Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Any single-loop system is going to have this problem. The dialog box prevents further execution until the user dismisses it. There are two solutions: 1. Put your UI operations in one loop and your data acquisition operations in a separate loop. Splitting functionality into separate loops is the fundamental way to get parallelism in LV. If you plan on writing code with anything more than trivial user interaction, you need to learn how to manage multiple loops. 2. Write a vi that opens the dialog box and dynamically launch it using VI Server calls. This is okay if you just have a one-off thing you want to add without having to start a significant rewrite. (Note: You will have a hard time trying to scale your user interface without it getting out of control. Once you're very comfortable with multi-loop applications you can take a look at the Actor Framework for ways to dynamically launch parallel loops.)
-

Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
There are two variations to this scenario: 1. In 5 seconds I'm going to need to know where you are at that time. 2. In 5 seconds I'm going to need to know where you are now. My current use case is the second scenario. Technically there's nothing preventing the producer from solving scenario 1 by continuously updating the notifier data until the consumer reads the future, but I don't know if that's their intended use. Boring Details In this app I need to place an overlay over a video image and align it with the part attached to the motion control system. The only way to do that is to have the user click on the screen to identify fiducials--key locations on the part whose locations relative to each other are known. By matching the location of the mouse click with the position of the mc at the instant the mouse was clicked and doing a bunch of coordinate transforms, I can determine the location on the mc system where the user clicked. It turns out the fiducials I have to work with are not in a fixed position. They can (and frequently are) out of position, so I have to capture 4 fiducials and do some averaging to minimize the error. I can't do the averaging until I have data from all the fiducials, but I also can't just save the location of the mouse clicks and send them all at once because the position of the mc system will have changed to bring other fiducials into the field of view. Each data point needs to contain both the mouse click location (in screen coordinates) and the mc position at the moment in time when the mouse was clicked. Originally I had the UI sending each mouse click to the mc system. The mc system would do the coordinate transform and store each data point until it received a command to do the averaging. Then it would average the data and apply the overlay in the correct location. It worked, but I didn't like it because it had the mc system handling temporary user data--a UI responsibility. By using futures I was able to bring the responsibility for maintaining the fiducial data back to the UI component, simplify the messaging interactions, and remove chunks of mc code dedicated to keeping track of the UI state. ---------- One other thing... you might wonder why, if my messaging loops respond "instantly," I don't just use a regular asynchronous message exchange or a synchronous message. In truth I probably could have without a noticable affect. However, UIs tend to receive a lot of update messages and with screen refreshes and UI thread blocking my sense is there's a higher potential for the UI input queue getting backed up, especially as users ask for more functionality. I try to write my UIs so if the queue does get backed up there's no noticable user impact. In general I'm less concerned about the UI loop's message response time. A 50 ms delay in a screen update is no big deal, but a 50 ms delay in getting the mc position is deadly when a 5 um error makes the system unusable. -
I released it specifically so other LV developers can use it in their day-to-day work, even if you are hiring out as a contractor/consultant. I have no problem with anyone using it as part of a customer's application or including it in the source code given to the customer. To be honest I have mixed feelings about people redistributing it to other developers as a toolkit and claiming it as their own. I don't really like the idea of someone else selling LapDog as a LV toolkit, but I haven't specifically taken steps to prevent it and I don't anticipate doing it in the future. I've considered a 'shout out' license, which means if you use it in a for-profit endeavor you have to drop me a note letting me know--just 'cause I'm curious how it's being used. But I haven't done that either. So no, there are no restrictions on its use. You can use it in a commercial application. You can give it away to your friends. You can change the banner color and re-release it as LapFrog if you're so inclined. It's free, it's open, and it's there to be used.
