

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
QD feels like a "Every problem is a nail...." situation to me.
I completely agree. Don't get me wrong, I love QD, but I don't care for the collection of arcane keystrokes that are used to bend it to one's will. Ideally what I'd like is not so much to have a floating window open at all times, but a tool like yours come up due to some context like quick-drop does.
-
Yeah when Christina mentioned the cell height of each cell needs to be the same, I thought when have I ever wanted the cell height to be different for a single row, and I guess there is a case for this but I have never needed it.
Often my header rows are different heights, though there are obviously other cases. Regardless, it is good to know of this optimization, as by knowing it I can use other tricks to show things like units and what not which would cause the abnormal sizes for a single row.
-
I think incorporating this logic into quick drop would be ideal.
-
 1
1
-
-
Do you guys really use FGV or AE much anymore? I would think it's a dying practice now with native classes.
On the contrary, FGV is how one implements static class data. My usage of FGV has perhaps even gone up with the widespread adoption of object oriented design in my LabVIEW code.
-
If you want to update the graph only after events come in, but don’t want the overhead of updating every event in a “burst”, you can put a “-1” constant inside the timeout case and wire it back through shift register into the timeout, and set the tunnel out to “Use default if unwired” so that the timeout is zero after any event other than timeout.
This is probably the most common pattern I use for making simple user interfaces. I think it's a great way of handling any interface whose rendering state can be determined from a single call. Things get more complicated for complex interfaces if you can't just go blindly rendering everything all the time, but most of the time I find this recommendation is spot on.
-
The mutability of types in ECMA/javascript always made me wonder how reliably one can interact with strict-typed languages. I suppose to use the built in version you need to enforce a stricter version of the JSON schema you'll be reading in that includes types. My guess is this limitation is also a good part of why it's so fast.
When converting between dynamic and strict typed languages, I suppose it's expected that there needs to be an extra burden somewhere to enforce types. It's unfortunate though that LabVIEW leaves this burden to the writer's side. Of course what happens if you don't have control over the source of the JSON? Do you honestly think MtGox has a specification that prince_int and amount_int are to be serialized as strings? Who's to say, though it seems rather unlikely. What happens if one day price_int suddenly comes in as an integer but amount_int remains a string? Need another work around.
I'd argue that unless you have direct control over the source of the JSON, or unless there is a schema or documentation defining types (and obviously structure) within that JSON, then the native API shouldn't be used. Shame, because it is really nice. Really, it's nothing new-- serialized data is only useful if you know how to read it.
-
I'm not sure of the nature of the ADC that lies under the hood, I'm working of a USB-6341.
I agree with Tim_S that it's likely the resource just isn't available when I happen to make the call. There has to be something going on under the hood because this error creeps up seemingly after random periods of time: could be after a few thousand reads, could be after a few hundred thousand. Part of me though expected this layer of hardware interaction to be transparent. Nothing is explicitly interacting with the hardware, so the fact that it's unavailable likely means there's just some issue with my request happening at exactly the wrong time according to some internal clock the ADC is likely running at. "Likely" because there's not a lot of information to debug this with. This is all eerily familiar to when I have to break out low level SPI communication with ADC chips...
The return of an error makes sense when you think about it: on time critical loops jitter could be introduced. If a zero timeout is wired the VI better well honor it, even if "waiting" would be just one iteration of some internal clock equating to a few nanoseconds for a register to become available.
Still though, it seems...weird. All of my LabVIEW experience has taught me to think of AIO timeouts in terms of data availability with respect to buffered acquisition, not hardware availability due to some hidden stuff going on under the hood.
-
Neat, I hadn't seen LVMark, but yes, it does the same thing.
Deferral updates of itself does nothing for my example, text will still paint out of bounds of the indicator. But deferral of updates, combined with some forced layout recalculation of the indicator, then enabling updates works and prevents text from appearing out of bounds. Kludgy though.
