Leaderboard




Popular Content
Showing content with the highest reputation on 12/02/2015 in all areas
-
Setting the receive buffer isn't a help in the instance of rate limiting. There is a limit to how many packets can be buffered and they stack up. If you send faster than you can consume (by that I mean read them out through LabVIEW), you hit a limit and the TCPIP stops accepting - in many scenarios, never to return again or locking your application for a considerable time after they cease sending. For SSL, the packets (or records) are limited to 16KB so the buffer size makes no difference. Therfore it is not a solution at all in that case but that is probably outside the scope of this conversation but does demonstrate it is not a panacea. I'm not saying that setting the low level TCPIP buffer is not useful. On the contrary, it is required for performance. However. Allowing the user to choose a different strategy rather than "just go deaf when it's too much" is a more amenable approach. For example. It gives the user an opportunity to inspect the incoming data and filter out real commands so that although your application is working real hard to just service the packets, your application is still responding to your commands. As for the rest. Rolf says it better than I. I don't think the scope is bigger. It is just a move up from the simplified TCPIP reads that we have relied on for so long. Time to get with the program that other languages' comms APIs did 15 years ago I had to implement it for the SSL (which doesn't use the LabVIEW primitives) and have implemented it in the Websocket API for LabVIEW. I am now considering also putting it in transport.lvlib. However. No-one cares about security, it seems, and probably even less use transport.lvlib so its very much a "no action required",in that case. Funnily enough. It is your influence that prompted my preference to solve as much as possible in LabVIEW so in a way I learnt from the master but probably not the lesson that was taught As to performance. I'm ambivalent bordering on "meh". Processor, memory and threading all affect TCPIP performance which is why if you are truly performance oriented you may go to an FPGA. You won't get the same performance from a cRIOs TCPIP stack as even an old laptop and that assumes it comes with more than a 100Mb port. Then you have all the NAGLE, keep-alive etc that affects what your definition of performance actually is. Obviously it is something I've looked at and the overhead is a few microseconds for binary and a few 10s of microseconds for CRLF on my test machines. It's not as if I'm using IMMEDIATE mode and processing a byte at a time2 points
-
I've often think about security of my LabVIEW applications but I haven't seen much discussion in the LabVIEW community and almost never see consideration given to securing network communications even at a trivial level. So I am wondering...... What do you do to protect your customers'/companies' data and network applications written in LabVIEW? (if anything). How do you mitigate attacks on your TCPIP communications? What attacks have you seen on your applications/infrastructure? Do you often use encryption? (For what and when?). Do you trust cloud providers with unencrypted sensitive data?1 point
-
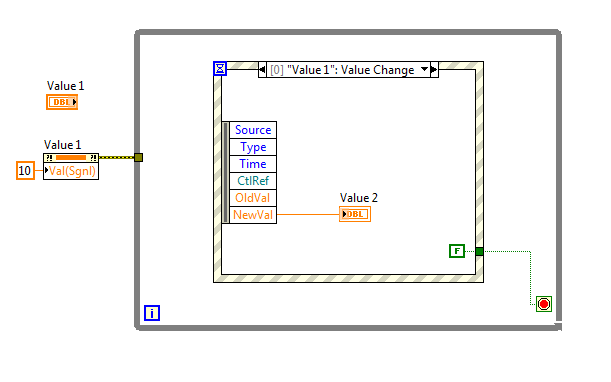
In looking through the CLD-R prep material, I ran across one example problem that made me realize I didn't quite understand how Events are registered/queued/whatever. See the attached image. In it, Value1 gets set to a certain value by means of a Val(Sgnl) property node. When executing this code, Value 2 will be set to the same value as the constant set to Value 1 (in other words, it gets set to 10). What I'm not understanding is the event queue mechanic. Before reviewing this and running the code, I would have assumed that the Val(sgnl) write event would have been discarded since there were no Event Queues set up at the time of the signaling event. Clearly though, the event structure Value Change event triggers once the dataflow gets to that point in the program. Do all events simply start stacking up in an event queue somewhere from the beginning of program execution? Is there an intelligent manager that only stacks up events for potential queues that may or may not happen later in the code? Similarly, if I duplicate the Event queue in that While loop (and change the Value 2 to a new variable, call it Value 3), then both queues get executed. Is there a separate event queue/stack/whatever for each event structure? Thanks for the help. If there is already a good thread on this please link me- I did some searching and didn't see anything.