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
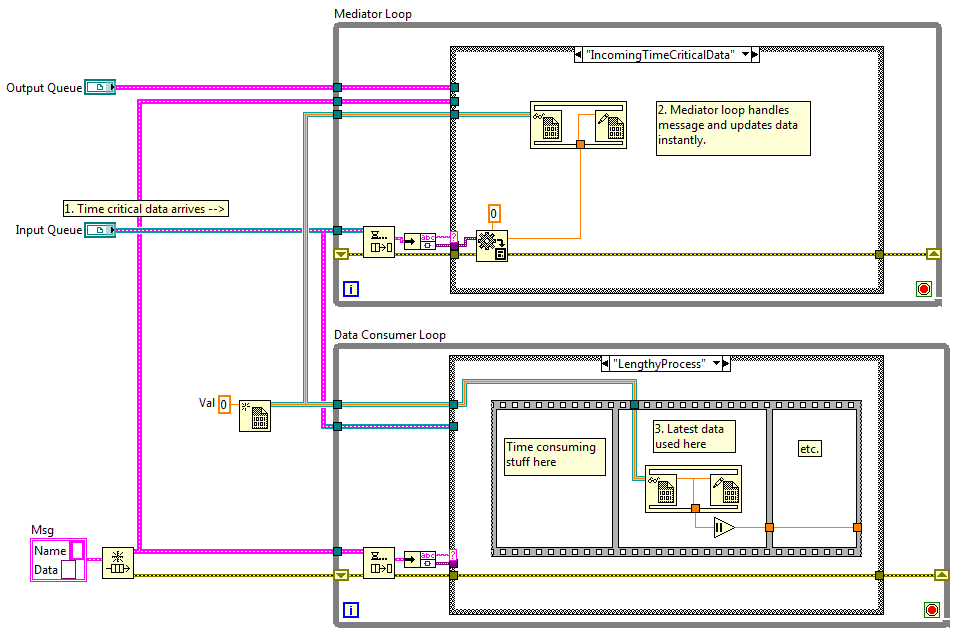
Good point, the difference being it spawns a new execution path rather than linking into an existing one. (Well, not that call directly, but isn't it designed to be used with the new 'Run Without Waiting' function?) To clarify, futures aren't an architecture and I'd actively discourage anyone from building an application primarily on futures. It's a concept that can be applied to solve specific difficulties in asynchronous systems. I'd describe my current project as having an "event-oriented messsaging" architecture. Your assessment is correct. If the UI waits a minute before redeeming the future the data will be a minute old. The same thing would happen if the UI loop got the data immediately but waited a minute before using it. Any time you make copies instead of using references to share data between parallel loops you run the risk of operating on "old" data. (Edit... ahh, now I understand what jzoller meant by 'stale' data. Duh.) If you need absolutely-the-latest-data-available-at-this-exact-point-in-time, creating references as close to the data source is the way to go. I don't think I've ever needed that level of instantaneousness. Because messages are routed through dedicated message-handling mediator loops, as a practical matter they propogate through the system instantly. Usually the end consusmer also handles the message close enough to instantly as well. On rare occasions the end consumer may be engaged in a relatively long process and use "old" data while new data is waiting on the queue. There's several potential solutions I can think of: 1. You can replace the last step in the message chain with a DVR to get the time critical data to the data consumer. If I can't change the message handlers to make the consumer more responsive this is often my first step. The second or third time the loop needs the DVR is a clue it's time to refactor it away. A very simplified example looks like this: 2. You can set up a direct data pipe between the data producer and data consumer. I use the messaging system to send the producer and consumer each end of the pipe--usually a data-specific notifier or SEQ. Then the consumer queries the pipe when it needs the data instead of using an internal copy. I do this if I'm worried about a data stream loading down the messaging system. 3. Hmm... I seemed to have forgotten what it was while I was putting together the example...
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
Due to popular demand (**snicker**) I put together a (very) quick example illustrating how and why I used a future. No time for a detailed explanation beyond what I posted above, but I will say this... In the examples the UI loop retains an array of futures and then sends them all back to the producer loop so it can redeem them and perform a calculation on the values. This is what I my app required, but I suspect the "normal" use case would be for the UI loop to redeem the futures. Futures, at least the way I implemented them, don't have stale data. It's a one shot notifier, so the data is either there or it isn't. I put a timeout input on Future.Destroy for just those situations. (Not shown in the example.) In general I think it's up to the developer to be reasonably certain the data will be there when needed (while putting in proper error handling code just in case it isn't.) It turned out in my case I didn't have to worry about the data not being there. The UI loop requested all the futures representing the MC data, then sent them back to the MC for processing. Since all the initial future requests preceeded sending the array of futures for calculation, by definition all the future requests will be serviced before the calculation request. FutureExample.zip
-
When developing apps with multiple parallel processes, many developers prefer messaging systems over reference-based data. One of the difficulties in messaging applications is how to handle request-reply sequences between two loops. Broadly speaking there are two approaches: synchronous messages and asynchronous messages. In some ways synchronous messaging is easier to understand. The sender asks the receiver for a piece of data and waits for a response before continuing. The downside is the sender isn't processing new messages while its waiting. Important messages will go unnoticed until the sender receives the data or gets tired of waiting. It can also be hard to verify correctness in synchronous messaging system. Cross loop execution dependency may hide deadlocks in your code and they are very hard to identify. Asynchronous messaging sidesteps the issue of deadlocks. Each loop executes on its own schedule so there's no danger of multiple loops waiting on each other. The drawback? There are a lot more messages to handle and the bookkeeping for sequences of data exchanges can get messy. For example, if a data consumer, C, needs data from a data producer, P, it might send a GetData message then continue servicing messages as they arrive. When P processes the GetData message, it in turn sends a HereIsData message back to C. C then not only needs to implement a HereIsData message handler, but also needs to keep track of the reason why it wanted the data in the first place so it can continue its previous task--there is more state to manage. Since synchronous messaging processes the returned data inline with the request it doesn't have this problem. Often I eliminate the need for additional state management by having P broadcast new data to all C's every time it changes. That ensures each C has the latest data and