

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
I don't use Git either, but I expect the only LabVIEW specific files that should be ignored are those listed in the original post. I also like Shaun's idea to ignore the various OS-specific database caches.
I agree with Jack about not excluding binaries. Some of my LabVIEW source code directly calls binaries that I've created in C++/C#. The C source is not part of these packages rather they just include the binaries that are produced from another package.
-
OK, a lot to handle here I'll do my best to parse this down into some matter of cohesive reply.
I mean if you can’t service the queue as fast as elements are added, then you’ll eventually run out of memory.
PS, if you recall this conversation we had, one can use a timeout in a way that is guaranteed to execute the desired code on time
James and I are on the same wavelength here-- I was referring to implementations like this. I will add however that these types of systems do not guarantee code to be executed in time. If a message arrives just prior to the timeout firing and processing the message takes longer than the time remaining, the code can execute late. Similarly a backlogged queue can cause lost executions. Even worse a busy OS can also cause lost executions. I've used mechanisms like this with the caveat of having code in place that can track when execution frames have been lost. In my experience this is very rare, but non-RT OSes are particularly notorious for just grabbing all available CPU in some situations. Invoking Windows authentication services (waking a lock state, remote desktop connections) are cases I see regularly where seconds can go without my sleeping tasks being serviced when I’d otherwise expect them to wake. If you do have the luxury of an RT OS, I’d argue there are better more deterministic ways of tackling this one but I don’t want to diverge too much.
1) Assertions of correctness. ...I've tried to make sure that no one can accidentally reintroduce the errors that the AF is designed to prevent (a slew of deadlocks, race conditions and failures-to-stop, documented elsewhere). "The queue works like this" is a critical part of those assertions.
I don’t have an answer for this. Any way of exposing an arbitrary transport layer would indeed necessitate that layer being exposed outside the Actor implementation and you’d lose the ability to make those assertions. I’m not criticizing; this is a very good reason to have the implementation the way it is. Thanks for laying it out.
4) Maximize Future Feature Options. The Priority Queue class is completely private specifically because it was an area that I expected to want to gut at some point ant put in something different.
Now that is very interesting. I was actually admiring your Priority Queue implementation as being quite elegant. I like how it falls back on native queues and how priority is mutated when a task is already waiting on the queue because at that point priority is irrelevant.
5) Paranoid about performance. Dynamic dispatching is fast on a desktop machine. Very low overhead. But I was writing a very low level framework. Every dispatch, every dynamic binding to a delegate, gets magnified when it is that deep in the code. I kept as much statically linked as possible, adding dynamic dispatching only when a use case required it.
I appreciate this, I just find it shocking to hear, especially in light of other languages and libraries that throw objects at everything, often when functions are by default dynamic/overridable. Granted this is why words like “sealed” come to play...
5) Auto Message Dropping Is A Bad Idea. There's a long discussion about message filtration in the http://ni.com/actorframework forum. It's generally a bad idea to try to make that happen with any sort of "in the queue" system for any sort of command system. The better mechanism is putting the filtration into the handler by using state in the receiver...
Indeed, I was never implying that things like filtration can’t be done in the AF using such mechanisms.
Designing an actor such that the message queue routinely gets backed up during normal operation creates the additional complexities you identified...
...but they must be addressed if your actor operates on the "job queue" principle.
Yes. I think where I diverge from Daklu and perhaps AQ is that if I’m going to have an Actor delegate tasks to a “job queue” subordinate, I might want to wish this subordinate to be another Actor. For these tasks (Actor or not) the very point of their implementation isn't to service their messages as quickly as possible but to use the queue as a message/command/whatever buffer.
6) Lack of use case for replacing the queues means lack of knowledge about the right way to add that option. Who is the expert about the type of communications queue? The sender? The receiver? Or the glue between them? MJE, you mention querying the actor object for which type of queue to use. Is that really the actor that should have the expertise? Perhaps Launch Actor.vi should have a "Queue Factory" input allowing the caller to specify what the comm link should be. Honestly, I don't know the right way to add it because no actual application that I looked at when modeling the AF had any need to replace the queue. What they generally needed instead was one type of queue instead of the three or four they were using (i.e. communications through a few queues, some events, a notifier or two, and some variables of various repute).That is an excellent point. I hadn’t considered it and I can’t argue it-- I redact my suggestion.
