mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by mje
-

What's New in LabVIEW 2011: Accelerate Your Productivity
mje replied to Phillip Brooks's topic in LabVIEW General
I played with the desktop execution trace toolkit and the unit test framework. I've been wanting something like this for ages, but never saw it as a justifiable expense given all the other application's I already have to maintain licenses for. I'm so happy I get to use them now with the developer suite. These tools are invaluable and I always thought it was an awful decision on the part of NI to not include them with their higher end development systems. I only wish I had access to the unit test framework three months ago when I was assembling document trails and closing out our defect database... -
What's New in LabVIEW 2011: Accelerate Your Productivity
mje replied to Phillip Brooks's topic in LabVIEW General
Yes but the issue can be eliminated for many use cases. Since the new ACBR nodes allow you to reuse the same refnum, you can most likely open references to any required VIs during application initialization and hang onto them for the lifetime of the application. This of course assumes you're not dynamically loading to reduce memory footprint, in which case you're still out of luck. -
Gotcha. That is a great idea.
-
Oh for sure. I didn't mean to imply a State should only have a singular method. The idea is that the Context defines many methods which are ultimately each delegated to a mirror method in the State class. A given concrete State class then overrides methods as required to interpret the requests for that specific State. For any others reading along, I will point out the key difference between our two examples that I see is you have your context defined as something along the lines of: class Context{ Model myModel; State myState; DoSomething() { myState.DoSomething(myModel); }} Whereas I had something along the lines of: class Context{ State myState; DoSomething() { myState.DoSomething(this); }} Some confusion might arise because either of us have a slightly different semantic for what we are calling Context, though if you look at the details, functionally they are very similar insomuch as the Context essentially is the Model in my case. Though I'll add that I often break out and use explicit Context and Model classes as well, the extra class really doesn't add much to the complexity of the system. One thing that confuses me about your post though: How does this happen? If for each Model you have a corresponding State (whether the State is contained in the Model itself as in my example, or part of a parent Context as in yours), isn't it the State's instance that is deciding which onInterrupt method to call when the request is delegated to State:onInterrupt? Of course that call could end up working it's way up a State class hierarchy, is that what you are referring to? -michael Oh well, yes, another thread for sure. And likely another day, I've probably sunk too much time into this discussion today! Thank you though for all your feedback so far, Paul.
-
Yes, I agree friendship is not the way to go: it's far to difficult to maintain. I also agree that it's usually a bad idea, though there are a few situations where extremely limited scope friendship is useful. As for the model storing the state as an enumeration and invoking things via a factory pattern, that is the exact thing I'm usually trying to explicitly avoid by using the State pattern. At the heart of a factory is some conditional construct that needs to decide what concrete class to use, and is the same argument often used to attack certain very commonly used architectures in LabVIEW. I think the beauty of the State pattern is there is no maintenance of a case structure: the object itself is the mediator of what gets invoked at run-time by virtue of dynamic dispatching. Adding a new concrete state is as easy as extending the state class and the corresponding override behaviors which are relevant to the state then applying that state at what ever scope it is needed.* As for State's needing to be aware of one another, that's only the case if the design decision is made to burden the State descendants with the responsibility of deciding what the follow-up State is. The logic for deciding when to switch states does not need to be in the State hierarchy. (*Of course the dirty little secret is that somewhere the application conditional code needs to exist to decide state context switches. So even by eliminating a monolith by using a dynamic dispatch, we still have an even harder task of maintaining dozens/hundreds of conditional pieces of code that decide on state switches, regardless of where in the pattern the decision was made to make to apply this logic. But I digress...) Indeed, the proliferation of VIs from having to maintain mirror methods in two class hierarchies is a negative of the pattern. Though the Context hierarchy is usually quite limited in size. I wouldn't dwell on what the Context:Return method in the example is doing, I was only using it to illustrate a behavior I'm not sure about. If we have a Context method which for all intents and purposes can be treated as a LabVIEW property, should we be able to do so? Something in the IDE is preventing me from doing as much. The real use case is my Context has some properties which are not simple accessor methods, but state dependent calculations. Functionally I have no issue, I can just call the VIs directly by placing the calls on the block diagram. But it would be nice if I could instead have them accessed via the same property node I'm using to collect the 15 other Context properties from...
