Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
When building large apps continuous integration helps ensure you're not breaking your executable when you check in new code. I've seen posts indicating some of the larger Labview shops do this. My question is how would I set up a system to automate the builds? Eventually I'd like a system that monitors the repository, automatically builds new code, and fires off blamemails when the build breaks. Do you have a dedicated build machine? If so, does it require its own Labview license? (I haven't seen anyone refer to a separate LV tool that just does builds, so I assume it does require its own license.) Are your builds automatically triggered when code is checked in or do you have to invoke it manually somehow? How would you set up a system to monitor your repository, and which scc system do you use? Are there any command line utilities for executing builds? Do you have to open a LV project and use scripting? Do your builds automatically run unit tests you have created? This is just an idea I've had floating around in my head for a while. I'm nowhere near close to implementing it, but I'd like to get some idea of what's possible and how much work it would take.
-
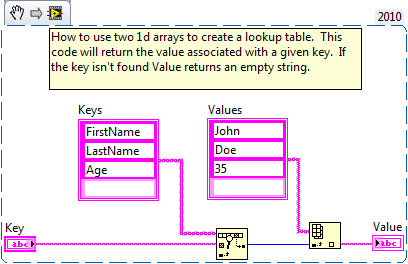
I think it's probably not a good idea for your application to rely on labels if there's another way to accomplish the same thing. Instead of putting each value in a unique control in a cluster, can you use a look-up table? Create a 1d array of strings to hold the names of the data. Create a second 1d array of strings (or ints, variants, etc.) to hold the data value.

-
Great link. I tend to forget about the wiki page. The original question is more about what everyone's favorite hotkeys are than what hotkeys are available. I thought it might give some insight into other developers' workflow. (i.e. Mapping context help to F1 and New Project to Ctl-Shft-N is a pretty good clue I use them a lot while coding.)
-
I'm curious what hotkey combos the rest of you use most frequently and what quick custom quick drop key combos you use. At home I have a Logitech G15 keyboard with 54 available macro keys. I keep thinking I should map LV functions to them but I just haven't gotten around to it yet. Here are the hotkeys I use most frequently: F1 - Remapped to toggle context help F2 - Rename Ctl-Shft-N - Remapped to open a new project (great for preventing cross-linking) Ctl-Shft-A - Remapped to Save As I try to set up my quick drop key combos so I can hit them all easily with only my left hand. Here are a few of them: stw - While loop (structure, while) stf - For loop stfs - Flat sequence structure stc - Case structure ste - In-place element structure stev - Event structure std - Diagram disable structure stcd - Conditional disable structure sterr - Error case structure carr - Array constant (constant, array) cb - Boolean constant 95% of my quick drop use is placing a structure of one sort or another. For some reason I haven't gotten into the habit of using it for other stuff.
-
Yeah, he was always one of my favorites too. Sadly I don't think I've seen Kermit on SS in forever. Did he retire after Jim Hensen died? Elmo seems to be the main face these days but I never bonded with him. (Probably because I was 15 when he first appeared.) It seems like there was a lot more subtle humor aimed at adults back in the 80s than there is now. One of my favorite sketches of all time was "The Golden 'An.'" ("Take this golden An to Stan in the tan van.")
-
That's good. My THC spider is getting the munchies...
-
(For those outside the US, you can see the original commercial .)
-

LVOOP constant with non-default parent values?
