Leaderboard


Popular Content
Showing content with the highest reputation on 11/12/2010 in all areas
-
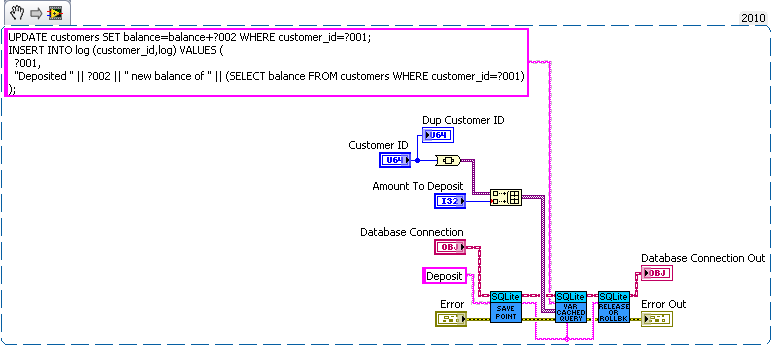
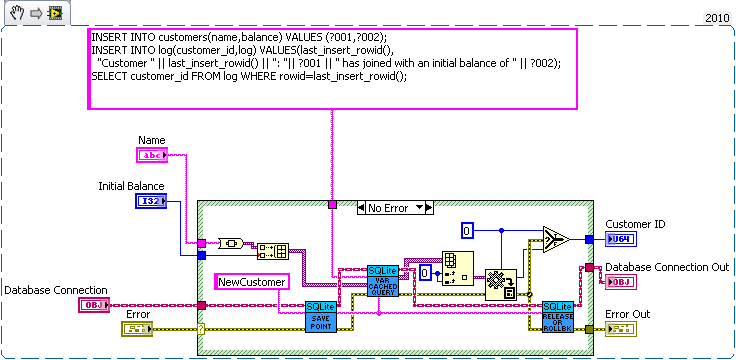
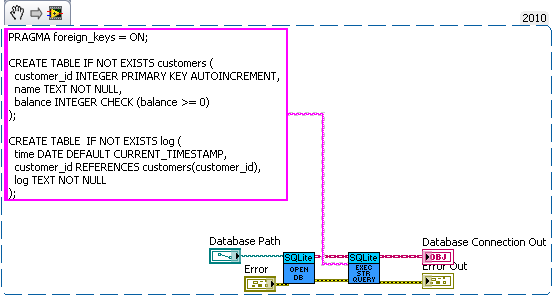
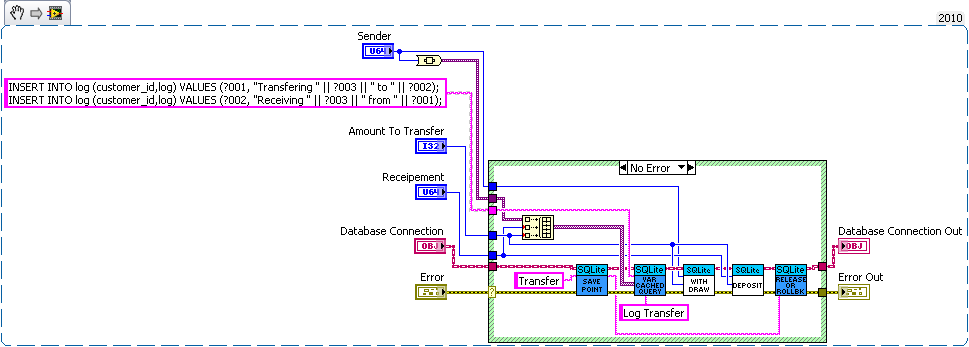
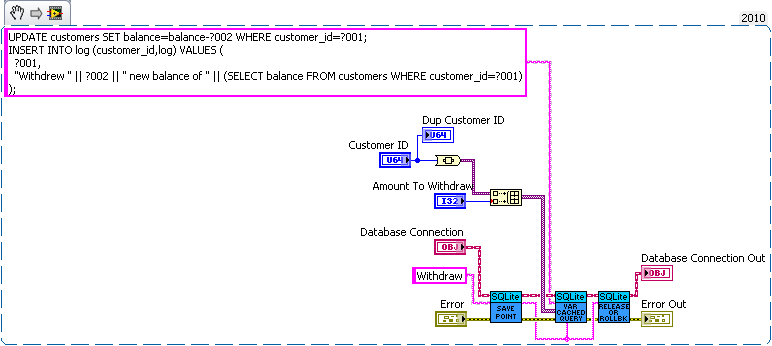
I think the problem is that journal only maintains consistency (well not quite) on a single file while sqlite needs two files to be consistent with each other. Without syncing (which acts as a write barrier) the data may be written to the database before modifying sqlites journal. Now the OSes journal can be protected from that (since the OS can control the write buffer) but SQLite doesn't have such a protection. I'm curious how SQLite would perform if it used Transactional NTFS instead of syncs and an on disk journal. That would be doable but the tricky part would be determining which is corrupt. The easy solution of storing the check sum of the database in another file suffers from the same out of ordering you can get without fsyncing (ie both databases are modified before the check sum is actually written to the disk). I'm unsure if pragma intergrity_check can catch all problems. I check that the number of input values is equal to the largest number of parameters used by a single statement. So all binding's must be overwritten in my API. The single question mark is confusing for multistatement queries. I could make an interface for named parameters (the low level part of my api exposes the functions if the user really wanted to use them). But I decided against it since I didn't think the lose in performance was worth the the extra dll calls and variable lookups. But named variable may be faster in some corner cases since my code will bind parameters that aren't used, but it's easy to minimize the impact of that (by optimizing the order of the parameters). I just see composability to be a key feature of database interaction. You'll probably want logging to be synced at least (a log of crash isn't useful use if the important piece never reaches the disk). How about a bank example. Lets say you're writing a database for a bank. So we need a table for bank customers and how much money they have, and a second table for logging all the interactions on different accounts (so we can make bank statements). The following code is just hacked together for example so there likely are bugs in it. We have three sub vis for our API, create customer, withdrawal and deposit. Now withdrawal subtracts money from the account and logs the withdrawal, and deposit does the same but increases the amount instead of decreasing. We want to make sure the logs match the amounts so we'll wrap all the changes in savepoints. But this say we want to add a transfer subvi. Since we used savepoints we can safely implement in with the withdraw and deposit subvis we previous added (saving us code duplication). As for why this is useful consider what happens if I need to change the withdraw (maybe take cash from a credit account if it goes below 0 instead). Or I want the ability to lock an account (so no changes in balance). What happens if there are multiple connections to the database. If I wasn't in a transaction in the transfer the receipt account could be locked before the money is deposited which would error then I'd have to write code to undo my withdraw (now what do I do if that account get's locked before I can deposit it back). If I wanted to setup a automatic bill pay I could use the transfer vi in an automated billpay vi. In short savepoints allow for programmer to avoid code duplication by allowing composability of transactions.
