Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Figured it out... sort of. Since these are the Unicode versions of the functions I need to manually convert the strings to 16-bit arrays. Unfortunately it looks like Labview stores the current directory internally rather than using OS calls. No matter how much I change the current directory the XML dialog box defaults to the last directory used from within Labview.

-
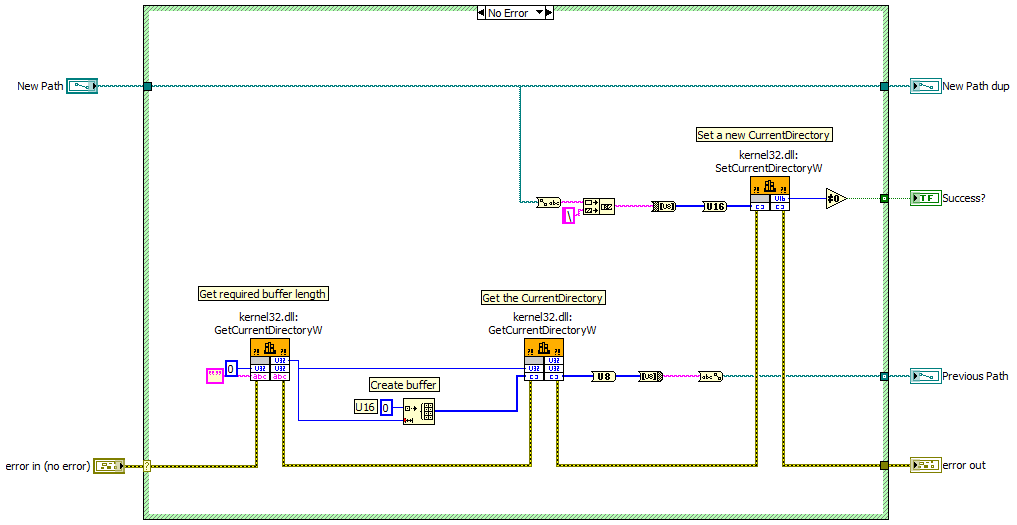
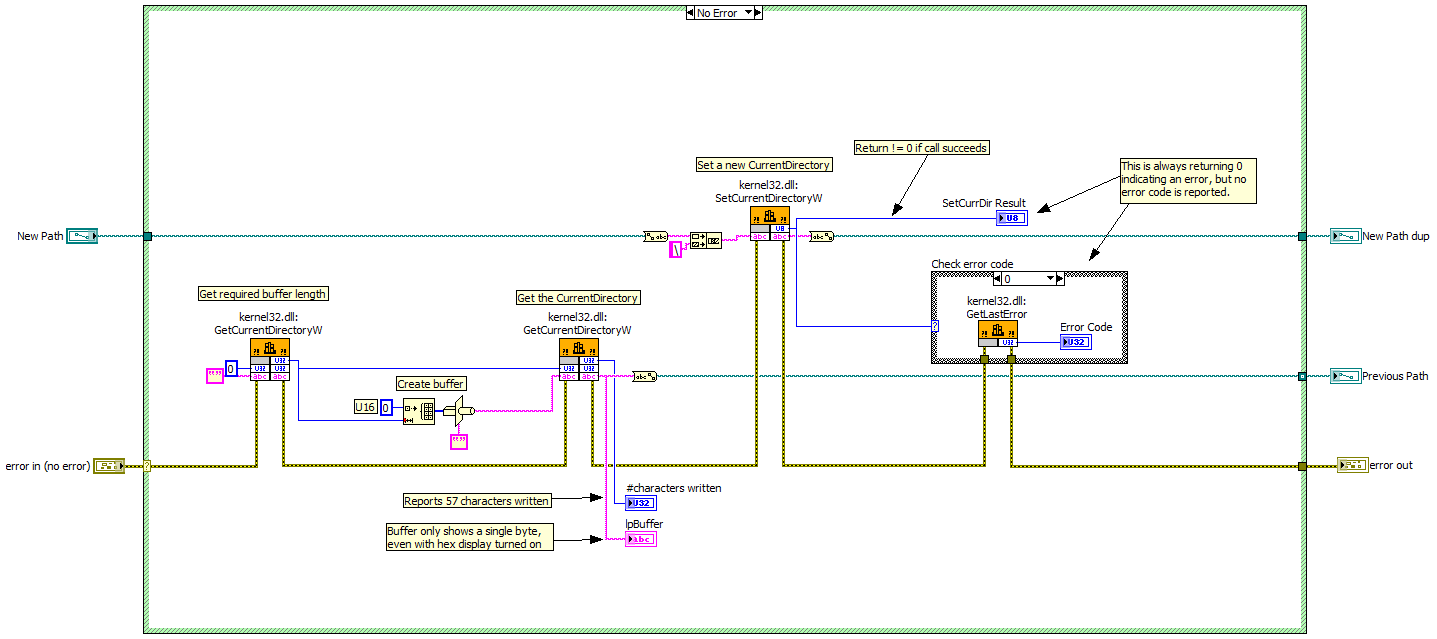
I have an app that saves various types of configuration files in xml format. To avoid mixing the different types of configuration files, I have different default directories for each type. For simplicity, I use the Read/Write to XLM File VIs and let the user select the correct file via the automatic dialog box. To get the correct default directory to show up when the dialog box opens I've been trying to use the Get/SetDefaultDirectory functions in kernal32.dll. Problem 1: The string returned by the second GetCurrentDirectory call is only showing the drive letter, even though the function is reporting many more characters being written. Problem 2: The SetCurrentDirectory call reports an error but checking the error code turns up nothing. Problem 3: The vi occasionally crashes LV. I think I have all my call parameters set up correctly... Any ideas? Set Current Directory.vi
-
Are you sure you want to convert your application into an OO approach? If your application is already working or you have deadlines for getting it working, I'd strongly recommend sticking with traditional LV programming. Learning OOP is a bit like being a kid at an amusement park; every time you turn around you see something better that you just gotta try out. (Usually because the new approach appears to solve a problem your current implementation can't address.) End result? You can easily spend a lot of time rewriting the same code over and over. If your paycheck depends on you producing working software, start learning OOP on side projects. (Like the CLD practice exams.) </soapbox> Now, to more directly answer your question... There are several rules of thumb for OO programming. One that applies to your particular question is the "Open/Closed Principle." This principle states that working code should be "open to extension but closed to modification." It is based on the idea that once you have working code you don't want to be mucking around in it and potentially introducting new bugs. In other words, if it ain't broke, don't fix it. Unfortunately there isn't enough information for me to suggest a "best" approach. It depends a lot on what can be changed, either by the user when running the application or by new application requirements. You mentioned