Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
What it looks like depends an awful lot on exactly what kind and how much decoupling you want. All decoupling requires inserting some sort of abstraction between the two components being decoupled. The simplest form of what *I* would call a decoupled UI is to have all the UI code in one loop and all the processing code in another loop. That means no controls, indicators, property nodes, etc in the processing code. All information is transmitted through your messaging system. If you can wrap your process loop in a sub vi and still have everything work right then you've taken a good first step. In that scenario your UI is still dependent on your functional code. In most cases that's fine. Sometimes you might want to develop a UI that is completely independent of the functional code--maybe one team is developing the processing engine and the other is developing a complex UI. In that case you'll need a third component (the controller) to tie the two pieces together. Hmm... some of my cld practice exams might show a decoupled UI. I'll try to take a peek in the next couple days.
-

Best Practices in LabVIEW
Daklu replied to John Lokanis's topic in Application Design & Architecture
Lucky dog. I asked for one for Christmas but alas, Santa wasn't forthcoming. (Funny how delegation is so useful both in business and in software.) -
Haven't digested the whole things yet, but here are some initial thoughts... Well, I thought about it while I was developing the Interface Framework as a way for callers to get details at runtime about the interfaces an object has implemented. I even implemented a little bit, but I didn't pursue it. I think I included a way to query the names of the interfaces an object has implemented, but decided for several reasons that the calling code has to know which interface it wants to use and how to use it. You lost me here. I guess I need a bit of clarification on exactly what you mean by "type safe." In Labview, I equate type safety with strong typing. i.e. Mistakes generate compiler errors instead of run time errors. By that definition once you've exposed a variant on your public api you've lost all type safety. From the user side, if I see a sub vi with a variant terminal I'd expect it to accept all variants, not throw a runtime error if the variant doesn't contain a "string variant" or "boolean array variant." But like I said, I'll have to digest more later...
-
Best Practices in LabVIEW
Daklu replied to John Lokanis's topic in Application Design & Architecture
Hey John, are planning on starting a new project or doing a running refactor on your current code? My sense is that a running refactor is technically more challenging but is less risky overall as it offers continuous incremental improvements on existing production code instead of a starting a new dev effort on an incompatible parallel branch. My thoughts and experiences, for what it's worth... Things to avoid 1. Don't try to do a detailed design before you start coding. I have yet to produce a design on paper that didn't need to be altered--sometimes significantly--when implemented. I discovered I spent wasted a lot of time working out details on paper that never got implemented because of a change somewhere else. 2. Don't get bogged down in process. The goal is to develop good software, not develop good processes. Too much process is just as bad as no process. Finding the sweet spot for your group will take some time. 3. Don't be overeager to use inheritance. It is actually a fairly restrictive relationship. Delegating tasks via object composition is a much better general purpose way to reuse code and give an object additional abilities. Things to do 1. Find a development methodology that works for you. There are lots of competing ideas about the "right" way to develop software: Test Driven Development, Agile, Waterfall, Unified Process, etc. In truth, the "right" way is the way that helps you deliver the product on time. There is no single best methodology. It depends a lot on the corporate culture, types of projects being developed, requirement maleability, timeline, etc. I've taken bits and pieces from several methodologies and combined them into an informal process that works well for me in my current environment. Your process will likely be different. 2. Architect from the top down; design and implement from the bottom up. (This point is debatable--every dev has their favorite way to do things.) When I'm architecting the app I break the requirements into functional components and figure out the api for each of those components. Each component then get broken into sub components if the complexity warrants it. At this time I'm just thinking about the component's public interface; I don't worry about implementation details. When I get to the point where I have components with a manageable size then I start implementing code, assembling the components into larger components as I work my way back up the architecture. 3. Decouple the UI. You mentioned using a web front end. It's possible (and not terribly difficult) to decouple your UI from your functional code in a regular Labview app. I get irritated with programs where a simple UI change propogates down into the lower levels of functional code. That's just poor (IMO) design. Plus, decoupling the UI makes it possible to create unit tests at the application level. 4. Dedicate time for refactoring and simplifying your code. Software development is a very organic process. (At least for me.) When I get to a point where a component's public interface works the way it is supposed to, it's not really done. I can pretty much guarantee the internal workings have some extra fat laying around. Take time to do some lipsuction--it'll improve the long term maintainability of your app. Addressing some of the specific items you raised... Design Patterns - One of the best bits of advice I read about design patterns is to "apply design patterns gently." In other words, don't carry around your design pattern solution looking for a problem to solve. Applying them where they are not needed adds a lot of unnecessary complexity. (It's a great way to learn the design pattern, but I have a lot of extra stuff in many of my early applications.) Unit Testing - Contrary to common perception, unit testing is not free. In fact, it is quite expensive. Not only does it take time for initial development, but you have to go in and fix the unit tests when a design change breaks them. When a test run results in a bunch of failure, chances are at least some of those failures are due to errors in your test cases. Every minute you spend fixing your test cases so they result in a pass is a minute you're not spending improving your code. Don't get me wrong; I think unit testing can be extremely helpful and I'm still trying to figure out how to best use it as part of my dev process. But I think it's a mistake to try and create a comprehensive unit test suite. Packed Project Libraries - Some users have reported problems with ppls. You might want to wait a year or two before including them as an integral part of a mission critical app. -Dave -
Install it in a virtual machine.
