hooovahh
-
Posts
3,477 -
Joined
-
Last visited
-
Days Won
299
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by hooovahh
-

LVMark: Format markup for string controls
hooovahh replied to jzoller's topic in Code In-Development
I know this post is ancient by internet standards, but I've been using LVMark off and on for years now. I recently posted a Hooovahh String package here on VIPM.IO. I plan on making a video demonstrating features of that package including LVMark some day. The LVMark code is mostly unchanged from the version posted here, just some comments and VIA_Ignore tags mostly. I do think there are places where performance could be better, but I've only ever used it on relatively small strings. There seems to be other LabVIEW Markdown libraries, like the one Ton linked to (but links seem to be dead), and a QControl here that has similar functionality. I do like the simplicity of LVMark. -
Handling HAL with Children Through Packages
hooovahh replied to hooovahh's topic in Object-Oriented Programming
Yes you make a good point. Maybe I just see it as friction when going to a built application. Like ideally you just tell LabVIEW this is my top level VI and if it runs in the IDE it should run in an EXE. Anything that gets in the way of that simplicity feels like an annoyance to me. But you are right once it is done once that's it. I think the explicit find for each class is more obvious. Like you said a developer may drop down a Find VI and it will either be broken (with the required terminal un wired) or they will need to find what they need. I think I do find the Class Constant method easier in times when you don't know what hardware you want, and you want to just use any. But admittedly that is quite rare and most applications are for a tester with a known set of hardware. I can do both of course, but maybe have the Find for that class be the VI that is on the palette. I don't understand what you are saying here. Are you saying that if the hardware uses a DLL for example, you won't know until you try to deploy to a target where that isn't supported? I mean the VI will be broken in the context of a Linux target, so that will at least clue in the developer before having to deploy it and see it doesn't work. -
Handling HAL with Children Through Packages
hooovahh replied to hooovahh's topic in Object-Oriented Programming
I've used a variation of this design in the past and as you said if you load it dynamically from disk, LabVIEW needs to be told to always include it in builds. If I provide VIPM package to someone, I don't think it is an obvious step that they should need to find my class and add it to an always include for builds. I don't need to do that for other APIs, like DAQmx for example. If you can rely on the documentation to have the always include, and you control on disk where things are, your dynamic load solution with naming of the class will work. If I want to avoid always include, and if I want the code to have to be brought as a dependency, I think there are only one of two options for forcing the library to be in memory, so the dependencies are brought along. Either have a class constant somewhere, or a class specific VI. It must be one of those two options right? That was my original question of which design do people prefer and use to force some code to be dependent on that class? -
Handling HAL with Children Through Packages
hooovahh replied to hooovahh's topic in Object-Oriented Programming
Looks like Jim went with the design where class constants are passed in as an array of classes to operate on like my first example. -
Handling HAL with Children Through Packages
hooovahh replied to hooovahh's topic in Object-Oriented Programming
But the "Find" is child specific, you can't use the same find VI for each class type. Some will use RS-232 COM ports. But others could be 485, or Modbus, some TCP IP Addresses, UDP Address, HTTP Addresses, etc. And they will all talk with different protocols. So there needs to be new Find, for each package and class type installed. And using one classes find function should not force a dependency on all the other classes. This is because of the platform specific needs mentioned earlier. If I went the way I think you are describing, you would call a Find function, and it would "return an array of class objects" Okay but to do that don't I need to have all those children classes in memory? Wouldn't that mean using that Find causes a forced dependency on all classes? Then that breaks things like RT deployment when a target doesn't support that type. This is a great elegant solution that I like. But imagine the situation where I would like to pick the RSA polymorphic, and have no other classes in memory. Well no classes at the same level as RSA, obviously the parents of RSA need to be in memory. That's why this solution doesn't work, and that's why a Find which returns an array of classes doesn't work.