Program1, Program2, and Shutdown. Do you also need to support the possibility of Program3, Program4, ..., ProgramN? Can the user change the program contents at runtime? Do you need more than one program object at any given time? Do you expect to be able to use your program class in other applications? Option 1 is the easiest to implement but as expected, offers the least flexibility. Users have to select the program from a predefined list. You have to edit your class source code to change a program or add new programs. Not only that, but when you add new programs (Write Program3, etc) you'll have to modify your application source code to use the new program. This clearly violates the Open/Closed Principle. Finally, this implementation makes it more difficult to reuse the Program class in other applications. Depending on your exact implementation, Option 2 doesn't offer any functional advantages over option 1 in the short term. Its benefit comes in code maintenance. It is a more standard design and I believe more easily understood by developers new to the project. It is also more easily refactored to extend your application's functionality. For example, you could relatively easily implement a plug-in architecture that allows you to create and distribute new Program child classes without modifying your application code base at all. (Trying to do that with option 1 requires you to modify your Program class, which is part of the application's code base.) Option J ( ), with its SetProgram method, allows for the possibility of having users define new programs at runtime. It also allows you to easily reuse the Program class; you don't have to change its source code at all to adapt it to other applications. A plug in architecture can be implemented that allows programs to be stored as text files, making it very easy to create new programs using notepad. It does not allow for an arbitrary number of simultaneous programs. (But then neither do the other options.) Perhaps ironically, I think it is also a simpler design than either option 1 or option 2. Whether or not it is the best option depends on your specific requirements. There's a good reason it seems more complicated. It is. IMO, object oriented programming generally does not reduce complexity of the application as a whole. What it does is encapsulate sections of complexity so you don't have to keep the entire application in your head to understand what is happening. Each layer of abstraction adds some amount of complexity, but once you have that working you can forget about the details and just know your Program class is working as expected. Keep in mind that as you become more familiar with OO patterns things that at one time seemed complex become much less so.