-
I put together a quick and dirty VI which takes some form of general markup and applies properties to the built in LabVIEW string controls. The results are usually pretty good, but every so often I see some weird rendering behavior. For example:
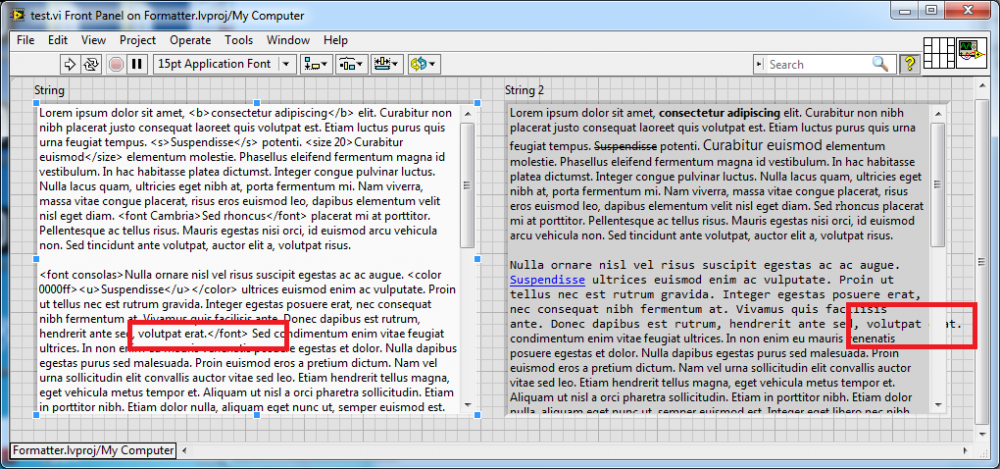
Note the "erat. Sed" text is missing, and worse the "erat" even overflows the bounds of the indicator. Has anyone ever played enough with formatting of the string indicators to know how to avoid this?
It would seem if I force the indicator to re-calculate layout after applying the formatting I can fix it, say for example hiding and re-showing scrollbars. But in that case the text that's out of bounds remains painted.
Some really rough code to reproduce is attached (2012). Results may vary depending on OS settings and font availability: Formatter.zip
-
Darren, thank you. I haven't tested it yet, but you likely just fixed the longest outstanding defect on one of our products. Like button x Inf.
-
1
-
-
I have an analog input task that I periodically read on-demand-- that is no buffering or timing. A task is created with DAQmx Create Channel (AI-Voltage-Basic).vi, when I need data, it is read using DAQmx Read (Analog 1D DBL NChan 1Samp).vi. Simple. I do the read with a zero timeout. To me this means since there's no timing/buffering happening the read operation should just do whatever it needs to read the data and return.
After a seemingly arbitrary amount of time though, I get a timeout error (-200474) from the read operation. This is not a "how do I fix this issue" post: I know it's really just a matter of putting a reasonable positive timeout on the operation. I'm more concerned with what causes the issue and if the returned error is appropriate.
So it seems that timeouts can happen even when not using buffered modes. The device is not being used for anything else, so it is not like it is busy with more demanding operations.
If you set timeout to 0, the VI tries once to read the requested samples and returns an error if it is unable to.I get this, and to me it makes perfect sense in buffered operations. If I'm operating at a fixed acquisition frequency and I try to read before the next acquisition, sure a timeout can happen. But when operating on-demand is the timeout error expected behavior?
If something is preventing the device from being able to read that data when requested I would expect error information to be returned regarding the problem, not a timeout error. This isn't a buffered operation, I'd like to know why you couldn't read the data when I asked! Maybe I'm just unlucky and every so often I try to read the value just as the internal registers are being updated on the device, who knows.
I guess for tasks like this I need to think of a timeout as to a limit on execution time, not a limit on waiting for available data. Just seems weird to me. This is the first time I've done unbuffered acquisition since...well since I first started playing with LabVIEW over a decade ago. Maybe I just need to reframe my thought process.
-
There are some private properties you can use in LabVIEW 2012 SP1 and later that allow you to set the focus row of a Listbox or Multicolumn Listbox programmatically. Whenever you programmatically change the value, if you also programmatically change the focus row, it should behave in the manner you're looking for. I had heard the behavior was fixed natively to the controls in LabVIEW 2013, but it appears to still be an issue that we have to workaround programmatically.
This VI (saved in LabVIEW 2012) contains the private properties you would need. Again, these properties were added in 2012 SP1, so they're not available in an earlier version.
Oh, and it was a top woman, not a top man, who added these private properties for us.

This behavior has irked me for some time. I also observe it in the Tree controls, do they have a similar private property?
-
I couldn't find MJEs interactive DOS thingy..
