Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Yep, that's what I was thinking if a single readable config file is a requirement. Meh, if it works for you it's right... but here are some things you may or may not have considered: -Using FP controls to store data in memory is somewhat common, but imo it is needlessly confusing. It's also much slower to read/write than block diagram data. As a general rule I only put something on the FP if it's a sub vi input, output, or UI stuff. -Be sure to think about how you will handle versioning issues with the ini file. What happens if the software is expecting version 2 and the ini file is still using version 1, or vice versa. Like Paul, I use typedefs whenever class data is being serialized. It feels redundant but I find it makes it easier to manage versioning. -We developers like writing cool and elegant code that adapts to different situations. It more fun and it's way more interesting than boring mundane code. On the other hand, simple mundane solutions are usually easier to write and read than the clever solutions.

-
My original thought was that it closes off a larger section of code to multiple developers. In hindsight, it's not so much that I have a problem with version control and nested libraries, it's more that nested libraries in general don't serve any purpose for me. I use project libraries to define software components. Usually I want the components to be loosely coupled to other components to facilitate reuse. The only reason I can think of for nesting libraries is for organizational purposes when a component is made of several subcomponents. However, by combining multiple subcomponents into a single library I can no longer use a subcomponent in another app without dragging all the other subcomponents along with it. I retain more flexibility by not nesting them. Incidentally, using a dot naming convention for project libraries is something AQ suggested to me... oh... four years ago or so when I first started crying about namespaces. I resisted for a while but, as is usually the case, I came to understand how his suggestion simplified things.
-

Re-Designing Multi-Instrument, Multi-UI Executable
Daklu replied to jbjorlie's topic in Application Design & Architecture
Good question. I agree with AQ. The line between View and Controller is a lot fuzzier than between the Model and the other two. If you're looking at diagrams like the one one wikipedia, my advice is to ignore it and do what makes sense to you. There are lots of ways to skin a cat but they all result in the same thing... tasty soup. My preference is more along the lines of Paul's "other flavor" MVC implementation. There is no direct communication between the model and view at all; it all goes through the controller. (Instead of a triangle my three components are in a line with the controller in the middle.) The controller is where I put the glue code that translates output messages from one into input messages for the other. I actually don't like calling it MVC because I don't think it's an accurate description. It's closer to a Model-View-Mediator architecture, but that's not exactly right either. Depends on your messaging topology. Applications using the observer pattern lean towards a lot of direct point-to-point communication. In these the message source usually sends a copy of the message to each receiver. I prefer a hierarchical messaging topology. In that system the thermocouple sends out a single Temp message to it's owning mediator, which then forwards it to the next mediator, and so on down the line. Copies are only made if a mediator has to forward the message to multiple destinations. Or you could always do a hybrid of the two... -
I didn't know that. Thanks for the tip.
-
Nope, there is no standard. Different needs have different solutions. On one recent project the customer didn't want the users to be able to mess with the configuration settings, so I stored it in binary format. If the config file needs to be human readable your main options are the XML palette or the Config File palette... unless you want to write your own parser. As for how to get the config data into an object, one thing I've done in the past is write Config classes with multiple Create methods. For example, there might be a CreateConfig(Path).vi that takes a path as the argument for times when I need to load the config from disk, and another CreateConfig(Data).vi that accepts an array of key value pairs for those times when I already have the data in memory. One other thing, I have found it beneficial to use unique config objects for different devices rather than one giant config object containing all the configuration data. That way I can just send the config object to the device object instead of issuing multiple configuration commands.
-
At my previous job we had multiple developers working on projects and we used TFS. One particular project had grown out of control and it was really easy to end up with conflicts when trying to check stuff in. I've since picked up some habits that help keep everyone in their own sandbox. 1. Set the options "Treat read-only VIs as locked" and "Do not save automatic changes." This is one advantage TFS and similar systems have over SVN. Since TFS uses the read-only flag to determine whether or not a file is checked out it's very difficult to accidentally change a VI. 2. Use project libraries to separate your application into components and put all vis in a library. That will reduce the number of changes to the .lvproj file and help prevent collisions. If vis are not in a library the .lvproj file has to maintain information about its location. When a vi is in a library, the library maintains the location information for all its members, meaning the .lvproj file doesn't get changed as often. 3. Make sure only one developer is working on any given library at a time. Don't allow anyone else to make changes to that library. 4. Don't nest project libraries. Putting classes in an lvlib is good, but an lvlib in an lvlib doesn't work so well. If you have hierarchical libraries you can use dot notation naming conventions on your library names.