can use its internal copy inline instead of requesting it and waiting for a response. Sometimes that is not a very good solution. Consider the case of a high output P and a C that sometimes, but rarely, needs the data. That's exactly what I ran into recently with a motion control system where the motor positions are updated every 10 ms or so but the UI needs to know position data maybe 5 times every 30 minutes. Continuously broadcasting position data to the UI seemed like a waste of resources. Where am I going with all this? A little while ago I ran across a concept called "futures." It is essentially a promise to supply needed data at some point in the future when it is not available at that instant. The future doesn't have the data now, but it will when it is redeemed. Rather than broadcasting thousands of unnecessary messages or creating lots of extra states to manage, I used futures to get the readability of synchronous messaging while (mostly) maintaining the natural parallelism of asynchronous messaging. I don't have time to code up an example right now so let me try to describe it. (If there's interest I'll try to post an example later.) The process flow I used for my futures is similar to this: 1. UI determines it needs position data from the motion controller (MC.) 2. UI creates a future and keeps one copy for itself, sending the other copy to the MC as asynchronous message data. 3. UI continues processing, not caring about the specific data right now but trusting it will be there when needed. 4. MC eventually processes the message and "fills" the future. 5. UI gets to the point in its execution where it needs the data, so it "redeems" its copy of the future and obtains the data filled by MC. Compare that with synchronous messaging and the difference becomes clear: 1. UI determines it needs position data from the motion controller (MC.) 2. UI requests position data from MC. 3. UI sleeps while waiting for a response. 4. MC eventually process the message and sends a response. 5. UI continues processing, confident it has the data it needs for future processing. I don't claim this idea as my own, or even that its new. I implemented the future using a notifier. In fact, under the hood a future looks a lot like a synchronous message. The important difference is where the waiting takes place. Synchronous messaging forces the sender to wait for a response to the message before continuing. Futures give the sender more control over their own execution. They can redeem the future immediately and behave like a synchronous message or they can redeem it in the future and continue doing other stuff. It turns out I unknowingly implemented futures about a year ago as a way to have synchronous messaging with LapDog. At the time I was focused on obtaining the response before continuing, so it never occurred to me to defer reading the notifier until the data was actually used. I've just started using this idea so I don't really know where it'll lead. I don't think it's a "safe" replacement to synchronous messaging; there is still the danger of deadlocks if futures are used extensively. I think they're better used as a lightweight request-response mechanism when implementing a new state is too heavy and broadcasting is too resource intensive.
-
I picked up a couple HP tablets for cheap at their recent fire sale. They sold out in a hurry here in the US but you might be able to find some in the UK. One is still running WebOS and I installed Android on the other. My opinion on tablets... more flash than substance. They're fine for consuming information--web sites, ebooks, games, etc.--but they're still a pain if you have to do any substantial input. Anytime I have to input more than a sentence or two of text the lack of a mouse or ctrl-arrow keys for precision cursor placement really annoys me. I can justify a $100 price tag (what I paid) but $400-500? Nope, not worth it. I'm not much of an Apple fan--their closed ecosystem is too constraining--but it's hard to argue against Steve Jobs' influence on the technology market. What continues to amaze me is how effective Apple's marketing is at convincing people to happily pay premium prices for less functional devices. Yeah, their hardware is usually pretty slick looking, but the marketing machine is where the real genius is.
-
I was hoping for something a little more informal... like an ini key or something.
-
Actually, in rare situations I do parse the sender name from the rest of the message. Since the master can't exit until it receives exit messages from the slaves, sometimes I'll combine all the exit messages into a single case and keep track of who has sent exit messages via a feedback loop. It's contains the functionality a little more than having separate handlers for each slave's exit message. Structurally what you're describing is, if I'm understanding correctly, similar to the decorator pattern but it is not (imo) a decorator. Patterns are defined by their intent, not their structure. Decorators are optional composable bits of functionality. An object can be wrapped in 0..n decorators and still behave correctly. I don't think what you're describing quite fits. All problems in computer science can be solved by another level of indirection... except for the problem of too many layers of indirection. Forgive me for saying so, but applying that in this particular case smells of too much indirection. I don't see that it provides any real benefit in this use case. One place where I have considered boxing messages in other messages is with errors. It's just something I've thought about though... haven't tried implementing anything yet.