Daklu replied to shoneill's topic in Object-Oriented Programming
Despite my frequent visits to the soapbox and carrying on about a specific topic, there is no universal "right" thing to do. It all depends on your specific needs, priorities, and capabilities. I tend to follow AQ's second suggestion. Each of my class' Create methods are appended with the class name--Create MyParentClass.vi, Create MyChildClass1.vi, etc.--and the class output is static dispatch. That avoids potential name collisions in the inheritance tree yet allows the flexibility to initialize child classes with different data. I used to take the time to create abstract parent classes, but I spent too much time writing preventive error handling code to handle situations where a parent object is unintentionally travelling on the wire. I also found it a bit cumbersome to work with during the initial development process when I'm making lots of changes to class methods since every change required modifying two classes instead of just one. These days my first step is to implement one of the planned child classes as the concrete parent. Other planned child classes inherit from the concrete parent. If the need for an abstract parent arises later it's not difficult to create one and reassign the inheritance to have all the children point to the new abstract parent. (Of course, deciding when the concrete parent should be converted to an abstract parent is one of those decisions that only comes with experience.) The one time when I will start with an abstract parent class is when I'm creating a code module that needs to define a class, but other code modules will be creating concrete child classes to pass to the first module. In other words, one module is exposing an interface that will be implemented by another module. When my entire class hierarchy is contained in a single code module the extra overhead and complexity of an abstract parent usually wasn't worth it to me. YMMV. -
LapDog pre-release packages available for testing
Daklu replied to Daklu's topic in Object-Oriented Programming
LapDog, an open source initiative to bring mid-level object-oriented components to Labview, needs developers to provide feedback on our pre-release packages. Pre-release packages can be in various stages of development, from proof of concepts (POC) that may change a lot and never be officially released, to release candidates (RC) that are expected to be released soon and are very similar (or identical) to the released version. We're looking for developers to run these packages through the ringer and let us know their thoughts on them. Bugs are important, but they're not all that's important. Is the package API easy to understand and use? Is there anything you want to do that you couldn't do with the package? Did you experience any performance problems? Is the documentation sufficient? Are the method icons okay? While LapDog is currently targeting intermediate level programmers who understand OO principles, programmers of all skill levels are invited to participate and share their experiences. Pre-release packages can currently be found in a private community on NI's website. To join the group, send either jgcode or myself a pm with your ni.com user name. We'll add you to the community and you can download the packages. Current pre-release packages: Oct 06 2010 - Message Library v1 - RC - Object oriented messaging framework. Oct 06 2010 - Message Library v1.1 - Beta - Same as v1 with a PriorityQueue class added. Sep 27 2010 - Linked List v0 - POC - Linked list implementation using two queues. Sep 27 2010 - AdvDataStruct Linked List - POC - Linked list implementation using DVRs. I'll update this message as packages progress through development. Thanks, Dave- 1 reply
-
- 3
-

-
Gratz Cat. I've enjoyed your posts and admit to being more than a little jealous that you get to test your systems on a nuclear submarine. (Yeah, yeah... I know it gets old. But that first time...!) And can we eat it too?
-
I appreciate the feedback Shaun. This is the kind of discussion that makes LAVA so valuable. Good questions. Here's what I have in mind... In my project I have one task, 8 channels, and 8 scales. As near as I can tell users can't edit those in Max so this is effectively a default setup. I believe any custom setting will require a new task, channels, and scales to be set up in Max. New tasks are created only when significant parameters are changed, such as the number of signals being captured or changing the input terminals. Each Max scale will apply to a specific signal from a sensor, so there will be up to 24 of them. (On second thought... there'll be one scale for each setting on each signal, so there could be a lot of them.) I'll have a global virtual channel for each DAQ terminal giving me 8 of those. I think those scales and virtual channels will be sufficient to cover all combinations. When the test engineers are setting up a test they can go into Max and look at the Task details to see which terminals should be connected and change the sampling rate if they want. Then they go into the individual channels and modify the settings and scale to match the sensor signal they have connected to that terminal. There are a lot of scales to choose from but they are edited rarely, such as when I get an updated cal sheet for a sensor. If I'm thinking about this right, this should give the test engineers a lot of flexibility without completely overwhelming them. Are there any gaping holes I'm missing? Starting and stopping tasks during the test is out of scope right now. If they *do* come to me with that request, I'll roll my eyes, sigh loudly, and make them feel bad for even asking. That is a concern. The application doesn't actually use Max though. The app only cares about the Task. Max is just the interface for configuring the Task that will be run. I think I can design the app in a way that will make it easier to insert a new module that provides an alternate way to configure the Task for a given test.
