Leaderboard




Popular Content
Showing content with the highest reputation on 09/12/2014 in all areas
-
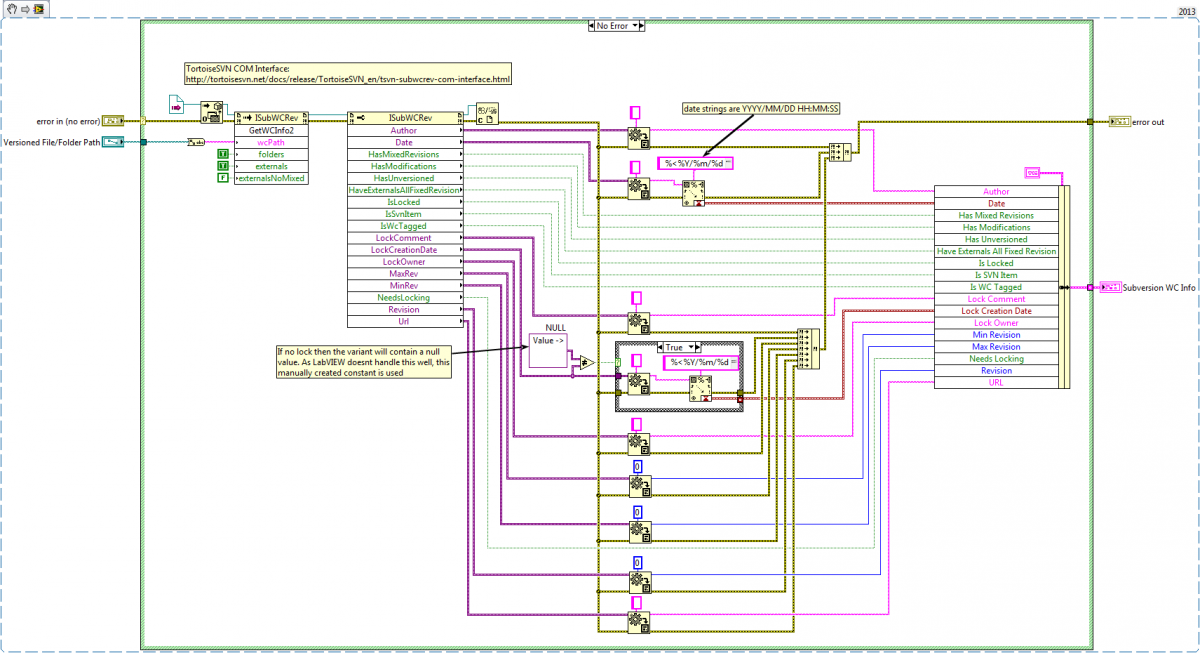
Alternatively, if you dont have the command line tools installed (or don't want to use them ), you cou could use TortoiseSVN's COM interface (http://tortoisesvn.net/docs/release/TortoiseSVN_en/tsvn-subwcrev-com-interface.html)
 2 points
2 points -
Unwrap Phase VI1 point
-
Thank you for the link. It seems I already have the most efficient way according to this document, since I never separate channels in several write operations. I tried the defragmentation, but I found that it takes a very long time (like 3 minutes) and doesn't improve the read operation's performance enough to make it worth. I also modified my test VI to measure the time more accurately and added extra cases so please take version 2. I start being able to pinpoint where the optimizations I need might be by analyzing the attached table I populated from my tests. Reservation: Comparing 3&6 (or 3&9), we see that reserving the file size makes a huge difference for the Write operation when the file is going to be written often. It makes sense since LabVIEW doesn't need to keep requesting a new space to be allocated on the hard drive. It also optimizes the read operation (less fragmentation since the file size is reserved). However if we compare 6&9 (or 4&7, or 5&8), it appears that reserving the full size is better for the read (again, less fragmentation I suppose) but significantly worse for the write, which I don't understand. Reserving only N samples instead of N*M gives better results for the writes. Writing in blocs: Comparing 5&6, we see that - not surprisingly - writing less often but with more data is more efficient for the writing time. However since the file was fully reserved, there is no difference on the read time! Comparing 8&9, this time both the write and the read are optimized when writing less often, since this time the file was not fully reserved, so more writes led to more fragmentation. Data layout: Comparing 4&5 (or 7&8), we see that the data layout doesn't have an influence on the write operation, but the decimated layout significantly improves the read operation since all samples for only one channel are requested. I would expect the interleaved layout to be more efficient if I was requesting only one or a few samples but for all channels. I didn't test that since it is not the scenario that my application will run. Additional note: Tests 1&2 shows the results one gets when writing all data with a single write operation. Case 1 leads to a super optimized reading time of 12ms, but the write time is surprisingly bad compared to case 2, I don't understand why so far. Those 2 scenarios are irrelevant anyway since my application will definitely have to write periodically in the file. I would conclude that for my particular scenario, reserving the file size, grouping the write operations, and using the decimated layout is the way to go. I still need to define: - The size of the write blocs (N/B) - The size of the reservation, since reserving the whole file leads to bad write performance. Test TDMS v2.vi
1 point
-
One of these days (I have said this before) I will dust off my XNode Wizard. It automates a basic set of common tasks and makes it easy to create a certain class of XNodes: Growable nodes, dropping template code and mapping the terminals from the template to the XNode, and drawing the image. My own experience is that with the limited set of features I have managed to reverse engineer, they are stable, yet you can still write a broad spectrum of useful nodes, especially since a vast majority of the time you want a subVI with something resembling the type adaptation of primitives without writing hundreds of polymorphic instances. The fact that XNodes ship with LV (ie. Match Regular expression) means that stable objects can be created. Express VIs are using very similar if not the exact same framework. I can corrupt a VI with scripting, with Write to File, or even setting the current values to default. And just because I can wreak havoc with my reciprocating saw does not change the fact it is my favorite tool in my garage. With great power comes great responsibility. I do wish that someday I could package XNodes in Packed Project Libraries, they are made for each other. A single package containing one useful top-level object and a bunch of specialized subVIs that are best kept private. In the meantime, besides the existing resources on LAVA I would check out the following: http://forums.ni.com...ode/m-p/1293680 (a cool, simple XNode example. Shows handling clicks, type adaptation, and updating the image) https://decibel.ni.c.../docs/DOC-15362 (a bit of a play, shows a few more abilities and techniques) Attachment: This is a picture constant which allows drag and drop of common image types (JPEG, PNG). You can place this constant on the BD and then drag and drop an image file to get a constant picture. When you are finished, you can right-click and replace the XNode with a simple picture constant (this avoids the need to distribute the XNode with your VI). I like it as a quick way to get a picture constant without the usual method of read file, draw to picture indicator, create constant, copy, paste. Simply extract the folder and drag the .xnode file to your BD. XNodes can be added to your palettes, just remember to choose the 'All Files' filter when browsing for the .xnode file. enjoy! PictureConstant.zip1 point