Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-

Traits - An alternative to interfaces, mixins, etc.
Daklu replied to Daklu's topic in Object-Oriented Programming
No, I don't think that would be necessary. Classes could be composed with traits, but the trait isn't owned by the class. I envision it would be similar to how a class can be a member of another class, but the first class isn't "owned" by the second class. They're still two separate entities. Using LV's current paradigm a trait would need a fp representation (similar to a class) so it could be put in a class, but since they are stateless (like a library) there wouldn't be a .ctl or wire associated with it. Yeah, and it seems to be a more natural fit for Labview than Interfaces or virtual classes. I have to confess I do have a bit of an ulterior motive to posting this paper. Traits as implemented in the paper closely align with how I prefer to build code--small units of reusable code with focused fuctionality that are composed into larger units (classes) based on the needs of the application. One of the biggest problems I face is creating applications with a lot of composition means there's a lot of delegation. Delegation methods are boring to write and I've had several people complain it's too confusing. Traits could be a partial solution to that issue. Some of the details still escape me though... For example, a trait provides a set of methods that implement a behavior and requires a set of methods the class (or another trait, or perhaps a child class?) needs to implement. (page 7) Can these methods be overridden in child classes? My guess is provided methods cannot be overridden but required methods can. I'd like to play around with a language that implements them and see how they work. Yes, absolutely. I don't expect all the class' behaviors are defined by traits. In addition to overriding a required method, there will still be times when you'd want to derive a child class to change behavior (such as creating test doubles) or to add new methods. -
Recently I ran across a paper describing Traits as an alternative and superior construct to handle code reuse. From what I understand they are similar to Interfaces except they allow (but do not require) the Trait to implement the methods it defines. Classes can be built by composing the traits containing the functionality you want the class to have, thus avoiding the inheritance problems associated with multiple inheritance and mixins. I'd love to see traits implemented in G. I think it would something of a cross between an lvlib and lvclass, with a bit of it's own features built on top. I'm pretty sure you can manually build the code structure traits encourage, but having an .lvtrait construct would make it so much easier. Thoughts? [Edit - Posted to Idea Exchange]
-
I think it offers better reusability and less work. The time/complexity curve isn't linear--it's exponential. The best components are those that excel at a single task. They are easier to write, easier to test, and easier to read/use. It's harder to understand a single component doing two things than it is to understand two different components doing one thing each. If your use cases are constrained enough to allow you to ignore the problems with Postman class hierarchy, that's great. As a reuse author I have to think about what others might need to do, not just what I need to do. Writing a custom proxy isn't that big of a deal. Essentially you're just transferring messages between a queue and a tcp connection. Throw in whatever additional functionality you want, like persisting data to disk in case of network failure, and you're done. If you have a TcpConnection class and a TextPersistence class in your reuse library that encapsulate some of that boilerplate code, all the better. That may be true. What happens the other 10% of the time? As soon as you run into a situation where the generic solution doesn't work you're forced into clumsy workarounds that are unnecessarily complex. Additional changes are thrown on top of that, making the problem worse. I know 98% of the time when I write code before I need it (such as building persistence into TcpPostman) I get it wrong--usually because there are additional constraints or requirements I hadn't thought of. If you find yourself getting tired of writing proxies, perhaps a better solution would be to create a reusable Proxy class encapsulating the common requirements. Then you can create a ComponentProxy class (possibly with Component or Proxy as the parent, depending on the situation) and extend/customize it for the specific need. This is the point I was making earlier with your use cases being limited. In your case it sounds like there is an implied requirement that if the app fails for some reason you can rerun the test. Would you change your opinion if your app was doing the data collection for a test that cost $2 million to run and a network failure caused lost data? We all tend to be rather egocentric when it comes to implied requirements. No wonder, they're usually just subconciously assumed rather that stated. (If they were stated they'd be explicit requirements.) They influence our development patterns without us even knowing it. In my experience, they remain subconcious until we're forced into making a change that violates one. Then it smacks me in the face and taunts me. (*smack* "Whatcha gonna about it, huh? You can't touch me!" *smack*) I hate that. Additional functionality is never free. It costs processor cycles, memory, hard disk space, and developer time while you (and future devs) learn the api. The costs may be acceptable to you and your employer, but it's not free. Yep, and I can keep saying no. I understand how a Postman class would be desirable if you're using an architecture based completely on publish-subscribe. But publish-subscribe isn't always appropriate and I'm not willing to put constraints on MessageQueue (or any other message transports I create in the future) by making it a child of Postman in order to simplify that one use case.