I think you're referring to http://lavag.org/topic/13486-printing-to-the-standard-output/#entry80999. I don't think it would be of help here, it just creates a console which can be used to print to...probably read from too, never tried that though. I've only ever used it for quick and dirty, "I need to dump a bunch of text to screen regularly and am too lazy to create a user interface" type of scenarios.
-
Well, host application is really just semantics. A LabVIEW exe requires the LabVIEW RTE to interpret what's inside. You can make similar arguments for "native" applications in windows, whether or not it's an actual runtime or just dependencies doesn't really matter in the end. Ever try to run visual studio compiled C++ executables on a fresh install of Windows that predates the compiler? Good luck with that unless you have an MSVS redistributable around. In the end it's just a hierarchy of dependencies, the only real difference is the exe has all the required info for the operating system to recognize it as something it can "execute".
Regardless, I want to get error feedback from this tool. When my application loads this code and executes it, I want to know if it was successful. I've already added a command line interpreter that recognizes the request to serialize an exit state to a file. This is really all I need. It's more straightforward though to be able to just park on the DLL call than to have to decide on a temp location, and wait for that temp file to be populated with information before continuing.
-
Indeed, that's exactly what we are doing by breaking out this code to a stand-alone component, be it a DLL or EXE. It will be self-contained with it's own versions of whatever it needs.
The DLL is nice in that it allows relatively easy passing of parameters between the new and legacy code. If we go an EXE route, we need to create some sort of wrapper to pass things out since we don't have access to stdout/errout or the exit code in LabVIEW (passing things in is easy via the command line).
-
The reason I used that instead of the native 2D picture control is because it has the Stretch, or Zoom feature that resizes images very nicely. LabVIEW's picture control does have the Zoom Factor but it makes the image look like crap.
I really wish the LabVIEW picture control would be improved. It scales vector based images just fine but does so horribly for raster content. When you look at performance considerations the opposite is true: it can handle huge raster images, but even a moderate amount of vector content absolutely kills any hope of having a fluid experience.
-
2
-
-
Valuable info, thanks.
This is coming up because of supporting legacy versions serialization code. A while ago we made a switch from a proprietary binary storage format to a database back end (wonder what that could be, Shaun?). I want to lock down our legacy code which manages the binary versions and the binary to database conversion. This will be a component build from fixed revisions from our source code repository. Since I'm literally pulling out code from our last iteration and building it to a stand-alone component, I can re-use our existing test cases to validate the code, and deem it working. We are now free to make changes to our database interface (how the actual VI calls are made, not the schema), because we don't need to worry about breaking the existing conversion code-- it is locked away in an independent component.
I had not thought about the different run-time engines, but that is a very good point. I definitely don't want to have to distribute multiple LabVIEW, MSVC, and SQLite redists, so I suppose this component would have to be recompiled in whatever flavor of run-times I'm using at the time. However the recompile would still be from legacy versions of our source code, and could be tested with legacy unit tests. Our core development would still be free from having to support the old API we were using in this legacy code.
To that effect I threw together a quick proof of principle. I made a DLL with an exported function which makes a call to a VI qualified as Shared.lvlib:Version.vi and returns the number. I made an EXE which loads the DLL and shows the return value, all the while making a call to a similarly named VI which it includes. The EXE and DLL do indeed each use their own version of Shared.lvlib:Version.vi and return different values. Success I think?
DLL Test.zip (LV2012SP1, built DLL and EXE included)
-
I've never built a DLL using LabVIEW before, but am starting to think this may be the way to go for a component I'm working on. However I have one concern where my google-fu is failing me and thought I'd lob this one over the fence since at least of the lava gurus here likely knows the answer.
Consider this situation:
My DLL is built and includes SharedLibrary.lvlib (version 1).
My EXE is built and includes SharedLibrary.lvlib (version 2).
That is both the DLL and EXE reference the same library, all be it incompatible versions. Each fully includes all the dependencies they need to run on their own. With respect to each library version, the namespaces are identical-- that is we don't have SharedLibraryVersion1.lvlib and SharedLibraryVersion2.lvlib, but two different versions of SharedLibrary.lvlib.
Now let's say my EXE needs to dynamically load my DLL: Do I have a problem? Am I going to run into any weird namespace collision issues? I would hope everything should be locked properly behind their respective boundaries, but...