-
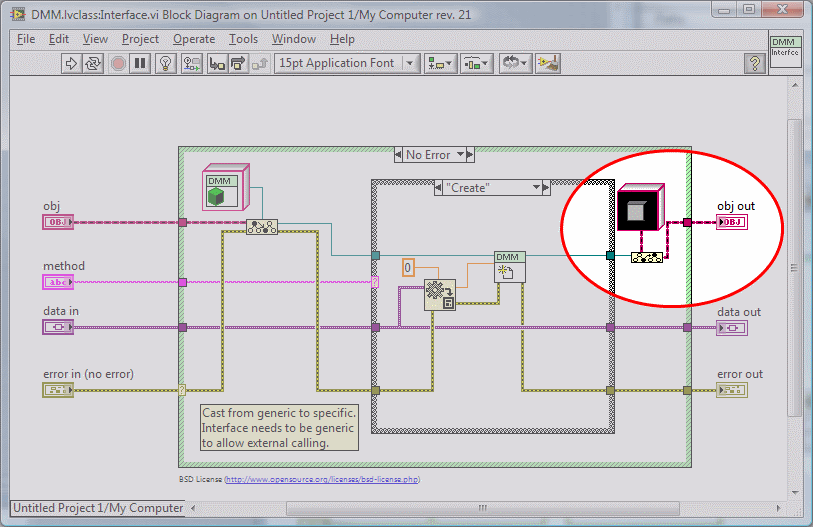
Yeah, I drank the kool-aid a couple years ago. The biggest benefit I get out of it isn't dynamic dispatching, it's the encapsulation. My code is much cleaner when I'm using classes. I'm more aware of when I'm linking things that shouldn't be linked and I'll stop and do it "right." (Well, try to do it right anyway.) I've really been having a lot of fun exploring what I can and can't do with LOOP.I was going to post my code yesterday but I've been having problems with a package dependency. VIPM hasn't been showing it as available for installation. Almost. The fp control that you created the constant from has to have non-default data set as its default value. That object block contains a DMM object. If you ran the VI, selected Edit -> Make Current Values Default during your testing, and then created the constant from the output terminal that would have done it. I've just recently started using non-default class constants on purpose. I've found it an effective way to eliminate the requirement for a 'Create New' method in certain cases. That's an important gotcha I hadn't thought of. I'll have to keep my eyes open for that one. Thanks for the tip.
