mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by mje
-
 Following the instructions I get a non-executable VI when the exe is created, but I see where the example is going. Ultimately, it's the same architecture, only using a packed library instead of loose files. Two things spring to mind which would prevent me from using it: As we've both pointed out, copies of the interface are created in every packed library. For a simple class, this is not a big deal, but if the interface is part of a larger hierarchy, this can get wild pretty darn quickly. It's a packed library, there's no way I'm going anywhere near them until the implementation has matured way more than it is now. I created one out of my most common reuse library as soon as I got LV2010, and trying to use the packed library resulted in LabVIEW rendering so poorly the IDE was not useable. I share your thoughts, I have no idea how lvlibp's got out the door in the condition they're in. They seem like a really good idea, they should have been left in the oven for another year. I completely understand your desire to have every plug-in as a single file: it's clean and simple as can be to distribute.
Following the instructions I get a non-executable VI when the exe is created, but I see where the example is going. Ultimately, it's the same architecture, only using a packed library instead of loose files. Two things spring to mind which would prevent me from using it: As we've both pointed out, copies of the interface are created in every packed library. For a simple class, this is not a big deal, but if the interface is part of a larger hierarchy, this can get wild pretty darn quickly. It's a packed library, there's no way I'm going anywhere near them until the implementation has matured way more than it is now. I created one out of my most common reuse library as soon as I got LV2010, and trying to use the packed library resulted in LabVIEW rendering so poorly the IDE was not useable. I share your thoughts, I have no idea how lvlibp's got out the door in the condition they're in. They seem like a really good idea, they should have been left in the oven for another year. I completely understand your desire to have every plug-in as a single file: it's clean and simple as can be to distribute. -
Wow. That was...easy. I can't believe I never noticed that property was returning different bounds than the All Monitors property. Thanks. I'm kind of embarrassed about that one now!
-
I have an application which displays floating tooltip information via VI I hide/show/move as required, sort of like this: Problem being that the taskbar tends to hide the floating window. I can bound the floating VI's position to be entirely in a given monitor, but that doesn't seem to help me with things like the taskbar. Is there a way to determine the workable area I have on a monitor? I'd like to keep it native, but if someone knows the right Win32/.NET calls to make, that could work as well (I haven't done any searching on the MSDN yet). I could bound the floating box to be inside the bounds of the owning VI, but I'd rather not do that. The application's workspace is made up of several windows, so overlapping with other windows is to be expected, I just want to make sure the tooltip is readable. Regards, -m

-
Last time I did this was back in LabVIEW 8 (?). It was actually out of necessity then, since VIs namespacing was different (if it existed at all?) and if you had dynamic dispatches, you ended up with a hierarchy of identically named VIs which couldn't be compiled into your executable. The end result is all dynamic dispatches had to be saved external to the executable...that is on disk. Ultimately this proved a good thing for me because I was able to use the external classes to develop further extending classes outside of the executable. In the end I had a plug-in architecture that was designed entirely serendipitously due to limitations of the IDE at the time. I wish I had access to the code, but it's several jobs ago... What ultimately materialized was an interface class gets defined. In your case I believe this is beta. This interface will need to be part of some distribution so other projects outside the scope of your application can use the class to extend as required. This "distribution" can simply be a literal copy of the source code you pass from project to project, or it can be a proper "Source Distribution" defined as a LabVIEW Build Specification where block diagrams and front panels are removed (if you want to lock down your code, for example). Take home point is you end up with your .lvclass file and all supporting files, which you may or may not be able to directly edit depending on how it's distributed. You use this as you develop all your other components. Now consider the gamma project. I use my copy of the beta distribution, add it to my gamma project, and go ahead coding everything as I normally would, extending the class, etc. When I'm done, how do I generate a working copy of gamma that I can use in my alpha? A proper "Source Distribution" is the best choice since you can add your gamma class to the build specification, but also explicitly exclude beta from the spec. After all, the plug-in will ultimately be used with alpha, which already knows what a beta is. Why should I include beta a second time? Think if you have 20 plugins, do you really want to have 20 copies of beta laying around? Then go ahead and create alpha, using the same beta distribution as you've done before. When it comes time to make your alpha.exe, make sure your beta.lvclass comes along for the ride (usually does automatically since you'll probably have a constant of it somewhere on your block diagram). There you have it, gamma was just developped completely independently of alpha (or delta, or any other plug-in). And alpha is completely unaware of what a gamma is, the only thing it needs to know is the path to load a gamma from. See this attachment: Dependency.zip (LV2010 SP1) If you go the Builds directory and launch the executable, click the "Look For Plugins" button and point the dialog to the folder containing the exe. Then select the plugin you want to load (Gamma/Delta). When you click the Load Plugin! button, the class will be loaded on demand. If you look at the code for Alpha, you'll see the original exe has no clue what either of the plugins are ahead of time, and neither plug-in knows about the other. You can extend your beta as many times as you want, the only thing you need to worry about is some sort of contract such that your executable knows where to look for these extra classes at run time. In the case of the executable I half cheated by having you pick the path, and the exe then looks for a *.lvclass file with the same name as each folder contained in the folder you point to. I'm sure you can dream up something much more sophisticated, but I hope the example gets the point across? Have fun! -michael
-
Hmm, I've read through this a few times now, and I must be missing something. Why can't beta be a distribution which alpha, gamma, and delta all depend on? Is there a need for alpha to be aware of gamma/delta (I assume that since beta is an interface, the answer is "No," but I thought I'd ask.