-
You mean I'm actually supposed to read that? I suppose you faithfully read all the terms and conditions when you install new software too? Already have, except for reuse code. Still doing that work in 2009.
-
[Deleted when the two threads were combined.]
-
Not so much intimidated as cautious. I've been burned too many times by details I thought would be easy. Our group has developed a bit of a reputation for over-committing and under-delivering. (Lots of reasons why... some we are directly responsible for, some we are not.) I'm trying to get that turned around with this project. Because it's highly visible and on a tight schedule, I'm hesitant to go down any rabbit hole I can't see the bottom of. I don't want to start a new code module I need to develop and maintain unless we really need it. It's not just the DAQmx part of it, it's also that that aspect of the test system requirements aren't very well defined yet. I do know we won't be using anywhere near 192 different sensors. At most there'll be a pool of maybe two dozen possible individual signals, each with anywhere from 3-6 selectable scales, each with their own calibration info, each potentially measuring something different (acceleration, temp, etc.) We'll be capturing up to 8 signals at a time on an arbitrary terminals. The sample rate isn't known yet. Should all that info come from the config file? Should I use a combination of Max and config files? What should the config schema look like? How will I simplify setting up a test in the future? How do I stupid-proof the config file? What are the other signal parameters I haven't thought of? There's lots of questions I don't have answers to right now. So I punted.
-
Good analagy. I'm sure I come across as an ivory tower theorist at times--maybe even most of the time. I really am much more interested in the practical side of things. It's just that I need a more ivory tower approach than many others to meet the flexibility requirements in my current environment. (And as a practical matter, I really, really, hate rewriting code.) Wha...? NI has a "Product Development to Manufacturing Transition Toolkit?" *Now* you tell me... More seriously, you are absolutely correct. Although I have programmed in all those positions it often wasn't my primary responsibility and had to do it in my spare time. There are lots of specific things I don't know how to do that people with more Labview experience see as second nature, or even essential. NI Max is a one example. Until last week tasks confused me. Databases is another example. It's been over a decade since I've created any software that interfaces directly with a database (and that was in VB6.) That's practically the #1 requirement for manufacturing test systems. Fortunately, the other two developers have more overall LV experience than me and can help me out with the things I don't know. (Now I just need to wean them off procedural programming.) Ouch... that's a pointed compliment. Normally that is what I try to do. In this particular instance I'm choosing an option I know (thanks to feedback on this thread) may present scalability issues in the future. Why? It's the less-risky option right now. DAQmx is new technology for me that I don't understand well enough to be comfortable rolling my own Max interface. I could spend a lot of time learning DAQmx and implementing something that ultimately doesn't work. Instead of risking wasting that dev time, I'll abstract the Max aspect of the app and replace it with something that scales better when the need arises.
-
Need you ask? I've held positions across nearly all the stages of a product's life cycle: Conception, development, transition to manufacturing, manufacturing sustaining, etc. The only stage I haven't been involved in is end-of-life.
-
This is for 2009 only? I'm not given the option to install the package for 2010.
-
There are some engineers who think like that, but most understand that there are layers of complexity to what they're asking for. When someone tells me what they want and then slip in a, "that should only take a couple weeks," I'm very blunt in my response. "*You* define your feature list and priorities. *I* define the delivery date." There are two LV programmers here now and another one starting on Monday. Our group has been the bottleneck at times in the past, primarily because of poor planning and unrealistic expectations. We're learning how to get better. These days I put off almost all UI development until the end of the project and focus their attention on the core functionality they need. We've spent too much time in the past rewriting user interfaces to accomodate the latest change requests. I also make the test engineers directly responsible for what features get implemented. How do I do that? I develop in two week iterations. At the beginning of an iteration I sit down with the test engineers and their feature list and I ask them what features they want me to implement over the next two weeks? If I think I can do it, I agree. If not, they have to reduce their request. (Usually I have one or two features that are the primary goals and several items that are secondary goals. Sometimes I get to the secondary goals, sometimes not.) At the end of the iteration I deliever a usable, stand-alone functional component with a very simple UI that does exactly what was requested, no more. They can use it immediately as part of the chain of individual tools I'm giving them every two weeks. Hopefully at the end we have time to wrap it all up in a larger application and make it easier to use, but if we don't they still have the ability to collect the data they need. If we hit their deadline and something isn't implemented, it's because of their decisions, not mine. So far this is working out very well, but it's still very new (I'm the only one doing it) so we'll see how it goes over time. (I talked about this a little more in this recent thread on the dark side.)
