

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
One complicating factor is as far as I can tell you can't get LabVIEW to scan whitespace as a valid string using the %s notation. Hence using %5s to scan " 0.00" will work (note the leading space), but the pure whitespace string " " will not as the scan primitive seems to treat whitespace as insignificant. So you'll likely need to get more specific and use character classes, for example %5[a-zA-Z0-9. ] (also note the space character in the class). Someone please correct me if I'm wrong about this, but I've never figured another way while sticking to the scan primitive (I'm aware a regex can do the trick, but that's not the topic at hand).
The other thing to wrap your head around is LabVIEW does not accept the %* syntax, so you'll need to replace your delimiters with valid constants. Your example strings all have spaces as delimiters, perhaps you can just use a "s"?
Other than that, shoneil covered everything else I believe.
-
 1
1
-
-
My history with xcontrols is very similar to Jack's. Basically went full circle from "why would anyone ever use this?" to "Ok, this is pretty cool" then having learned of some key limitations or challenges I could not overcome without ditching the xcontrol idea completely, I'm now squarely in the "just no" category.
If I want a modular control, I now wrap it in a class and give it a method to attach it to a subpanel or other UI element it needs to function. Xcontrols are just too limiting and completely non-extensible. I will not be burned again by sinking my time into developing any more. I realize their uses, but I just don't think it's worth it even if you have a perfect use case because who knows what that use case will evolve into...
Jack hit many of the obstacles I ran into, and if I recall I also found quite a performance problem as well. I seem to remember a side by side comparison where I had identical code/functionality working in an xcontrol and a normal async vi + loop and the resulting xcontrol behavior was terrible due to what I can only assume is the overhead involved with whatever voodoo is done behind the scenes to wake that wannabe-but-totally-isn't-asynchronous facade.
-
No. No. No.
-
Nothing elaborate really. For this specific problem you can flip things around to delegate ownership of any pages to implementing classes, and have the parent class define a method that returns any pages which get operated on. For example Dialog:GetConfigPages returns an array of pages which is called by any Dialog method that needs those pages. The Dialog implementation can return any pages which might always be there, or an empty array by default. Any implementing method appends it's own pages to those returned by its parent.
However I don't think this suggestion is any more "correct" than your implementation-- I've certainly used both models.
-
1
-
-
Ah right, there's no path assumption. I still think a class qualified with a library name would cause issue though?
Maybe using a traditional dynamic dispatch method to query the class to see if it supports the option?
-
I can't say I use the quit/exit LabVIEW primitive anymore, but I do have 50 MB executables which can take a long time to shut down. This application can be called upon to manage data sets hundreds of GB in size resulting with a memory footprint of a few GB for tracking things like indices and caches.
I've observed this application take a minute to unload. I can watch the task manager tick down the memory footprint at a rate of about 100 MB/s as things get cleaned up. This is on my workstation grade system with 20 GB of RAM for an application that takes perhaps 1-4 GB of memory depending on data load. Large analyses on resource starved systems can take several minutes to unwind if page files get involved.
To some extent I also think its related to the size of the VI hierarchy-- size as in number of VIs, not number of bytes. I've written very simple "quick and dirty" applications with perhaps 10 VIs which can chew up pretty impressive memory footprints if you point them at sufficiently sized data sets, and when terminating these applications are pretty snappy. By contrast the 50 MB application with a sizable hierarchy can still take 20 seconds to unload even if it has no real memory load beyond what is required to run the application. I expect just as there's overhead involved with opening each VI when starting the application, there's something going on with each VI when terminating.
-
Is this in a scripting context?
The code you have makes a few assumptions, namely that the class is in the same folder as its VIs, and that all the classes aren't qualified by library names.
-
In my opinion there's nothing inherently wrong about using the to more specific class primitive in this situation. There definitely other ways to tackle this but let's stick with your original implementation.
Be aware that since the base class likely manages access to the Channel Config Dialog Pages at the Dialog Page level, you have to be careful about assuming you can say all the contained Dialog Pages are in fact Channel Config Dialog Pages. Even if the accessor is protected, you have to make sure that all access to the contained Dialog Pages is protected and that none of the public methods of the parent can set Dialog Pages. If this seems inherently fragile, it is, but it isn't necessarily wrong. Just be mindful of error handling.