-
You're right, classes don't provide perfect data protection. They provide a better balance of type safety, data protection, and decoupling than the alternatives. For instance, I believe the format of flattened clusters is documented well enough to make recreating an unknown cluster typedef a trivial exercise. Once you know the type you can unflatten it, change the data, and send it back without the component knowing it has been changed. It might be possible for a determined hacker to reverse engineer an unknown flattened class but it will take much more effort. Yeah, security through obscurity is not security, so any kind of resiliant data protection should include encryption of some sort. And while an encrypted flattened string does provide data protection and decoupling, it misses the mark on type safety. There have been lots of discussions about the dangers of automatically flattening a class--enough that most advanced developers don't do it. Any chance of pulling that capability from future versions? I know there would be all sorts of complaints and broken code, but don't you think that's a better long term solution? I'd like to see NI provide more of a base class library as well, but I don't think LVOOP is quite ready for it. It needs a solution to the strict single inheritance paradigm first. Add a way to aggregate behaviors across the inheritance tree (interfaces, mixins, traits, etc.,) then a base class library will have a better foundation to build on.
-
Is it sharable as an advanced tweak? (Like scripting before it was released?) Funny, I noticed that for the first time just a couple months ago. Glad to know I'm not the only one...
-
Agreed. (I think my semantics are easier to read, but it's a personal opinion.) Neither do I. It's just a test to see how decoupled a block of code is from the rest of the vi. If you can copy and paste a loop to a new project and it still works it's pretty well decoupled. If I want to actually reuse it I'll wrap the loop in a class and drop the class methods on the block diagrams that need the loop. I'm curious what your caveat is. Tieing the sender's ID to the vi (or class) name only works if each slave is wrapped in its own vi. As a practical matter I'm not going to do that. It gets in the way of understanding how a master manages the messaging relationship between it's caller and the slaves. I also often use relatively long descriptive file names. Making it part of the message itself is messy. I prefer a short sender ID for clarity and ease of use. Besides, linking the prefix to the file name doesn't solve the problem Steve raised--multiple instances of the same slave. I'm heavily leaning towards using James' PrefixQueue idea. That allows the master to define the sender ID in the context in which it is being used, regardless of whether the slave loop is on the same block diagram as the master or in a sub vi. To put it another way, I don't want transparent message names--that makes my abstraction layers leaky. I want message names that reflect the way the master is using the slave.
-
Top down and bottom up are not architectures. They are development approaches--they describe the order in which the code is designed and/or implemented. You can apply either approach to any architecture. (Though some architectures may more naturally align with one approach.) Sure enough, I missed it. My apologies. (Old age sucks.) If you write two components designed to work together and their interfaces are not compatible, then yes, you probably didn't think about the design enough. But to state interface incompatibility is generally the developer's fault is incorrect. There can be lots of reasons interfaces are not completely compatible. Any sort of layered abstraction naturally causes incompatible interfaces between high level components and low level components. Reusable low level components also lead to incompatible interfaces. You can't create interfaces for two different widgets that are both 100% compatible and expose all the features unique to each widget. Ever have to replace an instrument in an existing system with one from a different manufacturer? Incompatible interfaces. Wait... first you say you write an adapter sub vi, then you say adapters are only needed because of OOP? Design patterns are conceptual solutions to problems encountered when programming with loosely coupled components. It doesn't matter if the components are implemented using oop or not--if you're aiming for the level of decoupling typically desired in an OOP application you'll run into the problems. An adapter is just a chunk of code that translates from one interface to another. It doesn't have to be implemented as a class. In the instrument replacement situation above, the first reaction by many developers would be to go through all the code replacing all the old instrument calls with new instrument calls. (Frequently accompanied by late nights and large amounts of caffine.) Knowing about adapters one can consider wrapping all the new instrument calls in adapter methods that look like old instrument calls, plug it in, and be done. It turns out the "plugging in" part is way, way easier if you're using oop, but adapters can be individual vis as well. The point of a memento is to externalize a component's state while keeping the state data accessable only to the component. The external code can only handle the state as a black box entity. This prevents unwanted coupling and improves reusability. A component's state is represented by some sort of data. How the external code obtains the data (indicator, shift register, global, etc.) is irrelevant. How much the external code knows about the data is relevant. If the state is a cluster, changing the component's state cluster breaks the external code. Too much coupling. If the state is exported as a flattened string or variant the external code can unflatten it. Not enough data protection. There's also the potential of having the external code send an incorrect flattened type to the component. No type safety. In the case of mementos classes provide a far better combination of data protection, type safety, and decoupling than what is easily available using traditional techniques. Ugh. I hate that term. It's meaningless without clarification. What context are you using it in?
