Leaderboard



Popular Content
Showing content with the highest reputation on 09/08/2024 in all areas
-
I put a prerelease package under https://kalbermatter.nl/downloads/oglib_lvzip-5.0.4beta-1.ogp The package is now officially released as version 5.0.4-1 under https://www.vipm.io/package/oglib_lvzip/1 point
-
I presented at NI-Week 2009 on a couple of paradigms for extending the LabVIEW Error Handling Core (as inspired by all your posting here). Here are the resources from that presentation (I didn't screencapture the examples, but you should be able to see what I was talking about from the video and the code that's included): NIWeek Session Video Presentation Slides.pdf Presentation Code.zip It's a hot topic, and I know a lot of people have strong opinions on it, so let's discuss!1 point
-
I went mucking around inside General Error Handler.vi and am aghast at what I found. It seems like error definition is split between error code lookup (defined in error files) and extra information jammed into the description string using bracketed tags (like call chain and suggestions for handling the error). Why we're forced to handle specific error codes anyway is beyond me. There isn't any way of knowing which codes will be thrown by a given function, and many of the first 100 codes are reused in mysterious ways all over NI's APIs. (e.g. error 7 coming from a property node inside the VI that establishes an SMTP connection) Surely there's a better way to organize and transfer information about something having gone wrong? I realize that LV will always be dependent on returned error values from each function instead of cooler systems like exceptions, but there still seems to be a lot of opportunity for improving HOW those errors are encoded, decoded, and handled. Has anybody spent time thinking about this? Should I just put the rug back down and pretend I never looked under it?1 point
-
Two dusty threads from 2007 and 2009. I'll just lay this rug back down and walk away. There are probably more productive ways to occupy my spare time at work.1 point
-
Fixed. I've uploaded it to youTube as one video.1 point
-
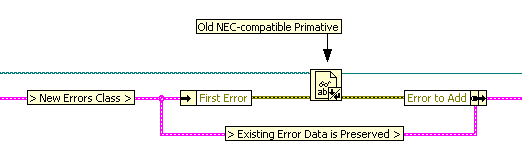
Something I'd thought about a while ago, and gb119 eloquently descrived on the LabVIEW Idea Exchange here, is the automatic conversion between the NEC and a new paradigm (ie: LVOOP Errors Class). One idea I'd had was something like the "Merge Signals" primative that is automatically inserted when you try to wire two signals into a graph: One of the real limitations of the "NEC in OO" paradigm that was presented is backward compatibility - this might alleviate some of that pain (automatically adding a onvert to and convert from on either side of a subVI with the NEC type - while including a wire between the conversion VIs to keep the existing errors data - sort of like wiring an existing cluster to the "input cluster" input of the "bundle by name" primative): I wish I had have been there! I'm glad you enjoyed it and it was thought-provoking - I think it's a very interesting topic and an opportunity for us to make a real difference in an area that we all know could be better
 1 point
1 point -
Every item added to the error code cluster is a MAJOR increase in the size of every VI's memory footprint. I'd rather see a single Variant and have all of these be attributes of that variant. The allocation space in VIs would be SUBSTANTIALLY less. (Assuming you stay as a cluster... if it becomes an object, well, load it up as much as you want... the top level data size is just one pointer.)1 point
-
QUOTE (ryank @ May 26 2009, 02:10 PM) In our system, you can pass in a variant of whatever data wires you want and they are formatted into a string. However, by default this code, along with the code to grab the call chain, only runs if there is an error. There is no string handling unless there is an error thrown. Presumably if there is some kind of exception, need for real-time performance is probably over. All that stuff would be so much easier if it were supported internally by LabVIEW. It would be great for NI to show some leadership on this and modernize the error handling system. This would really boost my productivity. Hopefully at the very least they will attend the NI Week session1 point
-
QUOTE (Anders Björk @ May 25 2009, 10:51 AM) Not generally. You have errors that arise from code where the only returned value is a number. No strings, no clusters, no booleans, just a number. They may be C built DLLs like the GPIB drivers. They may be DLLs built with LabVIEW VIs that are then returning just the error code. They could be log files where people just wrote down the number and are now reading it back in. There are tons of places where the only bit of data that is preserved is the integer. Because of the way that error codes get used by many users -- both internal and external to NI -- there's no way to have any migration path. Back in 2001, I spent a year working with CVI and TestStand and driver groups to find a migration path, and we ultimately determined that there couldn't be one, which meant that we needed to strengthen the protections of the NI Error Code Database to make sure that overlaps never occurred. That's when we started reserving error code ranges, so that two products simultaneously in development wouldn't accidentally grab the same number, or something like that.QUOTE (Black Pearl @ May 26 2009, 02:17 PM) Would't be an OOP aproach be best for that? Base class only contains the traditional error cluster, so the object can be casted to that base class to be compatible with the standard error. And something very much like that is what I prototyped and posted to LAVA last year.1 point
-