-
Queues, notifiers, network streams, globals, shared variables, etc. are all ways to get information (a message) from one part of your code to another (usually parallel) part of your code. They are simply transport mechanisms, each of which is tailored for specific situations. How the message is used (or even if it is used) is irrelevant to the transport mechanism. I agree notifiers are generally not a good way to transport messages that must be acted on, but it is still a method of transmitting messages. That's why I use queues. That's not to say all messages received on the queue must be acted on. I frequently ignore messages (dequeue and do nothing) when the loop is in a state where the message is invalid. It appears this is one of our core differences. I'm not looking for plug-and-play interchangability between message transport mechanisms. It's an additional abstraction layer I haven't needed. I decide on the best transport mechanism at edit time based on on the design and purpose of the receiving loop. Most of the time a queue is the best/most flexible solution. Occasionally a notifier or user event is better for a specific loop. Yep, but you'll notice the class isn't named "Universal Message Transport." It's named "Message Queue." It's intended to be a fairly low level LVOOP replacement for string/variant queues with a few built-in messages to improve code clarity. There could also be a "Message Notifier," "Message Network Stream," etc. I'd build a light wrapper class for Network Streams (or straight TCP if I was so inclined) with methods specific to that transport mechanism, similar to what I've done with Queues. That class would not be a child of Message Queue. Nope. You're saying you want an abstraction layer that allows you to transparently replace, CompA --QueuePostman--> CompB with, CompA --TcpPostman--> CompB and have things just work. I don't think that is a realistic or desirable goal. There are different requirements and concerns for managing tcp connections than there are for managing a queue between parallel loops. For example, suppose you're sending sensor data from one loop to another loop so it can be stored to disk. What happens when the link between the two loops breaks? Generally this isn't a concern using queues--you can verify it via inspection--so there's no point in writing a bunch of code to protect against it. But it is a big concern with network communication. How should the sender respond in that situation? In the sending loop SendMsg is inline with the rest of the processing code so it will (I think) block until connection is reestablished or times out. Do you really want your data acquisition loop blocked because the network failed? My solution is to insert an abstraction layer when it is needed, going from this, CompA --MsgQueue--> CompB to this, CompA --MsgQueue--> CompBProxy --Tcp--> CompAProxy --MsgQueue--> CompB. Advantages: I'm not carrying around extra layers of abstraction in code that doesn't need it. (Reduced complexity) The purpose of each loop/component is clear and distinct. (Separation of Concerns) I don't have to change any of the code in CompA or CompB to implement it. (Open/Closed principle) I can implement special protection, such as saving the data locally, when network problems arise. If I am ever faced with a situation where it's advantageous to handle different transports as a single type, I'll create a MessageTransport class and use composition/delegation to accomplish what I need. Using the network example from above, *something* on ActorB/CompA's side of the tcp connection needs to store the data locally if the network fails. What's going to do that? TcpPostman? Yep, right up to the point where you need one of the other functions. Then that one becomes crucial too. Yes they do, but they don't provide the level of control that is sometimes needed with a message queue. It's rare that I need to preview or flush a message queue, but when I do having those abilities saves me a ton of rework that would be required to implement the same functionality. Plus there are other subtle issues with events that I don't have to worry about with queues. From a general purpose messaging standpoint, queues do everything user events do but do it better. Absolutely you can, and I encourage you to do so... but it doesn't mean *I* should.
-
So... you feeling lonely and want us to pm you for a personal copy, or what? The things is, I *thought* I had done most of that in the first exam, which I failed. I also *thought* I did less of it in the second exam, which I passed...?
-
I've thought about it a bit in the past but don't really like it for the following reasons. As before, you may or may not view these reasons as sufficiently valid for me deciding not to do it. I don't see much point in creating a common parent unless I'm going to be using that parent in the code somewhere. A common parent (I'll call it "Postman" for lack of a better term) that abstracts the underlying message passing technology (queue, notifier, user event, etc.) would be very small. The Postman class can only expose those methods that are common to all child classes--essentially, "SendMsg" and "Destroy." But, if we look a little closer at SendMsg we see that the queue's SendMsg implementation has multiple optional arguments whereas the others have none. That means Postman.SendMsg won't have any optional arguments either and I've removed useful functionality from the queue class. Two classes inheriting from a common parent should share a lot of common behavior. Events and queues share very little common behavior. True, they both can be used to send messages in an abstract sense, but that's about it. They offer very different levels of control (i.e. have different behavior.) (True story: Several years ago when