-
It sounds like you do something similar to JKI's state machine. Personally I don't like that technique. I think parsing the message name makes the code harder to read. I don't ever include data, arguments, or compose multiple messages as part of the message name. It's only an identifier; it could be replaced with an integer or enum. The path would be in the data part of the message. The colon (I've also used a dot... haven't standardized yet) doesn't delineate commands or arguments. It's just a way to visually separate the name of the sender from the message description. Why (and when) do I include the sender name as part of the message? To help explain this, here's another new term: Event Agent. All agents define their api as a set of input and output messages. An event agent is an agent that defines its api without knowledge of any code external to it. Its input messages are commands/requests for action and its output messages are "events." Not user or fp control event constructs, but "events" in that they are messages telling the rest of the world something the agent has already done. An event agent's output messages are never commands to the external code. They are event announcements. In the example above the Slave1 and Slave2 loops are event agents. The master loop, in and of itself, is an agent but is not an event agent. The loop contains code to manage Slave1 and Slave2 specifically. On the other hand, the master loop combined with the two slave loops is an event agent (or at least it would be if it had an output queue.) An event agent is an independent unit of functionality and provides a natural decoupling point. Because it doesn't know or care who is sending messages, input messages do not include the sender's name. However, as the example above shows, often the code using the agent needs to know which agent a message came from. Output messages include a prefix containing the event agent's identifier. The example's app-specific glue code would be contained in the master loop. More generally, in an event-oriented application all of the glue code would be contained in mediator loops at each level of abstraction. (A master loop may or may not be a mediator.) Every other loop is copy-and-paste reusable. It's possible--in principle--to have a library of event agents and create an app just by writing custom mediator loops. -Dave Oh yeah, I've also found the Sender.MessageName format to be very useful for backtracking a message during debugging.
-
I disagree. Patterns are largely independent of the language you're using. Whether or not you need them depends on what you're trying to accomplish. Saying they're not as important in Labview is like saying formal development methodologies aren't important in Labview. Sure, many developers don't need them because the project scopes are relatively small, but their importance increases with project complexity. I think it's more accurate to say patterns aren't as important to most Labview developers rather than they aren't as important to Labview as a language. Agreed, and generally speaking that's the goal of patterns--getting pieces working together without binding them together too tightly. Why do you say that? I don't think Labview is more inherently hierarchical than other languages. Maybe because "the diamond" isn't a design pattern? I believe you're describing your app's static dependency tree or perhaps the communication hierarchy, not a design pattern. Design patterns are smaller in scope--they address specific problems people frequently encounter while working with code. Have two components that need to communicate but use incompatible interfaces? Use an adapter. Need to capture the state of a component without exposing its internal details? Use a memento. Stuff like that. "Diamond" might be considered an architectural pattern, but even then it feels too ambiguous. What aspect of the application is arranged in a diamond? I think it needs more descriptors. (Incidentally, adapter code can be written with or without oop. I can't think of a good way to do mementos without objects... maybe encode the component's state as an unreadable bit stream?)
-
Fair enough. A consistent conpane can go a long ways towards making a class' api user friendly, and on my block diagrams the object terminals are usually near the top and the error terminals are usually near the bottom. Beyond that it all depends on where the wires connect to the sub vis. Usually what happened is I'd change the block diagram layout and I'd have to go back and rearrange the front panel... followed by the conpane. (Yeah, that particular "best practice" didn't last for long.) This comment got me wondering... Maybe 10% of my app-specific classes use dynamic dispatching to provide the application's functionality. What's the going rate for others?
-
James is right. In fact, I think you can duplicate all the features of LVOOP using normal G techniques if you really wanted to and were willing to write the framework code. (Probably take a performance hit though.) Not much point in it imo... NI already provided it for us in a nice LVOOP-branded package. It's fun when the ideas click into place, isn't it? The instrument object isn't available in the mediator loop. You should be interacting the slave object via it's messages. As an aside, I think my original post emphasizes the OO aspect of slaves too much. The single owner nature of slave loops is the important concept. The class is just packaging you can put around the slave loop when the need arises. Another problem with the original post is there's an unspoken principle underlying my approach to programming. I have an overall grasp of what works for me and what doesn't, but it's hard to distill it into something under 250 pages. Here's a feeble attempt... As developers we're constantly juggling the conflicting requirements of separation and combination. We need to separate our code to prevent a big ball of mud, but we also need to combine our code to do anything useful. Many developers appear to take a vi-centric approach to programming--the vi is the basic unit of execution. (I'll call it "vi-ism" for shorthand.) VI-ism tends to view a vi amorphously. Multiple loops on the block diagram are just tasks running in parallel. The data is shared with any loop needing it via local variables or FGs. If a race condition is observed locks or timing mechanisms are added. Pretty standard stuff. VI-ism leads to multiple loops on the same block diagram sharing resources (local variables, control references, etc.) or data (FGs, DVRs, etc.) When the vi grows (which they always do) to the point where it's time to refactor some of the loops into sub vis, those vi-specific resources make it very, very hard to do so safely. VI-ism equates separation with a sub vi. In once sense it is correct. Sub vis provide a physical separation of the details. The dangerous corollary falling out of VI-ism is "no sub vi means no separation." In reality there are logical separations that may (and often should) exist on a single block diagram vi-ism doesn't recognize. One important logical separation is the loop. In my world the loop, not the vi, is the basic unit of