-
Web UI Builder - feedback wanted
mje replied to Mr Mike's topic in Remote Control, Monitoring and the Internet
Agreed. If I'm going to make a web interface for a device, I want it to be open to not only windows desktops, but other operating systems, as well as IOS/Android/Whatever devices. Why would I develop a platform locked web interface when I can already develop a more open stand-alone application? The Web UI Builder looks slick as can be, and I really think it's a push in the right direction (thin clients), but I don't think using silverlight was the way to go given how html technologies have evolved and non-desktop platforms are becoming more predominant every day. -
Nice, thanks Yair. I didn't even think to use that to my advantage in this context.
-
Well that took way too long, but I finally got a functioning release build spec. Iterations are slow when build times are long... I tracked the problem down to a private VI in a re-use lvlib which is required to have its front panel due to VI server calls made into the VI. The VI is not set to show front panel when called (because it should never be shown), so builds have no way of knowing the panel should be kept. This got me wondering, since the library is used as-is, there doesn't seem to be any way to enforce the panel to be included in a build other than each build specification must manually add the VI (among others) to their always include section. This seems very fragile and strikes me as the wrong way to go about business, especially since the VI is private: the user of the library should have no reason to even have to know about the existence of the VI, let alone be required to add it to each build spec. I think creating a packed library for distribution might allow the specification, but last I checked (bare LV2010, no SP), creating a packed library out of the lvlib made it nigh unusable as the IDE slowed to a complete crawl, so I've barely even explored that option. Is there no other way to flag a VI to always hang onto its panel when saved into a build? -m
-
Thanks for the tips. I had to generate a working executable over lunch, which means I spent the hour generating another debug build, so I can't confirm that all is solved. But this all makes sense, so I'll give it a whirl at the end of day. I did find out why I wasn't receiving errors. Silly little bug, I had the error out of my run method ultimately wired to the error in of Send Notification.vi, meaning if the VI server call fails my notifier would never signal. So my calling process would just wait indefinitely at that point for the failed child process to spawn. /facepalm
-
What exactly is the fundamental difference between executable builds when debugging is enabled versus not enabled? Other than the inclusion of symbols and what not so breakpoints can be used etc. I have an application which I've been building with debugging enabled for months and it has worked beautifully. I've now switched to release mode (not checking the "Enable debugging" box) and spent a few days trying to figure out why the executable no longer functions. I realize I'm being nebulous about this, but I really don't know what isn't working yet, so I can't really go into details. All I know is my executable spins up, shows the splash screen, grabs about 100 MB of memory then...just blocks. I'm making very slow progress mostly due to the long build times (I only run builds when I'm out to lunch, or when I leave for the night, meaning I only get two shots to fix it each day). Any tips on what might be different with respect to debug and release builds? Last night got me thinking maybe release builds are removing front panels of my dynamically loaded VIs, so that's next on my list of things to check. More news after the (lunch) break I suppose. I've also noticed the executable goes from 50 MB in debug mode to 24 MB in release mode. That seems like a big difference, but I have no idea what's involved with debug symbols etc, maybe that's normal? Regards, -m
-
The issue has started to creep back up for me as well. On any given day it's a crapshoot whether or not DNS will resolve for lavag. I believe my problem is due to a proxy we have in place at our work, especially since it only applies on hard-wired connections, our wireless works fine. Something about that proxy is seems to pick up bad DNS entries every so often. Given that it involves our corporate network, I anticipate the problem being efficiently resolved some time before our sun burns out.