-
Re-Designing Multi-Instrument, Multi-UI Executable
Daklu replied to jbjorlie's topic in Application Design & Architecture
I've been pretty scarce for the last 3-4 months so I just found this thread. If you're already using LapDog for messaging why not roll your own actors from scratch? They're not terribly difficult to write. LapDog doesn't care about the nature of message senders/receivers, nor does it care what kind of message is sent. If you want to use the command pattern and actors, create your own "Command" class as a child of "Message," give it an "Execute" method, and subclass that for each unique command. (I've been thinking about creating a LapDog.Actor package, but to be honest I haven't needed to use actors much.) In fact, your code may very well be simpler in the long run if you create your own actors. The downside of creating and using prebuilt frameworks is the framework needs to be flexible enough to handle a wide range of user requirements. Adding flexiblity requires indirection, which in turn adds complexity. If you have a lot of actors to write then you could create your own Actor superclass with a Launch method and subclass it for your concrete actors. I wouldn't do this. It's giving the business components (motor controller, etc.) responsibility for deciding how the data is displayed. Display is the responsibility of the UI code. Since the UI doesn't know what business component (bc) is on the other end of the queues it receives, you could have the UI send a Request_ID message to each component so it can map each bc's messages to the proper UI display. Then the UI decides what controls/indicators to show based on the response from the bc. Or, what I might do is create a BC_Token class containing a MessageQueue class for sending messages to the bc and a BC_Info class containing information about the bc at the other end of the queue. Your "initialization" code is going to be figuring out which concrete classes should be associated with each channel and creating the appropriate objects. During that process the initialization code would also create an appropriate info object for each bc it's sending to the UI. It packages the two things together in a BC_Token object and sends it to the UI as a message. -
*Visualizes Michael with a stack of hats precariously perched on his head.*
-
I'll be in Austin. I'm interested in shared/open source code, but I don't regularly use OpenG. (Mainly because there are--imo--too many dependencies between packages.) BTW, having never been to NI Week or an Architectural Summit, how do most people get from the airport to the hotel?
-
Thanks for the link Ton. I'm definitely going to spend a bit of time looking over those. I think 2009 was the latest version I've tried scripting with. The traverse vi shown in Jim's post wasn't available as far as I know, but boy it sure makes scripting easier. I still have to create a scratch vi to figure out the name of the object I'm looking for, but the whole process is much easier than it used to be. Now I just need to spend some time figuring out the available documentation tools and seeing if I can simplify my process.
-
Ahh... that's it. Thanks Jon. I guess I'll fumble around with scripting once again. As for it being super easy, I suppose once you know how to do it it is, but until then it's mostly just a frustrating expedition of trial and error. (NI hasn't published any sort of object model for the scripting engine have they?)
-
I'm digging deep in the dusty corners of my memory for this so I'm probably misunderremembering things, but... Doesn't OpenG use block diagram comments with special tags to set the vi properties documentation? Are the tools for converting the comments to documentation available somewhere?
-
I've been thinking about a pc-based oscilloscope for general purpose troubleshooting and debugging. Currently I'm considering the USBee DX and and BitScope 325. Anyone have experience with either of these products, or with pc-based scopes in general?
-
I have found removing the mutation history resolves all sorts of LVOOP ills. It doesn't always work, but sometimes it does--often enough that it's usually the first thing I try.
-
Hmm... odd question I had while converting all my xml outputs to binary strings. Flatten to String has error input and outputs, but the help file doesn't indicate if function generates any errors on its own or if it just passes through the errors it receives. I don't think it produces its own errors, but I'm not sure. Anyone else know?
-
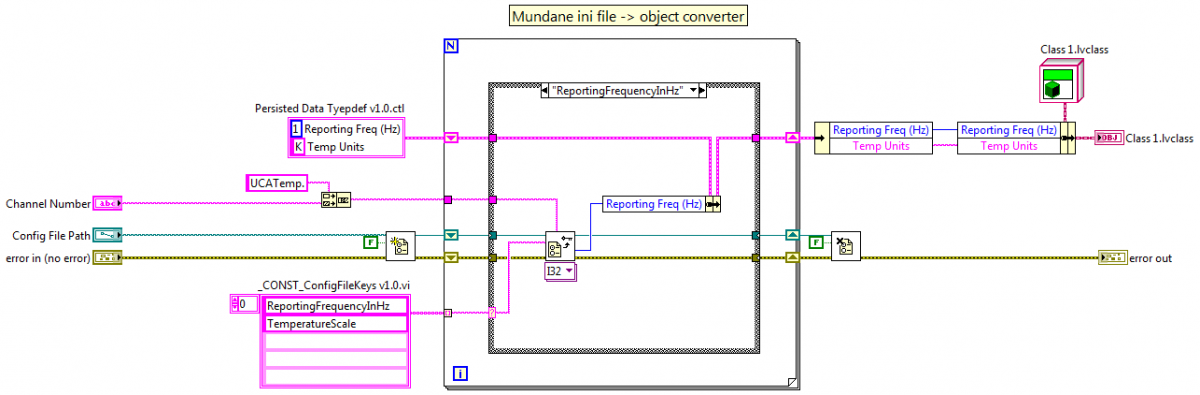
Good answers from everyone. Thanks. Primarily I meant readable by me and readable enough for an advanced user to be able to make a change if I gave them instructions on what to change and where to change it. One of the things stored in the config file is a list of available microscope zoom levels populating a certain ring control. The customer wanted to be able to easily add new zoom levels to the list. Creating a user interface and doing that via software is the better solution, but time is short so I was thinking directly editing the xml config file would be an easy work around. That's when I ran smack into the readability issue of flatteninig an xml string to xml. Based on the feedback and time constraints, I think I'll stick with binary config files and push that feature off to version 2.