I first jumped into LVOOP with both feet I thought (as most OOP newbies do) that inheritance is the answer to most problems. I was working on a project that handled many different instruments and figured (again, as most OOP newbies do) I'd have them all inherit from a common Instrument class. After all, I have to Open and Close all of them, right? The further I got into that project the more difficult it became to work all the functionality I needed into each instrument's Open method. On top of that, I didn't actually use Instrument.Open anywhere. The class heirarchy was an artificial constraint I had placed on myself and was contributing nothing useful to the project.) Another reason for using inheritance is to make it easy to change functionality. For example, I'd like the PriorityQueue to be a child of the MessageQueue class. That would make it very easy for LapDog users to start a project with a MessageQueue and--if they get to a point where the project requires it--replace it with a priority queue by simply changing the constructor. Queues and user events are not interchangable by any stretch of the imagination, so there's no benefit there. All in all, the "convenience" of having a single SendMsg method that works for both user events and queues simply isn't worth it. Wrapping notifiers makes more sense to me from an overall api standpoint than wrapping user events and I've considered that somewhat more seriously. I haven't done it yet mostly because I haven't needed it. Queues can do a remarkably good job of duplicating Notifier functionality. There are two main things that differentiate notifiers from queues: 1. Notifiers only store the last message sent. Easily replicated using a single element lossy queue. 2. Notifiers send message copies to each receiver. (One-to-many.) Generally in my code when messages need to be copied it is done by the component that 'knows' multiple copies are needed. For example, the mediator loop of the component that 'owns' the two receiving loops copies the message when it is received and sends a copy to each loop. I view notifiers and user events sort of like specialized queues to be used in specific situations. I find notifiers most useful when a producer generates data faster than a consumer can consume it and you don't want to throttle the producer. (i.e. You want the consumer to run as fast as possible or you have multiple consumers that consume data at different rates.) Unless those situations are present queues are more flexible, more robust, and imo (though many disagree with me) preferable to either of those for general purpose messaging. One thing that is important (imo) for robustness is that each loop in your application have only a single mechanism for receiving messages. (Nesting say, a user event structure inside a QSM's Idle case, can easily lead to subtle timing issues that don't show up in testing.) If you have a loop that sometimes needs queue-style messages and sometimes needs notifier-style messages, that's a good indication your loop is trying to do too much. Break it out into one loop with a queue and another loop with a notifier. One possible implementation for this kind of object is to create an array of notifiers, one for each message. It would have to have a separate table to keep track of the dequeue ordering. Another possible implementation is to use a single queue and every time a message is enqueued it iterates through the queue and replaces the previous message with the same name. A third implementation is to use a hash table. Regardless of the implementation, there are design decisions I'd have to make that end up reducing the overall usefulness for a subset of the potential users. -When a message is replaced, should the replacement message go the rear of the queue or hold its current position? -Since we're going to be searching and replacing data, the data structure used to store the messages and the search algorithms are going to have an impact on performance. Should I favor speed in exchange for using more memory (hash tables) or should I strive for a minimum memory footprint (array) and take the performance hit? -Should I do the searching and replacing in the Enqueue method or Dequeue method? In other words, which loop should take the performance hit for the added functionality? There are no absolute answers to these questions. It's up to the developer to weigh the tradeoffs and make the correct decision based on the specific project requirements, not me. ------------------ [Edit] BTW, even though I've rejected nearly all your suggestions I do appreciate them. It challenges my thinking and forces me to justify the decisions I've made. I hope my responses are useful to others, but the act of composing responses has led to several "a ha" moments for me.
-
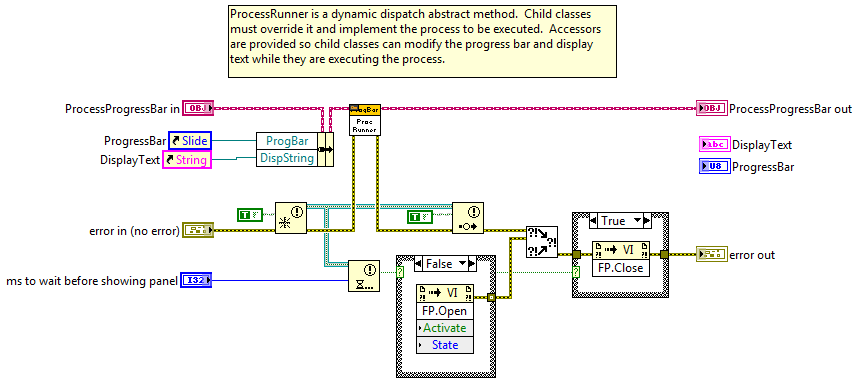
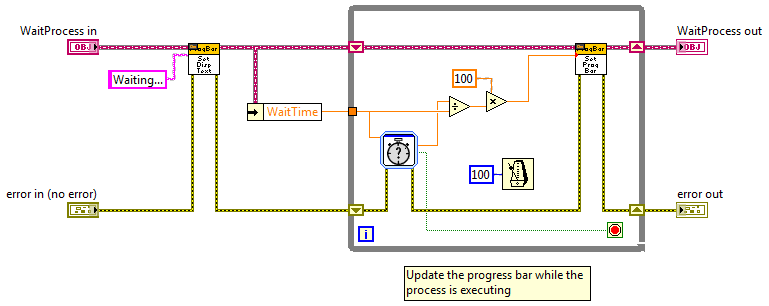
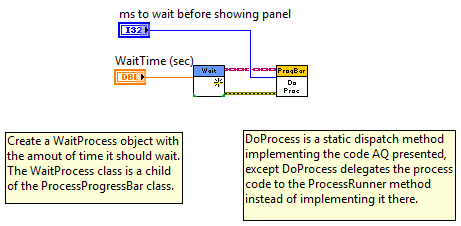
For kicks and grins I whipped up a quick example of a reusable and semi-generic process progress bar using (of course) LVOOP. I wouldn't consider this adequate for a reuse library since it is UI-centric, but it is something I might use as reusable code within an application. Code is in LV2009. Example Code BD ProcessProgressBar.DoProcess BD WaitProcess.ProcessRunner BD FYI... from LV2009 help, Generate Occurrence Function: Note National Instruments encourages you to use the Notifier Operations functions in place of occurrences for most operations. Whether or not that means they deprecated occurrences is subject to interpretation I guess. ProcessProgressBar.zip

-
Uhh... straighten out your error wire? (j/k ) Clever. I can't help but think about ways of generalizing it into a sub vi that can execute an arbitrary process. Hasn't NI deprecated occurrences in favor of notifiers?