I don’t have an answer either. You mention a networking layer, which was one of the things I was thinking of. If I want to have an Actor that can be commanded through a network or locally without the TCP/IP stack the means of communication needs to be decided by the task that instantiates the Actor. Let’s complicate things even more by having a task connect to an Actor that’s already running rather than starting a new one up. Maybe you have multiple tasks communicating with an Actor, some operating in the same application instance, others remotely. Different transports would be required, so I completely agree it’s not the domain of the Actor to dictate. Maybe this is something you've already considered in these 4.2 and 4.3 versions you've mentioned, I can't say. The last version I've had the time to examine is the one shipping with 2012.Finally thank you everyone for keeping this civil. I really want to keep this constructive. I'm not trying to tear down the Actor Framework. It's a very solid way of handling asynchronous tasks. I really want to share what some of my perceived limitations of it are, and get at what others think. I'm not out to write "MJE's Actor Framework", but it would be irresponsible of me not to survey some of the design decisions in the AF to consider how these decisions scope relative to the flaws I see in my own framework I'm reconsidering.
-
Excellent feedback, thank you.
Lack of extendability and customizability. More generally, it forces me to adapt how I work to fit the tool instead of letting me adapt the tool to fit how I work.
Indeed. As soon as I find myself doing this I stop and instead ask, "Am I sure this is the right tool for the job?" Usually the answer is "No".
This is typically only an issue when your message handling loop also does all the processing required when the message is received. Unfortunately the command pattern kind of encourages that type of design. I think you can get around it but it's a pain.
My designs use option 5,
5. Delegate longer tasks to worker loops, which may or may not be subactors, so the queue doesn't back up.
I particularly second this. Actors should endeavor to read their mail promptly, and the message queue should not double as a job queue.
Well the act of delegating to a private subActor (or any private secondary asynchronous task) only hides the extra layer. The public Actor might indeed respond to the message on short order, but there's no getting around to the fact that actually acting on that message takes time. Ultimately if some sort of message filtering has to be done at any layer because it just doesn't make sense to process everything, you're back to the original argument. If I can't do stuff like this easily with an Actor and my Actors are just hollow shells for private non-Actor tasks, I might not see a benefit for even using the Actor Framework in these cases.
The opposite argument of it's the responsibility of the task generating the messages to throttle them at an appropriate rate doesn't help either, the throttling still needs to happen. It's also dangerous because it creates a type of coupling between the two tasks where the source of the messages needs to be aware of the approximate frequency with which it can send messages. Who is to say this frequency doesn't change as a function of implementation or worse, state?
Agreed, though I'd generalize it a bit and say an actor should be able to specify it's message transport whether or not it is a queue.
Absolutely. I suppose I got tripped up on semantics. I didn't mean to imply any transport mechanism had to be a queue. Ideally I think an Actor should be dealing with an abstracted interface where all it cares about is a method to get the next message.
...but I'd heavily question any actor that has a timeout on the dequeue. Actors shouldn't need a dequeue timeout to function correctly.
Interesting assertion, care to elaborate?
Before everything else: Have you looked at experimental version 4.3? Does the option to add actor proxies satisfy your use cases?
Nope. I'll give it a spin as soon as possible. Regarding the rest of your reply, I intend to follow up tonight. For now I'm out of time and can't address the post in its entirety as this pesky thing called "work" demands my attention. -
Yes, though that version posted is the first-generation. The second generation I created never became public due to some limitations I was never satisfied with mostly stemming from switching to a DVR based architecture. It was used quite successfully though by us internally.
-
Thanks, I had not come across that thread. Time to read...
-
I'm considering a third iteration of a messaging library we use at my company and I'm taking a close look at what I feel are the limitations of all the frameworks I use, including the Actor Framework. What are the perceived limitations? How can they be addressed? What are the implications of addressing them or not addressing them? I have a good laundry list for my own library, but since it's not widely used I'd like to focus on the Actor Framework in this post.