-
Thank you. It's good to be wanted. I knew some manual processing was going to be needed. The question was asking how other people dealt with the problem I was having. Jon suggested using the Configure Logging vi on the task. COsiecki suggested retrieving unscaled data and getting the scaling coefficients from the task. You suggested implementing everything as a configurable ini. All viable solutions. All with different strengths. All appreciated. Easier, no doubt about it. Regardless of whether the app is implemented using OOP or procedural code, if they have to come to me for any little change it causes delays in the entire product development process. I call them "throw aways." Unfortunately that isn't acceptable in this situation. Here's a bit more of an explanation of my environment: I write test tools for a product development group. Early in the product's life cycle the dev team is evaluating all sorts of alternatives to decide which route to take. The alternatives can be entirely different components, different types of components, different combinations, different algorithms, etc. Anything about the details of the design can change. This process can take months. The tool I give them for qualification testing needs to be as flexible as possible while providing solid data that is easily comparable. If I or the test engineer is constantly going in to tweak the tool's source code, config file, etc., then it allows project managers and design engineers to more easily question the validity of results they don't particularly like. In this particular project, part of component qualification is comparing the ADC signals to signals received from other sources (I2C, wireless capture, vision system etc.) to cross check the data from the various components. It also requires coordinating the motion of complex external actuators with the data collection. Using the external actuators and parsing the other data streams is beyond the programming capabilities of the test engineers. (And they don't have time for it anyway.) As the product's design becomes solidified that kind of flexibility is deprecated. Design focus shifts from component qualification to product performance. Test efficiency and consistency become much more important as multiple samples are run through tests to obtain statistically significant data. Unfortunately the shift between component qualification and product testing is very blurry. There is no "we're done with component qualification, now let's build tools for product testing." The code written for qualification testing becomes the code used for product testing. I do take shortcuts where I can during the component qualification. UI's are very simple wrappers of the module's* underlying functional code and are often set up as single shots. (Press the run arrow to execute instead of a start and stop button.) There isn't a lot of integration between the various functional modules. Error handling probably isn't robust enough. But the functional code of each module shouldn't change once I've written it. (*Some of the modules we have finished or have in the pipe are an I2C collection actor object, an analog signal collection state machine, a sequencer for the external actuators, a wireless collection module, a few analysis modules, etc. Currently each of these function independently. The intent is to combine them all into a single app later on in the project.)
-
I guess I'm still a newcomer... I don't think I've ever heard of VI Shots. There will be people interested in all those topics and any other one you can think of. My question is what's the purpose of VI Shots? Is it to share tips and tricks--kind of video version of Darren's Nuggets? Or is it a more in-depth instructional tool? If it's the latter, casting too wide a net means there won't be enough content on any one topic to bring people in. Figure out the purpose and your target audience and the content decisions should be fairly easy.
-
"Labview allows modification, but not reinvention." I'm not sure what he means by that. Anyone have a clue? "Folks learned in Labview are walled off from just about all other hardware solutions." He's referring to developers who create test apps using Labview not wanting to consider other hardware vendors. Sounds like a disgruntled salesman... There's nothing inherent in Labview that prevents me from using other hardware as long as that vendor has supplied a good api. We rarely use NI hardware in our test systems: Total Phase Beagle and Aardvark instead of the USB-8451, Fanuc robot controllers instead of NI Motion, independent Agilent spectrum analyzers and VSGs instead of NI's virtual instruments, etc. We use NI hardware when that solution is the best one available, all things considered.