-
[Discuss] TLB - Top-Level Baseline
Daklu replied to Norm Kirchner's topic in Code Repository (Uncertified)
Hmm... suppose your UI has a "Start" button. You're not using LVx to trigger a start by referencing the front panel control are you? -
LapDog Message Library v1.2.0 has been released and is available on SourceForge. It packages several classes designed to simplify general purpose messaging for object-oriented programmers. Highlights include: 1. Familiar methods! If you've used a native queue and you're comfortable with LVOOP, you'll have no trouble figuring this out. 2. More convenience! Have you ever overloaded your Default case with error handling, timeout handling, and more? No more! DequeueMessage (and PreviewMessage) checks for errors on the input, errors from the dequeue prim, and dequeue timeout conditions, and returns unique messages for each of those conditions. Say goodbye to the hassle of nested case structures just to handle normal checking procedures. 3. A PriorityQueue! Ever wish you could easily prioritize messages in your queue? The LapDog Message Library includes a class that does just that. Better yet, it allows you to configure the number of priority levels your queue will have. 4. A collection of message classes for native Labview data types to speed up your development. Includes classes to support the following native types: Error Cluster, String, I32, Boolean, Path, and LVObject. If you need something not included, it's a snap to create your own class that inherits from Message.lvclass. 5. Palettes, cool looking wires, and more! The LapDog Message Library requires VIPM Community Edition (or better) to install. The package currently requires Labview 2010; however, we hope to release a version for Labview 2009 soon.
-
Now you have two.
-
Jim, Yes, NI does have user groups in some areas. Best way to find out if any are around you is to call your local sales reps. Really? Because I have this neighbor that's really been getting on my nerves... Oh, never mind. I thought you said you'd kill for a mentos.
-
Thanks for the kind words Felix. I showed your post to my wife and she said, "I like this Felix guy." I thought maybe it was because of the nice compliment. Silly me. It's because you have Johnny Depp as an avatar.
-
[Discuss] TLB - Top-Level Baseline
Daklu replied to Norm Kirchner's topic in Code Repository (Uncertified)
I thought those black marks were a mustache and goatee. I had no idea they had anything to do with LVx. Oh man, as much as I'd love that I don't think I have time right now. (I keep putting off my CLA exam because this other stuff sounds so much more interesting...) I'm pretty sure you have posted stuff about LVx somewhere around here, but my fabulous search skills turned up zero. Can you give me a two sentence overview of what it does? If I'm understanding correctly that sounds similar to MVC implementations I've done in the past. You basically create a functional component (model) and a ui component (view) separately, then tie them together with a third component (controller,) yes? I like doing that, but have a hard time justifying the time it takes to implement the ui and controller components when they are essentially throw away code. Instead of implementing a full-blown MVC architecture, lately I've been using a mediator loop between the ui and all the functional components. (I'll try to post a screenshot on Mon or Tues.) The mediator loop acts as the app's mailroom, receiving, filtering, and rerouting messages as appropriate. For the most part the mediator loop is a direct replacement for the controller component. The main difference is the mediator loop ties together the functional code and UI code on the UI's block diagram, instead of on its own (controller) block diagram. This obviously makes the functional code a dependency of the UI code, but since the UI is going to be thrown away it doesn't really matter. The nice thing about having a mediator loop is that it provides a natural seam to remove the UI and replace it with programmatic method calls. TLB doesn't have a mediator loop though; the UI and functional code interact with each other directly. I'm having a hard time wrapping my head around exactly how hard it would be to convert an existing TLB app with UI to a pure headless TLB component. Maybe I'll understand it better when I have time to study LVx. -
[Discuss] TLB - Top-Level Baseline
Daklu replied to Norm Kirchner's topic in Code Repository (Uncertified)
Hey Norm, Lately I've been reviewing some of the publically available implementation patterns. I primarily use a bottom-up dev process. As I combine lower level components into higher level components, I want to be able to test out the component as though it were an application in and of itself. (Yes, I know I should be unit testing instead... corporate inertia is tough to overcome.) Once I've tested it adequately I want to convert it to headless operation and incorporate it programmatically into some higher level component. How would you go about converting an app based on this template to a headless component? -Dave -
Found a bug today. If I go to 'Manage Friends' and use the 'PM this member' link, it attempts to send a message to me instead of to the friend I'm trying to send a message to. IE8, WinXP.
-
Excellent points Ben. I freely admit optimizing for performance is not something I have much experience with. In fact, I tend to follow the rule, "first make it work, then make it fast," even though that isn't always the fastest way to the solution.
-
I'm planning on putting up SlaveLoopTemplate.lvlib (you know... the uninteresting part) soon, but unfortunately I can't post the code from the real-world apps. I did convert the Timer Loop shown above into a generic slave loop. I'll see if I can dig it up and post it next week if you'd like. Nope. You're overthinking it. The 'producer' is simply the loop that sends the information. The 'consumer' is the loop that receives the information. All it means is that (almost) every loop has both a receive queue and one or more send queues. Interesting problem. Why n process loops? Is each channel analyzed differently?