-
I understand what you are asking, but a closer examination (triggered by Steve's comment) leads me to conclude your question is meaningless. How so? If there was really "nothing wrong with" the code you would have no desire to change it. The very fact that you made a change means you believe something was wrong with it. (Assuming, of course, your intentions are to improve the code base.) Why do I bother pointing out what appears to be an irrelevant non-issue over the question's semantics? Because underlying your question is an unstated assumption that, in my opinion, is the leading cause of software rot. "to avoid an "ugly solution" that was robust and really had nothing wrong with it" This phrase implies functionality is the only thing that matters--as long as the software functions correctly it is good. I disagree. Functionality only relates to the external quality of the software. Professional developers should be just as concerned with the software's internal quality as well. We all know block diagram style plays a huge role in how easy it is to read and understand what is happening. There are other things that contribute to internal quality as well: Choosing descriptive names for sub-vis, creating clean apis for the components, project explorer organization, consistency throughout the application, descriptive comments, application architecture, etc. Most LV developers do reasonably well keeping block diagrams organized, often to the point of obsession. (How frequently do we shift a wire 1 pixel just to fix a bent wire?) Somewhat fewer of them spend much time on the other things I listed. I think I can boil down your question to this: Is spending time improving internal quality worthwhile? Absolutely. Continuous refactoring, one of the principles of agile development, is all about improving internal quality. The trick--and the root of many disagreements between developers--comes in figuring out how much quality is needed. What one dev sees as a quality improvement another dev sees as a waste of time or unnecessary obfuscation. I know you smilied this comment, but I am compelled to respond to it as if it were a serious response anyway... Less is not more. Less is just what it says it is... less. Promoting 'less is more' implies we should develop applications with minimalism being our goal. (Minimal what can be debated... minimal # of vis, minimal size, minimal dev time, etc. I'll collectively refer to them all as stuff.) That, imo, is the wrong way to think about it. We should be trying to create the correct amount of stuff to satisfy all the project's requirements, not just the functional requirements. 'Less is more' is a useful reminder when people are in the habit of overdoing something. (Makeup, salting foods, etc.) In my opinion the LV community by and large errs on the side of not enough stuff, not too much stuff.
-
Really? What's your main mechanism for inter-loop communication?
-
Wow, now you're getting into the realm of large messaging middleware system companies charge through the nose for. It would be interesting to work on something like that but it's way outside anything I've ever been asked to do in Labview. I've written abstract DialogBox classes before where each unique dialog box is a separate child class. Giving the parent class a static Launch method ought to work, though I don't remember if I've specifically tried it. Actually I was thinking about debugging and maintenance more than writing the code to launch the vi. Personally I find it a pain to debug code when dynamically launched vis are used. That's exactly what I do when using LapDog.Messaging. (At least the technique is the same. Updating front panel controls may or may not occur in the user input loop.)
-
Actually, NI goes to great lengths to make sure their grading system is consistent. Every exam is checked by two people and from what I understand they almost always come within a few points of each other. Still, being consistent doesn't make it understandable. Having taken the exam twice now, I still have no idea of what they're looking for in a solution. It makes it very hard to prepare for an open-ended exam. It feels a little bit like writing a paper on the history of philosophy but having the grade determined (unbeknownst to you) by how many different philosophers you quoted. I know NI has been at least talking about alternate recert methods--advanced presentations, etc. I plan on going that route myself.
