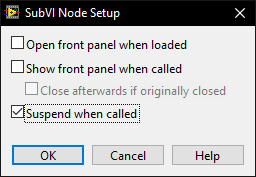
It may be in the codebase for 30 years but when debugging I may need to use the suspend (see below) to trace another bug through that and many other VI's.
There is a setting on subVI's that allow the FP to suspend the execution of a VI and allow modification of the data and run it over and over again while the rest of the system carries on. This is an invaluable feature which requires a front panel

This is simply not true and is a fundamental misunderstanding of how exe's are compiled.
Can't wait for the complaint about the LabVIEW garbage collector.
We'll agree to disagree.
^ 100% all these things.
-
1
-
-
On 6/29/2024 at 9:55 PM, mcduff said:
You may not be able to specify the channels in any order you want. If I recall correctly for some DAQs you can only specify them in ascending order.
Interesting! I never actually tested my assumption.
-
Will be in the order you specify the channels, so 1,7,3,6
-
You are trying to run before you can walk.
Try and get something (anything!) to display on the 3d graph. Read some docs to understand how to use its API. Once you understand the data you need to pass into it you should be able to display something on it. Then you will need to figure out how to get the actual measurements/information you care about to be displayed.,
-
Pasting this here for others to see in case they don't want to download the VI.
OK, so it looks like you "just" need to update the graph now. What have you tried so far?
-
What have you done so far?
Using polymorphic VI as data selector for a Var_Tag array data type
in LabVIEW General
Posted
How do you look up the data in your array? Via --Tag? If you are going to do that you might as well just use a map.
But anyway, I am not a huge fan of this approach. I think better composition into clusters or objects will also make your wiring neater, more testable, scalable etc
I do recognise the need for nice neat diagrams without wires going all over the place, but proper decomposition/architecture normally fixes this.
So in general I would have to say you are not on the right track with this approach, but this is of course just my opinion.