Leaderboard



Popular Content
Showing content with the highest reputation on 08/17/2015 in all areas
-
What? Been there since pre-8.2? Who's been laughing at us flailing around with locked-down multi-VI XNodes (or multi-multi-VI polymorphics) for years? This seems to answer 99% of my (and everyone elses) requests for a simple type-adapting VI. Looks like a very simple XNode without any type-checking (e.g. wire a Boolean to the Delay input and it generates the code but breaks the calling VI). But if the programmer can be trusted, it looks incredibly useful. I would presume it has the same caveats as using an XNode, but if it's now "released" (thanks jkodosky, who I imagine has some mandate to do so) it would be good to know anything to be aware of. BTW, this is certainly not the same as the buggy, non-supported Generic VI that was dangled in front of us some time ago.1 point
-
Short answer is no. you can't easily modify dependency locations. Longer answer is yes. you can modify environment search paths to point to the new target and delete the old target files to force re-linking, but this is really the hard way and it's going to get you into re-linking trouble/hell. Correct answer is that you're not using vi packages correctly. The code that goes into a VI package should be able to stand on its own. You should be able to debug/test/validate all VI package source code before you build it into a package. Think of a VI package as formally released reusable source code. If you feel the need to constantly switch between built packages and source code, then you're not adequately validating/testing before building the package. Hope this helps.1 point
-
Well, lots of questions and some assumptions. I created the cdf files for the OpenG ZIP library by hand from looking at other cdf files. Basically if you want to do something similar you could take the files from the OpenG ZIP library, change the GUID to some self generated GUID in there. This is the identifier for your package and needs to be unique, so you can not use that of another package or you mess up your software installation for your toolkit. Also change the package name in each of the files and the actual name of your .so file. When you interactively deploy a VI to the target that references your shared library through a Call Library Node and the shared library is not present or properly installed then you will get an according message in the deployment error message with the name of the missing shared library and/or symbol. If you have some component that does reference a shared library through dlopen()/dlsym yourself then LabVIEW can not know that this won't work as the dlopen() call will fail at runtime and not at deployment time and therefore you will only get informed if you implement your own error handling around dlopen(). But generally why use dlopen() since the Call Library Node basically uses dlopen()/dlsym() itself to load the shared library. Basically if you reference other shared libraries explicitedly by using dlopen()/dlsym() in a