-
Never done the beeping bit, but I have done auto-cancelling dialog boxes. Problem is determining a time everyone can agree is appropriate. They want the wait time to be short when they're not interested in it and long when they might be distracted by something else but still want to interact with the app. Users... *sigh* Been down that road. It certainly works, but unless you want to create a unique loop for every dialog box (not very scalable at all) you're pushed into calling the vi dynamically and dealing with those associated headaches. I find it easier to save dynamic calls for those situations when they're really necessary. That's a good question. All loops need to be able to receive messages, at the very least so they can receive an 'Exit' message. For loops with an event structure I create a user event of the generic message type and put a message handling case in the user event handler. (The screen shot shows a generic "DisplayPrompt" message handler I created earlier that I am in the process of refactoring away to improve readability.) Some people like to use user events as a general messaging construct, but I prefer queues due to their flexibility, transparency, and robustness. The only time I use user events is for sending messages to user input loops. The data that is displayed in DeltaZ comes from the Core and is routed through the mediator loop. If the UI loop need to know DeltaZ as well then I can either copy the data in the mediator loop and send it to both the display and UI loops or store the data with the mediator loop and send it to the display loop with the command to display the dialog box. The exact implementation I use depends on the specifics of the application. (Why do they want a new dialog box for validating their inputs? Seems like it would be easier to color controls red if the input is invalid, refuse to let them progess until valid inputs are entered, or something like that.) I respectfully disagree. The ideal queueing system does exactly what the current queue implementation does. It spits things out in the order it received them with very little overhead while providing users with the ability to add on additional functionality if they want to. What you're asking for adds overhead to the queue functions. To the best of my knowledge Enqueue and Dequeue are O(1) operations. Saving only the last version of each message will turn at least one of them (probably Dequeue) into an O(n) operation as it has to iterate through the entire queue to check for duplicates. As a developer, I can make a decision to wrap NI's low level functions in sub vis to add functionality in exchange for requiring more execution cycles, more memory, etc. I don't have any way to remove functionality from those functions to make them perform faster if that's what I need. I generally oppose the Idea Exchange posts that ask for new features or options on the low level functions for this exact reason. Convenience always comes with a cost. I will say that over the years I've seen several requests for this kind of feature. I have run into the same kinds of issues you have and at one time wished for the same thing. However, I humbly suggest that the problem may not be a lack of functionality in queues, but is instead the result of the programming patterns you are using. Specifically, I believe the need for this kind of queue functionality comes about from indiscriminantly using QSMs and insufficient planning. (Though I have nothing other than my own anicdotal evidence to support the theory.) You mentioned a state message is rendered obsolete in a few seconds and would like the old message replaced in the queue by the new message. If I may ask a pointed question, why do allow messages--which should be propogated immediately through the application--to sit around in the queue for several seconds unprocessed? What can you do to improve your application's response time to messages? When I asked myself those (and other) questions I ended up with the hierarchical messaging architecture. Creating more complex queue functionality may be a workable solution, but I have to say that since I've started using hierarchical messaging the need for complex queue functionality has disappeared. In fact, even though I created a priority queue for LapDog, I've found my messages are processed fast enough that I don't ever need it. -Dave
-
Easy enough to implement by extending LapDog.Messaging or rolling your own wrappers.
-
I absolutely agree with you Greg. The front panel is a throwback to the days of widget-based programming. In some ways LV reminds me of programming in VB6. Widgets are great for RAD--which certainly is part of Labview's core audience--but as many of us have experienced they become too restrictive when trying to do something outside of the predefined functionality they provide. On top of that, widgets tend to couple business code to the UI, which hurts in the long run. I recall other discussions where AQ or another blue commented that they are working towards the point where a block diagram can be loaded without loading the front panel, but it's a slow and tedious process. Perhaps once they accomplish that we can toss the fp altogether.
-
So I posted my ealier frustrations with the CLA Exam in Nom, Nom, Nom..., and since I recently presented at a user group meeting I was given the opportunity to take the exam again on the 19th. I'd been so busy I haven't had any time to practice but I figured I might as well. The second exam problem was very similar to the first, but I think a few requirements had been removed. My impression was that it had been simplified a bit. The first time around I worked on the api's for each major component and tried to get them connected together via messaging. None of the components were fully implemented. I had developed the messaging structure and tried to make sure the mediator loops (that handle message routing) were routing messages to their correct destinations. Honestly though, I don't remember how complete that part of the app was. At the time I felt like I had developed a reasonably good framework that could be filled in by CLDs who understood the framework. As I detailed in Nom, Nom, Nom..., NI disagreed. One piece of feedback I received from NI while reviewing the first exam was to implement one component completely so developers could use it as an implementation example for the other components I design. I did that this time around, but it took so much time I didn't do any work on several modules and the top end component tying all the pieces together wasn't fleshed out at all. When I finished the exam my solution felt far less complete than my solution for the first exam. There were many [Covers: xxx] tags I didn't get around to working on. I left with no expectations whatsoever and figured I'll keep presenting and keep retaking the exam until they take pity on me or just get tired of seeing my name. To prove truth is stranger than fiction, I passed. I am honestly just as surprised I passed this time as I was that I failed the first time. The overall structure of my app was the same this time around as the first time--components executing in parallel communicating via hierarchical messaging and Harel/UML style state machines as needed. I think I used class-based state machines the first time whereas this time I used a flat state machine contained on a single block diagram. That might have made it easier to understand but IMO is an implementation detail not terribly important to the overall architecture. I'm not complaining about passing but I have to say I still don't understand NI's grading system at all. Here's my scoring breakdown with evaluation comments in parentheses: Style: 10/10 Documentation: 16/20 (Architecture/modules not documented adequately for developer to implement/complete functionality.) Req Coverage: 18/30 (Percentage of requirements covered = 60%.) Arch Development: 30/40 (Comments had 4 different "xxx module not designed.") Baffled... (See y'all at the arch summit! )
-
I used to do that too, but combining display updates with user inputs can easily cause subtle issues that may not become apparent until it's too late to fix easily. For example, what happens if a dialog box blocks the thread? No display updates are shown until the dialog box is cleared. What if nobody is around to clear it? The event queue will keep growing until eventually LV crashes with an out-of-memory error. Or maybe the dialog box is sitting there for 3 hours before somebody notices and clears it. Then they get to watch as the UI catches up with the last 3 hours of data updates. In general I have found that combining functionality--like so many things--is slightly faster to implement in the short term but costs way more time in the long run. Yep, it is. I prefer not to use globals, but sometimes business decisions override architectural decisions.