-
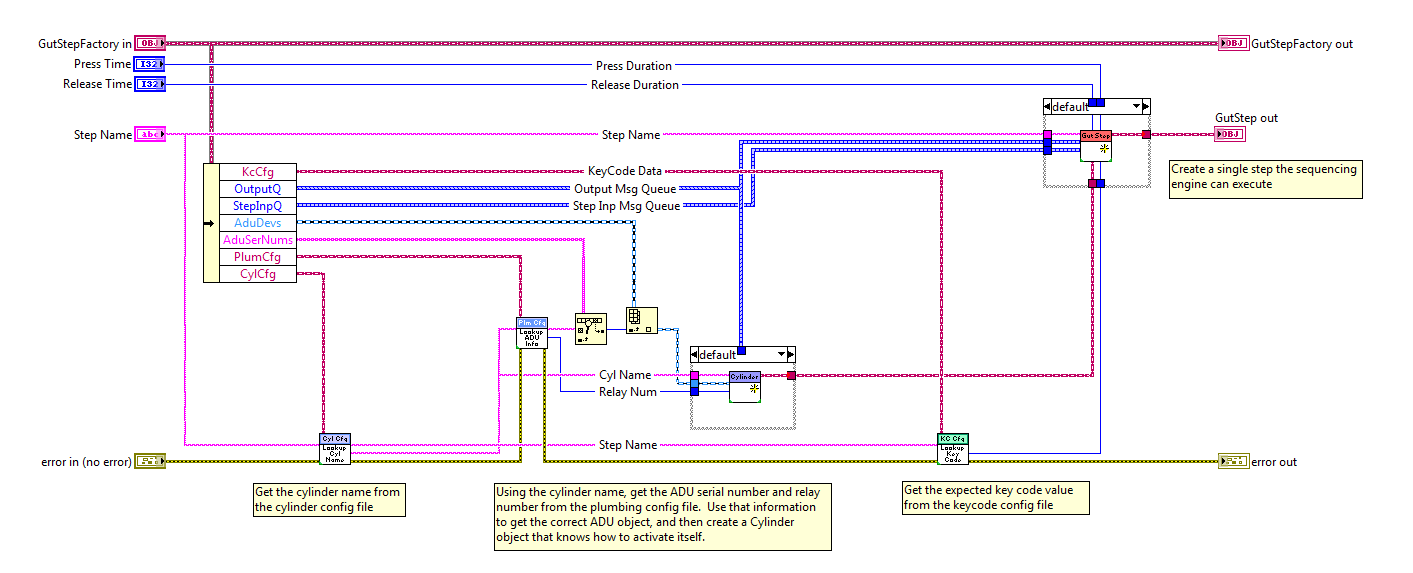
Does each of your slave classes have it's own factory method? If so, then I think we do the same thing but just give them different names. In my mind, if a method instantiates the class it's a member of, I call it a creator. It is (again in my mind--no idea if this is universally true) a "factory" if it instantiates and returns an instance of a different class. Here's a factory method I have implemented as part of a factory class. This particular factory method correlates data from a bunch of different sources and creates a GutStep object based on that data. "Producer" and "consumer" don't have to be fixed attributes of a specific loop. They can be roles. Furthermore, the roles can change at various stages of your application. Nearly all my loops both produce messages for other loops and consume messages from other loops. What's preventing you from adding a 'receive' message queue to your producer loop and having your consumer loop send it the required information? Any chance you could throw up a block diagram?

-
Really? You were just asking yourself, "I wonder what crazy idea Dave has cooked up recently?" Yep, this is similar to the Actor framework. It's the result of a conglomeration of ideas I've picked up from various places, and the many discussions I've had with you has been a primary source of those ideas. I don't think the slave loop concept is revolutionary, but for me it is an evolutionary step forward in my code. I view the slave loop object as an intermediate step between a naked loop and an actor object. Since there's no dynamic instantiation the slave loop is easier to develop and debug than an actor object. It's also easier to understand than my prior actor object implementations. One thing I really like about this pattern is that if the time comes when I need to convert it to an actor, I can do that by adding a single DynamicLaunch method to the class and replacing the ExecutionLoop method with the DynamicLaunch method. None of the messaging needs to change. The queue data type is Message.lvclass; however, the "queue" wire you see is not a queue refnum. It's the class wire for MessageQueue.lvclass. (More details below.) Nope. I have a generalized object-based messaging library that is a foundational component of all my code. (Link to a copy that is very similiar to what is shown--right down to the icons.) [Edit - Ahh, I think I understand the potential confusion. InputQ and OutputQ aren't the names of the classes--they are labels signifying how each of the objects are used within the class. Both objects are instances of the MessageQueue class.] MessageLibrary contains a handful of core classes: MessageQueue.lvclass - This is essentially a wrapper for the queue prims with a couple exceptions. First, you can't define the data type. The primitive queue data type is always Message.lvclass. Second, the DequeueMessage and PreviewMessage methods contain logic to output special messages if there's an error on the input terminal ("QueueErrorInMessage",) if the queue prim generates an error ("QueueErrorMessage",) and if the primitive times out ("QueueTimeoutMessage".) Both DequeueMessage and PreviewMessage output the message name (wired into the case structure) and the message object for retrieving the message data. Message.lvclass - This is a base class from which all messages inherit. It is for sending messages that don't contain any data. It contains a single property ("Name" - string) and two methods: CreateMessage and Get MessageName. Here's how they look on the BD. Get MessageName is a static dispatch method so child classes cannot override it. It's an accessor with some extra logic. If the user defined a message name when the object was created, Get MessageName returns that string. If a name was not defined, Get MessageName returns the name of the class as the message name. Here's the BD. ErrorMessage.lvclass - This is a Message subclass that contains an error cluster and two methods: Create