I'm wondering why the communication mechanism with an Actor is so locked down. As it stands the Message Priority Queue is completely sealed to the outside world since it's a private class of the Actor Framework library. The classes which are exposed, Message Enqueuer and Message Dequeuer, do not define a dynamic interface that can be extended. This seems entirely by design given how the classes are architected-- and it's one of the things that has resulted in a fair amount of resistance to me applying the AF wholesale to everything I do. Well that and there's a fair amount of inertia on projects which predate the AF.Consider a task where the act of responding to a message takes considerable time. Enough time that one worries about the communication queue backing up. I don't mean anything specific by "backing up" other than for whatever reason the programmer expects that it would be possible for messages deposited into the communication queue to go unanswered for an longer than expected amount of time. There are a few ways to tackle this.1) Prioritize. This seems already built into the AF by virtue of the priority queue so I won't elaborate on implementation. However prioritizing isn't always feasible, maybe the possibility of piling up low priority messages for example is prohibitive from a memory or latency perspective. Or what if the priority of a message can change as a function of its age?2) Timeouts. Upon receipt of a message the task only records some state information, then lets the message processing loop continue to spin with a zero or calculated timeout. When retrieving a message from the communication queue finally does produce a timeout, the expensive work is done and state info is updated which will trigger the next timeout calculation to produce a longer or indefinite value. I use this mechanism a lot with UI related tasks but it can prove useful for interacting with hardware among other things.3) Drop messages when dequeuing. Maybe my task only cares about the latest message of a given class, so when a task gets one of these messages during processing it peeks at the next message in the communication queue and discards messages until the we have the last of the series of messages of this class. This can minimize the latency problem but may still allow a significant back up of the communication queue. The backup of the queue might be desired, for example if deciding whether to discard messages depends on state but if your goal was to minimize the backup dropping when dequeuing might not work.4) Drop messages when enqueuing. Similar to the previous maybe our task only cares about the latest message of a given class, but it can say with certainty that this behavior is state invariant. In that case during enqueuing the previous message in the communication queue is peeked at and discarded it if it's an instance of the same class before enqueuing the new message.These items aren't exhaustive but they frame the problem I've had with the AF-- how do we extend the relationship between an Actor and its Queues?I'd argue one of the things we ought to be able to do is have an Actor specify an implementation of the Queue it wishes to use. As it stands the programmer can't without a significant investment-- queues are statically instantiated in Actor.vi, which is statically executed from Launch Actor.vi, and the enqueue/dequeue VIs are also static. Bummer. Basically to do any of this you're redefining what an Actor is. Seems like a good time to consider things like this though since I'm planning iterating an entire framework.How would I do this? Tough to say, at first glance Actor.vi is already supplied with an Actor object so why couldn't it call a dynamic dispatch method that returns a Message Priority Queue rather than statically creating one? The default implementation of the dynamic method could simply call Obtain Priority Queue.vi as is already done, but it would allow an Actor's override to return an extended Queue class if it desired-- assuming the queue classes are made to have dynamic interfaces themselves. Allowing an actor to determine its timeout for dequeueing would also be nice.I'm not saying these changes are required to do any of the behaviors I've outlined above, adding another layer of non-Actor asynchronicity can serve to get reasonably equivalent behavior into the existing AF in most cases. However the need to do this seems inelegant to me compared to allowing this behavior to be defined through inheritance and can beg the question if the original task even needs to be an Actor in this case.The argument can also be made that why should and Actor care about the communication queue? All an Actor cares about is protecting the queue, and it does so by only exposing an Enqueuer not the raw queue. If a task is using an Actor and gums up the queue with spam by abusing the Enqueuer that's its own fault and it should be the responsibility of the owning task to make sure this doesn't happen. This is a valid premise and I'm not arguing against it.All for now, I'm just thinking out loud...-
 1
1
-
-
I agree with the general trend: handle your ini stuff in the application bot the installer. Mutate of create it when needed. A side effect though is all of my apps leave configuration data in profile folders since the uninstaller never checks for what the app has left behind.
-
I'm curious is this a LV2012 code base? I have yet to port the code referred to in the post you linked to 2012 so I don't know if the problem persists (it did in 2011 SP1).