-
Handling HAL with Children Through Packages
hooovahh replied to hooovahh's topic in Object-Oriented Programming
I don't think plugin architecture describes what I'm looking for correctly. Ideally the developer installs packages for the hardware they have. The package can have some idea of the system they have, so like 32bit DLLs can only be installed in 32 bit LabVIEW. I do think that I'm envisioning a static class constant (or VI call) to ensure dependencies are brought along for the build. Which does bring me back to the first question. Do people prefer or use one design over the other? And by that I mean the static dispatch parent with finding classes passed in, or explicit find for each child type? For that there would either be a separate CSZ TCP, and CSZ USB children, or there would be a CSZ Parent, CSZ TCP, and CSZ USB depending on implementation details and overlap between the two types. But I do get your point. As a developer I know I have a CSZ so I install that package, then start developing. Only once I go to deploy to an RT target will the USB one tell me it isn't compatible by saying it can't bring along some DLL requirement. I guess this is something that the LVAddons might help with. I haven't dived into it yet but as I understand it, files can be made available or not in the IDE based on the target. So then you might install the CSZ USB package, but it won't be on the palette if your target is Linux RT. I actually did run into this issue recently where I was using the JKI REST API. I tested it on Windows and assumed it would work fine on RT since it the normal HTTP functions are on Linux RT. But unfortunately later versions of JKI's package uses the Advanced HTTP functions which are not available. -
Handling HAL with Children Through Packages
hooovahh replied to hooovahh's topic in Object-Oriented Programming
How do you deal with built applications? Your solution sounds fine on Windows, and in a development environment. But if I make an RT or Windows application, it won't know to bring along the child classes into the build if they are called dynamically. Unless I add them as an always include I guess. I think there isn't any way around having to have either a class constant of the children somewhere (like into the Find Parent VI) or to have each child class have it's own Find which is part of it's own class and brought into the builds. I suggested the XNode option just because it could read those files on your Windows disk, then plop down the constants into the generated code. That has complications like only bringing along the classes on your disk, at that time, unless on load the XNode reloads and regenerates code which is a different kind of mess I wouldn't want to deal with. But then again it could be a cool right click feature for reload, or check boxes on what libraries are installed, and which ones to load. And while that is all cool sounding, the very large majority of the time a developer just wants to plop down a single VI, that finds the hardware for that specific hardware type. And then not have to do anything extra to make builds work. -
Handling HAL with Children Through Packages
hooovahh replied to hooovahh's topic in Object-Oriented Programming
The problem I have with that is you need a polymorphic VI that has all of the instances inside it. That creates a dependency that all children are available and installed. In my situation you may only install the Chamber package, and CSZ package. Then the developer only has the parent, and that one child (well 2 there is the simulate). So now where would that polymorphic VI live? In the parent package? Then that creates a circular dependency. I did explore creating an XNode that would look at your current system and drop a VI that had whatever children were available for that target, but that got a bit messy. The reason for having separate packages, is because some child classes, only work on some targets. I may have one chamber that uses a Windows DLL to talk to it over USB. This DLL wouldn't run on Linux RT, and I need to not bring along that child class as dependencies, because that will break the deploy or build, even when that child isn't being directly called. -
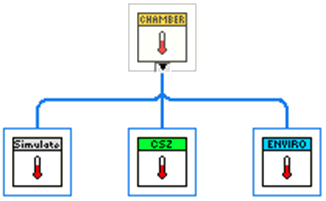
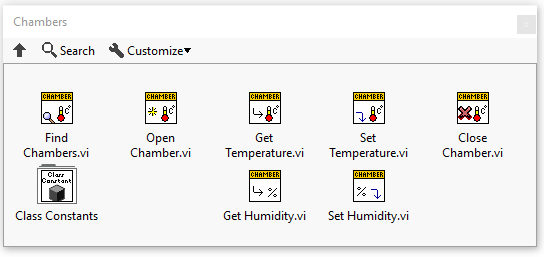
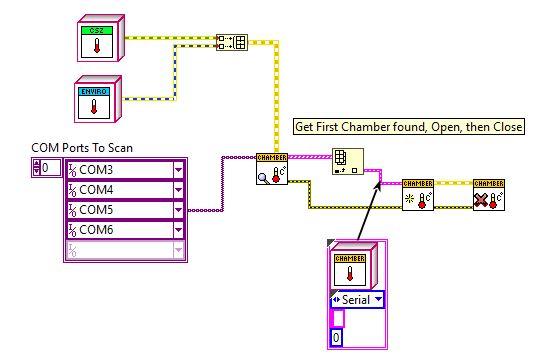
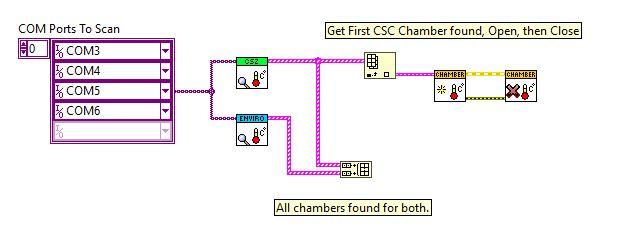
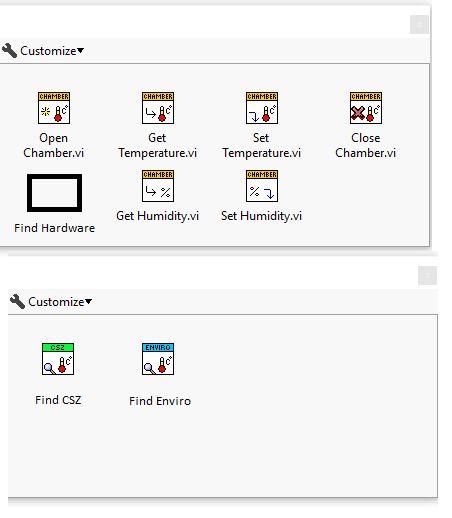
