Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Beer induced deadlock?
-
Okay, I believe you. I played around with your vi a bit and threw up some booleans to indicate various mouse events. I noticed a few things: No MouseUp events are firing on the array, tab, or pane, even though the behavior makes it look like it is. It doesn't have to be a Tab.MouseMove event. It will also halt on Pane.MouseMove or Array.MouseMove events, as long as those events are being fired. If you move the mouse cursor off the control that is triggering the MouseMove event it won't halt and you can keep scrolling. If you click and hold on the scrollbar (not on the handle) and move the mouse (keeping it inside the scrollbar edges) while the handle is scrolling, it will halt. Not much help, but at least you're not going crazy.
-
 I read up on this a little bit and in the US, posting something on the web does NOT invalidate your IP rights. The Copyright Act of 1976 extends copyright protection to all "original works of authorship fixed in any tangible medium of expression, now known or later developed, from which they can be perceived, reproduced, or otherwise communicated, either directly or with the aid of a machine or device," although it is not clear to me if this protection extends to software. What I get out of it is if you create original software (and assuming software can be copyrighted), it belongs to you regardless of whether or not you actually apply for a copyright or where you post it. However, the NI website includes the following: [underline added]So regardless of any licenses you attach to your driver, NI can do whatever they want with it; however, if you do not include a license the other company cannot download the driver and package it as their own. How do the BSD licenses and GPL fit in? IMO neither of them protects "your rights." (Although I do think both have their uses.) The BSD license essentially protects others who use your code from you deciding to sue them at a later time. In practice it looks like it effectively releases your work into the public domain. The GPL...? I'm not really a fan of it so I'll reserve comment. But again... I'm not a lawyer and I may have completely misinterpreted everything.
I read up on this a little bit and in the US, posting something on the web does NOT invalidate your IP rights. The Copyright Act of 1976 extends copyright protection to all "original works of authorship fixed in any tangible medium of expression, now known or later developed, from which they can be perceived, reproduced, or otherwise communicated, either directly or with the aid of a machine or device," although it is not clear to me if this protection extends to software. What I get out of it is if you create original software (and assuming software can be copyrighted), it belongs to you regardless of whether or not you actually apply for a copyright or where you post it. However, the NI website includes the following: [underline added]So regardless of any licenses you attach to your driver, NI can do whatever they want with it; however, if you do not include a license the other company cannot download the driver and package it as their own. How do the BSD licenses and GPL fit in? IMO neither of them protects "your rights." (Although I do think both have their uses.) The BSD license essentially protects others who use your code from you deciding to sue them at a later time. In practice it looks like it effectively releases your work into the public domain. The GPL...? I'm not really a fan of it so I'll reserve comment. But again... I'm not a lawyer and I may have completely misinterpreted everything. -
I agree. A 50 ms process in an event case is a long time. Hmm... I think there are significant problems with this idea. Discarding events based on whether or not that event is already in the queue is a bad idea because it depends in part on the number of events in the queue, which the programmer has no control over. This would make for very unpredictable behavior. Furthermore, if you keep only the most recent instance of the event it might never get processed because new events go to the back of the queue. Discarding new duplicate events and keeping the original could be useful in certain circumstances, but it is easy enough to implement using a notifier to trigger an event processor. If anything a 'no duplicate queue' would be better implemented as a downloadable reference design rather than an addition to current event structure.
-
I'm not sure what you're asking. The layout system itself is already implemented somewhere in the depths of Labview. Are you after documentation on that system to improve fp performance? Are you looking for a framework to help with resizing the fp during runtime?
-
crelf, the only person on earth who can manually instigate a denial of service attack. Script kiddies got nuthin on you.
-
Best thing to do is keep all your project files in a single folder tree. Then you can move the folder around and make copies however you see fit. If you are going to have multiple copies of the project open at the same time be sure to rename one of them.
-
Yes, but in the example I'm presenting all the methods are abstract. Not quite. Interfaces typically share some of the same behaviors as classes (such as inheritance) but an interface is a separate and distinct construct with unique abilities. Making all of a class' methods abstract does not give it the abilities of an interface. I take this to mean you typically have factory VIs or some other method to manually insert the child object (HashTable, etc.) into the client object (Variant Collection)? At first I thought you were describing the third workaround I mentioned. Then I reread this section and remembered once long ago when I accidentally changed the default value of an object cube and ended up with a black box around it. I'm guessing you're referring to doing the same thing here? I went ahead and followed your instructions from that thread and now have the lovely black box around the CollectionImp object in my VariantCollection.ctl. This does seem to solve the concerns I have with the other three methods I mentioned. As an added bonus, it also answers my use case question in the other thread! I do wish there were a better way to set an object to non-default values and determine what the actual object is though.