-
Quick responses... gotta run soon. We're crossing signals somewhere in here. If I do a Read that returns a waveform, the data is post-scaled, which I don't want to save due to size and I don't want to truncate due to lost precision. If I do a Read that returns the unscaled I16 data, then I have to manually apply the arbitrary scaling factors before displaying it. Me too. Except that it's their job to play with all those things to try and break the products. I can't restrict what I allow them to do, or they come back every other day and say, "now I want to be able to do..." My tool becomes the blocking issue, and that's bad mojo for me. (My tools are used by test engineers in a product development group. They need to be able to handle whatever screwball changes the design engineers conjured up last night at the bar. These are not manufacturing test tools with well defined sequential test processes.)
-
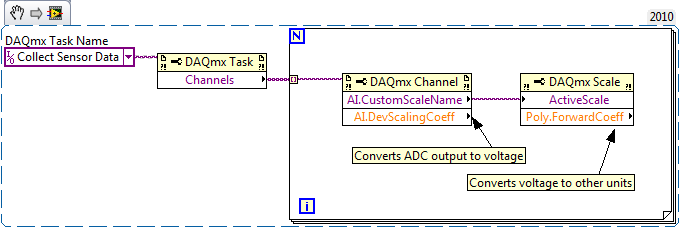
You're lucky I can't take them back. That diagram doesn't do what I need. I need to keep every bit of data from the 16-bit ADC; your diagram is going to lose precision. I could avoid that by having them enter all the scaling information in the ini file... except I'm collecting data from m sensors simultaneously and there are n possible sensors to choose from to connect. On top of that any sensor can potentially be hooked up to any terminal. And they'll need to be able to add new sensors whenever they get one, without me changing the code. Oh yeah, it has to be easy to use. Can all this be done with an ini? Sure, but the bookkeeping is likely to get a bit messy and editing an ini file directly to control the terminal-channel-scale-sensor mapping is somewhat more error prone than setting them in Max. Implementing a UI that allows them to do that is going to take dev time I don't have right now, and since Max already does it I'm not too keen on reinventing the wheel. I don't think your technique is bad--heck I'm ALL for making modular and portable code whenever I can. This is one bit of functionality where I need to give up the "right" way in favor of the "right now" way. Heh... they're test engineers in a product development group. They play with everything you can imagine related to the product. (Read: They want infinitely flexibile test apps.) But they don't play with the data. That better be rock solid.
-
I appreciate all the responses. Kudos for everyone! Well yeah, but show what on the graph? Users want to see scaled data; I want to store store raw data. In a nutshell the question was about manually transforming between raw, unscaled, and scaled data. Thank you for the detailed response. That's exactly what I was hoping for. I'll probably go with Jon's solution for now given time constraints, but I'd like to understand how to do it manually in case I need more control in the future. That got me pointed in the right direction. If I'm understanding the DAQmx correctly I'll use the channel and scale coefficients to do the transformations like this: Whoa.... no way! <jaw drops in amazement> (I did discover that... after I had already created everything in Max. I didn't see any way to transfer Max stuff over to the project so I had to redo it all manually.) Do you export them so the user can edit them in Max? It looks like the mx items are available to the app without exporting the config, but then they are not available to Max. Yes? Does this mean I can't create separate tasks in Max that all use the same physical channels, even though I'll only be using one task at a time? Hmm... this could be a problem over the long term. We're going to be using a single data collection computer to measure signals from different sensors, depending on the test being done. I had planned on having the test engineers use Max to set up new tasks, channels, scales, etc. and select the correct task in the test app. But if that's not possible I'll have to create my own interface for that. (Ugh...)