-
A slew of ideas about the new Asynch Call By Ref
mje replied to Aristos Queue's topic in LabVIEW Feature Suggestions
With one exception I asked myself those questions as to why they weren't implemented as soon as I played with the new ACBR features. I hope the ideas are expanded on! -
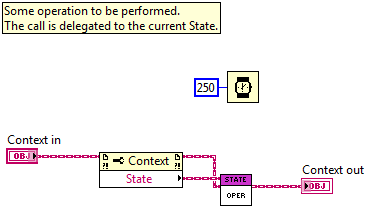
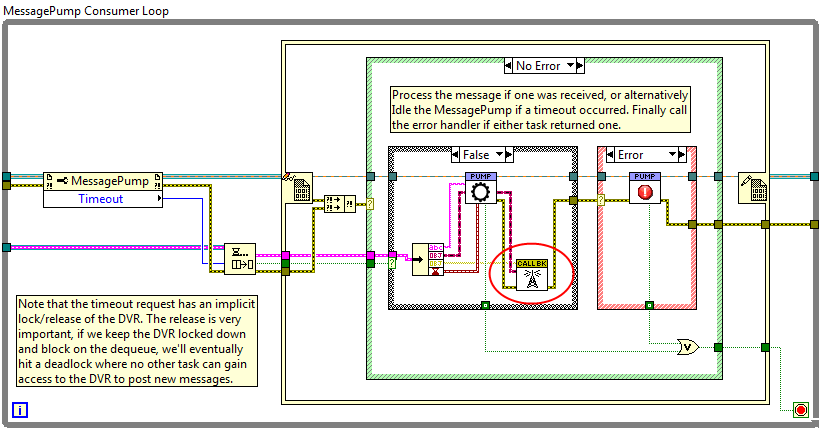
Attached is an example that demonstrates the State pattern. You can open Finite State Machine.vi to see an example of how this is all put together into a trivial FSM. Take note of the Context class. It defines two methods: Operate and Return. The Operate method is responsible for changing the "value" of our class. Depending on the concrete state that is stored in the Context's State variable, an internal Numeric value will be incremented, decremented, or the Context will be set to return. When we request to operate on the Context, the method instead pulls the current State object from its member data, and delegates the request to that State: A given State implementation then decides what it has to do with the supplied Context. There's an important subtlety that needs to be pointed out: This means that a class foreign to Context is deciding how to operate on an instance of Context, meaning Context must expose any operations or properties that are required through a public interface. This can possibly be avoided if we maintain friend relationships between Context and all States, though I can't say I'd recommend as much. Now here's the rub, look at the Context.lvclass:Return.vi method. This VI is intended to decide if the Context is ready to return from some master loop. It looks like it should be able to be made into a property node, since all that the method has is a single return value (boolean), in addition to the class and error I/O. But if you define a new property definition folder in the Context class, and place Return.vi in that folder, you get some errors. In LabVIEW 2010: Invalid accessor VI connector pane pattern. Well that's no help, the connector pane pattern does match. In LabVIEW 2011: Class output terminal does not return the input class. Also not much help, because the input class is returned to the output terminal, but at least we're getting somewhere. I can see this potentially being a problem since the class I/O wire is sent through the State.lvclass:Return.vi interface, and the Context class has no way of determining if the State class will guarantee that a data swap isn't performed on the Context wire within that VI. This can be verified by removing the State.lvclass:Return.vi call from Context.lvclass:Return.vi. Is this intended? The Context.lvclass:Return.vi method is not dynamic dispatch, why should it care about the continuity of the I/O terminals? Something else is afoot here. Is this a bug? State Pattern LV2010.zip

-
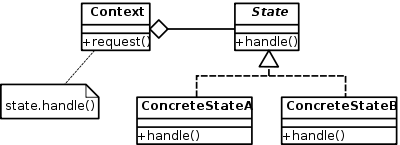
I've used some variant of the state pattern for a while now, but never noticed something with regards to its LabVIEW implementation until this weekend. To be clear, by State Pattern, I'm referring specifically to the one detailed byGamma et al: (wikipedia) The idea being that a given Context implements some interface whose behavior changes as a function of State. For behavior which depends on this state, the Context will delegate the request to the contained State object. That is we are defining a behavior through containment, not inheritance. To keep it simple, I won't go into why one would want to do this. In LabVIEW land, this means: Context defines some sort of interface (a set of public or protected VIs) which it wishes to expose to the outside world, this interface need not be made up of dynamic dispatched VIs. A State class will define a similar interface, though this one needs to be made up of dynamic dispatch VIs such that more concrete classes can modify behavior. This interface will often include a Context input/output as part of the VI calls such that the specific State can operate on the Context. Context also contains a variable to store the current State. Note however that during run-time the object stored in this variable is almost always an instance of a more concrete class derived from State (ConcreteStateA or ConcreteStateB in the diagram above). Any call the Context interface delegates the call to the State interface, often passing itself as an argument to the State interface. (Bah, I hit post instead of preview, more to come later...)