-
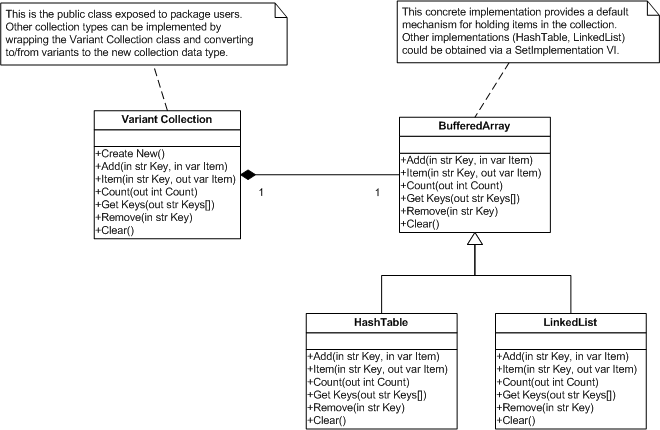
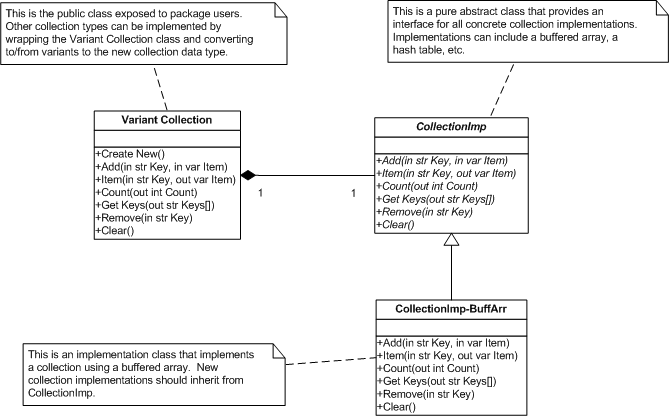
I admit it. Long ago I drank the kool-aid AQ was offering and I liked it. Despite all the bumps and bruises I've come back for a second serving by jumping Head First into Design Patterns. One of the bigger questions I haven't answered is how to best implement design patterns that use abstract classes when composing objects. For example, in my collection package the Variant Collection class has a CollectionImp object as private data with the expectation that the actual object at runtime will be a BufferedArray, HashTable, or LinkedList. This presents problems in the Labview environment. Dropping a Variant Collection object on a VI creates a Variant Collection with a CollectionImp object instead of one of the child class objects. Since the CollectionImp class has no code implemented in its methods the Variant Collection object will not work. Unfortunately Labview currently has no way to enforce initializing an object's private data at runtime. One common workaround is to have the abstract methods in CollectionImp throw an error at runtime. This works but it doesn't prevent the mistake in the first place and I am really tired of writing errors in all my abstract methods. (On top of that naming becomes an issue. How many ways can I say "raise error?") I was very excited to see the Must Implement option in LV2009. Initially I thought I wouldn't have to write any more "Invalid call to abstract method" errors. It turns out my excitement was short-lived. Another suggested workaround is to make the Variant Collection class a private member of a wrapper lvlib. This prevents users from dropping an object directly on a VI. Then you add a factory vi to create Variant Collection objects with the appropriate CollectionImp child class and wrapper VIs for each Variant Collection method to be exposed. (I've attached a modified version of Christina's Factory Pattern example that illustrates this.) This has several consequences. First, it's a lot of extra code to write, icons to make, documentation to verify, etc. Second, wrapping everything in a library means all of it will be loaded into memory rather than just the implementations that are used. Third, package users cannot derive their own collection implementations from the abstract class. Whether this is a positive or negative depends on your specific goals; nevertheless, it is a consequence. A third workaround is to replace the abstract CollectionImp class with a default concrete child class. (This is what Christina did in her Factory Pattern example. The "Generic Plugin" is in reality a "Black Plugin.") By doing this the problem associated with dropping a Variant Collection object directly on a vi goes away and a Create New vi is not needed. A mechanism needs to be provided that allows collections to use other implementations, but there is some sort of working default implementation. My hesitancy to use this method is partly because it violates the design principle of Depend on abstractions rather than concrete classes. I still don't have a good idea of how that design principle applies to Labview or what the long term consequences of violating it are. It's an unknown and I have no way to evaluate the risks. Another downside is that it can be harder to reuse the concrete implementation classes. The default concrete implementation may have methods that are not appropriate for the child implementations. For example, BufferedArray has Grow and Compress methods to allocate and recover array space. These may not have any practical meaning in the context of a hash table or linked list, so I'm forced to override them will null methods. This is generally considered bad OO design. If sometime in the future a developer were to use the HashTable object directly, they would find the class api littered with null methods. So my fellow LOOPers, how do you handle this situation? Do you typically use one of the methods here or a mix of all three? Are there other ways of dealing with the lack of object constructors initializers that I haven't listed? As always, all comments are appreciated but I'm especially interested in hearing from those who have developed a reusable code base for other LV developers. Wrapped Factory.zip

-
I agree. My main issue with them is typically they don't do quite what I want or don't give me quite the control I'm looking for. Can you explain this a bit? Is the init-destroy sequence executed each time during runtime or each time you drop an express vi on a block diagram?