-
Heh, looking over my post not sure what I was thinking-- the constant is the message object which does of course have a value. It's the value that's stored that would be empty. Brings up another question though why would a bad value matter if I'm overwriting it in the bundle operation?
-
So this was a really fun one to debug.
Background: this is my first actor framework project and I was having an issue where some of my messages would crash the LabVIEW IDE with an access violation. Four hours and several red herrings later, I present to you the offending code:
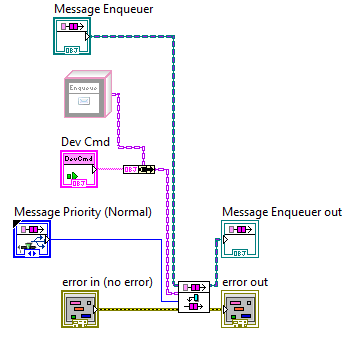
This is a simple Enqueue Message VI created by the stock Actor Framework Message Maker in LabVIEW 2012, and as far as I can tell has never seen any manual edits. I mean seriously-- if I had ever touched it no way the diagram would be that messy! The VI shouldn't be foreign to anyone who works with the AF except look carefully at the "DevCmd" (Device Command) object on the block diagram. Somehow that constant has a non-default value. Which is really interesting because the class in question contains an empty private data cluster and it always has. I don't believe the Device Command class has seen any edits either, in fact the class is essentially an interface as it has no state data and only defines a single dynamic dispatch method which is a no-op. Classes derived from Device Command define state and behavior appropriate to whatever that particular command is trying to do.
I have no idea what kind of non-default data might be in an empty object, but there you have it. Anyways, that message is used a lot in my application as ultimately the Actor method invoked by the Message's Do.vi forwards the Device Command to an asynchronous non-Actor task, and there are several specific Device Command implementations. Sure enough, any Device Command I tried to send would crash out with the access violation because of that Send Message VI.
Other interesting things included if I made a selection on the block diagram including the offending constant, I couldn't execute cut/copy commands. Couldn't create VI snippets either.
Anyways, deleting the constant and replacing it solved everything:
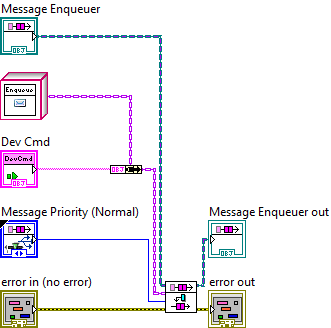
I still have no idea how that VI got the way it was. One possibility is the Device Command class is private. I'm wondering if the message maker gets tripped up by this? When the message was originally created, the class was broken until I pulled the message class into scope of the containing library. Perhaps I should have checked the block diagrams?
-
2
-
-
Negative, I could not get a version which did not produce copies-- using the base project above I always ended up with 400 MB of data space on the Test.vi after running.
To be fair though, I haven't given it much thought. I'm reworking my framework because testing for exact classes is in no conceivable way the right way of doing things. Especially since this is the second time the same flaw has come up, it's time to refactor.
-
I've noticed the text only gets pixilated like that when the image goes through a vector format. My guess is when this happens the underlying API for the vectors don't support text rotation so LabVIEW renders it (horribly) as an image. The only work around I've found is to use intermediate raster formats. I haven't looked at your code though so I don't know if that's possible in your case, but perhaps you could capture a bitmap and print that?
-
Hah! That is too funny. And looking back at that thread I'm running back to the same flaw in the same library I ran into a year ago. I guess you can say it never got fixed. That's the thing about "don't do it right, do it now" solutions-- they keep coming back to bite you.
That's it, fool me twice. Time to fix that framework, testing for class equivalence never was the right way to do it anyway.
-
Nice investigation, Daklu. I bet this is related to that trick AQ posted some time ago using sequential casting primitives which eventually landed in the Actor Framework templates. I'll do some digging and try some tweaks next time I'm at a workstation.