execution. Instead of a connector pane the loop's input and output messages define its interface. Data sources and sinks (fp controls, files on disk, etc) are "owned" by a loop, not by the vi the loop is on. If other loops need that data they must go through the loop's interface to get it regardless of whether the loop is on the same block diagram or not. The vi's role is changed to the basic unit of implementation. At the risk of confusing the issue more, let me replace "loop" with a new word to more accurately describe my meaning--agent. In this context I'll define an agent as an arbitrary block of code with well defined data ownership, is designed to run in parallel with other loops, and reacts to messages from code external to it. (Don't confuse my use of the word with Agent Oriented Programming, which seems to be closer to the Actor Framework implementation.) It's an abstract concept of a kind of abstraction. How is an agent different from a loop? -Not all loops have or need a messaging interface. A dumb timer loop spitting out data at regular intervals is one example of a non-agent loop. -Agents encapsulate data sources and sinks (when it has them.) For example, an instrument agent exposes read and write messages to the rest of the application, but it doesn't expose any information allowing other code to contact the instrument directly. All other code must interact with the agent if they need the instrument's services. Encapsulation sounds like an oop. Isn't an agent just another word for a class? No, a class is one way to encapsulate code. I can replace a cluster with a class and accessor methods, but it doesn't mean "cluster" and "class" are equivalent. The nature of the data isn't inherently classy. In the same way an agent encapsulates parallel functionality. You can put it in a class when you need the benefits classes provide, but it doesn't require a class. Agents sound a lot like Actors and Active Objects. What's up with that? I view agents as a more abstract concept than either Actors or Active Objects. First, Actors (as used in the Actor framework) and Active Objects are both objects instantiated from classes. Agents may or may not be in a class--the packaging is irrelevant to its core behavior. Second, I believe dynamically launching the object's execution loop is a built-in feature of those objects. (It's currently unclear to me if all Actors are dynamically launched.) Agents can be dynamically launched, but that would be a specific agent's behavior, not a universal agent characteristic. I think of Actors and Active Objects as subsets of agents with specific characteristics. Clear as mud?
-
Uhh... that's a block diagram. Why do you *care* where they connect? I remember posts on the dark side suggesting matching the general location of a terminal on the bd, fp, and connector pane was "good style." I tried it for a while but it got to be a pain rearranging all my wires and block diagram if I changed a conpane terminal connection. I'll try to put fp controls in the same general location as the conpane terminals, but I don't worry about matching the block diagram terminals. I'll put them wherever they need to be to make a clear block diagram. Personally I think most style debates are much ado about nothing. The goal is code clarity, not style for the sake of style. There are lots of ways to write clear code and communicate intent. We're "advanced" developers, right? I'll leave the style gestapo for the dark side. (Not suggesting anyone here is being part of the style gestapo... writing this brought back memories of numerous style debates with developers.)
-
Don't you show terminal labels on your block diagram? I don't think I've ever bothered looking at the text inside the terminal (except for integer types) as the label gives me all the information I need. Ahhh.... so much better.
-
Terminals, definitely. It's one of the handfull of settings I immediately change with a fresh LV install. (Along with branching dots, constant folding, and a few others.) I disagree. Emphasizing the inputs and outputs distracts me from what I'm really interested in, which is what the code is doing. Terminal icons are too similar in shape and size to sub vi icons, and to a lesser extent class constants. When I look at the diagram you posted it's hard to quickly identify where the vis are. The first couple times I glanced at it I didn't even notice the final Msg method outside the case structure--it was lost in the noise. In contrast, I easily identified all the sub vis in Shaun's diagram.
-
Hrm... so instead of sending the search parameters (most direct, highest average speed, etc) to the slave the parameters are hard coded into the slave? I guess that could be useful in certain situations... each instance will have a smaller memory footprint than if you coded a single slave that can handle different parameters. Overall it still seems like a pretty narrow use case. (And "master/slave" are still the best terms I can think of for describing the characteristics of the loops I create, though I'll try to take more care to clarify that it's *my* definition.)
-
I understand that, but it's largely irrelevant unless you're spawning slaves at runtime. And even then I don't think it's accurate to say queues don't scale... it's just a little more work to make them scale. I hadn't thought of that. (Though off the top of my head I can't think of a reason why I'd need that. My slaves don't need reminders to keep them on task.) I get the idea of overriding previous instructions to the slave. The notifier is easier to use in that situation if your master is sending messages to the slave faster than the slave can process them. Maybe it's just the way I code or the types of problems I'm solving, but that characteristic of notifiers is irrelevant in my messaging systems. Messages don't stack up on the queue so any 'new decisions' are applied equally well by queues as they are by notifiers. Here's the issue I have with notifier-based slaves in a nutshell: Notifiers broadcast the exact same message and data to all listeners. Why would I want multiple instances of a process doing exactly the same thing to the same set of data? That's just wasting cpu cycles. They're all going to return the same results. With a notifier I can't split a set of data and sent part to each slave. I can't send unique routing parameters to each slave in a navigation system. What benefit do I get by having a navigation system calculate a path to a destination four times in parallel instead of just once? It's a computer--the slave threads are doing calculations not offering an opinion. If each instance of the slave has a unique input queue then the master has far more flexibility in how to distribute the workload. I actually find very little need for notifiers in general. I'm not sure I've ever used them specifically for their one-to-many characteristics. I do use them as a data pipe when a data source is acquiring data faster than the consumer needs it, but that decision is based on their relative performance characteristics, not on the need to propogate data to multiple destinations. Maybe I'm just lacking the imagination needed to get it...