-
In that case you just close the refnum after you make the start async call. I believe passing off a secondary reference to the asynchronous VI is handled automatically, I have at least confirmed closing the refnum you have access to does not cause the VI to return.
-
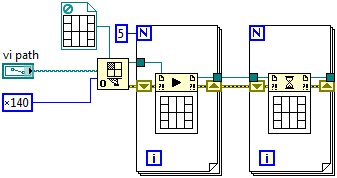
I do have a case where it would be useful (though not necessary), but as always, there are many ways to skin this animal. I have my own configuration dialog framework, not unlike the one used in various places in LabVIEW. The caveat being the individual category VIs are all reentrant. Basic use is: A list of categories are supplied in the form of an array of VI paths, array of category names, and an optional array of configuration parameters. Each category's VI is started up but remain hidden, the appropriate configuration parameter is passed to each VI. Note multiple clones of the same VI might be presented as distinct categories. As the user clicks each category, the clone for the proper category is displayed in a subpanel. Currently I have the responsibility of switching what's in the subpanel in the main dialog since it owns the subpanel, but this could just as easily be delegated to the clone VIs by passing in a refnum to the subpanel during some activation event. When the dialog is dismissed, the return values for each category are collected and returned to the calling VI. If I go with the 0x140 option, like you said as long as I pass an index or something I can always sort out which VI is returning with each blocked wait call. It's a useful framework, if there's interest I'll post it once I finish reworking it.
-
Ah yes, that makes sense. Thank you so much for talking me through this! Now please correct me if I'm wrong, since 0x40 option will always return a refnum to the target (not a clone), if we need to obtain refnums to specific reentrant clones when using the 0x80 or 0x100 options, the only way to do so is to have the clone return a refnum of itself to the caller after it has been started (via a notfier or something). The 0x8 option seems to work, but we "should not" use it? -michael
-
Fascinating. I do like that 0x40 works with the traditional CBR node as well, it's a very useful behavior. Now that is very interesting, your example does work as advertised. What puzzles me though is if I modify Sub Panel.vi to have a one second wait in the VI, thus forcing it to not return until after the Insert VI call is made, I see what appears to be the FP of the target VI not the clone. However if I switch the order of execution of the insert and start nodes, I get the clone in the sub panel. The two VIs are attached: You can easily switch execution order via the enumeration on the FP of Main.vi. What might be happening here? The Open VI Reference (0x100) does indeed return seem to return a clone refnum: if the refnum is inserted into the sub panel before anything else is done to it, we observe the clone behavior. If Start Asynchronous Call is called before Insert VI we instead seem to observe the behavior of the target (not the clone). The refnums themselves don't seem to be changing. Something about that refnum seems to be mutating through the Start Asynchronous Call node, the behavior is not consistent when the Start and Insert node orders are reversed. Posted the wrong VIs, server seems to be returning errors when I try to edit my post: Main.vi Sub Panel.vi
-
Edit: I went back to my use case and tried using the 0x108 option again and it worked. The error I was receiving was actually due to something unrelated to the async call. When it didn't work and the documentation said it shouldn't, I didn't even try to fix it.
-
Strange. The Open VI Reference documentation clearly states for both the 0x80 and 0x100 flag: "Do not use this option flag with 0x08," and in fact one of the first things I tried was to use it anyway. My efforts were rewarded with some error along the lines of "The referenced VI is not in a state compatible with this operation", or something similar. Is the documentation out of date? If so, then the 0x40 flag makes sense since we can choose between the two methods. My criticism was aimed at least initially it looks like you went ahead and replaced the 0x8 option with 0x40 for asynchronous calls. Having both options open is an excellent decision, if indeed the 0x8 one is stable.