-
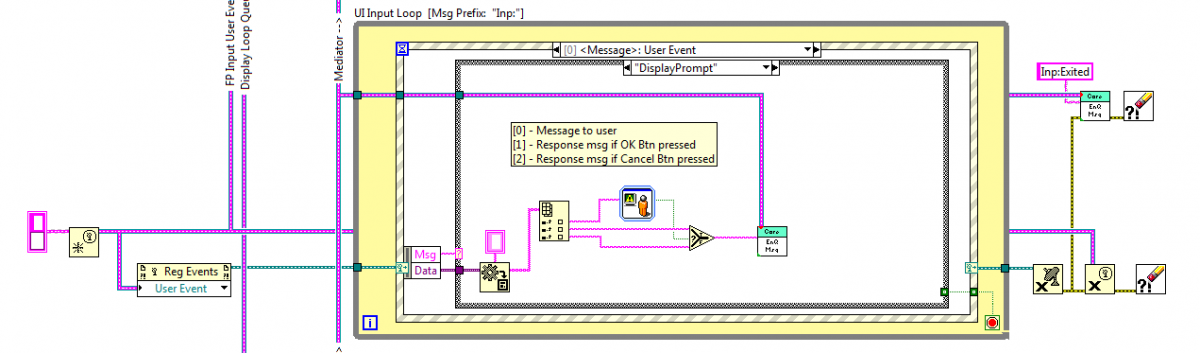
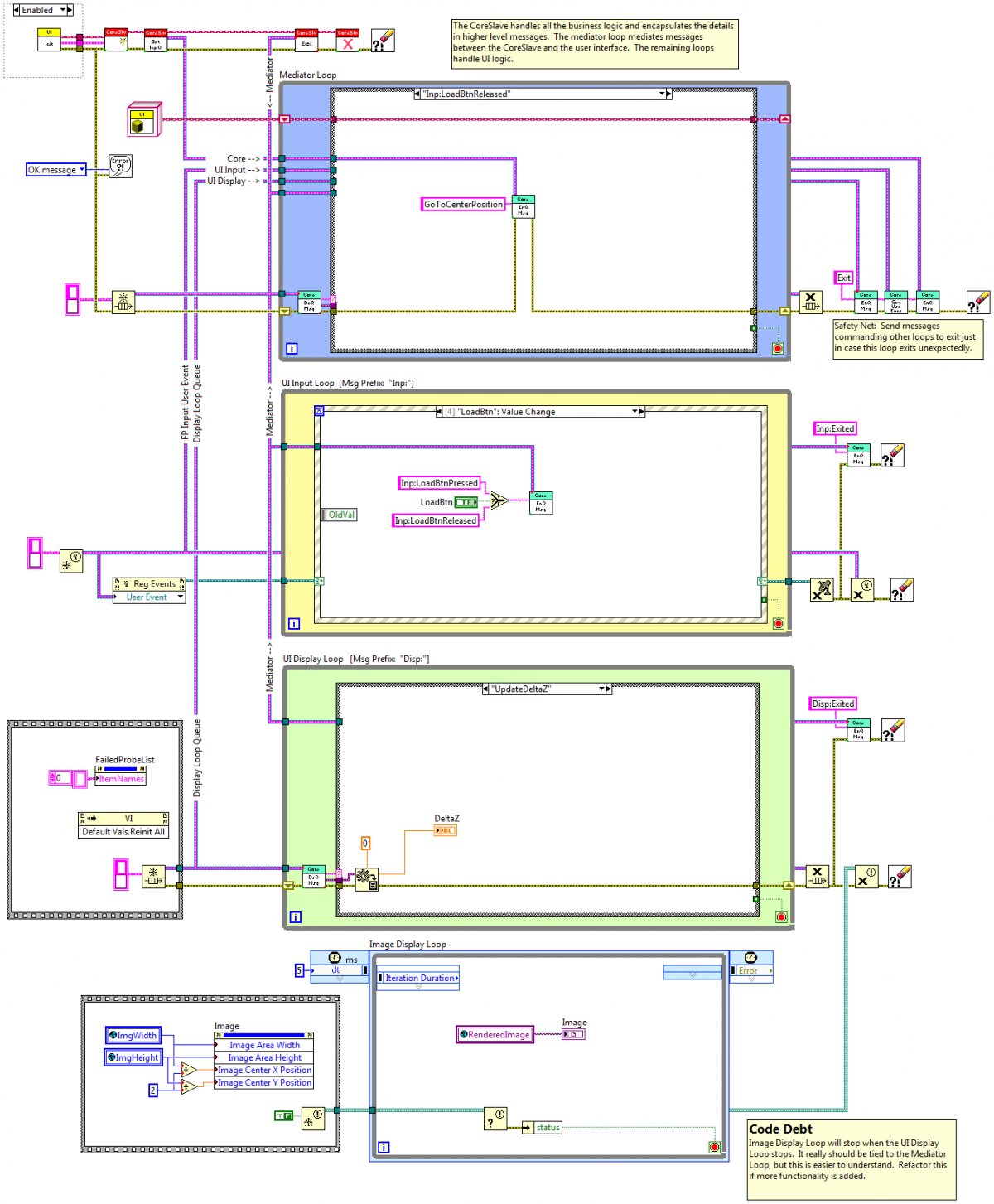
Still short on time... quick response. (Some day I hope to go back and answer your previous questions.) Correct. Here is a bd of the main ui in an app I am currently working on. This app uses a hierarchical messaging architecture I've described elsewhere. Each component has a mediator loop that handles all message routing between the external world (external to the component, not external to the app) and the various internal parts of the component. You can see the event structure for the LoadBtn control. It passes an "Inp:LoadBtnReleased" message to the mediator loop, which in turn passes a "GoToCenterPosition" message on to the application's business logic contained in the CoreSlave. There are two negative side effects of sending the Inp:LoadBtnReleased message down into the functional code: 1. If I want to change the way the user triggers moving the system to the center position, I have to change the name of the message through the entire app. It's not particularly difficult, but it is annoying and prone to errors. 2. More importantly, a "LoadBtnReleased" message doesn't have any meaning in the context of the CoreSlave or its subcomponents. They don't know anything about the UI. In fact, I can run the app without a UI at all if necessary. Suppose there were a need to automate a process normally done by users via the UI. I can drop the CoreSlave on a new bd, queue up a sequence of messages to execute the process, and let it run. Having a "LoadBtnReleased" message in that situation makes no sense and reduces readability. (Note: You'll notice this app doesn't use LapDog.Messaging. That was due to business reasons outside of my control. Instead I recreated the enqueue/dequeue functionality using traditional string/variant messages.) I'll think about it. It goes against my instincts, but you have made valid points. Rather than directly editing the LapDog.Messaging library, a better solution is to write your own wrapper class that provides the interface you want (polymorphic vis with variant support) and delgate the functionality to LapDog. That way minor version upgrades will be (mostly) painless. In practice they probably usually are, but there's nothing about them that would prevent a well-constructed command message hierarchy from being reusable. To be honest I don't use them much--they tend to cause more coupling than I like. -Dave
-
Uhh... Coloring the label red then showing the caption instead kind of defeats the purpose of coloring it red in the first place doesn't it? I agree with you regarding caption use, but I sure wish it were easier to switch back and forth between them. Maybe a hotkey combination that switches all fp controls between showing the label and showing the caption.