-
Are you referring to Labview's master/slave template or are these characteristics you consider inherent to the general pattern? I confess it seems like an odd (and fairly restrictive) way to define a concept as ubiquitous as master/slave. I can see how it would be one particular variation on the theme, but as an overall definition...? The sample code I posted doesn't preview the queue--each listener has a dedicated queue and when they receive a message they dequeue and process it like every other message. The two implementations I posted are effectively the same, aren't they? ---------------------------- Later... Some of the reading I've been doing indicates slaves are identical instances of some functionality dynamically created at runtime. It also implies slaves are frequently created and destroyed as a matter of course in many applications. If that's accurate then that's the part I was missing. Comments?
-
managing multiple instrument drivers - best architecture?
Daklu replied to automationtx's topic in LabVIEW General
You slipped a couple posts in there... I guess I'm getting too long-winded. I agree the other terms don't quite fit. Sometimes people just call them threads, but that creates confusion between LV threads, OS threads, and CPU threads. Besides that it doesn't relay any information about the intent of the loop. Instrument loop is as good as anything... at least for this thread. I'm not quite following this. When the app starts your instrument loops start running. The tests are top-level vis that are dynamically launched when users request it. You pass the instrument loop's input and output queues to the tests so they each can communicate with the instrument loop. You also plan on creating other top level vis to simulate instruments and stuff. Did I get that right? Potential problems: First, each message on a queue can only be dequeued once. How are you going to get messages from each instrument to all the top level vis that want the information? You have to create copies somewhere along the line. You can make the instrument loop observable and have other loops register their own input queues with it. Or you can have the instrument loop send all it's messages to another loop (mediator,) which in turn creates copies and sends them to the receivers. I prefer to split the functionality and keep each loop's responsibilities separate and distinct. Second, the idea of injecting an instrument's queues into a top level vi so the vi can simulate the instrument seems backwards to me. Isn't that why you have a Digitizer Simulated class? Subclass your simulated instruments directly from the instrument they're simulating. I have a simulated Stage object I use. When the creator executes it launches a front panel allowing me to manipulate encoder feedback and see how the app responds. It's great since most of my dev work is done away from the hardware. Better yet, switching between simulated and real hardware is as easy as replacing the class creator. Third, I'm curious how you are preventing tests from interfering with each other. If tests a, b, and c all send messages to instrument 1, are you running the risk of having the tests issue conflicting commands? I see.... would you be at 'F' in Everett? I spent several years writing test software to support hardware development activties. It's a challanging environment. Speed tends to take priority over everything else and it's hard to convince managers of the long-term benefit of good code. -
managing multiple instrument drivers - best architecture?
Daklu replied to automationtx's topic in LabVIEW General
James already commented on this, so I'll repeat what he said in a slightly different way. Broadly speaking there are two ways of sharing a resource among parallel processes: The first is using references. You share the object directly using DVRs, FGs, globals, etc. These are effectively forms of object references. If the "reference" is maintained internally within the class, it is a "by-ref" class. GOOP, G#, and possibly some other frameworks appear to be built around by-ref objects. The other way is to share access to the resource. In other words, have the object executing in it's own process and communicate with it via the messaging transport it exposes. I almost always use a queue, but it depends on the intent of the specific class. The Actor Framework and my coding style are based on this kind of sharing. AQ used the term "handle" for the queue. I'm inclined to stick with that instead of overloading the word "reference." AQ pointed out the difference recently but I don't have the link at hand. Reference objects methods are synchronous and execute in the same thread as the calling code. "Messaging" objects (for lack of a better word) are asynchronous and execute their methods in a separate thread. It's much more event-oriented and a bit of a shift in thinking about how to approach the problem. If I have to share an instrument among parallel processes I'll wrap the instrument class (which is usually a simple wrapper around the manufacturer's api) in a slave loop. I may or may not put the slave loop in a class. The slave loop api--the messages it can act on--is designed according to the amount of detail the calling loops need. Ideally they will only need a couple high-level messages that wrap a bunch of low-level details, but it's not always the case. The loop's error out is wired to ReleaseQueue for sequencing. I don't want to release the queue until the loop exits but since the MessageQueue doesn't propogate through the loop that leaves me with the error wire. I could use a flat sequence (and sometimes do if there's a lot of clean up code) but it's not necessary in this case and just clutters up the diagram. Errors are in a SR because the Dequeue method looks for errors on its error in terminal. When it finds one, instead of dequeuing the next message it packages up the error in an ErrorMessage