-
As rule I tend to avoid express VIs, but I happened to click on a link in Christian's signature and found this. I haven't looked at it in detail, but this may be the one express vi I'm willing to use.
-
I'm non-premium and was able to report Philip's post and the post rolf linked. Admin edit: Yep - your report got through (Daklu: "Possible spam, but mainly testing the 'report to moderator' feature.")
-
You want an airplane with that margarita?
Daklu replied to Michael Aivaliotis's topic in LAVA Lounge
I wonder if they have a height restriction for vehicles driving along that road. Be a bummer for all involved if a 747 bounced off the top of a semi. -
"List wrapping?" I'm unfamiliar with that term. (I think I need to code up a parser to understand that sentence. ) I don't see any discussion about this in the document. Is this reminder soon enough? BTW, the image in the section What is the purpose of the "LabVIEW Object" class? doesn't render correctly. The second frame is almost complete cut off.
-
Diverging from commonly accepted OOP language is a big mistake IMO. There are lots and lots of books available on object oriented programming. There are no books available on Labview object oriented programming. Anyone who wants to learn how to do OOP in Labview is going to have to read one of the books that focuses on another language. Introducing different terminology confuses the issue and becomes an obstacle to learning. (Heaven knows it's already hard enough to translate design patterns into Labview.)
-
I've been experimenting with friend classes as a way to limit the public interface of my code modules. For example, I created a set of classes in 8.6 to support Collections that I distribute in a single OGPB package. The Variant Collection class is the only one I want exposed to package users. In 8.6 I have to wrap everything in an lvlib and set my supporting classes, CollectionImp and CollectionImp-BuffArr, as private. That works reasonably well for now but I don't like the way it scales. Since libraries load all member vis the package memory footprint will grow as I add different collection implementations (hash table, linked list, etc.) With LV'09 I can designate the Variant Collection class as a friend of my support classes and give all the support class members community scope. I get almost* the same level of protection and instead of loading every collection implementation when LV starts I can dynamically load only the implementation I need at runtime. *Using friend classes a package user could create new child classes from my support classes. They cannot do that when I wrap my package in a lvlib. As Paul_at_Lowell alluded, friend scope in LV does not allow direct access to private data. It simply allows you to designate certain methods as 'semi-private' and decide who is allowed to use them. The class designer still has to create accessors to get/set private data.
-
I'm not a lawyer and have little interest in reading licensing details, but I don't think a company can take code from the public domain and prevent others from using it by putting a license on it can they? (Not that that's what you're saying.) They could use the source code as a basis for their own licensed code or even redistribute the same code under license, but claim sole ownership of something that is in the public domain?
-
Wikified. (Although I'm sure I violated all sorts of wiki rules.)
-
OpenG Builder & the Version vi
Daklu replied to Daklu's topic in Application Builder, Installers and code distribution
I've checked that. That's not it. I found a bug that was causing the problem, but I don't have any idea what effect my "fix" would have on anything else. I started a thread over on the OpenG forum with the details. I could use a prebuild script to read the version info from the version text file, but I don't see a way to link back to the package build config file to update the build information there. I was hoping for a way to dynamically figure out which build spec is being executed so I don't have to create unique scripts for each package. -
Dynamic Loading and Unloading of Libs?