-
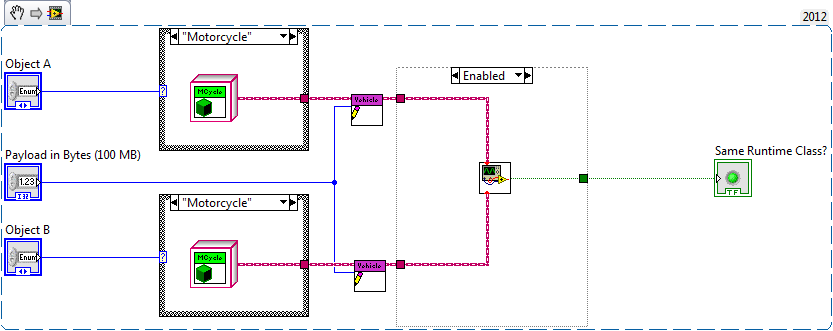
I have a case where I need to determine at run-time if two objects are of the same class. There's obviously no built in way to do this and a quick search turns up nothing, so here's what I came up with:
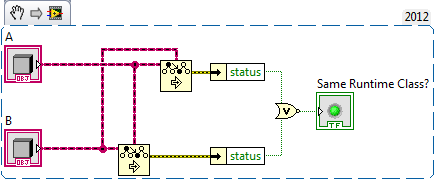
This isn't much of big deal, but when I was testing it I wanted to make sure the VI didn't produce data copies due to the wire splits, so I created a test where I give A and B a data payload. The good news is it seems the VI doesn't produce any data copies. The bad news is my test VI has double the memory usage I expected, so I'm missing some fundamental understanding of how buffers are working here.
Attached is the sample project. As configured, two Vehicle objects are created (be it a Vehicle proper or any of three distinct Vehicle implementations), each is loaded with a 100 MB payload. After running the Test.vi uses 400 MB of data space. Any one have an idea why? None of the objects are being sent to indicators so I'm not looking at buffers related to the UI.
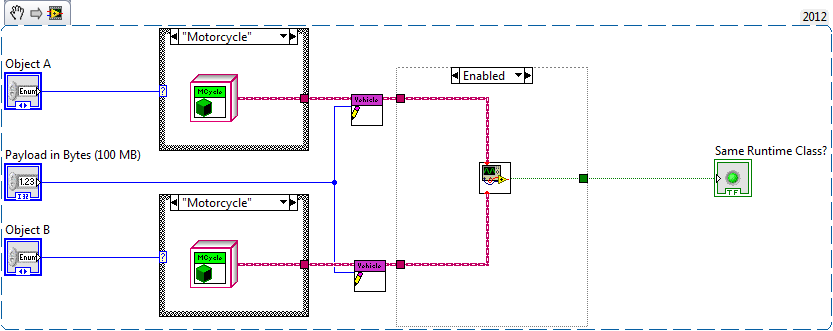
A few comments: If LabVIEW is creating copies at the coercion of the wires to Same Runtime Class.vi I'd expect those copies to vanish if the empty subdiagram is enabled, but this does not happen. If you just flat out delete the subdiagram the VI uses no memory because LabVIEW seems to be smart enough to realize you never need the buffer data.
-
Truth be told I find the op-code based nature of the picture to control to be more of a burden when all I want to do is show the image in a picture control. Large pictures-- that is pictures with a large number of operations, not necessarily large pixel size-- display horribly slow in the picture control. Most of my applications involve generating an op-code picture string, then converting it to a bitmap and back to a picture string so the picture data only contains raster data. The raster data renders much quicker.
However the opcodes are great for the odd case when you want to play with zoom levels on the picture control as the opcode based picture strings maintain fidelity as you zoom in. Similarly if you want to export the image to vector enabled meta-formats like EMF.
-
Yeah, the 2D picture control is definitely not aging well. At least it handles primitive shapes as op-codes so it is "vector like" so long as you don't go mutating the picture "string" to other formats.
-
Virtual machines are invaluable for this in my opinion. Bear in mind you can install any version of Windows that predates 8 without a license key and it will be fully functional for 30 days. Perfect for sorting these issues out. We use VirtualBox for this, but there are of course other options.
-
I don't have a recommendation for your specific issue, but if you just select all the additional installers does everything work? How about if you manually install the full runtime engine yourself?