-
I'm not saying using the control label as part of the message name is wrong. If that's a practice your development group standardizes on and everybody is comfortable with it then there's no problem. I'm just saying I don't like to use it for the reasons I stated. All the LapDog components (currently Messaging is the only released package, but Collections and Data Structures are around too) are intended to be usable by LVOOP developers regardless of their particular style. I don't provide everything needed to implement a given style, such as a Variant message, or a Command message, but they are very easy for developers to add on their own. Readability, probably yes. Testing, maybe. Flexibility, no. A lot of it depends on the project specifics, who the users are, and how much the user interface abstracts the implementation. If your software controls a system of valves and sensors and the operators are engineers who want direct control over everything, then yes, using control labels for message names might make sense. For higher level applications my fp events trigger "MyButtonClicked" messages. What that message actually does is handled elsewhere. Propogating fp control names down into functional code follows fairly naturally if you're using a top-down approach. In my experience the top-down approach leads to less flexible and tighter coupled code. Abstraction layers tend to leak. Using the bottom-up approach I name messages according to what makes sense in the context of that particular component, not based on what a higher level component is using it for. In theory it is, though I don't know how practical it would be. What breaks compile-time type checking is casting to a generic type--variants or a parent class, which is required to send multiple types over a single wire. If one were to create a messaging system where every data type sent had a unique queue for it then type checking would be maintained. The difficulty is in figuring out how to write the message receiving code without making a complete mess. Eliminating (or significantly reducing) run-time typecasting errors was my original goal of LapDog.Messaging. Creating a unique type (class) for each message and encoding the message name as part of the type eliminates a lot of the risk, though not all of it. Even though I've adopted a more generic approach with the current LDM release, users can still implement a "one message, one class" approach if they want. That's a good idea. (As long as the control isn't on the UI.)