I'd also suggest ditching the property node in favor of an accessor which is more modeled after the polymorphic primitives that LabVIEW uses where they have a "type" input. This is a prime candidate for the preserve run-time class primitive:
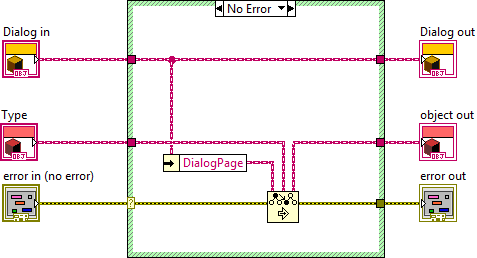
Why would I do this? It puts the type checking all in one place so you don't need to do it each time you want to access your pages. It also is very handy for coding because the wire type changes dynamically at edit time depending on what you wire to the type input:
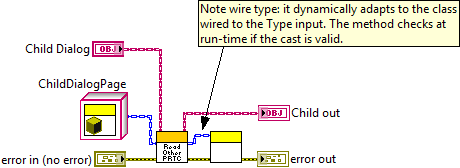
-
1
-
-
There are multiple "correct" ways to check for near equality and perhaps the implementation as it stands is not what NI wanted to endorse as the way of doing things. As in many things, often the best implementation depends on context. Just my guess.
I think it's neat the primitive exists, but don't see it as a major loss that the functionality isn't on the native palette.
-
This has happened to me often enough I'm paranoid about it. I think the use of it in a class is a red herring as I've seen my constants on the block diagram revert as well. I comment my constants now that way when it comes time to do a build, I can do a find all instances and "quickly" compare notes.
I've also stopped using enums in a lot of situations. I tend to have more very simple classes now...
-
I've mentioned previously (post #13), and AQ brought up again (post #132: It may not be proper to even specify the function name (i.e. one might have "Write Boolean.vi" and another have "Write Double.vi")), that this "Must Implement" feature is gated by an inheritance relationship defined through a GUID private to the class rather than filenaming conventions of the method; this is evidenced with the desire for StringMessage.lvclass:Create StringMessage.vi to implement Message.lvclass:Create Message.vi yet not have its same filename.
I've done my best to follow this topic, even if I haven't contributed lately. This is mostly because my original confusion/objection still stands and haven't really been able to think of a good way to explain my confusion. Your lapdog example triggered something though...
If StringMessage.lvclass:Create StringMessage.vi implements (in your must-implement sense, not the traditional override or interface sense*) Message.lvclass:Create Message.vi, especially to the point where Message.lvclass:Create Message.vi method does not define a connector pane or the StringMessage.lvclass:Create StringMessage.vi changes the connector pane I just don't see how the relationship between the two is at all relevant to someone writing code.
Code which operates only on the Message interface can not call the StringMessage "implementation" because the relationship is not dynamic dispatch and there is no way to link to the mutating connector pane: if I only know about Create Message, I can't wire up a string to Create StringMessage because I don't know it needs a string! Maybe I can't wire anything up to it because the original method didn't even define a connector pane.
If I do have knowledge of the StringMessage class, I can already just drop the CreateStringMessage call right on my block diagram creating the static link, I have no need for this pre-defined relationship.
The only use I can see for something like this is a linkage which might be useful for something like palette building where Message would define a CreateMessage as must-implement and place it on it's palette. Then when you bring up a context menu on an input the correct implementation would automatically be on the palette, or if the menu is brought up with no context, the method would be invalid if it does not have a default implementation. Is this what you're after? Because I still can't see any use case for this on the actual block diagram which isn't already covered by just dropping the right statically linked VI. It seems like it would be really a creative trick for the IDE to play...
-
I don't think expecting a quick turnaround is the right way to frame the issue. Quite simply, there is rarely only one way to do something and if you find a bug, chances are you can work around it by tackling the problem with an alternate strategy.
But to answer your question, yes, I've found bugs which have been reported, some where platform specific. In the end I can't say how long it took to fix any of them if they ever were fixed at all-- I just took a step back and did things a different way. Maybe not the way I wanted to do it but in the end all that matters is getting the task done, not how it's done.
-
Confirmed. I remember in the past with things like this I've serialized them as strings. In fact I believe a DAQmx Name inherits from the native string type because you can wire up a DAQmx Name to anything that uses strings and vice versa.
I believe the logic is Names are system specific so are treated somewhat like refnums? Though it doesn't make much sense why they'd serialize the name to XML but not deserialize it. Who knows.
Anyways chances are your real use-case involves a class which hangs onto other state data which also might not need to be serializled, stuff like refnums, cached data, etc. When depending on native LabVIEW serialization-- which is very rare for me-- I often define a private data type/class which I create to hold only the information that needs to be serialized then throw that construct at the LabVIEW primitives. In your case I'd swap out the Name with a string.