ErrorMessage (with a Name input) and Get ErrorCluster. It's part of the framework because it is the object type returned by the DequeueMessage and PreviewMessage methods when they deliver QueueErrorMessages and QueueErrorInMessages. I also use it extensively for transmitting error information around my apps. Originally I subclassed Message.lvclass for every message I wanted to send and did not provide the ability to give the messages names (aside from Message.lvclass, which always needed a message name.) The strict typing and class-based message name meant I didn't have to worry about matching the message name string in the sending vi with the message handling case strings in the receiving loop. I just had to make sure the message handling case strings in the receiving loop matched the class names in the project window. It was much easier for me to verify the code was correct. In practice I found that to be quite cumbersome during development and confusing, especially as messages propogate up and down through application layers. I've recently added some additional capabilities and add-on libraries that give up some type safety in exchange for simplifying the dev process. Unfortuately I haven't rolled them into the released package yet. What metric should I use? Number of vis? Bytes of hard drive space? Block diagram area? As for "doing something in the real world," I assume you mean "actually helps meet the functional requirements?" There's a lot of processing taking place that doesn't have a physical aspect but is still required to meet the functional requirements.
-
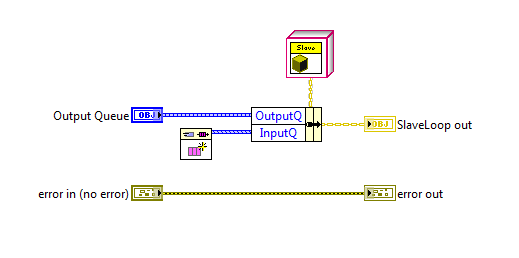
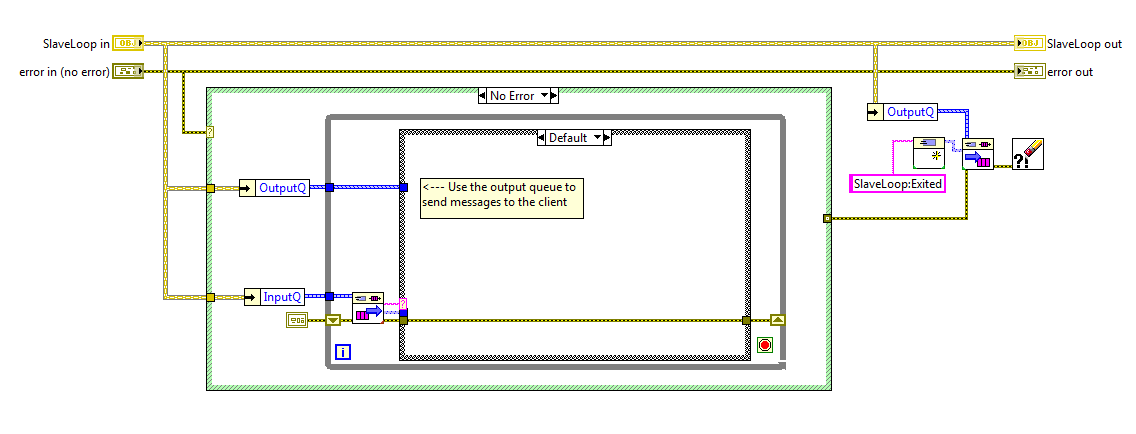
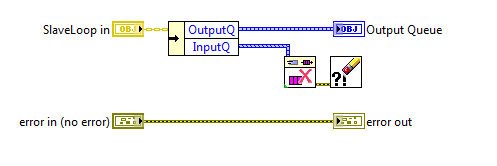
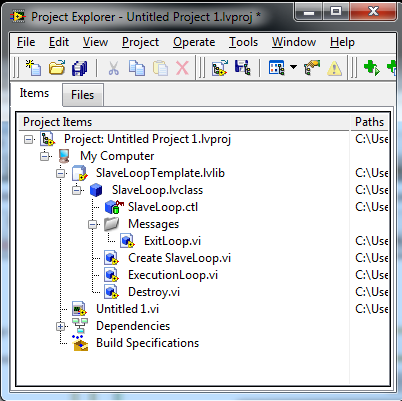
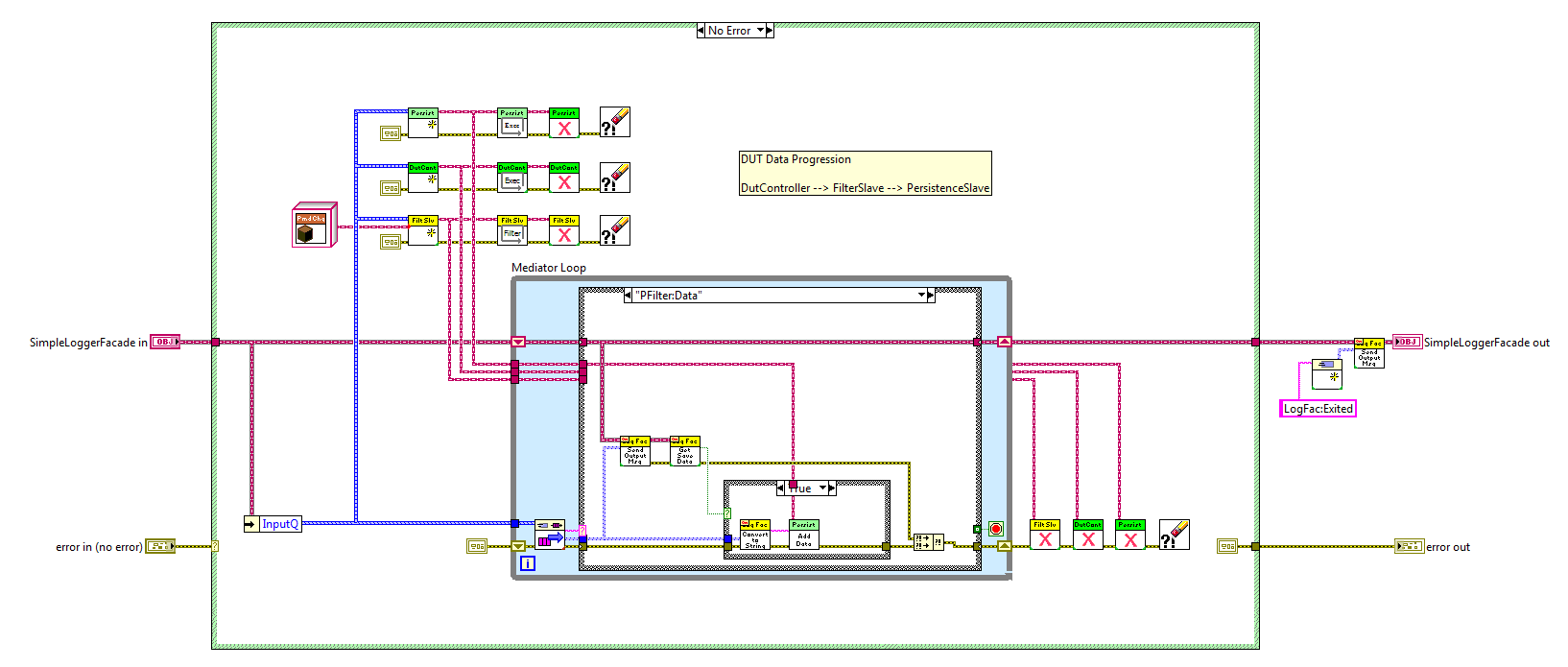
I know some people like to have all their loops visible on the block diagram of the top level vi. I used to do that too, but I found that as the application grew the block diagram got too busy, there was too much to keep track of, and it became very easy to make mistakes. (Not to mention stepping through code is a major PITA.) After a bit I switched over to wrapping my loops in sub vis. That helped, but I ran into issues with that left me dissatisfied as well. I thought I'd share one of the patterns I now use that not only helps me think of my code in components, but also help ensure my components stay decoupled during implementation. It's not particularly unique or innovative, but it might be helpful to someone. I call it a "slave loop object," indicating this object is providing some sort of functionality and sending messages to an "owning" vi. The core slave loop pattern consists of four vis. Three of them, CreateSlaveLoop, ExecutionLoop, and Destroy, execute in parallel to owner's processing loop. The fourth slave loop vi is the messaging vi, ExitLoop. Here's a simple example of what it looks like when used. As expected, the creator method sets up the object's initial conditions and obtains the required resources. At a minimum the object needs an input queue to receive messages from the owning vi and an output queue to send messages to the owning vi. The execution loop can contain anything you want to run in parallel to the owner's main process loop. Usually I'll use some kind of message handler, like this, though I also have used the slave loop pattern to combine several other components and expose a simplified api to the higher level components. (The "facade pattern.") The destroy method is boring and predictable, but here it is. I return the Output Queue to the caller, mainly as a way to indicate to programmers using the slave object that the slave is not releasing the queue. I don't think I've ever used that output for anything but it's there if I need it. Finally, here's the ExitLoop message method. What's this do? Nothing but send a message from the owner's loop to the slave loop executing in the ExecutionLoop method. All new methods I add to the class I'm implementing are