-

Right-click on LVOOP object wire to Insert Class Methods
Daklu replied to Jim Kring's topic in Object-Oriented Programming
Maybe you talked to too many people. In the future you should just talk to us. Yep, you talked to too many people. Good music never comes from having too many fingers on your fiddle. Designing a UI that gives a good user experience is hard. As engineers we tend to prefer things with lots of options that we can customize. UI designers like to design interfaces "right" so they don't need to be customized. A good UI designer understands his target audience and the kinds of tasks they will want to do. Including a customizable option means they couldn't design that part of the UI correctly. (Though there may be perfectly valid reasons for it.) I resisted this idea for a long time. I figured having a default UI for basic users with lots of customizable options for advanced users would make everyone happy. The problem is that implementing n additional options requires 2^n effort and most users will use only a small part of the functionality. You can eliminate a lot of unnecessary coding with a proper UI design. Sometimes there is no "right" or "wrong" way to do it and you just have to make a decision. Users generally adapt pretty quickly even if it's not the way they would have preferred it. I don't blame you. I'm curious... where did you get all this feedback from? It sounds like the kind of requests you'd get from a public posting on the NI forums or (*gasp*) even here. Doesn't NI have usability teams to provide developers with guidance on how features should behave in the IDE? -
I get no visual difference between OnePixelBorder and TopLeftBorder. Functional difference is the TopLeftBorder cluster is harder to select--I have to go to the top or left border to do so since there is no bottom or right border.
-
Kurt, I noticed an unusual upcast to a non-default Labview Object. Why do you do that?
-
[CR] Improved LV 2009 icon editor
Daklu replied to PJM_labview's topic in Code Repository (Certified)
Bug: Show Terminals checkbox does not update. If I use Ctl-T or the Edit menu to show/hide the terminals, the checkbox under the canvas does not get updated. Clicking the checkbox still toggles the terminal view so it ends up being out of synch. ------------------------- UI Suggestions: -On the Layers tab the control box is centered in the pane with lots of whitespace around it. You could fit at least one more layer in there, maybe two. Less scrolling = better. -On the Layers tab move the active controls to the left side of the tab. Most of the user's mousing will be on the left side of the editor. It pays to not make them move the mouse long distances. ------------------------- Functionality Suggestions: -Hotkeys to switch between tools? (Bonus points for user-definable hotkeys!) -Lockable user layers? -
I tried that. I mocked up a Baby class and a CellPhone class, both of which inherited from my Interfaceable class. Babies sleep and cell phones sleep, so I implemented an ISleepable class (which derived from my Interface class) to provide an alternate access point to their sleeping methods. Then I built ISleepableBaby and ISleepableCellPhone classes which implemented the interfaces for each class. Converting the main object (Baby & CellPhone) into their ISleepable counterparts is no problem. Converting them back into their main objects is a problem. Since the conversion method needs to be a member of the Interfaceable class it will an Interfaceable object, which then needs to be downcast by the interface user. I didn't like that--I'd rather put more responsibility on the interface developer in return for something that is easier for the user. The other issue is that method restricts users to only having access to a single interface at time. Since classes can implement many different interfaces I didn't want to force users to go through a conversion every time they need to switch interfaces. These are the main design goals I have been working towards with my Interface framework, roughly in priority order: Allow many-to-many relationships. A class can implement many different Interfaces, and an Interface can be implemented by many different classes. Maintain conceptual continuity with Interfaces in text-based languages. (To avoid "polymorphism" confusion.) Push the complexity as far upstream as possible. There are two kinds of users: Interface users and Interface developers. Neither should be burdened with building repetitive framework code. Converting existing classes into Interfaceable classes should be easy. Keep the framework lightweight and transparent. This is a redistributable code library, not a product. Minimize dependencies on other packages. Some of these I've been able to meet with my code; some still need to be worked on. I'll try to get my code posted later today.
-
I've never tried this. How does it fail? Does it just not dispatch to the correct child class VI? Probably nothing in terms of functionality. In text languages using Interfaces is a lot like using classes and objects. Wrapping your Interface methods in a class would help give the user a consistent experience. Yeah, except for that tiny little issue about it relying on a particular feature that cannot exist in a dataflow language. However, I did redesign it around by ref objects and last night I got it working correctly. I'll try to get it posted soon but it is more complicated than my previous design so I should probably put together some documentation for it. I've been poking around with Interfaces off-and-on for about a year now. I could write a book on what doesn't work! I'm glad I've spent the time doing it though... I've learned a lot of things that I wouldn't have encountered in job-related stuff.