I ran into a similar issue with the 64 bit IDE where the installer it created was missing some critical component that broke my executable. After contacting an application engineer at NI the only solution was to use a third party installer which installs the the entire runtime as there was no way to configure the IDE to include the component- you might have to do the same, or alternatively instruct users to install the full RTE themselves.
I should add that if you can narrow down what's going on, please contact NI so they can log the issue and address it in future releases.
-
1
-
-
- Addmission to the summit is free for CLAs.
You got me excited for a second because that sentence made me think perhaps one could attend without being a CLA. Alas, 'tis not so.
I'm still split on what to think about the summit. I completely understand wanting to up the ante with respect to who can attend otherwise the summit could blow up into something way out of hand, but part of me also is disgusted at the closed nature of the summit. I firmly believe it's not in anyone's best interest to keep these good ideas sealed behind an ivory tower.
To be clear I'm not a CLA and I don't ever see myself getting sponsorship to obtain one. I'm not speaking out of bitterness of not being able to attend, I just honestly think more open discussions would prove to be more constructive.
- Addmission to the summit is free for CLAs.
-
Note that we've discussed such a feature before and I hope that should it ever see the light of day that it would not be restricted to only classes. Think generic VIs which perform operations on arbitrary array types etc.R&D prototyped but never released generic VIs (loathe the name because the terminology is way too overloaded, but I'll use it for now). We need a way that you would put a placeholder in the private data control and then in your project specify "I am using a new class which is the same as my generic class but with that placeholder filled in with ". -
Subpanels.Problem is how are you going to put the relevant controls/indicators into the page? Hmmm... I don't think you can. -
Wait, I missed that. Are you saying you think overriding protected accessors is bad? I completely agree community data is mostly bad, but there several use cases I've adopted which come to mind for protected:
- Derivative classes need to apply more restrictive bounds checking to the write methods.
- I also have a derivative classes which implements a Read Timeout() override such that in certain states it will return a calculated value rather than the field stored by the parent state-- it needs to get something done after so many seconds and if the parent is returning a longer than necessary timeout, it returns the appropriate smaller value.
- Also some of my accessors are really just VIs that return constant values. While these aren't strictly accessors since the default implementations return VI scoped static data, the intention is derivative classes might wish to return state fields or data calculated from state.
-
Playing devil's advocate here, what use would this be that couldn't be achieved through inserting step(s) in the inheritance tree?
The only problem I see is to use inheritance you'd potentially have a chain of relatively simple, unrelated, and nonsensical classes where the only use is to restrict access to state data. Generally speaking I use object oriented design to take advantage of polymorphism, not for such esoteric shenanigans.
Also let me be clear, I don't think using inheritance to solve this problem is a good design, I'm just asking if it would be a functional equivalent. Solving this issue with inheritance brings along quite a bit of baggage in my opinion.
Network Discovery via UDP
in Remote Control, Monitoring and the Internet
Posted
I have a rather amateurish question here, but frankly this is the first time I've ever had to deal with networking so in this respect, I am the amateur.
I'm writing an application which will be communicating with deployed targets. The network topology is the client computer is connected to a switch as are one or more targets. Both the client and targets have obtained DHCP addresses from a server by virtue of another connection to the switch. I'm trying to avoid any hard-coded IPs, and similarly don't want to have to burden the user with actually knowing the IPs of all the computers involved, so was trying to do some basic network discovery.
So let's have a loop spinning on each target which responds to UDP discovery requests:
It sits and waits for a "Hello?" broadcast, and when it gets one, responds with a hearty "Hello!". Yes of course it will ultimately get more sophisticated than that, but let's learn to crawl before we walk, hmm?
Now the client computer will come along and send out a UDP "Hello?" broadcast and wait for a bit to see who's out there.
This works great when I test them locally on my client machine. I'll note for "Local Port" I'm using a zero value such that the OS just grabs anything that's available. The "Remote Port" in the bottom bit of code is set up to match the "Port" setting for the top bit of code. But when I put the target logic on one of my RT targets, I get nothing. When I debug the target VI it doesn't get the broadcast. So there's something basic about UDP broadcasting I'm not quite getting. Anyone care to offer advice to a noob?