-
1
-
-
Hah, no worries. I love these types of problems. Pure logic.
Non-contiguous strings exist, just not in LabVIEW

I figured you had a good reason to use a regex because as it stood a regex was not the best way to do it: scanning would be faster.
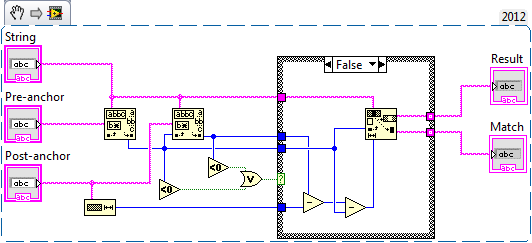
You have an interesting problem though in that you want to replace and match at the same time, and apparently globally.
-
By giving up I meant giving up on fixing that post by the way.
Anyways, you're not going to be able to do it with the match primitive alone. It won't make a new string for you, which is what you need if you want to get the actual "The quick brown fox jumped over the dog" out of the match. The S&R would do it, but then you won't get the match. If you add some extra logic though, you can do it.
I hope I got your examples right, my LabVIEW stopped accepting snippets for some reason, so I rolled this one from scratch.
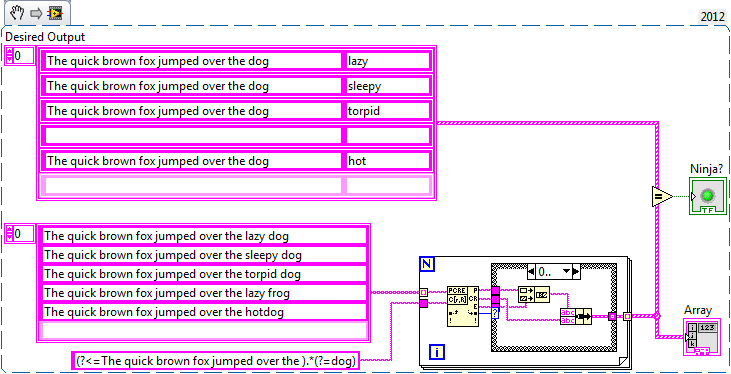
Other case is empty by the way, in case the snippets I produce are as defective as my ability to read them. Basically you need to construct the final string yourself.
-
[blockquote class=ipsBlockquote data-author=JackDunaway data-cid=102091 data-time=1363301998]<p>
What I'm really interested in doing is returning the original input string as the match, <em class='bbc'>minus</em> the submatch. Figure this out, and then we can fly around on vines saving days :-)</p>
<br />
Oh, I misread. Yes, the look ahead/behind are what you want.<br />
<br />
<span style='font-family: courier new', courier, monospace'>(?<=The quick brown fox jumped over the ).*(?=dog)</span><br />
<br />
Using the S&R in regex mode will get you the string you want, but the match primitive won't since the whole point of the match is not to create new strings but to only return substrings. You could still use the match though if you concatenate the before/after substrings.
Ok, I give up. My phone completely screwed that up:
(?<=The quick brown fox jumped over the ).*(?=dog)
If that doesn't work, I give up.
-
Yeah, S&R will be way faster. But you asked...
Don't forget the * and + operators are greedy, they will match as long of a string as possible. So a simple "The quick brown fox jumped over the (.*)dog" will do the trick. Substitute + for * if you want to require at least 1 character, or use the {m,n} syntax if you have other length restrictions.
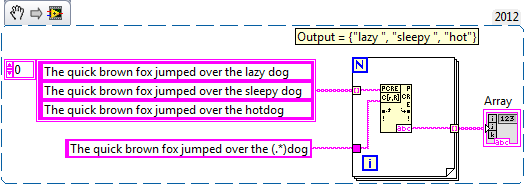

-
Do you mean the dichotomy between a command and a request?
Yes, that's what I was referring to. I won't go into detail how I think an Actor doesn't satisfy a command pattern only because there seems to be a good consensus on that. However I don't really believe an Actor is simply a request based system either. I don't really have time to rebut this point today though (if it needs rebuttal). Similar to how Shaun thinks the framework blurs the line between messages and processes, I don't really see the AF as laying on either end of the command-request spectrum.