Lets say I have a basic hardware abstraction layer for environmental chambers. Here I have the parent Chamber class, a Simulate Class which overrides the required members, a CSZ, and an Envirotronics which are two makers of chamber hardware. For this example lets say I want to distribute this as 3 different VIPM packages. I have my Hooovahh Chamber.vip, which contains the Parent, and Simulate classes, and I have two others the Hooovahh Chamber >> CSZ.vip, and Hooovahh Chamber >> Envirotronics.vip. On the palette I have the main functions all look similar to this. My main question is about how people handle the Finding and Opening functions? I want these drivers on the palette to be easy to use for my developers. At the moment when you install the main Chamber package it installs the Parent VIs you see, and the Simulate class constant on the Class Constants subpalette. Each child specific package then installs a new class constant in the subpalette. Then when a developer wants to use the Find Chambers, they must wire to it an array of classes to use. Here is an example: Here we have a Find VI that is static dispatch on the parent, with overrides insides for each of the Chamber types. It returns an array of found Chambers which is a cluster. In the cluster is the class for the chamber found, which is used in the Overrides for Open and Close. This works and is fine. But I like the idea of hiding away the class constants, and having more self contained Find VIs for each hardware type. In most cases we know the hardware we want to talk to and it isn't an array of classes on an array of COM ports, but instead the one hardware class we intend to use on the system. What I think I would prefer is some thing more like this: Here the developer gets a dedicated Find VI for each class which is a static dispatch for each child class. They all return the same array of cluster (which would be a data type from the parent) and then that array of found chambers is used in the Parent Open which has overrides for each class inside. In this design I would have the Find for each class installed on the palette under some kind of Find Hardware subpalette. In this case I imagine there would need to be some kind method of keeping each Find from only using one COM port at a time. Either through VIG or Semaphore of some kind. Admittedly this is simplified in the previous example since the Parent would be doing the finding, and would know to only pass a unique COM port to one child at a time. In all of these cases I imagine we have full control over the Parent, and all Children. If anyone develops a new child class, we would roll it into the reuse library as another package which would go through the verification process. Do developers prefer one design over the other? What pros and cons haven't I thought about? Thanks.
-
This year I went to NI Connect (the new NI Week) for the first time in 7 years. I thought I would be the exception and see all those that have gone year after year. But it turns out that many of us this was our first year back, or some last year was their first year back since COVID. In general I think this is a good sign, that things are moving in the right direction. NI has some new leadership that has a LabVIEW focus, and at least at the moment appear to want to push adoption. Reversing the subscription only is a welcome change, but for many it hurt the inertia of business. Once a ship starts moving in the wrong direction it takes a while to come back. Or put another way, respect is lost in buckets and gained in drops. Plenty of businesses have likely moved away from LabVIEW and NI because of poor decisions, that in my opinion, were so NI would look more valuable for an Emerson sale. I'm in the Detroit area, and plan to retire doing LabVIEW. At the moment I think I can do that. Not long ago I didn't think that would be the case. We were just blindly paying the SSP each year. The subscription only model, made management here reevaluated things. We took a few years off. Then perpetual licenses came back again so we renewed. I think we will likely get a new perpetual license every 4 years or so. This will hurt NI since this means less users on the newest release finding issues. Building back trust will take time here, and this will likely play out in a similar way around the world for other companies.
-
There are several SQLite libraries on VIPM.io. I personally use the one by JDP Science, but a few others also look promising. Changing over will obviously take some time finding and replacing one API for another, especially if there are differences in design choices in how they each implement similar functionality.