-
Your implementation really deserves its own thread. Not because I'm worried about hijacking this thread (I think has run its course) but to make it easier to find. I like the way you've solved the problem of calling similar methods from unrelated classes. That is an approach I had not considered. I think I like that you don't have to obtain the interface before using it. On the other hand I think the reliance on strings and the CBR node will make maintenance more difficult in the long run. What you have doesn't quite present the user with traditional Interfaces, though it wouldn't be hard to wrap your interface in a class to give it a more standardized feel.
-
Having only used imperitive languages other I still struggle to understand other programming paradigms. I've always envisioned the dataflow "magic" as being a function of the compiler. In other words, I expected compiled dataflow programs to be structured much the same way compiled imperitive programs are. The Wikipedia entry for Dataflow programming describes a very different structure: Once I understood that the other pieces started falling in to place. Question for you: If I have a VI with independent parallel operations the execution order is indeterminate. Assuming compiled Labview programs use some sort of list scanning described above, does it follow that although I cannot predict which order each operation is executed the order will be the same each time the program is executed? [Edit: Is "terminal" the correct term to use when referring to something that can hold data? I've generally though of terminals only as controls or indicators that are on the conpane. Although constants and controls that are not on the vi conpane could be viewed as sub vis with their own conpanes...]
-
In my experience the terms "reference" and "pointer" are often used interchangably. How are you differentiating the terms? They both essentially do the same thing--they refer to a location in memory that contains either the data of interest or the next memory location in the chain. Having parallel wires refer to the same piece of memory is done all the time with refnums, be it named queues, events, fp controls, etc, so it's obviously possible. Branching a DVR results in two parallel wires referring to the same piece of memory. Is this a limitation of dataflow languages in general or specific to Labview's implementation. Obviously there are still aspects of dataflow I don't fully understand. Data on the parallel by-value wire has to exist somewhere in memory. It don't get why a pointer to that memory location would not be meaningful. It would violate the principle of data flow, but there are lots of things within Labview that do that already. --------- Many Hours Later ----------- I had to look at this for a long time. When I first read it I envisioned all sorts of weird schemes under the hood that used the upstream prim to modify a value after it has been sent downstream. Here's a summary of the conversation I had with your alter-ego, Evil AQ (pronounced "evil-ack"), in my head. Evil AQ explained a lot of things to me, but I question his accuracy... you know, what with him being a figment of my imagination and all. (Note: My conversations with Evil AQ tend to be rather caustic.) Me: "Huh? The prim that created the value is what actually performs operations on the value downstream? That implies that rather than the data being passed around between prims, the data remains with the orignating prim and downstream prims are passed to it. How... odd. That seems kind of like functional programming. I thought you used C++ under the hood." Evil AQ: "No you dolt. That wasn't a comment about perpetually persistent primitives. Look, when have you ever seen a value on a wire change? Me: "I see it all the time. Wire an integer through an increment function inside a while loop. The value on the wire changes with each iteration." EAQ: "Let me rephrase... when have you ever seen a value on a wire change without that section of code executing again? Me: "Well, the value on the wire has changed after going through the increment node." EAQ: "Uh uh. That's a different wire. Another rephrase... when have you ever seen a value on any single wire, defined as all branches starting at the source terminal and ending at each destination terminal, change without that section of code executing again? Me: "Never. Duh." EAQ: "It's good to know you're not a complete maroon. This would be tougher to explain if I were restricted to finger paints and monosyllabic words." Me: "Monobillasic... monosymbolic... monosy... what?" EAQ: "Never mind. What would happen if you had a raw pointer to a value on a wire?" Me: "I could have Interfaces!" EAQ: "Slow down there Flash. Think about this for a minute. What would happen to the value on the wire?" Me: "Ohhhh... it would change." EAQ: "Very good. You pumping a full 100 Watts through that brain or is your dimmer switch turned up a little too high?" Me: "What about control refnums? They change values." EAQ: "There's a reason they're called 'control' refnums. They refer to controls, not wires. Control values can change. Wire values cannot." Me: "Oh. Right. Well queues can change the values of items that exist somewhere