-
It's far to big a topic for me to explain it in a forum post. Search Labview help for "run vi method". Include the quotes in the search string.
-
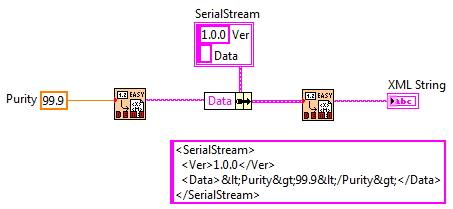
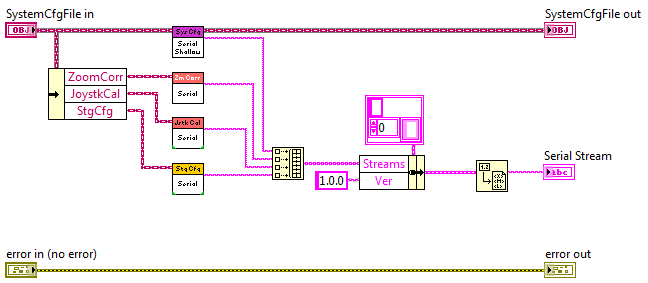
So we've talked a lot about the dangers of using LV's built-in object serialization techniques. When I save objects to disk I'll throw the data in a typedef, convert it to xml, and write it to disk. All is good. If I'm going to need version mutation I can wrap the xml data in a cluster with a version number, convert *that* to xml, and write to disk. That second xml conversion makes it a little difficult to read the original xml string. Usually it's not that big of a deal--I can figure it out enough to modify the data if I need to. In my current project I have a SystemConfig object that is an aggregation of its own data and unique config objects for several subsystems. I did this so I wouldn't have half a dozen different config files. Each config object has it's own serialization implementation, similar to the one above. (It doesn't use JKI's Easy XML. I've been exploring that on my own.) When the SystemConfig.Serialize method is invoked it in turn invokes each object's Serialize method, puts all the serialized strings in an array, adds the version number, and flattens it all to xml so it can be written to disk. This works, but all those xml conversions really mess up the readability. Has anyone found a good way to serialize aggregated objects while maintaining the ability to manually mutate the data and preserve readability?
-
Baby steps, James... baby steps. Even with that I'd still want a separate node that could do type testing. I don't use the case structure every time I'm testing a numerical or string equality and I'd probably get pretty annoyed if I had to use the case structure for type testing.
-
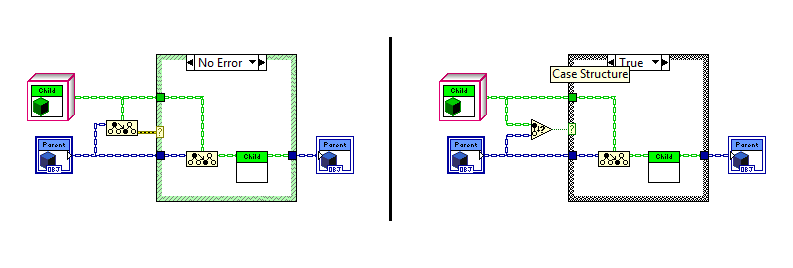
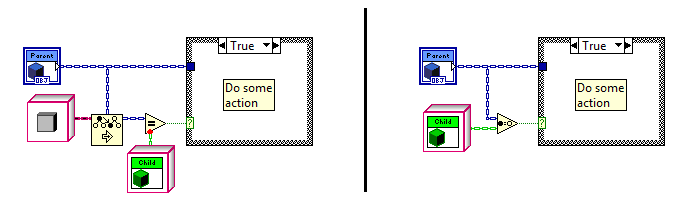
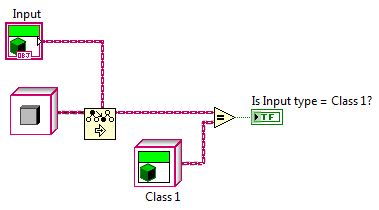
Yup, you've effectively shattered my original assertion. (Touche!) I agree, with the 2012 To node there is no functional need for an Is node. My issues isn't with functionality, it's with clarity. At its core writing code is about communicating with the compiler. Writing readable code is about communicating with future developers. The code on the left is what we'll have with 2012. The code on the right is what it would look like with an Is node. Functionally they are identical, but the average developer is going to look at the code on the left and see needless duplication. In plain english it reads like this: 1. Downcast the object. 2. If the downcast doesn't return an error, downcast the object again and call the method. Unless he knows the TMS node creates a copy when the cast fails, *and* knows that copy isn't created when the output terminal isn't wired, it looks like code that would show up on a "Look at what the dumb previous developer did" thread. By giving the type check its own node it allows us as developers to more effectively communicate with each other via code. The code on the right reads like this: 1. Check to see if the object can be downcast. 2. If it can, downcast it and call the method. The intent is much more clear in the code on the right because the semantics flow naturally from the nodes we're using rather than requiring us to remember obscure details about the To node's inner workings. The future developer may wonder why I bothered with the typecheck instead of using a single downcast and casing out an error, but it doesn't look like a silly mistake and--as you mentioned--more naturally leads into "what's the difference" questions precisely because they are different. So to your question, "Is it really worth an extra node?", my response is yes, absolutely. As long as we're talking about type checking, and... umm... you'll be working on it anyway (*fingers crossed*)... I'll throw this out there too. I have to write the code on the left occasionally and every time another developer runs across it I have to explain what it's doing. It sure would be nice to be able to write the code on the right. (And I think an "Is More