Leaderboard



Popular Content
Showing content with the highest reputation on 01/27/2017 in all areas
-
Without the source your only hope is to use the mechanisms left by the developer. If there is no ActiveX and the only interaction is with a mouse and keyboard, then you'll have to simulate a mouse and keyboard. There are several examples of using AutoIt or LabVIEW to look for windows to be active (based on their titles) then simulate pressing keys to navigate where you want and type in information. This is quite error prone and user interaction may mess with stuff.1 point
-
I've been looking into this recently as well. The other TDMS alternative is HDF5 which has been discussed around here not long ago. For my situation I'm responsible for two conceptual customers -- people who want to maintain the machine, and people who want to see the immediate output of the machine. I'm thinking HDF5 is a good fit for the immediate output data set, as it is easily movable (flat file), can contain lots of data types (even images), and is cross platform enough that anyone can open the data from python or matlab or whatever. The other customer (long-term maintenance) requires more of a data warehousing scheme to store basically everything, potentially with compaction of older data (ie average over a day, a week, a month). This is feasible with flat files but it seems very unwieldy, so I've been also looking into time series databases. Here is essentially the evaluation I've made so far (which is inconclusive but may be helpful): Basic DBs, requiring significant client dev work. The advantage being that they are all old, heavily used, and backed by large organizations. mysql can provide this, but it doesn't seem to be great at it. What we've tried is that each row is (ID, value, timestamp) where (id, timestamp) is the unique primary key. What I've found is that complex queries basically take forever, so any analysis requires yanking out data in small chunks. Postgres seems to handle this structure (way, way, way) better based on a quick benchmark but I need to evaluate more. Cassandra seemed like it would be a better fit, but I had a lot of trouble inserting data quickly. With an identical structure to mysql/postgres, cassandra's out of box insert performance was the slowest of the three. Supposedly it should be able to go faster. The slow speed could also be due to the driver, which was a tcp package off the tools network of less then ideal quality. There is an alternative called Scylla which i believe aims to be many times faster with the same query language/interface, but I havent tried it. More complete solutions: Kairos DB seems cool, its a layer on top of cassandra, where they've presumably done the hard work of optimizing for speed. It has a lot of nice functions built-in including a basic web UI for looking at queries. I ran this in a VM since I don't have a linux machine but it was still quite fast. I need to do a proper benchmark vs the above options. InfluxDB seemed like a good platform (they claim to be very fast, although others claim they are full of crap), but their longetivity scares me. Their 1.0 release is recent, and it sounds like they rebuilt half their codebase from scratch for it. I read various things on the series of tubes which make me wonder how long the company will survive. Could very well just be doom and gloom though. Prometheus.io only supports floats, which is mostly OK, and allows for tagging values with strings. They use levelDB which is a google key-value pair storage format thats been around a few years. However its designed as a polling process which monitors the health of your servers and periodically fetching data from them. You can push data to it through a 'push gateway' but as far as the overall product goes, it doesn't seem designed for me. Graphite, from what I read, is limited to a fixed size database (like you want to keep the last 10M samples in a rolling buffer) and expects data to be timestamped in a fixed interval. This is partially described here. opentsdb: InfluxDB's benchmarks show it as slower then cassandra. It has to be deployed on top of hbase or hadoop and reading through the set-up process intimidated me, so I didn't investigate further, but I think the longetivity checkmark is hit with hadoop given how much of the world uses it. Heroic, same as above except it requires cassandra, elasticsearch, and kafka, so I never got around to trying to set it up. This may also help, i found it during my search: https://docs.google.com/spreadsheets/d/1sMQe9oOKhMhIVw9WmuCEWdPtAoccJ4a-IuZv4fXDHxM/edit Long story short, we don't need this half of the requirement right now, so we're tabling the decision until later when we have a better idea of a specific project's needs. For example, some of the tools have automatic compression and conversion over time, while others are geared more towards keeping all data forever. I don't know right now which is going to be the better fit.1 point
-
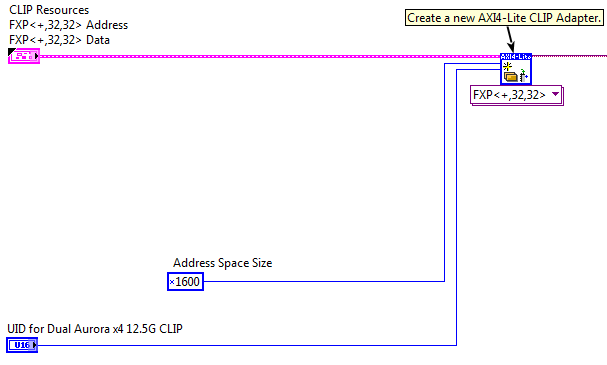
Got it working, just needed to ask someone who knew what they were looking at. I needed to make a change to the "Create AXI4-Lite Resources.vi" which is next to the instruction framework interface on the FPGA. The Address Space Size is 0x800 by default so it just needs to be made larger. I compiled successfully at 0x1600 but I was told the correct size is 0x1200. Matt J
 1 point
1 point