Daklu replied to danielsan's topic in Application Design & Architecture
Poor namespacing strategy (by NI) stikes again! This sounds like an SVN question, which I don't use, but I can appreciate the problem and have developed a workflow that works regardless of your source control system. It may or may not apply to your situation. I'll make the following assumptions: You don't code against your reuse code's source. What I mean by this is when you create a reusable code module you build and install it to the expected file system location (even on your dev computer) and all code you write links to that instance, not the instance in your development directory. You use some sort of version numbering scheme with your code modules. Most people follow the major.minor.bugfix.build convention; however, differentiating between a major and minor revision tends to be open to interpretation. First, my versioning rules state that I increment the major version number if and only if backwards compatibility is broken. I could end up with unusual version numbers like 1.98.3 or 36.0.1. Doesn't matter. The whole point of the major version number is to differentiate between incompatible module releases. Second, when I build the source I append the major version number to any public top level libraries. If I have four classes in my module then the build process renames them MyClass1__v1, MyClass2__v2, etc. If the four classes are wrapped in a lvlib then I can get by with only renaming the library MyLabviewLibrary__v1. (I use OpenG Builder to build code.) Third, I deploy each module as a package to a directory that includes the major version number as part of name. (C:\reuse\MyLabviewLibrary v1\MyLabviewLibrary__v1.lvlib) I strongly recommend VIPM for managing your reusable code packages. If budget constraints are getting in the way you can get by with OpenG Package Builder and VIPM Community Edition, both of which are free. If you have the money you'll likely save time and frustration by purchasing VIPM Professional. Following this strategy gives me the following benefits:When I release compatible updates to a code module it is deployed to the same directory and all dependent code automatically uses the updated module. When I release an incompatible update, the previous version of the module is not overwritten and dependent code can continue to use the old code. Upgrading an application to use a new major release requires some level of manually replacing the VIs from the old module. Some may not think of this as a benefit, but I do. It forces me to be more rigorous when changing the application code to account for the incompatibilities. I recently gave a LUG presentation on managing reuse code. You can find it here. -
A (perhaps) better solution is to release them on the NI's Instrument Driver Network. Then the source code is out there and available for anyone else to use/improve.
-
New QuickDrop shortcuts not working
Daklu replied to Shaun Hayward's topic in Development Environment (IDE)
You're my hero. I just ran into the same problem. Thanks for posting the solution! -
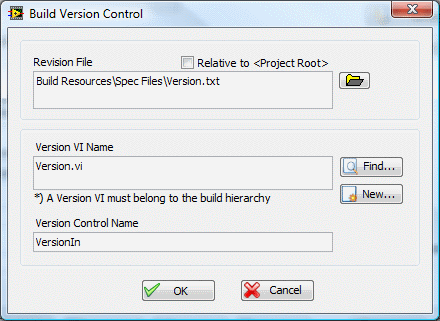
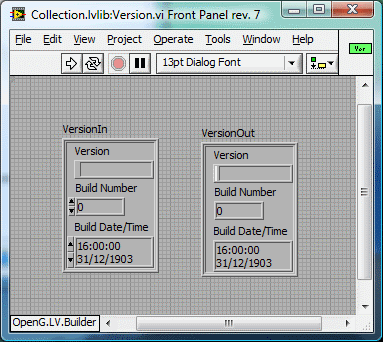
1. I've been unsuccessfully trying to use the Version.vi option using OpenG Builder. I got it working briefly several months ago but I can't remember exactly what I did. As I recall the Version.vi front panel control default value should be set with the latest version information. I think I've set up correctly but for some reason it's not working. The version text file is being updated correctly. Any ideas why the built Version.vi isn't obtaining the version info? (This is especially embarrassing as I gave a LUG presentation on OGB a couple months ago and now I can't get it to work! ) 2. Is there some super-secret magic needed to get the version New... button to create a version vi for me?. I've tried several different things but nothing is ever created and no errors pop up. The dialog box just silently closes. 3. It would be nice to automatically incorporate the latest version info in the package when I build using OpenG Package Builder. There doesn't appear to be a way to automatically hook into the package information with scripts, which leads me to believe I need to either grab the ogpb file from the source directory (or maybe the temp directory) or wrap the package building process in another vi. Is there an easier way I'm missing?
-
I'm definitely interested and reviewing your code is on my short list. I just haven't had the time yet.
-
Doesn't the 'View Unread Content' link in the upper right corner (next to the RSS icon) do what you want? Assuming, of course, that you previously marked the threads as read.