If malicious code is a concern you might be able to override Actor Core and test the messages when they arrive, discarding any messages that you did not put on your white list. Or just don't ever expose the Enqueuer and wrap all message sends in actor methods. (i.e. OriginalActor.SendGetPathMsg) I've pretty much decided that if someone has enough access to the source code or runtime environment where they're able to inject malicious code, I've got far bigger problems that hardening the actor framework of choice won't solve.Malicious code-- whether the maliciousness is intentional or not-- would be a concern for applications designed to load external components at run-time (plug-ins etc). Basically at this point I'm not sure I'd want to expose any Actors Enqueuers directly through an interface external components would be able to interact with.
Since the Enqueuer is sealed off and an Actor demands that overrides of Actor Core.vi call their parent implementation, if I choose to expose the Enqueuer I have absolutely no way of restricting which messages could be sent to the Actor and which Messages get acted on.
Now this isn't an insurmountable problem: encapsulate the Enqueuer in yet another layer which provides an interface external components use to interact with. The implementation simply delegates to the Actor by firing off a set of corresponding privately scoped messages down the Enqueuer.
-
Indeed, that was one of the first things I tried to resolve the issue. Flushing had no measurable effect as far as I recall. The hardware for this project has since been disassembled so no further testing can be done.
-
To dredge this up again:
An actor receiving requests is generally in charge of its health and destiny; an actor sent commands is subject to DoS attacks or other hazards from external sources, whether incidental or malicious.
A command makes the sender responsible for knowing whether the receiver can process the message without going into some unexpected state. In the context of the entire system's operation, yes, the sender needs to know when it should send a particular message to a particular receiver, but it should never have to worry about breaking the receiver because it sent a message when it shouldn't have. (Like I said, lots of gray between actor and non-actor.)
I wasn't sure I was buying into this over the last week or two. I completely get the difference but I'm not convinced the dichotomy is relevant to the Actor Framework because depending on which relationships you're looking at (Actor-Message, Actor-Queue) I don't see an Actor living at either end of the spectrum. Depending on how many layers of the onion you peel back, I can imagine looking either perspective.
I've also been thinking about the relationship between Actors and their Messages and today I came up with something which sort of blew my mind. Maybe this is obvious to those of you who have been working with the AF for a while but to me this was a surprise that I could do this.
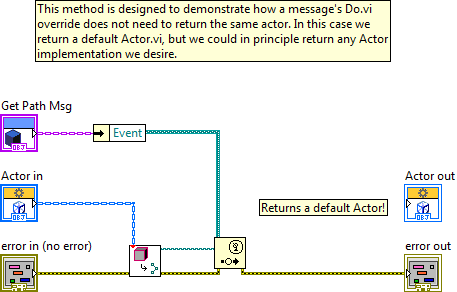
This is an override of a Message Do.vi method I made as an example. Note it does not return the same Actor supplied as in input to the output. The Message has effectively switched out which Actor is spinning in the Actor Core.vi loop. To me this completely flies in the face of having an Actor be in charge of its destiny and obliterates the idea of sending requests to an actor. I can chop that Actor's head off whenever I please.
All I need to do is send a malicious Message to a spinning Actor and I can completely kill it. Can you even contain this behavior if you start working with a plug-in architecture? Without digging too deep I think this stems from the fact that the main Actor Core.vi doesn't enforce the Dynamic Dispatch to the output terminal and would seem to be a conscious design decision.
Sample code attached. Open the Test.vi in the root folder to see a functioning example. Made with the stock AF shipping with LV 2012.
-
1
-
-
Well I guess you could cast your class to a more generic class (within the 'Read Trip' implementation of the child) and then call the parent class implementation of your 'Read Trip' method.
No. Calling a dynamic dispatch will always call the most specific implementation of the method available for an object regardless of the wire type, so casting the wire to a more generic class does not change the VI which gets called at run-time. The only way to call a parent implementation of a dynamic dispatch if from within the method itself via the Call Parent Method primitive, at which point the next most specific implementation gets called. There's no way to skip implementations by design.