If this is a problem it's no big deal, I could always change the DLL into another executable, but I'd rather not as it makes a bit of a mess of passing data in and out.
-
1
-
-
Wow, you two got way ahead of my ability to follow this thread, took me a while to catch up. Needless to say my playing about is way behind what you have been thinking about.
You Init. Then you Uninit. Then you take that same already-uninitialized pointer block and wire it into a Read or a Write. How does the Read or Write know that the pointer block has been deallocated and it should return an error? Screen shot 2013-07-12 at 10.37.50 PM.png
Screen shot 2013-07-12 at 10.37.50 PM.png
This is a very interesting problem. Well for me it is. While a DSCheckPtr call would help in that specific case, It wouldn't likely be robust if LabVIEW is in the habit of regularly recycling memory as might be done in a real application. The check is near useless if you don't check the pointer under some kind of lock-- there's a race condition because who is to say the pointer wasn't released after you check but before you operate on the pointer? It's easy to see if you do the check before entering the loop and have to do a significant wait, but even if you check it on every iteration there's still the possibility. Of the pointer being released between calls.
What if in every set of pointers has an additional sentinel pointer was allocated? The value in this sentinel would tell us if rest of the pointers were still usable. When uninitialize is done, all the pointers are released except the sentinel, which is instead is operated on to guard against the rest of the structure being used. However this causes a memory leak: we need someway to release this sentinel pointer. Is there a way to register a callback with LabVIEW such that when whatever VI hierarchy goes idle which started this whole mess, we can invoke some code to release the sentinel? I imagine registering sentinel pointers somewhere, and when the callback is invoked releasing them.
The issue of the pointer being released while a read/write is stuck in its polling loop also needs to be addressed. If someone splits a wire and manages to block a read/write call while uninit is called bad things will happen. We may have to build a lock into read/write that is shared with uninit. Don't panic, I don't mean a traditional LabVIEW lock-- I think we can do this with another pointer. Here's my logic. Say we have our private data as something like this (ignoring the buffer proper since it's not part of the discussion):class CBufferPointers{private: // Sentinel, guards the rest of the pointers. U8 *pSentinel; // Our read/write lock. Same lifetime as pSentinel. U8 *pLock; // Writer cursor U32 *pWCursor; // Reader cursors U32 *pRCursors; // Tracks the size of the pReaders array. I32 Readers;}Then I can see the read/write/uninit logic working something like this:
if (pSentinel == 0){ // None of the pointers are initialized, // set error out to a not a refnum or something similar.}else{ // Local constant on the block diagram U8 sentinel = 0; MoveBlock(&sentinel, pSentinel, 1) if (sentinel == 0) { // The cursor pointers have already been deallocated. // Return some error } else { do { // Local constant on the diagram U8 lock = 1; // Assert our lock while reading the existing state. SwapBlock(&lock, pLock, 1); // The loop condition ensures that we are asserting a new // lock by asserting that we have changed the value from // 0 to 1. If something else already set the lock to 1, we // just keep trying. } while (lock == 1); // Rest of read/write/uninit algorithm // When done we release our lock U8 lock = 0; MoveBlock(&lock, pLock, 1); }}Of course for any of that to work, we need atomic operations on the move/swap calls. Rolf's earlier statements worry me that we don't have that. Is there some low level function/instruction we have in LabVIEW that can be used to implement something like this? I've never delved so greedily in to the depths of LabVIEW before...
-
When you do Init, wire in an integer of the number of readers. Have the output be a single writer refnum and N reader refnums. If you make the modification to get rid of the First Call node and the feedback nodes and carry that state in the reader refnums, then you can't have an increase in the number of readers.
I have a half-implemented version that does something similar. It works by pre-allocating an array of reader cursors representing the positions of each reader. The array size represents the max number of registered readers. All the cursors start as negative indicating nothing is registered for that index. The writer init returns with no registered readers. Reader initialization/registration involves finding an available cursor (negative), setting it to a valid starting value (either zero or some offset depending on where in the lifecycle the writer is). This has forced init/release mechanisms to use a lock to ensure atomic operations on the cursor array to avoid race conditions while doing the read-write sequence but looping on the cursors during enqueue/dequeue operations can happen without a lock as in Shaun's examples. Releasing a reader involves setting it's cursor negative, allowing that cursor index to be reused if necessary.