-
I've been thinking about this thread, but unfortunately I have been too busy to give it the response it deserves. Yep, you're right. For the life of me I can't remember what I was thinking when I wrote that... However, that still means you have code down in your message receiving loop that requires knowledge of the UI. Specifically, it has to know the control's label. Labels are one of those things that--in my experience--developers tend to change without thinking too much. Writing algorithms that unnecessarily depends on label text causes brittle code. This is one area we differ. I'm more concerned with creating code that is sustainable rather than code that is easy to write. Often times these goals exert opposing forces on your design decisions. In fact, there is a noticable decrease in my code's sustainability when I try to make code that is "easy" to write. Readability, testability, extendability, etc., all take priority over writability. This is only true when the data from the two modules are linked together directly. If you drop a value in a variant message to send it to a different loop the compiler can't verify the run-time type propogation is correct. In the hypothetical world where Labview ran the Mars Orbiter, using typed units may not have prevented the problem. There's more I wanted to comment on, but I'm falling asleep at the keybroddlxz.z.zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz...
-
Just a quick response... I'm short on time. My initial thought is doing something like your example pushes UI code down into your application and is probably best avoided. Multiple controls can be registered for the same case (and I do it sometimes myself) but somewhere in your code you need to figure out exactly which control triggered the event and respond appropriately. I believe the best place to do that is in the event handling loop. I wasn't aware different units were considered separate types. To be honest I've always thought the units were more trouble than they were worth. I'll have to think about that for a while before deciding whether or not to add a variant message. I like your other examples too, though I need to study them some more before I comment on them.
-
[Grr... whoever decided the backspace key is a great hotkey for the browser back button needs to be shot. ] I had a rather lengthy response typed up, then made the mistake of trying to delete text using backspace. Here's the short version: There are several reasons why there isn't one. You may or may not view them as valid. 1. Variants are usually used for custom data types, which implies typedeffed clusters or enums. I don't like using typedeffed clusters as part of my public interfaces between components. Their lack of mutation history makes it too easy to unintentionally and unknowingly introduce bugs. 2. Historically, the current LapDog.Messaging package evolved from a similar library where every message was a unique class. When that proved too cumbersome for my liking, I moved towards the current system with message classes based on message data-types instead of the message itself. Since my goal is to send data, not send a variant (the variant is just packaging that allows arbitrary data to be sent on the same wire,) I never had a reason to create a variant message type. 3. When I'm building an application one the things I'm most concerned about is the interactions between components and what the dependency graph looks like. Variant message, imo, obscure the dependency relationships that are being created. Sending data via a variant message is as easy as hooking an arbitrary wire up to a variant input terminal. I may not realize I've created a new dependency until I go to code the message receiver and try to convert the variant to real data. Who knows how much work I'll have to redo to break the unwanted dependency. By requiring a new class for each message data type (or to a lesser extent dragging the message creator from the project window) I'm forced to confront and resolve the dependency issues before I write the code. Ultimately, the decision about VariantMessages is left to the individual. I never intended the packaged message types to be a complete set... just the most common ones. I always create application-specific Message child classes with custom data types, and users should feel free to create their own Message child classes for reuse that are appropriate to their situation. Yep, it is. Personally I have no desire to create and maintain all of them. Maybe someday NI (or a charitable Lava contributor) will do it. I've already explained why I don't use variants, but that doesn't make the need for classes for each custom data type any less daunting. Personally I think that requirement is more or less a result of Labview's G's nature as a statically typed language. Using variants doesn't solve the problem, it just moves it around a bit and makes it harder find. Looks like a conversion issue. Here's a bd from LV2009.
-
Ahh... I had seen a reference to the Xilinx tools but I didn't realize it was required for cRIO applications. I thought it was only required if I was compiling to some third party fpga target. I downloaded 11.5 and successfully took the next baby step. Thanks everyone. (Have a round of kudos... on me.)
-
I don't think I've ever ventured into this forum before, but after 5 years of LV desktop development I now have a cRIO project on my plate. So... after fumbling around a bit I was finally able to connect and configure the device. Now I have some FPGA code I'm trying to compile and I keep getting the error, "The compilation tools are not installed on this machine. Run your LabVIEW FPGA installer again and select the compilation tools, or try connecting to a compile server on another machine." I've run the FPGA Module as well as the NI-RIO installer several times, but I'm not seeing any options for compilation tools. I've scoured the documentation and online content and keep coming up empty. Can anyone tell me what I need to install to get the FPGA compiler tools? LV2010 sp1 NI-RIO 3.6.1 cRIO 9118 Chassis cRIO 9025 Controller