object and spits it out in a "QueueErrorIn" message. Then the error handler case is just like any other message handler. Some people put an error handler vi inline after the case structure. Nothing wrong with that. I prefer this way because it puts my error handling code on the same level of abstraction as the rest of the message handling code and it gives me a more coherent picture of what the loop is doing. Overall my approach to error handling in slaves may be a little different than what is common. I don't terminate the loop on errors. That's fine for quick prototypes but I don't like it for production code. Unless you're dynamically launching your execution loops, terminating a loop is an unrecoverable error; the app has to be restarted. Good applications will gracefully self-terminate when unrecoverable errors occur rather than let the user unknowingly continue with incomplete functionality, so usually there's a cascading trigger mechanism that stops all the loops when one of them stops. But I find that behavior rather inconvenient during active development. Lots of times I want the execution to continue so I can repro the conditions that cause the error. If the error isn't handled locally in the slave loop it propogates up to its master as a message, which can choose to act on it or pass it up the chain. Eventually someone decides to do something with it. Right now unhandled errors are eventually converted to debug messages containing the source and summary of the error and displayed in an indicator on the fp. Later on in development I might convert that to a stored error log. My slave* loops don't get to decide on their own when to stop. The slave exits only when the master sends it an Exit message. (Exceptions noted below.**) Here's how my apps might respond to a low-level error that requires termination: 1. A terminal error occurs in a low-level slave loop. 2. If necessary the slave puts itself in a safe state, then sends a RequestShutdown message to its master. 3. The RequestShutdown message is propogated up through the app control structure (master-slave links) until it reaches the top of the chain--the Grand Master. 4. If the GM agrees termination is appropriate it sends Exit messages out to its immediate slaves. Those slaves are in turn masters of other slaves, so they copy the message for their slaves. This repeats so all slaves receive the message. The masters do not terminate yet. 5. When a leaf slave (those slaves that are not also masters) receives an Exit message it cleans up after itself and terminates the loop. The final act by any slave loop is to send an Exited message to its master. 6. Once the master receives Exited messages from all its slaves it terminates and sends its own Exited message to its master. Eventually the GM receives exited messages from all its slaves and terminates itself. *[This is my preference. I don't consider it part of the definition of a slave.] **[There are two exceptions to this rule. 1) If the slave's input queue is dead someone else has incorrectly released it. Since it cannot receive an Exit message the slave should terminate itself. 2) If the slave's output queue is dead the master forgot to send the slave an Exit message before terminating. Since nobody is able to listen to the slave's outputs it should terminate itself.] Seems like a lot of extra work, doesn't it? One of my rules for master loops is they do not terminate until all their slaves have terminated. (With the same two exceptions noted above.) This rule grew out of my exploration with Active Objects a couple years back and problems with trying to shut down dynamically launched vis during active development. Eventually I decided most of my requirements were better addressed by statically launched parallel loops, but I kept the master requirement for a couple reasons. 1. It's easy to define a controlled shutdown process, regardless of the reason for the shutdown. 2. During active dev, when a loop doesn't shut down correctly it's fairly easy to find the offending loop. It's the one that didn't send an exit message, and since I can define the UI to be the last thing that terminates I'm not left guessing whether or not the messages were sent. 3. If I want to dynamically instantiate multiple objects at runtime it's dirt simple to convert it to an actor style object. The thing that immediately jumps out at me is you'e wired a MessageQueue constant into the Digitizer Execution Loop. That won't work. You have to use the Create method. I realize you probably did that so you could run the vi, but I wanted to make sure the requirement was clear. Your simulated and custom Digitizer classes inherit from the abstract Digitizer Base class. In general I have discovered abstract base classes tend to get in the way unless you have very specific and well defined reasons for using them. I make better progress by starting with a concrete class. I'd just use the Custom Digitizer class and subclass the Simulated Digitizer from it. Others probably have different opinions. Later on if you need other digitizer classes with very similar behaviors you can make them subclasses of the Custom Digitizer as well. If the other digitizers implement different behaviors you can then subclass them all from a common parent, or create a separate class hierarchy and delegate to the digitizer classes. (I usually like delegation better.) Regarding where to put the Create and Execute vis, creating a DigitizerSlave class too early can slow down development because you're shuffling back and forth between the two block diagrams to make sure all your message names and message types stay synched up. I usually start the slave loop on the same block diagram as the master and push it down into a slave class if the need arises. (Though dynamically launching the execution loop does qualify as "need.")- 22 replies
-
- 1
-

-
- multiple drivers
- driver management
- (and 3 more)