-
mje: Yes, those functions are reentrant.
ShaunR: I'd like you to try a test to see how it impacts performance. I did some digging and interviews of compiler team. In the Read and the Write VIs, there are While Loops. Please add a Wait Ms primitive in each of those While Loops and wire it with a zero constant. Add it in a Flat Sequence Structure AFTER all the contents of the loop have executed, and do it unconditionally. See if that has any impact on throughput.
Thanks for the confirmation.
Regarding the yielding, I saw no measurable difference when I made this a similar modification earlier, though the tests were in a virtual environment.
-
I spent an hour or so last night starting to code my own solution and got as far as muddling with pointers for indexing then stopped for the night. It occurred to me while I was mulling the problem through my head are the memory manager calls re-entrant? If I'm going about working directly with pointers using functions such as DSNewPtr, DSNewPClr, MoveBlock, and DSDisposePtr much as Shaun did in an effort to circumvent the lock mechanisms behind DVRs and FGVs, is it even possible to have two MoveBlock calls executing at the same time? Obviously this demands that each call be made from a different thread and the CINs aren't configured to use the UI thread, but the documentation is pretty much headers only as far as I can tell and doesn't really indicate either way.
I'm hoping to quantify whether there are any gains to be made by leaving behind the DVR in favor of lower level memory management of the reader/writer indices. I'm still going to be keeping the buffer proper as a native LabVIEW implementation (DVR) since I see no other way to be able to store non-flat structures by poking about memory directly without invoking expensive operations like flattening/unflattening. My hypothesis any gains that may be had will be modest enough to not warrant the increased CPU load of polling the indexing loops.
Just after posting this I realized the re-entrant nature of MoveBlock is probably irrelevant if it is only being used for indexes. These bits of data are so small there's likely no measurable difference in practice if the calls were forced serial or not. Might be relevant if playing with larger structures, but as I said, I plan on keeping the buffer in native LabVIEW.
It will still be interesting to test my hypothesis though to see if dancing around the reference locking mechanism saves anything. Yes, I'm a scientist, hypothesis testing is what I do...
-
1
-
-
I think two issues are being conflated here. Everything AQ posted with respect to objects is of course correct. However regardless of the nature of an object's structure the data needs to be brought into some scope for it to be operated on. It's that scope that's causing the problem.
Using a global variable will demand copying the whole object structure before you can operate to get your local copy of the single buffer element.
Using a DVR or a FGV demands an implicit lock, either via the IPE required to operate on the DVR or the nature of a non-reentrant VI for the FGV. So while a class does not have any built in reference or exclusion mechanics, pulling that data into some useful scope such that it can be operated on does.
The same issue is what has prevented me from posting an example of how to pull a single element from a buffer without demanding a copy of the entire buffer or running through some sort of mutual exclusion lock. Short of using the memory manager functions as Shaun has already demonstrated I don't see how to do it. I know there are flaws with the memory manager method, I just don't see an alternative without inducing copies or locks.
-
2
-
-
However, because SpectrumData_TAG along with FAT, FAT2, GAG, STA and RDB are all DataRecords...
I think this may be your problem. I'd tackle it like so:
class SpectrumData{ public virtual DoSomething();}// Each type inherits from the SpectrumData classclass FAT : SpectrumData{ // Implement the must-override public DoSomething();}// Other implementations...class FAT2 : SpectrumData;class GAG : SpectrumData;class STA : SpectrumData;class RDB : SpectrumData;// Note no inheritanceclass SpectrumData_TAG{ SpectrumData Data; DoSomething();}SpectrumData_TAG::DoSomething(){ // The TAG class delegates to the appropriate implementation of the contained type. Data.DoSomething();}That is the TAG class wouldn't share the same ancestor as each individual type. I'm assuming there's a good reason you're looking to preserve this union-like behavior.
-
1
-
Force the use of class data accessors (Property or VI) by class members
in Object-Oriented Programming
Posted
For me I use accessors in all cases except where I'm making specific attempts to work in-place, often when manipulating large arrays or variants for example.
It goes without saying that most of my accessors are declared as inline such that there's no functional difference between the accessor and an unbundle proper (this is the default for VIs created via the project explorer's template).
I doubt there's a way to prevent using the bundling primitives.