messaging methods similar to this. Very simple. The natural question is why bother wrapping all that functionality in a class? Isn't this a lot of extra effort that takes more time and makes the application more complex? Complexity in this context is a matter of perception and depends to a large extent on what you're familiar with. For some this will be more complex until they become familiar with OOP ideas. For others (like me) this is easier to understand because I can tackle parts of the application without needing to comprehend the whole thing. I don't think there's an absolute answer to the complexity question. As for it being a lot of extra effort, no, it isn't. The core of a slave loop class can be hammered out in a few minutes. Less if you have a template class you can copy and paste into your project. That's certainly more time than the 30 seconds it takes to set up a parallel loop on your main BD, but I save a lot of time in other ways. -Since the slave loop's input queue is private, I'm forced to write messaging methods to send it data. This lets me enforce type safety on the message's data because I--the slave loop developer--have control over what data types are exposed on the messaging method's connector pane. If my slave loop has a FormatText message, I drop a string control on the messaging method, wire it up, and I'm done. Since the only way to send that message is by calling the FormatText method, and the FormatText method only accepts string inputs, I don't have to worry about handling cases where the caller might accidentally send an integer. Any mismatched data types are compiler errors instead of runtime errors, so there's a bunch of testing and reviewing I don't have to do. -When using multiple slaves, I don't have to worry at all about accidentally sending a message to the wrong loop. The slave object can only be wired to it's own methods. Again, a mistake here is a compiler error instead of a runtime error, saving me a bunch of time down the road. -The names of the messages are not exposed to the calling vi. Whether you use strings or enums for your message names, you can run into problems if you ever try to change them. Since those names are never exposed or even known outside of the class, it is much easier to make that change and be confident you haven't accidentally broken functionality elsewhere. -Each message to the slave loop is a class method so it is very easy to discover what messages it accepts. I just go to that folder in the project window and look them over. I'll add any pertinant details to the vi's documentation so context help tells me everything I need to know. I don't ever have to dig in the execution loop itself to refresh my memory about what messages to send or what data types to use. All the gory details are encapsulated away and I have a nice clean api to work with. ------------------ As they say, the proof is in the pudding, so here are some block diagram images of execution loops I've created for a project I'm currently working on. The first slave loop is called by my top level UI and is an example of a facade. Notice it has three slave loops of its own. Each of those slave loops were created and tested earlier in the project. Those slave loops were designed to work together, but if I expose them directly to the UI then the UI has to handle all sorts of messages it doesn't really care about. That can be confusing so I created this slave loop object to hide that complexity from the UI. The second execution loop is from the 'DutCont' slave in the above diagram. In this instance I had a slave loop, 'XFireServer,' that has most of the low level functionality I needed, but I needed a watchdog timer to automatically send periodic messages. XFireServer's api is pretty low level, reading and writing to usb pipes, so I also wanted to create a higher level api with methods specifically for the device this tool is testing. This class encapsulates all that functionality and presents it as an easy-to-digest single class with only 7 public methods. As always, comments and critiques are welcome. [Edit Feb 23, 2011 - Added SlaveLoop template class.] Here's a template class with the basic SlaveLoop elements. It's built in LV2010 and does require the LapDog MessageLibrary package, included as part of the zip file. LD SlaveLoopTemplate.zip