in memory. What about them?" EAQ: "Yes, but they are changing the value of an item the queue refnum refers to. They are not changing the value of the queue refnum itself, which is what actually exists on the wire." Me: "I see. But in reality by-val wires don't contain the data itself, do they? If they did memory allocations would take place at the moment the wire branches and I've know that's not right." EAQ: "Correct, wires do not contain the actual data." Me: "It actually refers to data that resides elsewhere in memory, right?" EAQ: "Sort of correct. Wires don't refer to a piece of data so much as they refer to a specific terminal on VIs and primitives. A terminal** is essentially something that can define the values of a piece of data, such as a control, indicator, constant, etc. and includes input and output terminals to prims." (**Evil AQ didn't know the correct terminology for this so he used the word 'terminal.' Luckily I knew what he meant.) Me: "So shouldn't it be possible to create a refnum that simply refers to the same memory location that a wire does? Ha!" EAQ: "Well yes, but it won't work in the way you're thinking. Try looking at it this way... by val data exists only in terminals. Wires are simply a graphical representation of how the terminals are mapped to each other. Ostensibly every time data "flows" across a wire a data copy is made and placed in the memory location that represents the destination terminal. While in principle you could have a refnum that refers to the same data the wire 'refers' to, effectively it would be just like a value property node for one of the terminals. (It doesn't matter which one, since they all contain the same data values.) That scheme would consume LOTS of memory, so the Labview compiler is smart enough reuse memory when it can. For example, since all the terminals a wire connects to must contain the same data values after executing, the memory locations that are represented by the terminals are actually pointers that refer to a single piece of data. Sometimes the memory location of that data can be reused by other terminals further downstream. Sometimes it can't. Ironically, obtaining a reference to that memory location is one way to guarantee it can not be reused." Me: "Really?" EAQ: "Well yeah. You're referencing the value in the terminal, which doesn't change until that section of code executes again. If downstream operations change the value a new copy must be made to avoid corrupting the old copy, which you have a reference to." Me: "I get it now. Thanks Evil AQ. You're the greatest." EAQ: "You sound like my mother. Now beat it punk, I'm trying to sleep." So did Evil AQ do a decent job of explaining things to me?
-
Thanks for the encouragement. For what it's worth I'm fairly confident Interfaces are on the roadmap somewhere. On another thread when I mentioned I'd really like Interfaces AQ responded with something along the lines of "not enough time has passed for that to be implemented." However, given the poor showing for Interfaces in the Idea Exchange and comments in The Decisions Behind the Design, I suspect they're much farther down the road than I would like. Here's what's really puzzling about the whole thing: How did I manage to go two months without realizing that?
-
I know I'm way behind the rest of you on using DVRs, but today my quest for the Holy Grail (also known as Interfaces) hit another stumbling block. So all this time I've been playing around with DVRs I've been working under the assumption that the New Data Value Reference prim simply created a pointer to the object wired to its input. Based on some testing I did today it looks like the prim wraps the entire object in a DVR. The end result is that an object can be either By Ref or By Val, but apparently there is no way to have a reference to a By Val object that exists on the block diagram. For example, operations such as this will always create a copy of the object. Since the New DVR prim doesn't output an object is it really impossible to have a 'pointer' to an object? (Suddenly all the discussion about containing private data in a DVR makes much more sense.) [Rants follow... pay no attention to them. They are a result of my momentary frustration.] I was *this* close to having an easy-to-use Interface framework that would have worked with By Val objects and avoided the need to wrap the class data in a DVR. (I hate having to use initializer VIs just to get an object to work correctly.) I assume it was designed this way to try to prevent race conditions. I understand the reasoning but I still get frustrated by a development environment that at times seems unable to decide how much it supports references. Labview is kind of in a middle ground where it doesn't quite follow the pure "everything is data" idea but also doesn't fully support references, leaving it difficult to work with either. [/Rant] Back to the drawing board. I've been resisting the DVR data wrapping but it looks like I'll need to go that route. It's unfortunate--converting a class to implement Interfaces is more complicated if DVR data wrapping is required vs the method I had envisioned. [Edit Aug 2, 2010: Early non-working versions removed. Get released version here.]