This is a topic I've been experimenting with for a while. Basically, I've found it's insufficient to have just a central error handler or just a local error handler. I think you need to have strategies for both. If you do just central error handling, it becomes difficult to do things like retry an operation, because it requires a lot of code for the central error handler to communicate with the specific section of code that threw the error. You also have to deal with the behavior of other code as you pass the error around, which is difficult, because different VIs and APIs treat incoming errors in different ways (which means that for any sufficiently complex secton of code, the behavior on an incoming error is essentially undefined). If you do just local error handling (I use the term "specific"), you end up calling dialogs or accessing files from loops you probably shouldn't be accessing them from (I do a lot of RT programming). My strategy has been to create a specific error handler which you call after each functional segment of code (which can be a loop iteration, subVI, or something more granular), and which can take actions based on specific error codes that happen in that segment (much like exception handling in other languages like Java). The specific error handler can take actions like retrying code, ignoring the error, converting it to a warning, or categorizing it. Ideally, the concept is that at the end of any functional segment of code, the errors from that segment have been handled if possible and categorized if not. You can then avoid passing them to other segments of code to get around the problem with undefined behavior that I mentioned before. For usability's sake, my specific error handler is an express VI that lets you configure a list of error codes or ranges and actions for each. I categorize errors by using the <append> tag in the source field, which keeps them fully compatible with all of the normal error handling functions (one drawback is that this requires string manipulation, which is kind of a no-no time-critical RT code, I haven't yet come up with an alternative I'm comfortable with though). A categorized error feeds into the central error handler (you can pass them with queues, events, FGs, or whatever you like), which can take actions based on categories of error. Each error category can take multiple actions, examples of actions are notifying the user, logging, placing outputs in a safe state, and system shutdown/reboot. Of course, there is always the case of an error code you've never seen before, which I usually treat as a critical error that puts the system in a safe state, logs, and notifies the user. At some point I'll get the kinks ironed out of my code to the point where I feel comfortable posting it (at that point it will probably show up as a reference design on ni.com), but I think the concepts are solid no matter what implementation you use. Regards, Ryan K.1 point
-
QUOTE (crelf @ May 22 2009, 02:57 PM) Ah, but you hit on a very real problem: People cannot move to a new range. If we could do that, we would make the GPIB error codes no longer overlap with the LV error codes. But there's a lot of VIs in the world that check for specific error codes as returned values. Changing the error code for a given error can wreck havoc. Once an error code is allocated, it stays allocated, even if the product is end-of-life, because someone might still be using that product out in the world.1 point
-
QUOTE (jdunham @ May 20 2009, 11:53 PM) No need for waterboarding. No one had ever asked for a larger range. As of this morning, the range 500000 to 599999 is now reserved for users.1 point
-
This is my take on error handling I use a FGV to store User event. On an error I generate a user event and pass the error to my event loop. In the dynamic error event case I have a state machine that can handle whatever error based on the error code, and then perform a custom action (i.e. shut down hardware, perform a certain action to correct the error, etc). I also log all errors generated to a text file. This I have found works for me because the error dialogs are handeled in the event loop and I can still call other sections of code when the error dialog is displayed. I am very interested in what other people do to handle their errors. Dan P.S. I hope NI gives you the big room for this presentation and doesn't have it at 4:00 on Thurs.1 point
-
I'll try and add my :2cents: to show the concept of how I handle error logging and visualisation in my applications. I basically have the whole error/message logging encapsulated in a by-ref class. This class: handles logging of the errors/messages to disk rotates logs every N days has an active thread of which optionally the UI can be shown as a (floating) window to see the realtime log publishes log events to interested subscribers through dynamic events Each parallel loop (including dynamically spawned processes in active objects etc.) takes a reference to the logger object. To make sure all errors are catched all executions chains should end with the AddError method. In the example here, on error, the default logwindow would be shown (which shows all messages since application start). Whether or not you want that depends on the type of application and where you are in the development cycle. I usually use the catched event to determine what error occured and decide what to do with it (e.g. ignore it, show in a nice UI, quit app, etc.)1 point
-
QUOTE (Black Pearl @ May 20 2009, 08:38 PM) Weird... error code 7 is one of the ones I deal with on a daily basis (just today, in fact, I fixed a bug today involving a function returning it and the next function in line not handling it correctly) and I've never had the GPIB error... this could be because except for a week of training 9 years ago, I've never had reason to use GPIB. :-) The common NI Error Code Database came into being in LV 6.1. Prior to that, every group had its own error codes, and of course, every group started counting at 1... except for one group ( I forget which) that actually used error code zero as an error. Ug. Nowadays we have reserved error code ranges for different products, and we offset the errors coming from the operating system into their own region. There's even two ranges reserved for our customers. :-)1 point
-
QUOTE (Black Pearl @ May 20 2009, 06:57 PM) I agree that usability is a key. I'd sure like to know who at NI thought it was a grand idea to share error 7 between File I/O and GPIB. "Why does my system have a GPIB error? ... Because your configuration is pointing to a file that doesn't exist." I have NEVER in 16 years had a user tell me that there was a File I/O error when an error 7 occured. I used to be bad at error handling. (I hope Brian isn't using me as the bad example.) I now use a centralized error handler with an error passing vi that makes it simple. With a central error handler, I can log errors and command things to shutdown if severe errors occur.1 point