-
Ok, that actually makes sense. A zero value then specifies whatever monitor is the default system monitor, and then any number greater than 0 is a specific monitor. When returning a value, the property node always seems to resolve to a specific monitor, and never returns 0. Thanks, James.
-
With regards to the Front Panel Window: Monitor VI Server property, LabVIEW documentation says this: I have a computer with a single monitor and the property always returns 1. Is this number perhaps a 1-based index and the documentation is incorrect? When I read theDisplay: All Monitors property, I indeed only get one element back which corresponds to the properties of my one and only monitor, there is no '1' index...
-
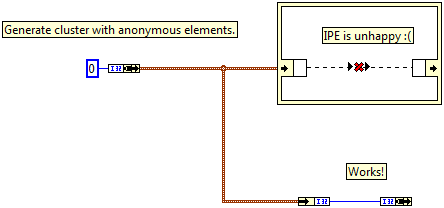
Oh yes, of course it's expected. I just don't like how since I have an anonymous cluster I can't use the IPE to operate on it. Doesn't affect my code at all, just annoyed. Makes for messy code since I need to unbundle a whole cluster to operate on a single value. And no, I don't have control over the incoming cluster, so making the type named won't work. I could typecast it to a named one, but meh it's not that big of a deal...
-
Ran into this today: Since the IPE unbundle nodes work by name, they aren't happy with anonymous types. Bummer. Not a big deal, but it would be nice to be able to operate on unnamed types...
-
Architecture Question for Observer Pattern
mje replied to Stagg54's topic in Object-Oriented Programming
Why not have the parent message class implement a dynamic method that logs some default information. Override methods can override/extend/extinguish as needed? I've done a few variants of this. Some parent method defines an interface, maybe it's supplied with a byte stream refnum, maybe it's as simple as providing a ToString() method that returns a log friendly form of the object. Regardless of the exact interface, the parent method ultimately logs some basics such as the timestamp, fully qualified class name, whatever is relevant. Some extending classes override this with other information entirely, other implementations call the parent then concatenate extra information, and others in turn override the method only to not do anything and therefore keep the messages entirely silent from a log perspective. This model of course depends on the message itself being able to define what needs to be logged and what doesn't, which is what I think you mean by your modules being unaware? That is the observer doesn't decide what gets logged, and the signalling process doesn't have direct control over the logs, except by virtue of what messages it sends. -
Wait....what? I had no idea you could change values of either input or output when you do that. Suddenly that feature is useful to me...
-
Thanks folks. Sorry for the reply, having a heck of a time connecting to lava from work recently, so my response is delayed... The programmer would almost certainly know ahead of time whether their data size would be dominated by the names or values. Knowing which method to use really isn't the issue for most I'd expect. Most definitely not. If a type is supplied, a name must be as well. There are definitely games that we can play to reduce the allocation size when creating the arrays by having nested data structures etc. But it still demands an allocation each time I want to perform an enumeration of my variant attributes. It seems like an unnecessary waste. I'd expect the variant attributes are implemented in some form of a binary tree for lookup. I don't know a lot about how to enumerate these data structures, but my guess is whatever they've chosen to use under the hood makes it non-trivial and is probably why we can't do it as it stands. Variants did get a big "kick in the pants" recently (to quote an NI employee). I know lookup performance of attributes improved greatly, so I wonder if it might be possible to easily allow enumerations now?
-
It seems too have worked itself out at about 3 PM eastern time. They always say it can take a few days for DNS to propagate, I've just never actually seen that happen before. /shrug
-
My workplace has had trouble resolving lava.org since the move. Connection has been spotty at best up until today, where the name does not resolve at all. Works from my phone though. Last I checked home worked too. Maybe there was some issues propagating the new addresses?