-
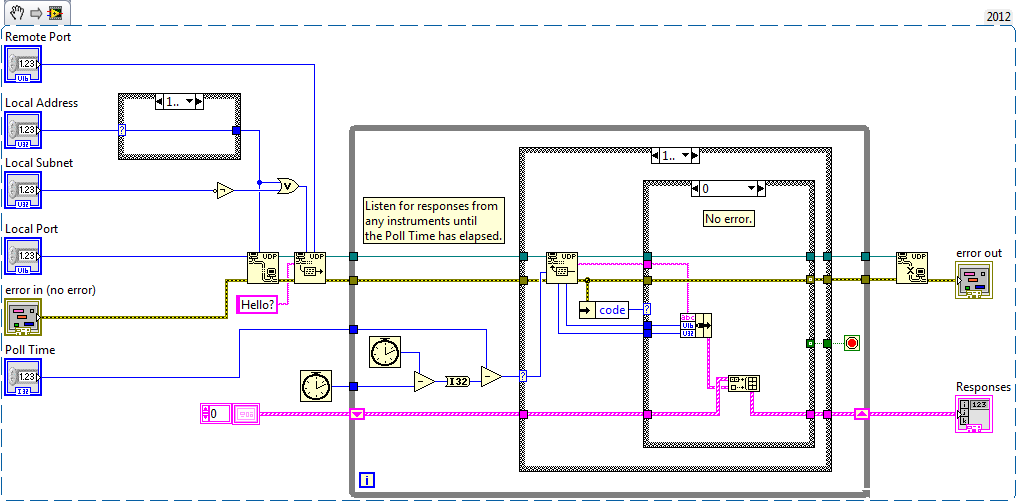
Just getting into the RFC now:
The reason TWO reserved ports are used, is to avoid 'waking up' and scheduling the BOOTP server daemons, when a bootreply must be broadcast to a client.Since my replies are never going to be broadcasts it's probably excessive to use two ports.
-
So 255.255.255.255 is only a good address for localhost-type UDP communication then?
I'm unclear on this. I've seen reference to 255.255.255.255 being also used as a "down the wire" broadcast address for example when a machine might not have an address. So the 255.255.255.255 address likely makes it past the adapter but everything I've seen so far implies the broadcast stops as soon as it hits a router. I'm going on the assumption by "router" the literature basically means any network hardware beyond an adapter since my initial test failed as soon as the devices were separated by a switch, but this is where my network knowledge starts to wear thin.
To all, is it "ok" to listen for replies on the same port as the initial broadcast? The RFC uses distinct broadcast and listening ports, I'm wondering if I should do the same?
-
I'm not 100% familiar with UDP, but I'm wondering about the IP address your client is writing to and whether you're wanting to write to a multicast address...
Cheers Brian, this put me on the right path. It turns out 255.255.255.255 is a valid UDP broadcast address, but the datagram won't make it beyond the local network, that is it won't make it past the network adapter. So not very useful for most situations. The correct way to do this is to broadcast to an address masked with the compliment of the subnet the adapter is operating on:
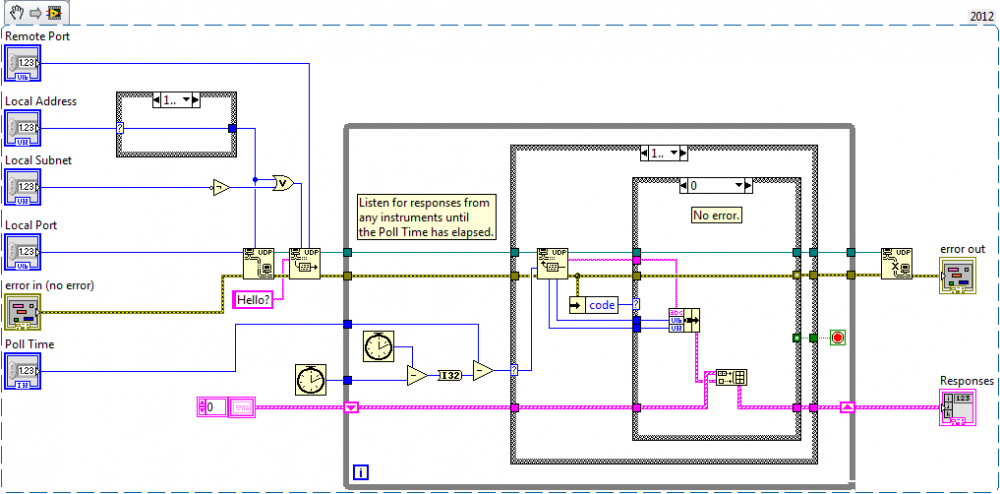
Works like charm.
Waveform chart X scale not matching time correctly
in Application Design & Architecture
Posted
The time passed problem is because you're converting a double precision number back to a timestamp. When you do this you're using the double as the seconds elapsed since the epoch and will result in an absolute time. Since it's absolute things like timezone and daylight savings come into play-- you see +1 hr in Switzerland, but on the east coast USA I see +7 hours. What you probably want to do is just keep the difference as a double and configure your indicator to display as relative time rather than a raw numeric.
As for the x-axis wonkiness, I don't know. I've had issues with charts which use time as an axis and have never figured them out either.