shared library you will have to implement your own error handling around that. If you implicitedly let the shared library reference symbols that should be provided by other shared libraries then the loading of your shared library will fail when those references can't be resolved. The error message in the deplyoment dialog will tell you that the shared library that was referenced by the Call Library Node failed to load, but not that it failed because some secondary dependency couldn't be resolved. This is not really different with Windows where you can either reference other DLLs by linking your shared library with an import library or do the referencing yourself by explicitedly calling LoadLibrary()/GetProcAdress(). The only difference between Windows and elf is in the fact that on Windows you can not create a shared library that has unresolved symbols. If you want the shared library to implicitedly link to another shared library you have to link your shared library with an import library that resolves all symbols. On elf the linker simply assumes that any missing symbols will be resolved at load time somehow. That's why on Windows you need to link with labviewv.lib if you reference LabVIEW manager functions but with labviewv.lib being actually a specially crafted import library as it uses delay load rather than normal load. That means a symbol will only be resolved to the actual LabVIEW runtime library function when first used, not when your shared library is loaded, but delay load import libraries are a pretty special thing under Windows and there are no simple point and click tools in Visual Studio to create them. Please note that while I have repeatedly said here that elf shared libraries are similar to Windows DLLs in these aspects, there are indeed quite some semantic differences, so please don't go around quoting me as having said they are the same. Versioning of elf shared libraries is theoretically a useful feature but in practice not trivial since there are many library developers who have their own ideas about versioning of their shared libraries. Also it is not an inherent feature of elf shared libraries but rather based on naming conventions of the resulting shared library which then is resolved through extra symlinks that create file references for the so name only and a so name with major version number. Theory is that the shared library itself uses a so.major.minor version suffix and applications link generally to the .so.major symlink name. And anytime there is a binary incompatible interface change, the major version should be incremented. But while this is a nice theory quite a few developers only follow that idea somewhat or not at all. In addition I did have trouble to get the shared library recognized by ldconf on the NI Linux RT targets if I didn't create the .so name without any version information. Not sure why on normal Linux systems that doesn't seem to be an issue, but that could also be a difference caused by different kernel versions. I tend to use an older Ubuntu version for Desktop Linux development which also has an older kernel than what NI Linux RT is using.1 point