-
I've looked for installation path information to use in my post-install/pre-uninstall scripts too, with pretty much the same result. I did find one avenue that showed some potential, but time constraints have prevented me from investigating it deeply. When VIPM installs/uninstalls a package it saves the package configuration file in the temp directory. It should be possible to read the configuration file from the temp directory and extract whatever information you need. Let me know what you find out.
-
I like this idea much better than using green wires. Color is one of the main ways I distinguish between groups of related classes.
-
Estimating Software Size - Can We Still Do It?
Daklu replied to Phillip Brooks's topic in Object-Oriented Programming
No. 365 only takes you to the end of the first year. You need 366 to celebrate your Lavaversary. BUT, since you joined during a leap year you need 367. -
I agree with everything you said, but this last paragraph highlights why I now avoid deep inheritance trees. We have an internal hierarchy that includes classes for various instruments, products that need to be tested, protocols, etc. The intent is to use this api as the foundation for all our test tools. If we come across a new requirement the api doesn't support, we *can't* change the outer layer without breaking other applications. So we either have to fork the api for that application (which we have done) or implement hacks (which we have also done.) As you say, there is no "right" answer. It's just a matter of picking your poison. I actually like Star UML better than Visio. Plus it's free. I finally had a chance to look at the Bike/Racer implementation this morning. That looks like a very good way to create by ref class hierarchies. I'll have to play with it more to see how it fits into my use case. (Which means I'll have to remember what my use case was... )
-
I agree with 'check in early, check in often,' but merging often (every day or so) kind of defeats the purpose of branching in the first place doesn't it? If you're going to merge every change back into the trunk why not just do the dev work on the trunk? Yikes! I understand why it's unsolvable, but still... yikes! In the case of simply adding or removing VIs from the library it's possible to do a text merge on the .lvclass file, but frankly doing that worries me. I'm never confident that I'm not accidentally breaking something in one of those flattened data fields. I would hope for the Merge and Compare tools to be expanded to include library files, but sadly that idea wallows at only 9 kudos while the fluffier ideas get all the attention. (I'm not saying that the top ideas aren't useful -- they are -- but they tend to focus on making existing functionality slightly easier to use instead of adding functionality to address difficult problems.) --------------------------------- We've been following the 'Branch per Component' pattern for our current project, a test sequencer. (Don't ask.) We try to keep the trunk stable and working so our internal customers have a single place they can retrieve the latest working code. Our process for developing a new test case roughly follows these steps. Some of these steps may be unique to TFS; I don't have much experience with other scc systems: Create a branch for the new test case and check the branch in. (This check in is an exact copy of the trunk but having this in the branch makes it easy to find the base version when doing 3-way merges.) Add code for the new test case. When changes are checked into the trunk, forward integrate them into the branch. When the new test case code is complete, do a final forward integration from the trunk to ensure all the latest changes are included. Assuming everything works, reverse integrate the branch into the trunk. Now, since merging classes 3-ways appears to be unworkable, any time a developer edits a class in a branch, if that class also exists in the trunk he should apply a lock to the class in the trunk preventing other developers from checking it out. Once those edits are done the developer can check the changes into his branch, merge the class back into the trunk, and remove the lock. All the other developers then need to make sure they get the latest version of that class. This seems like a very error-prone way to handle the inability to do 3-way class merges. Any mistake that allows two developers to make changes to the same source code is going to result in lots of wasted time while one of them to rewrites their code against the other's changes. (Which, coincidentally, is where I find myself right now.) It makes me wonder if the branch-modify-merge pattern is the best one for us to use. Unfortunately the other patterns have issues of their own. I'll have to think on this for a while.