-
Set "treat read-only VIs as locked" to true as default
Daklu replied to crelf's topic in Source Code Control
In general I agree with you. However, LV disallows more than just editing when a vi is locked. I can't copy-and-paste code or controls from a locked vi to the vi I'm working on. I can't right-click >> Find All Instances of a locked vi. (That one really irritates me.) Personally I enable those options on my dev computers, but I think it's a tougher sell to make it a default setting. -
I'm curious, in your opinion what is it that makes a QSM a QSM, and what changes would take that construct out of the definition of QSM? I'm working on a presentation for our local user group. "QSM" seems to mean something different to everyone and I'm trying to figure out what the essence of a QSM is.
-
QFT. Maintaining data between loop iterations and carrying it through the case structure doesn't make the loop a state machine. It just makes it a loop with data you want to persist between iterations. It *has* state, but it's not necessarily a state machine. The OP mentioned a "simple state machine," which I interpret as the enum-into-a-case-structure kind. For that the shift register is the best way to go.
-
Non-zero default values for reference types
Daklu replied to Tomi Maila's topic in Object-Oriented Programming
As a general rule, I disagree, though it may be true in your application. The best thing about events is that you can generate as many as you want and it doesn't matter if there are 0 listeners or 100 listeners. If nobody is consuming the event it disappears. I don't have to worry about stale messages clogging up the queue. Or let the event consumer component control the life of the event producer component. That works okay if there's a single consumer but gets problematic with multiple consumers. It also couples the event producer and event consumer code more tightly than perhaps you want. I don't think I'd be comfortable using an event in situations where I had to guarantee a listener is available. The one-to-many nature of events puts the event refnum life in the hands of the signal producer and makes it hard for it to know whether any consumers are executing. What happens if the consumer has an error and abruptly stops? How does it notify the producer of its status change? One nice thing about using queues instead of events for signalling is that since the consumer controls the life of its listening queue when it is no longer executing the queue refnum is released, raising an error at the enqueue prim to let the signal producer know that consumer isn't available. It makes a nice backup mechanism when--for whatever reason--the primary messaging system breaks down. I do this with queues quite often--multiple loops consuming the same queue with an inherent guarantee that only one is executing at a time. I would *think* it would work for events, but that whole mechanism is rather opaque so all bets are off. -
I heard about Scratch while listening to a podcast this morning and decided to take a few minutes to try it out. My 13 yo daughter has expressed interest in game programming but has a bit of a short attention span. I think I'll introduce her to Scratch. She's probably on the older side of the target audience, but it will get her thinking, as you say, algorithmatically. One thing I really like about it is the parallel nature of the script processing engine. Running scripts in parallel forces them (to some extent) to break down the problem into components instead of building monolithic single threaded programs. In the 1/2 hour I played with it it seemed very stable and easier to use than, say, the Mindstorms dev environment.