-
I've never really given it much thought. UI in LabVIEW is generally atrocious - just look at the enum editor. I don't think its any worse than others, but that probably isn't saying much. I still get caught out by not being able to right click copy and paste into controls That's a big claim there. Take your favourite action engine and make an xnode to replace it. Tell me how many days it took Having looked at this a bit now, I think my Data Aware controls need to be Xcontrols (just as hard as Xnodes, but with an extra dollop of flakey) They really need the facade. I already have some (as Xcontrols) but I'm not going to release because I would have to replicate all the right click menu options manually in the code. That is just too much of an ask for something like a Treeview and pretty much rules them out for 90% of where I would want to use them. I think anywhere that needs a custom UI that does not need to inherit an existing control or function is a good use case for an Xcontrol or Xnode so we could probably agree that they could replace Express VIs. Does an express VI automagically make its diagram representation? That would be a nightmare creating the node look and operation from scratch. I haven't looked or even used them ,really, but I suspect they are the same technology too underneath. It all seems to be just different cheeks of the same face The same underlying technology with specific, in built, interfaces to make certain desirable features easier fro muggles like me. I like that approach. That's how I try to design my APIs. They may be complicated under the hood, but should be intuitive and easy to use. Raw Xnodes aren't intuitive or easy Xnodes are the potters wheel when all I want is a crappy ashtray to put my cigarette out. But VIMs and polys are super easy. They are the blue tack and scotch tape when I want to put my posters on the wall. They enhance my productivity which would plummet if they were to go or be replaced with Xnodes. <shivers> Don;t say things like that.1 point
-
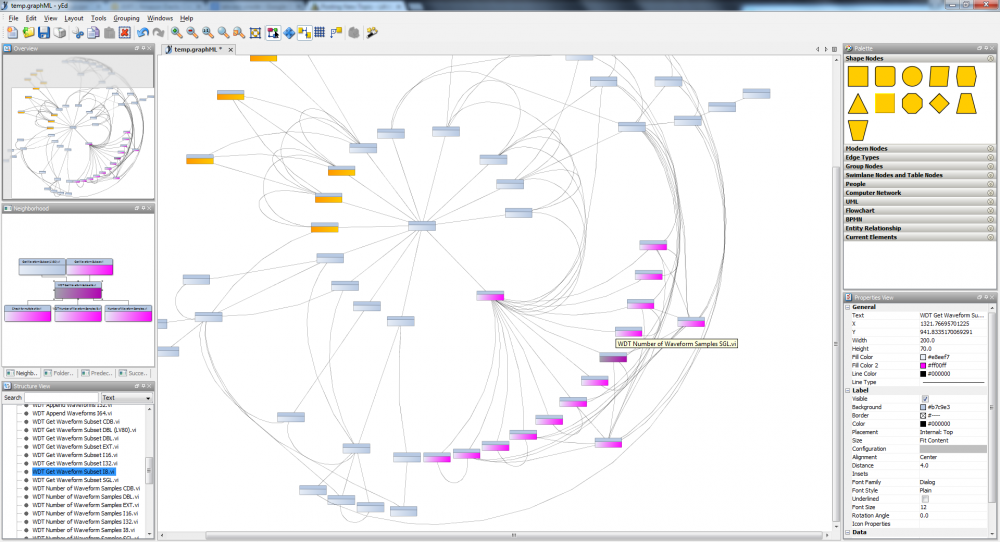
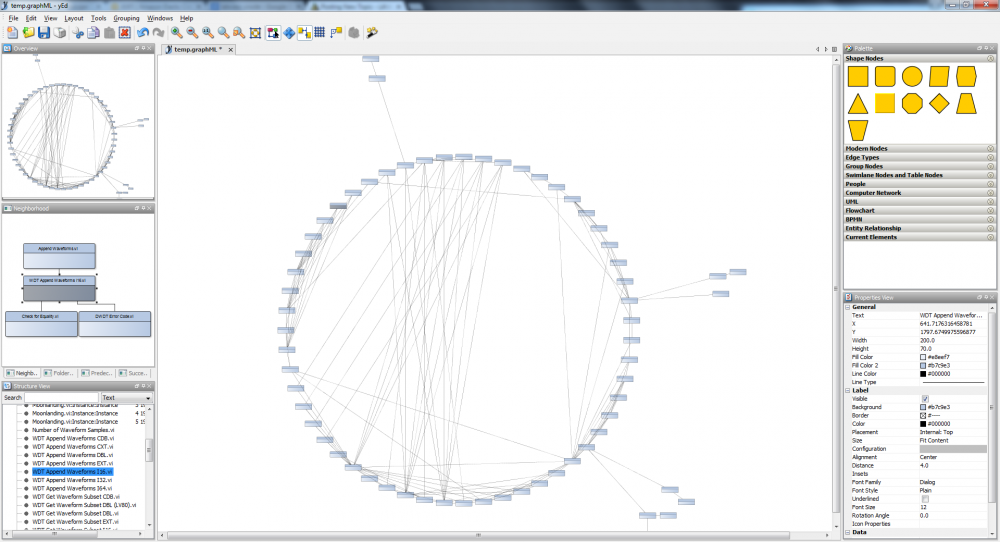
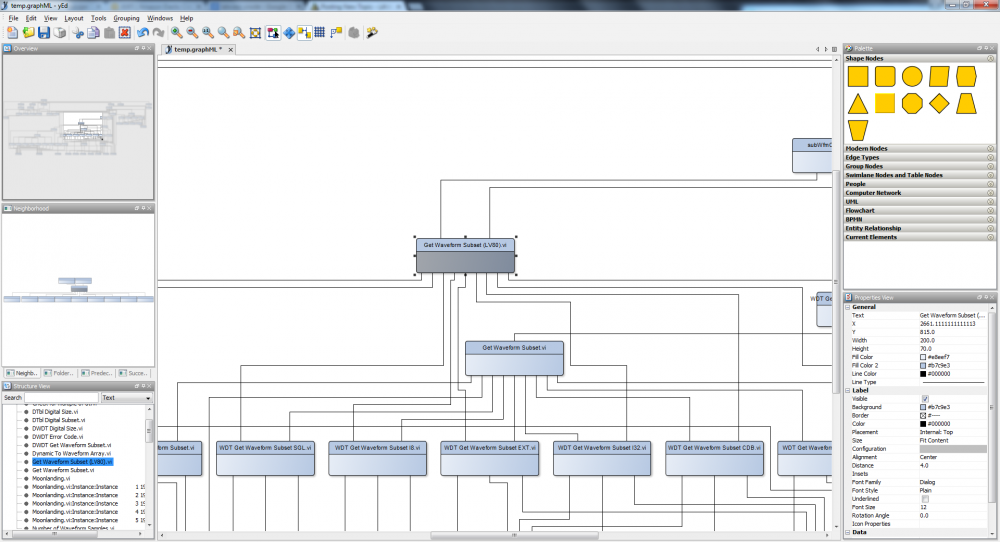
Hello, I have been playing around with Hierarchy analysis and yEd graph editor with some interesting results. I believe graphML could become a very nice API to document VI hierarchies especially when coupled with yEd and its web interface tools etc. Here is the hierarchy analysis of the moon landing NI example. You can switch graph types at the click of a button, filter / colour different elements by type etc, select partial neighbours of the hierarchy ... the possibilites go on. graphML is XML based so is pretty easy to do. Craig
 1 point
1 point -
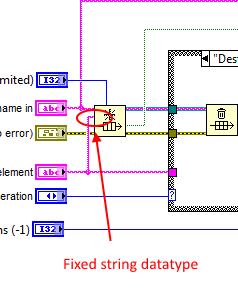
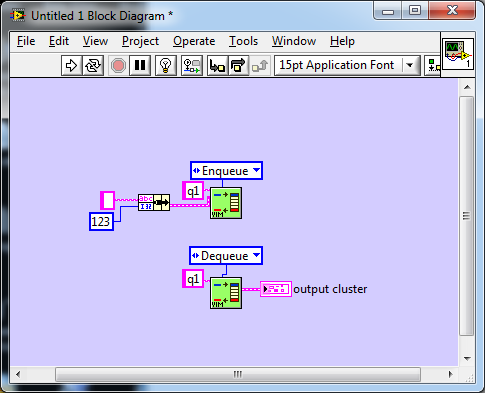
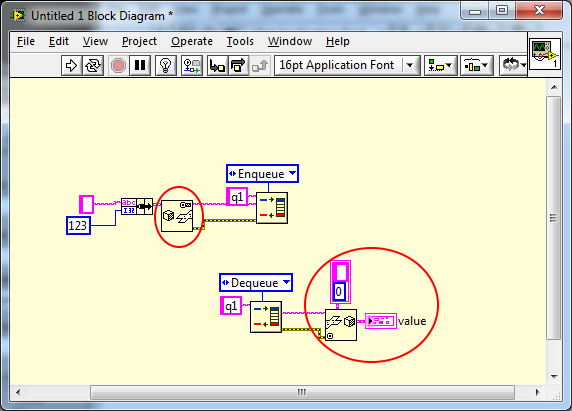
