Leaderboard


Popular Content
Showing content with the highest reputation on 10/17/2019 in all areas
-
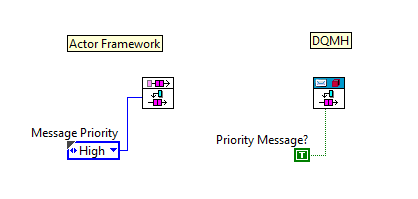
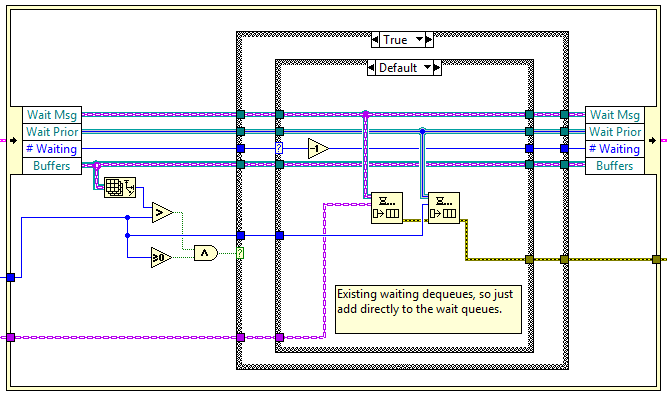
Thought I'd show an example of "complexity" of a framework, according to my way of thinking, by comparing the priority messages of the NI Actor Framework and the DQMH: Looks the same from an API level (they even use similar icons). Let's look inside; here is the relevant code section for priority messages for the AF: Yikes! And here is the same for DQMH: Ah, much simpler. Now we can see which framework involves more complexity: the DQMH. Wait, what, you say? Isn't the obvious complexity of the AF implementation mean the AF involves more complexity? Well, no, because I, as User of a framework, care nothing about the implementation, I care about application I am building with these APIs. So let's consider the task of sending three high-priority messages, A then B then C. In what order will the three messages be received and acted on? With the Actor Framework the order will be A, then B, then C, ABC, always. With the DQMH we have: 1) if the receiver can execute them faster than they are sent, the order will be ABC 2) if the receiver is handling another message the order will be CBA (as we place on the front of the queue) 3) if the receiver is idle, but executing A takes time (allowing C to get before B), the order will be ACB 4) if busy but finishes after B is sent but before C is sent, the order is BCA 5) as (4) but B is finished executing before C sent, ther order is BAC Thus with the DQMH there are 5 possible orderings of execution, with the probability of the various orderings highly dependant on timing of not-directly-related bits of code (other messages being sent). At best, this is counter-intuitive and potentially confusing during debugging. At worst, one combination is a rare race condition that doesn't show up during testing and causes near-impossible-to-debug errors in deployed code. So that is an example of complexity, and it is certainly accidental, as the DQMH designers did not intend unpredictability of message-handling order when they used enque-in-front as message "priority".
 1 point
1 point -
Of course it is. They changed the PK0x030x04 identifier that is in the first four bytes of a ZIP stream, since when they did it with the original identifier, there was a loud scream through the community that it was very easy to steal the IP contained in a LabVIEW execuable. And yes it was easy as most ZIP unarchivers have a habit of scanning a file for this PK header, no matter where it is in a file and if they do and the local directory structure following it makes sense they will simply open the embedded ZIP archive. This is because many generators for self extracting archives simply tacked an executable stub in front of a ZIP archive to make it work as an executable. The screaming about stealing IP was IMHO totally out of proportions, the VIs in an executable have no diagram, no icon and usually not even a front panel (unless they are set to show their frontpanel at some point). But NI listened and simply changed the local directory header for the embedded ZIP stream and all was well 😆. The ZIP functions available in LabVIEW are a byproduct of integrating the minizip and zlib sources into LabVIEW for the purpose of compressing binary data structures inside of VIs to make the VIs smaller and of using a ZIP archive in executables rather than the old <=8.0 LLB format used. The need to change away from the embedded LLB was mainly because with the introduction of classes and lvlibs, the VI names alone where not always unique and therefore couldn't be stored in the single level LLB anymore. They needed a hierarchical archive format and rather than extending the LLB format to support subdirectories, it was much easier to use the ZIP archive format and the ZLIB provided sources came with a liberal enough license to do that.1 point