-
Non-zero default values for reference types
Daklu replied to Tomi Maila's topic in Object-Oriented Programming
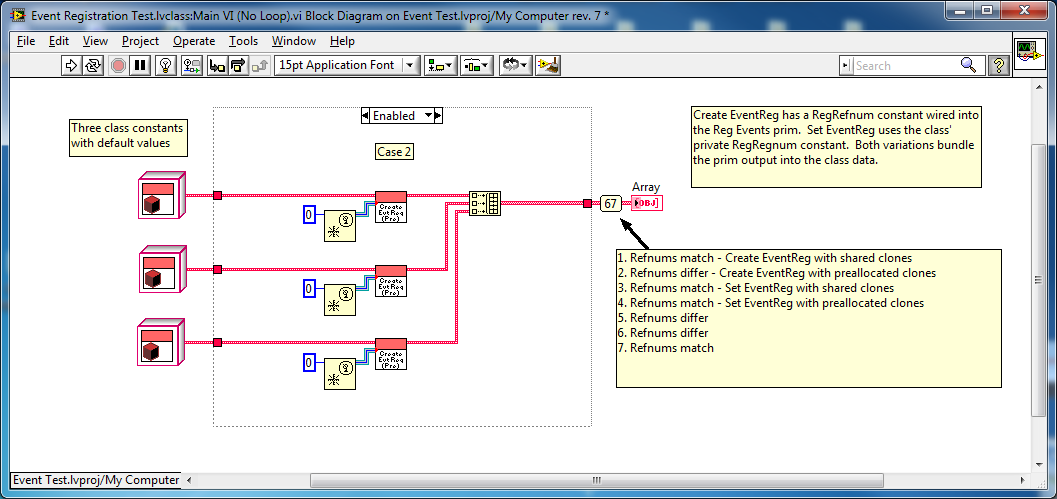
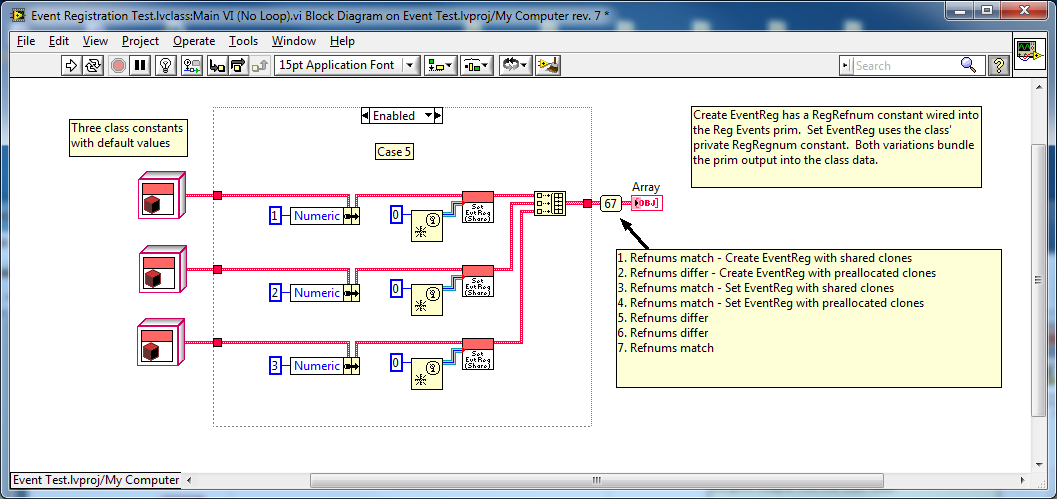
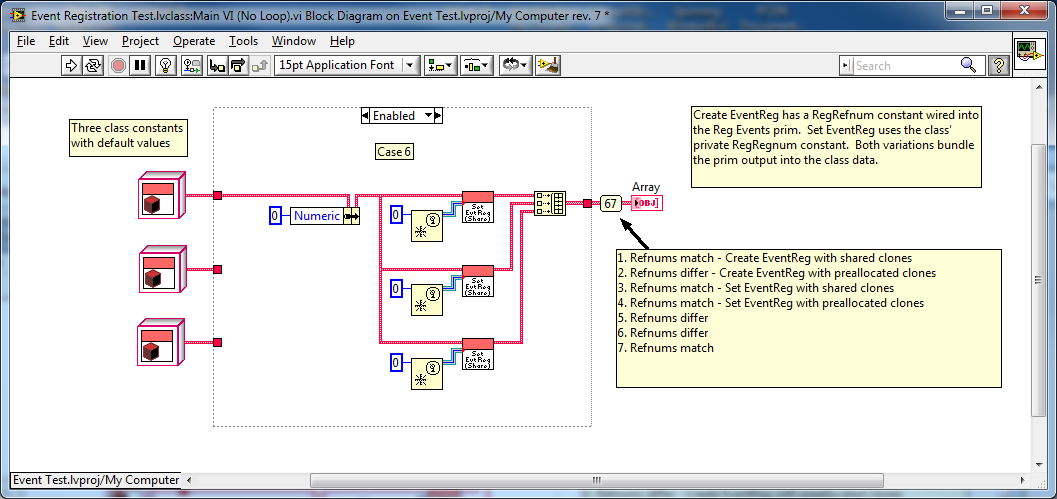
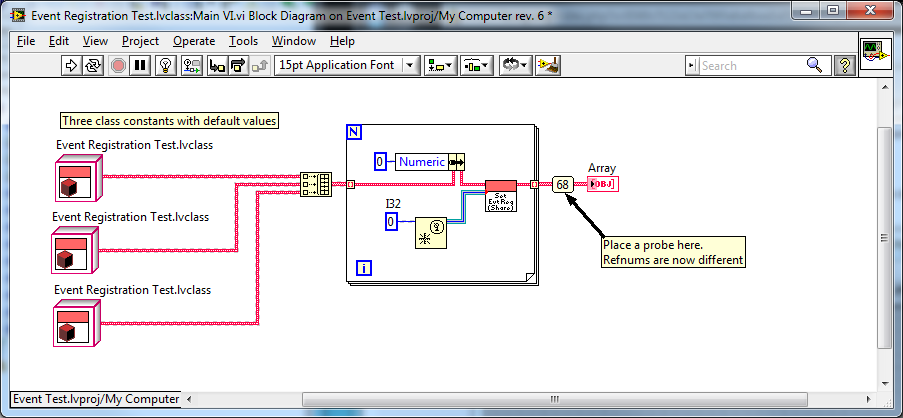
I agree. As long as I'm operating on the thing referred to and not the refnum itself, I shouldn't have to wire it through. But when changes to the refnum itself are propogated upstream? I attribute it to magic. Not sure yet whether it's black magic or white magic... Me either, I gotta get back to work. But first.... Here's some more evidence suggesting the value on the Event Registration Refnum wire depends on which refnum constant/control instance in memory it ultimately maps back to. In case 2 I changed the accessor to a preallocated clone and used a Refnum constant as the input to the Reg Events prim to guarantee different instances of the constant. The refnums returned were all different. Case 4 (not shown) is the same thing, except I unbundle the refnum constant from the class instead of using a constant on the bd. It returned identical refnums since all three object instance are default and all default objects point to the same instance in memory. Cases 1 and 3 were the same test using shared clones instead of preallocated clones. They