-
OK, so I'm very excited about the Start Asynchronous Call primitive in the new LabVIEW 2011. Awesome stuff. Went ahead and started using it in several libraries I have where I used to use the old kludge method to do it. Works fantastically. But...I don't really like the way it was implemented with regard to reentrancy. I have a use case where I have a set of re-entrant VIs I open and start asynchronously, then at any given time I'll be placing one of them in a sub panel depending on context. Works beautifully with the old method, because I call Open VI Reference with the 0x8 option to get a reference to the specific clone, and can plop it in the sub panel whenever I wish. But things don't quite work that way with the new way of doing things. When I call Open VI Reference, I need to use the 0x40 option to allow simultaneous calls to the reentrant VI which opens a refnum to the VI, but as the documentation states: So I can't use this reference to place the VI in a sub panel, I instead need to get creative and use some form of synchronization to get back a refnum to the running VI, etc. Bah, what should have been easy has now been made complicated. Sigh... Attached is a two VI example showing the (as expected) non-functioning behavior: Async Subpanel.zip This seems all related to the way the Wait On Asynchronous Call primitive works, in that when you have multiple clones of a VI running, the sequence with which the clones returns does not matter with respect to the sequence of blocked wait calls, which allows code like the following to work: Anyways, it would be really nice if there was some way for the Start call to return a refnum to the VI that's actually running. I've got to say I really don't understand the decision to have the methods work like this. I see where you were going with the design, understand how it works now, and even can see some use cases, but why engineer a new way of working with clones like this when you already had a functioning option (0x8). Surely there's not an architectural reason that would keep LabVIEW from blocking until a specific clone returns had the 0x8 option been enabled for asynchronous calls? Hope you all had a great NI Week, wish I had been there. Regards, -michael
-
What's New in LabVIEW 2011: Accelerate Your Productivity
mje replied to Phillip Brooks's topic in LabVIEW General
I'm most excited about the apparent IDE speed increases. Though this little diddy is also great news: In particular: Execution Details This node exhibits the following execution behaviors: Does not require the user interface thread to be idle
-
Self-addressed stamped envelopes
mje replied to drjdpowell's topic in Application Design & Architecture
In practice I find asynchronous mechanisms like the one James just posted to almost always be preferable to a synchronous request. The reason is even in a dedicated hierarchy where each messaging component is clearly owned by a singular owner, and even if the system is designed such that all messages flow from owner to down the hierarchy, there is usually a case where a component will have to send a message in reverse. Maybe a component has stopped (unexpectedly or otherwise) and the owner *must* be notified. If the owner is locked down in a synchronous call deadlock is a very easy possibility, and debugging the deadlock can become nigh impossible as the application complexity grows. I'm not saying synchronous calls are bad, but even if you think you know everything about a given framework, you still need to be very careful. In my experience there is rarely a true unidirectional messaging system. Some of my components will always care if their message targets return unexpectedly. -
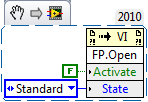
How are you presenting the front panel of this pop-up VI? If you explicitly open it via an invoke node, you can specify that the VI should not receive focus: All you need to do is configure the VI to not show its front panel when called, then some place in your code, make a call to FP.Open to show it. Just be careful, once you start doing this, you also need to manage when to close or hide the FP.