-
Can you describe the issue and steps you took?
-
VPN to the rescue. Yeah I see it. If you do a resource replace function outside of the scripting functions, you can probably get around the runtime environment requirement. But again I don't know what problem that solves, you still need to use LabVIEW in the development environment to use the controls. To me this is an extension of the IDE. Having something like QuickDrop be a separate application for instance doesn't solve anything, but adds unnecessary complications.
-
Several of the functions that this uses to generate the control are LabVIEW properties and methods that are only available in the full development environment. Control creation isn't the type of function NI had planned for LabVIEW to do at run time when it was created. What problem are you trying to solve with having this be a built application?
-
"I don't want your damn lemons!"
-
Yes thank you I see that now. The link to a login page, private hosting, and the listing for Commercial Pricing at the top of the page made me think it was more restrictive.
-
I'm unsure of your tone and intent with text, but I'll do my best to explain the vocabulary. The Free (as in beer) is like when I go to a friends house and they offer me a free beer. I can have this beer, and I am entitled to enjoying it without monetary cost. Of course someone else paid for it, but I get to enjoy it, they shared it with me. I do no have the rights or the freedom to reproduce this beer, market it, and sell it. My free-ness is limited to the license you provide. I guess an equivalent analogy here could be if my friend gives me a beer, but expects me to help him move. It is an agreement we both have. If I am "free to do what I want" that is a different kind of freedom. A freedom that is more like free speech, a right that we have. It isn't as limited as someone giving me a beer, it is closer to someone giving me a beer recipe. Typically this is associated with free open source software. Open source software is free (like beer) someone is giving it to me without having to pay. But the freedom I get goes farther than that. This probably is a problem with the english language, and how words can have many meanings and without context "free" can mean different things. The Beer/Speech is just there to help clear up what kind of free we are talking about.
-
Yup. Last time I checked.
-
Do you guys also disagree philosophically about sharing your work online? That link doesn't appear to be to a download but a login page, it isn't clear to me if the code is free (as in beer). I assume it isn't free (as in speech). In this situation I think Rolf's implementation meets my needs. I initially thought I needed more low level control, but I really don't.
-
All very good information thanks for the discussion. I was mostly just interested in reentrant for the ZLIB Deflate VI specifically. For my test I took 65k random CAN frames I had, organized them by IDs, then made something like roughly 60 calls to the deflate, getting compressed blocks for each ID and time. Just to highlight the improvement I turned the compression level up to 9, and it took about 400ms. In the real world the default compression level is just fine. I then set the loop to enable parallelism with 16 instances, which was the default for my CPU. That time to process the same frames at the same compression level took 90ms. In the real world I will likely be trying to handle something like a million frames, in chunks, maybe using pipelining. So the improvement of 4.5 times faster for the same result is a nice benefit if all I need to do is enable reentrant on a single VI. Just something for you to consider, and seems like a fairly low risk on this VI, since we aren't talking to outside resources, just a stream. I'd feel similarly for the Inflate VI. I certainly would not try to access the same stream on two different functions at the same time. Thanks for the info on time. I feel fairly certain that in my application, a double for time is the first easy step to improve log file size and compression.
-
I don't see any function name in the DLL mention Deflate/Inflate, just lvzlib_compress and lvzlib_compress2 for the newer releases. Still I don't know if you need to expose these extra functions just for me. I did some more testing and using the OpenG Deflate, and having two single blocks for each ID (Timestamp and payload) still results in a measurable level of improvement on it's own for my CAN log testing. 37MB uncompressed, 5.3MB with Vector compression, and 4.7MB for this test. I don't think that going to multiple blocks within Deflate will have that much of a savings, since the trees, and pairs need to be recreated anyway. What did have a measurable improvement is calling the OpenG Deflate function in parallel. Is that compress call thread safe? Can the VI just be set to reentrant? If so I do highly suggest making that change to the VI. I saw you are supporting back to LabVIEW 8.6 and I'm unsure what options it had. I suspect it does not have Separate Compile code back then. Edit: Oh if I reduce the timestamp constant down to a floating double, the size goes down to 2.5MB. I may need to look into the difference in precision and what is lost with that reduction.
-
Thanks but for the OpenG lvzlib I only see lvzlib_compress used for the Deflate function. Rolf I might be interested in these functions being exposed if that isn't too much to ask. Edit: I need to test more. My space improvements with lower level control might have been a bug. Need to unit test.