Specific" node and an "Is" node compliment each other nicely.) You'd know better than I so I certainly won't dispute it. However, the differences in pseudocode clearly reflect which side of NI's firewall each of us is on. My interpretation is from the perspective of a Labview developer who uses the To node as a black box. Yours is from the perspective of a developer who knows how the node works. Take a look at your two ToMoreSpecific function calls. They have different arguments, even though the block diagram nodes they represent have the exact same wires connected to the exact same input terminals. To me that is very unintuitive and hard to remember behavior. I rarely pull out the Show Buffer Allocations tool. Generally speaking I don't find it very helpful in figuring out why memory is being allocated or where I should apply my efforts to get the most bang for my buck. I'm sure a lot of it has to do with me not understanding the tool well enough. Maybe that's part of why I'd rather have an "Is" node where it's obvious the only allocation is a boolean than rely on a "To" node that sometimes allocates and sometimes doesn't. You're a team lead/manager aren't you? Do the pointy-haired thing and delegate. Call it a learning opportunity. (Just out of curiosity, is it a lot of overhead to create a node? The type checking code is already there and just needs to be extracted from the To node. Easy cheezy, right? *Whistles a tune innocently while blatently ignoring my sig.*) Methinks you and I have very different ideas of "fun."
-
I agree 100%. There are times when type checking is very useful. I'm not saying type checking is useless or even that the compiler optimization is a bad idea. Obviously it is an improvement. I just think language is much more readable if the question of type compatibility is answered by an "Is Type Of" or "Is Child Of" node rather than requiring us to resort to confusing semantics with the To More Specific node. Roughly speaking, the text equivalent of the sample Stephen posted is: obj response; response = ToMoreSpecific(Parent,Child); if isNotError(response) { response = ToMoreSpecific(Parent,Child); response.setValue(54); }; [/CODE] Then there's also this little trick Stephen posted a while back for run-time type checking: I appreciate the effort Stephen goes to to keep us informed and I hope my comments aren't perceived as an attack on him. The fact that he has to explain how to accomplish certain tasks efficiently should be a clue the language is not providing something developers need.
-
I can't speak for anyone else, but if I'm trying to change the output of a sub vi based on how (or if) downstream code is using it, that's a pretty good indicator something is wrong with my design. The easiest solution is to refactor the sub vi into smaller functional parts. Clearly the existing one is doing too much stuff in one step. I posted this comment on the NI forum as well, but this thread is getting more activity:
-
Democracy is two wolves and a sheep deciding what's for dinner. Good thing NI isn't a democracy.
-
If the ecosystem is restricted to only counting tablet or phone software apps, then yes, I'd agree with you. Apple's ecosystem extends beyond that, to phone and the desktop software and hardware, and that certainly isn't 1000x bigger than the rest of the stuff out there. I'm a firm believer in "to each his own" so if an Apple gadget does the trick for you, that's great. There are always tradeoffs though. Apple isn't a benevolent dictator--like every other business in the world they're in it to make money. I've talked to far too many people with stories of having to pay $400 to replace a $30 cd-rom drive to be comfortable putting my money into a mac, much less converting my entire household to it. Remember all the huge complaints about MS being a monopoly? Imagine Apple with the same market share.
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
Yep. Right now it's not clear to me how often I'll have these kinds of situations. Maybe it's a side effect of the way I think about the components, maybe it's a unique situation that won't arise very often. I guess time will tell.