-
This is exactly why I love LAVA. I can voice an opinion and have more experienced developers (or the lead R&D developer in charge of LVOOP!) challenge my ideas. I'm writing this response with the intent of explaining how I came to the conclusion that deep trees are bad, not as an attempt to teach you (as if!) the finer points of OO programming. I'm more than happy to be shown the error of my ways. I'll also note that a "class heirarchy" implies, in my mind, inheritance relationships. First, I think there are subtle differences between "malleable" and "extensible." Both refer to ways of altering functionality; however, extensible code adds functionality through 'bolt-on' additions while malleable code adds functionality by changing the way the objects are organized. As a metaphor, image the code is represented by marbles in the shape of a triangle on a chinese checkers board. Extensible code allows changing the triangle into a circle by adding marbles to it. Malleable code allows changing the triangle into a circle by moving the marbles that are already there. In my opinion, deep class hierarchies may be highly extensible, but they are rarely malleable. My opinion is based partly on my experiences and partly what I've learned from OOP literature. One of the first lessons I learned when I started "seriously" studying OO design was to favor composition over inheritance. Various books and websites have pointed out that inheritance relationships are fairly tightly coupled. Creating a long inheritance chain causes dependencies that are not easily changed later, especially when there is existing code that depends on that chain. Learning that, I realized why the class hierarchies I've worked with have ultimately fallen short of what we needed them to do. In the past several years I've worked with two fairly deep framework class hierarchies and neither ended up being able to properly support the functionality we needed without completely redesigning the tree. Undoubtedly some of the problem was due to our inexperience with OO design. However, looking back on it now I still do not see inheritance providing a good solution to the problems we faced. Our hierarchies, like kugr's, were based on hardware devices, so when he says one branch of his "deep class hierarchy" is devoted to "motors, actuators, sensors, [and] analog outputs," the warning bells start ringing. If this branch is based primarily on inheritance he may end up in exactly the same situation I did. Having been burned twice by deep inheritance trees, my design philosophy now leans heavily the other way. Instead of trying to fit hardware devices with different capabilities onto the same inheritance tree, now I look to have several short and small inheritance trees. Many small trees gives me malleability. Extensibility tends to be achieved by creating an abstract facade and creating child classes that are composed of the parts of the smaller trees that I need.
-
At work we are using TFS and follow the branch, modify, merge pattern for code development. This can cause all sorts of problems when code collisions occur in classes or project libraries, such as what might happen when multiple developers change the class .ctl or library VIs are added or removed. What process steps do you go through when resolving conflicts like this to avoid broken projects?
-
The short answer is no. I don't quite understand exactly what changes you made. If you can post images of your code it would help me understand your implementation. (My LV'09 trial license expired and I haven't got a home license from work yet.) Danger, Will Robinson! Deep inheritance hierarchies aren't very malleable and you may find yourself unable to accomodate future changes. Or worse, you could end up hacking in modifications and ending up with very brittle code. Can you post a diagram of your object model?
-
Rolf comes closest to what I've been able to discover. This is a .Net limitation, not necessarily a Labview limitation. This is part of the problem. If the assembly isn't in the GAC, .Net looks in the directory of the executable that is requesting the assembly. In the dev environment that's Labview.exe. I'm not too keen on loading up that directory with assemblies. Looks like the GAC is the only reasonable way to go.
-
No, I don't think so. I had never even looked at Java code before buying this book, so I just considered it pseudocode. I wouldn't worry too much about the syntactical details in the book; Labview's version of OOP is different enough that no text language implementation translates directly into Labview.