 1 point
1 point -
Unless something has changed, both the Embedded Web Server and Application Web Server are AppWeb by EmbedThis. That web server in and of itself seems pretty capable and pretty sweet, but the wrapper that LabVIEW puts around it strips and sanitizes virtually all of the configuration file options: https://embedthis.com/appweb/doc/users/configuration.html Also, unless something has changed, setting up `SSLCertificateFile` with a private key signed by a bona fide CA (rather than self-signed) took some jumping-thru-hoops. You can poke around and modify the `ErrorLog` and `Log` specs, but only a couple security tokens are honored by not being sanitized away (https://embedthis.com/appweb/doc/users/security.html and https://embedthis.com/appweb/doc/users/monitor.html) Also -- unless something has changed -- the developer experience between dev-time and deploy-time is vastly-different, the way the web service actually works. At a very high level, the problem was this: the concepts of who calls `StartWebServer()` (maRunWebServer) were hard-coded or something into the way the RTE loads applications, and so therefore was not invoked when you just run your application from source in the IDE. In that case, there was this weird out-of-band deployment via a Project Provider, where it used the application web server rather than the embedded web server. Where of course, managing the configurations of these two disjoint deployments didn't work at all. YMMV, but I don't use it for anything. libappweb always felt pretty awesome, but it was just shackled (oh; and while libappweb continually improved, the bundled version with lv stayed on some old version) On a side note, the AppWeb docs site got a huge facelift -- looks like Semantic UI; looks/feels spectacular.1 point
-
I'm not sure I would agree her fully. Yes security is a problem as you can not get at the underlaying socket in a way that would allow to inject OpenSSL or similar into the socket for instance. So TCP/IP using LabVIEW primtives is limited to unencrypted communication. Performance wise they aren't that bad. There is some overhead in the built in data buffering that consumes some performance, but it isn't that bad. The only real limit is the synchronous character towards the application which makes some high throughput applications more or less impossible. But that are typically protocols that are rather complicated (Video streaming, VOIP, etc) and you do not want to reimplement them on top of the LabVIEW primitives but rather import an existing external library for that anyways. Having a more asynchronous API would be also pretty hard to use for most users. Together with the fact that it is mostly only really necessary for rather complex protocols I wouldn't see any compelling reason to spend to much time on that. I worked through all this pretty extensively when trying to work on this library. Unfortunately the effort to invest into such a project is huge and the immediate needs for it were somewhat limited. Shaun seems to be working on something similar at the moment but making the scope of it possibly even bigger. I know that he prefers to solve as much as possible in LabVIEW itself rather than creating an intermediate wrapper shared library. One thing that would concern me here is implementation of the intermediate buffering in LabVIEW itself. I'm not sure that you can get a similar performance there than doing the same in C, even when making heavy use of the In-Place structure in LabVIEW.1 point
-
This one bit is not quite correct. You're thinking about multiple Event Handler Structures binding to a shared queue created by a single Register For Events Node. That's the scenario that produces undefined behavior. (Not just unpredictable behavior; truly undefined behavior) Multiple Event Handler Structures bound to a "Statically-Registered Event" are OK, but as hooovahh suggests, not usually recommended. --- "Statically-Registered Event" -- contrasted with "Dynamically-Registered Event" -- is just a silly terminology for "magic wires that you don't see that you just 'know' must exist". The original post is an excellent case study for the mental leap required to learn/believe/trust/understand Static Event Registration. For some reason, in LV world it's taught that Static Event Registration is "easier" than the "advanced" topic of Dynamic Event Registration. Maybe if Dynamic Event Registration were taught like this -- it's wires you see, in the code you wrote, that code in front of you on the block diagram; that's what happens and why it happens. And lifetimes of both the event sources and event sinks -- yeah, that's kinda just wires too -- the wires you see in front of you, on the code you wrote. Understand this, and then the concept of "Static Event Registration" might help you by replacing a little syntax with some accepted, implicit convention. Said another way -- Dynamic Event Registration is syntax where the mental model maps to the visual source model, whereas Static Event Registration is just a shortcut that hides implementation details. (Yes, there do exist some notable functional differences between the two, but that's just a shortcoming of both, not a fundamental difference in the model) @Scatterplot -- as an excercise, can you create the same diagram, just with a static reference to `Value 1`, wired into a `Register for Events`, wired into the Event Handler Structure? Post that snippet, then let's use that as an explicit example to the "wireless" model of Static Event Registration.1 point
-
I wonder if this is very useful. The Berkeley TCP/IP socket library, which is used on almost all Unix systems including Linux, and on which the Winsock implementation is based too, has various configurable tuning parameters. Among them are also things like number of outstanding acknowledge packets as well as maximum buffer size per socket that can be used before the socket library simply blocks any more data to come in. The cRIO socket library (well at least for the newer NI Linux systems, the vxWorks and Pharlap libraries may be privately baked libraries that could behave less robust) being in fact just another Linux variant certainly uses them too. Your Mega-Jumbo data packet simply will block on the sender side (and fill your send buffer) and cause more likely a DOS attack on your own system than one on the receiving side. Theoretically you can set your send buffer for the socket to 2^32 -1 bytes of course but that will impact your own system performance very badly. So is it useful to add yet another "buffer limit" on the higher level protocol layers? Aren't you badly muddying the waters about proper protocol layer respoinsiblities by such bandaid fixes? Only the final high level protocol can really make any educated guesses about such limits and even there it is often hard to do if you want to allow variable sized message structures. Limiting the message to some 64KB for instance wouldn't even necessarily help if you get a client that maliciously attempts to throw thousends of such packets at your application. Only the final upper layer can really take useful action to prepare for such attacks. Anything in between will always be possible to circumvent by better architected attack attempts. In addition you can't set a socket buffer above 2^16-1 bytes after the connection has been established as the according windows need to be negotiated during the connection establishment. Since you don't get at the refnum in LabVIEW before the socket has been connected this is therefore not possible. You would have to create your DOS code in C or similar to be able to configure a sender buffer above 2^16-1 bytes on the unconnected socket before calling the connect() function.1 point