-
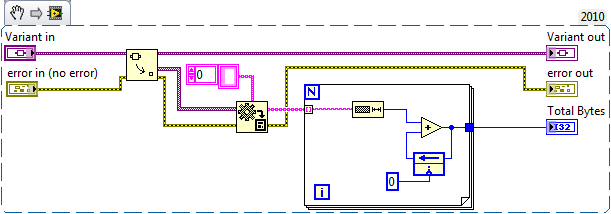
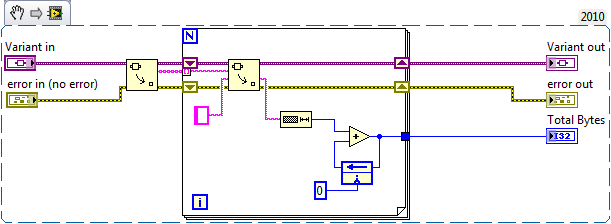
I use variant attributes quite a bit when I have a list of data which is both large (be it element size or number of elements) and dynamic (regularly adding/removing elements). This is ideal if access is primarily random, where I access some arbitrary elements at any given time. From time to time though, I must use sequential access where I need to enumerate every element. There is no native way to index variant attributes, so as far as I can tell we're left with one of two ways to do the enumeration. One: This is a bad way of doing it, as it involves returning an array of all objects as variants, converting it to the proper type, then operating on each element. Memory consumption becomes dominated by the size of data contained in the attributes. When running the VI with 100 MB of data (1000 attributes each 100 kB in size), the VI uses just over 100 MB of memory. Two: This is a much better way of doing it, involving accessing each element individually. Reduces memory consumption since we're not operating on the large values array, the footprint is dominated by the size of the largest element. Running the same case as above shows memory consumption of just over 100 kB. Nice. Turns out it also runs faster than the previous code as well (about 2/3 the time). But there's still a problem here. We're allocating an entire array of names. This can be verified if we redo the tests using large name strings as well. Using the same as above, 1000 attributes each with 100 kB values, but this time each name is also 100 kB in size, the memory footprints change to approximately 200 and 100 MB respectively. That is the second method still requires a lot of memory by virtue of the array of names it must use to operate. While the above situation is largely academic (screw 128-bit GUIDs, I'm going with 819200-bit ones!), it can come into play if your lists are large by virtue of the number of elements (opposed to the size of elements). In this case method "One" might prove the better way of doing it. I guess what I'm really going for is it would be good if there were a way to index variant attributes. YES, I know if you regularly need to enumerate your attributes you're doing it wrong, but there are some uses which you can't get away from. Serialization comes to mind. Any thoughts on this? I'll probably take this over to the idea exchange in a bit, just wanted to seed some discussion first. Attached is some code I played with to get the numbers above. Includes the two snippet VIs above, and a third one which generates variants for them to operate on. WARNING: running the test with the "Long Names" method continuously while collecting metrics can make the IDE unstable due to memory spikes if the default values are used. Close out your "real" work first! Regards, -michael AttributeEnumeration.zip
-
Good feedback, thanks folks. Yes, 2010 SP1. I think the take home for me will be to examine my hierarchy and see which parts of it can get unloaded after they're done (and if that even makes a difference). There is a definite one-time analysis phase which is quite dynamic from a memory stand point. After that, processing overhead is minimal and the application is visualization of mostly static data. We'll see where this lands...
-
Do any of you have experience with the Request Deallocation function? I'm wondering what proper use is. One of my beta testers for an application I'm writing occasionally reports out of memory errors. When the application instance reports this, it has usually climbed up to about 800-900 MB of memory. I guess I have a few questions with regards to LabVIEW and memory as I've never created any LabVIEW applications that manage large data spaces. Is there a hard limit on what LabVIEW 32-bit is capable of? Am I looking at a 3 GB or so ceiling? I'd never expect to have more than maybe 500 MB of data resident in memory at one time for extreme cases, but the application will be managing gigabytes worth of data space which is cached to disk and can be called up on demand for display purposes. I suspect that what I'm really running into is out of continuous memory required for allocations as there is ample memory available on the system. Does requesting deallocation help keep memory space unfragmented or is that a function of the OS which LabVIEW essentially has no control over? -m
-
Create a 'proper' borderless vi (without the raised/embossed look)
mje replied to MartinMcD's topic in User Interface
I ran into this today as well. If I make the window floating, the frame goes away. But if I leave it as a modal window, the border always appears even if it is not re-sizable. I'd like to have a borderless modal window... -
Just thought I'd add the issue persists in 2010 SP1.