One of my long standing annoyances was not having a completely generic re-use solution for encapsulating queues and events. As much as AQ thinks my vanishing wires is a no-no, it is a necessity to me to create reusable modular code that has the benefit of being clean and easy to read. Taking the backbone of my message systems as an example, the Queue.vi, I was able to do this somewhat but had to make a decision to forgo data typing. Since my messaging is string based, I could encapsulate but had to wire a string to the input of the queue and fix the datatype - I had to wire something. This meant for rare occasions when I did not want a string, waveforms, for example, I had to type cast or flatten. (I actually wired it to the name wire, but at that time it was just so a wire didn't cross another. OCD? ) This was ugly, but acceptable for the 10% of use cases. It would have been possible to create a polymorphic VI which could work for simple types (bools, integers et. al.) but clusters, a more probable requirement, would be back to flattening. A poly would also have bloated the code base by a huge factor meaning that a simple, single VI of 16kB would have taken up an order of magnitude more space and compile time. I wasn't OK with that either. A Xnode would also have sufficed, but Xnodes where not around in those days, are an unsupported feature even now and just too damned hard - if we ignore how flakey they can be. It's hard to justify any of the other complex technologies when all use cases are covered by a single small VI with some effort by the developer just for type casting. The thing that was missing was VIM style of polymorphism that would transfer the datatype to the underlying queue primitive, transparently, without defining all permutations and combinations up front and without having a supporting entourage of VIs just to turn tricks. That would make it simpler to use. Simpler to understand and maintain modularity. It would be more elegant! And now we know about VIMs. Woohoo! And I get all that (or should I say all that disappears) just by moving a wire and adding the letter m to the VI name , No code bloat. Still 16kB. Still a single VI. Whats not to like? The one down side is that it can now produce a run-time conversion error. In the old days that would have been a problem as there were virtually no primitives that could generate run-time errors so that would have ruled out this usage. With LVPOOP, though, run-time errors have become acceptable so it is a small price to pay. This is why I'm so excited about the VIM. Finally my Queue VI doesn't need the flattening and unflattening verbosity and can relieve the user of that burden making the code even more compact and cleaner. My OCD has been satisfied I was never able to find a generic solution to events, however. They were always application specific due to the registration refnum.. Now, though, I think VIMs will enable me to do to events, what I did with queues and that makes me even more excited.
1 point
-
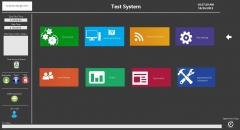 Creating a Windows 8 look UI for customer...1 point
Creating a Windows 8 look UI for customer...1 point