returned identical refnums. In case 5 I forced LV to allocate independent memory space for each object by changing one of the values. It returned different refnums. In case 6 I "set" a class value to the default value, then branched the wire. In principle this is still a default object, but (if my theory is correct) LV doesn't recognize it as a default object and allocates space for it. Once the object is no longer default the accessor method seems to operate as expected. This returned different refnums. And finally, wrapping around again to Tomi's original example, making this change causes the refnums to be different. At this point I'll go out on a limb and say even if my memory is incorrect in this particular case, it's probably not a good idea to pass Event Registration Refnums as parameters. Event Registration Test.zip
-
Non-zero default values for reference types
Daklu replied to Tomi Maila's topic in Object-Oriented Programming
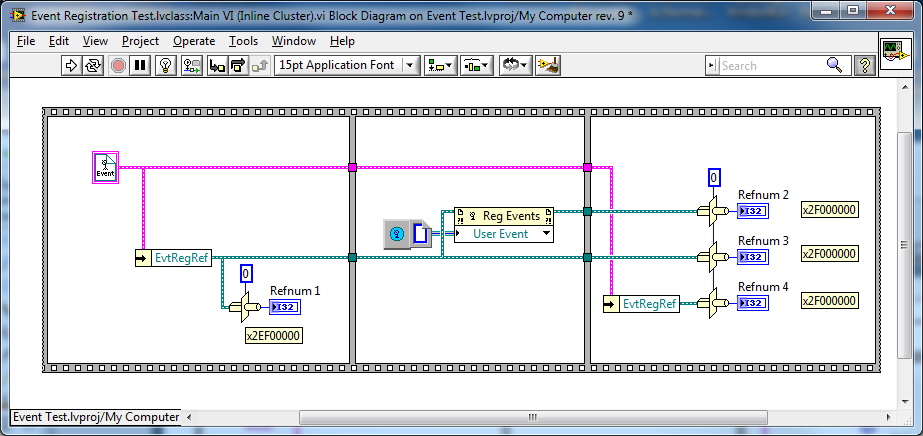
Nope. Same problem with a cluster. The refnum value appears to be intrinsically linked to a specific block diagram constant. Change the value downstream and the constant value upstream changes. Interestingly, if I change the cluster constant to a cluster control, Refnum 1 always returns 0 while the rest continue to match and change with each execution.