 2 points
2 points -
The journal (either SQlites or the File systems) is always written to before any updates to the actual file(s) and the transaction is removed after the completion of that operation. In the event that something goes wrong. The journal is "replayed" on restart, therefore any transactions (or partial transactions) still persisting will be completed when the system recovers. The highest risk area is that a transaction is written to the DB but not removed from the journal (since if it exists in the journal it is assumed to be not actioned). In this case, when it is "replayed" it will either succeed (it never completed) or fail silently (it completed but never updated the journal). This is the whole point behind journalling. In this respect, the SQLite DB is only dependent on the SQLite journal for integrity. The OS will ensure the integrity of SQLites journal. And SQLite "should" ensure the integrity of the DB. However. If the file system does not support journalling. then you are in a whole world of hurt if there is a power failure (you cannot guarantee the journal is not corrupt and if it is, this may also corrupt the DB when it is "replayed"). Then it is essential that SQLite ensures every transaction is written atomically. It ( intergrity_check) would be pretty useless if it didn't. I think it is fairly comprehensive (much more so than just a crc) since it will return the page, cell and reference that is corrupted. What you do with his info though is very unclear. I would quite happily use it. I could not detect any difference in performance between any of the varieties.There are no extra DLL calls (you just use the different syntax) or lookups (its all handled internally) and, as I said previously, it is persistent (like triggers). Therefore you don't need to ensure that you clear the bindings and you don't have to manage the number of bindings. It's really quite sweet In my high level API, I now link to variable name to the column name (since the column name(s) must be specified). I think here you are talking about an application crash rather than a disk crash. If the disk crashes (or the power disappears), its fairly obvious what when and why it happened. For an application crash, the fsync (flushfilebuffers?) is irrelevant. Excellent example. The more I think about this. The more I think it is really for power users. My API doesn't prevent you (the user) from using save-points with the low level functions, after all it's just a SQL statement before and after (like begin and end). However. It does require quite a bit of thought about the nesting since a "rollback To" in an inner statement will cancel intervening savepoints so you can go up, down and jump around the savepoint stack. In terms of bringing this out into the high level APIs. I think it wouldn't be very intuitive and would essentially end up being like the "BEGIN..COMMIT" without the flexibility and true power of savepoints. Maybe a better way forward would be to provide an "Example" of savepoints using the low level functions.1 point