-
So then is this what an Idea Exchange should be? Ask NI to expose the Inflate/Deflate zlib functions they already have? I don't mind making it I just want to know what I'm asking for. Also I continued down my CAN logging experiment with some promising results. I took log I had with 500k frames in it with a mix of HS and FD frames. This raw data was roughly 37MB. I created a Vector compatible BLF file, which compresses the stream of frames written in the order they come in and it was 5.3MB. Then I made a new file, that has one block for header information containing, start and end frames, formats, and frame IDs, then two more blocks for each frame ID. One for timestamp data, and another for the payload data. This orders the data so we should have more repeated patterns not broken up by other timestamp, or frame data. This file would be roughly 1.7MB containing the same information. That's a pretty significant savings. Processing time was hard to calculate. Going to the BLF using OpenG Deflate was about 2 seconds. The BLF conversion with my zlib takes...considerably longer. Like 36 minutes. LabVIEW's multithreaded-ness can only save me from so much before limitations can't be overcome. I'm unsure what improvements can be made but I'm not that optimistic. There are some inefficiencies for sure, but I really just can't come close to the OpenG Deflate. Timing my CAN optimized blocks is hard too since I have to spend time organizing it, which is a thing I could do in real time as frame came in if this were in a real application. This does get me thinking though. The OpenG implementation doesn't have a lot of control for how it work at the block level. I wouldn't mind if there is more control over the ability to define what data goes into what block. At the moment I suspect the OpenG Deflate just has one block and everything is in it. Which to be fair I could still work with. Just each unique frame ID would get its own Deflate, with a single block in it, instead of the Deflate containing multiple blocks, for multiple frames. Is that level of control something zlib will expose? I also noticed limitations like it deciding to use the fixed or dynamic table on it's own. For testing I was hoping I could pick what to do.
-
How to load a base64-encoded image in LabVIEW?
hooovahh replied to Harris Hu's topic in LabVIEW General
😅 You might be waiting a while, I'm mostly interested in compression, not decompression. That being said in the post I made, there is a VI called Process Huffman Tree and Process Data - Inflate Test under the Sandbox folder. I found it on the NI forums at some point and thought it was neat but I wasn't ready to use it yet. It isn't complete obviously but does the walking through of bits of the tree, to bytes. EDIT: Here is the post on NI's forums I found it on. -
Yes I'm trying to think about where I want to end this endeavor. I could support the storage, and fixed tables modes, which I think are both way WAY easier to handle then the dynamic table it already has. And one area where I think I could actually make something useful, is in compression of CAN frame data and storage. zLib compression works on detecting repeating patterns. And raw CAN data for a single frame ID is very often going to repeat values from that same ID. But the standard BLF log file doesn't order frames by IDs, it orders them by time stamps. So you might get a single repeated frame, but you likely won't have huge repeating sections of a file if they are ordered this way. zLib has a concept of blocks, and over the weekend I thought about how each block could be a CAN ID, compressing all frames from just that ID. That would have huge amounts of repetition, and would save lots of space. And this could be very multi-threaded operation since each ID could be compressed at once. I like thinking about all this, but the actual work seems like it might not be as valuable to others. I mean who need yet another file format, for an already obscure log data? Even if it is faster, or smaller? I might run some tests and see what I come up with, and see if it is worth the effort. As for debugging bit level issues. The AI was pretty decent at this too. I would paste in a set of bytes and ask it to figure out what the values were for various things. It would then go about the zlib analysis and tell me what it thought the issue was. It hallucinated a couple of times, but it did fairly well. Yeah performance isn't wonderful, but it also isn't terrible. I think some direct memory manipulation with LabVIEW calls could help, but I'm unsure how good I can make it, and how often rusty nails in the attic will poke me. I think reading and writing PNG files with compression would be a good addition to the LabVIEW RT tool box. At the moment I don't have a working solution for this, but suspect that if I put some time into I could have something working. I was making web servers on RT that would publish a page for controlling and viewing a running VI. The easiest way to send image data over was as a PNG, but the only option I found was to send it as uncompressed PNG images which are quite a bit larger than even the base level compression. I do wonder why NI doesn't have a native Deflate/Inflate built into LabVIEW. I get that if they use the zlib binaries they need a different one for each target, but I feel that that is a somewhat manageable list. They already have to support creating Zip files on the various targets. If they support Deflate/Inflate, they can do the rest in native G to support zip compression.