-
Self-addressed stamped envelopes
mje replied to drjdpowell's topic in Application Design & Architecture
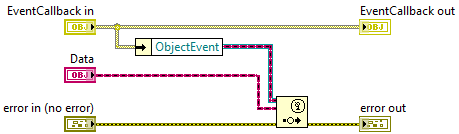
I think this is a good way of doing things. With a mechanism like what you describe, asynchronous message replies become trivial, and you can even implement synchronous messages* in the same framework if you ever need them. In fact I have my own architecture which does pretty much the same thing you have done (don't we all have our own it seems now a days): Any message which is past in is compromised of four things: a message identifier (string), some parameters (LabVIEW Object), an optional parameter to signal a reply with (Callback Object), and an automatically created time stamp. After every message is processed, the operated parameters are passed to the corresponding Callback object's broadcast method (circled in red in the screen shot above). A default Callback Object's broadcast method does nothing, meaning the default configuration for passing message if you don't supply a Callback derived class is to operate in fire and forget mode (pass a message off and don't care about a reply). The magic of using a class for a reply command (or Callback in my language), is that you can extend the reply mechanism to use any type of object, from native LabVIEW synchronization primitives like notifiers, to other messaging architectures. For example, if I want to send replies to a generic user event, I create an EventCallback class and implement the broadcast method as: Using something like that, message replies can pretty much be sent anywhere, to any type of framework object or primitive construct. All of this of course means that the originator of the message needs to know where the message reply is required to be sent to. That doesn't mean that you can't also have the system configured so the message handler decides what to do with a reply, though I don't advise mixing the two. *A word about synchronous messaging (where a message is sent, and the sender blocks until a reply is obtained): Be very careful. Deadlock is very easy if you introduce circular dependencies, I've pretty much learned to avoid any form of synchronous messaging, even though it's easily done with the reply-to mechanism.
-
Orange nodes are configured to run in the UI thread, yellow ones run in any thread. For IsUserAnAdmin() I don't think it should make a difference, but many other Win32 API calls must actually be called via the UI thread (specifically ones which are not marked as thread safe). Come to think of it the documentation for IsUserAnAdmin doesn't comment on thread safety, so it should probably be forced into the UI thread. I'm not sure why you're supplying an initial value to the return variable? Does LabVIEW even let you do that (it shouldn't). Also noted this gem in the docs: Darn.
-
Well, determining if you're running under an administrator privilege is easy enough: But like you implied, you're probably going to have to serialize that config info somewhere, so you're going to need a file. Restricting the ownership of the config file to the administrator group is probably what you want, and successfully being able to open it for write operations should clue you into if you're good to go. -m
-
So this idea rekindled something I've been longing for for a long time in LabVIEW: better integration with web-based UI technologies. I've in the past played with using HTML/etc to create dynamic user interfaces which frankly aren't possible in LabVIEW since elements can't be created or destroyed dynamically, and this is something HTML/etc excels at if you know a little DOM and the idea of a little javascript doesn't scare you. First a little proof of principle to show that you can get data in and out of a WebBrowser: WebBrowser.zip Caveats: This is a very simple proof of principle. To use it you must Be on a Windows based PC (it uses .NET after all). Keep the contained folder in a location which doesn't have spaces in the path, I didn't do any URL parsing... How it works. Getting data in is pretty trivial. Once the document is loaded in the browser, grab a reference to whatever you need (in this case an input element), then whenever want to update the value, just push it to the browser using the element refnum. Getting data out isn't so bad either, though it is rather annoying. If you know any DOM, you're probably familiar that all the input elements have an onchange event associated with them. Well forget that, you can't use a refnum to register for an event callback for anything you pull from the hosted browser (someone please correct me if I'm wrong about this). But you still can register for events on the top level WebBrowser2 refnum, so I pulled the BeforeNavigate2 event and registered a callback for that. Now whenever I want to get data out of the web page, all I need to do is trigger a location change, then pull out any data I wish. You can probably imagine a few other ways to skin this one... There are still some things that are basically off limits in LabVIEW. In the past I've defined entire COM interfaces (via C++), then passed the corresponding IDispatch interface into the browser which allows you to define arbitrary functions and variables which can be called directly from within a hosted document via the global window object available through javascript. I would love to be able to do this in LabVIEW. Imagine being able to call some code like this: <input type="text" onchange="CallMyVI('Foo', 'Bar');" /> And have a registered callback VI automatically be called with "Foo" and "Bar" being placed in the appropriate terminals of your connector pane. So what's the point behind this post? I'm really just hoping to seed some discussion on this. I have no idea how many of you have some web-based development under your belts, but I'm hoping even if you don't, that you can see the possibilities that can be opened up by being able to have a more dynamic user interface canvas available to us? Hopefully in time I can get a more thorough example of what I think is possible, but for now the proof I posted above is all I have. Regards, -michael
-
Yup, happens depending on the phase of the moon and what not. I'm not saying having the destination folder open in explorer can't cause the error, but I've had it open plenty of times and not had problems. I've had the error creep up for builds I've run many times which have not changed (from static tags in a CVS system). Restart, hope for the best, and the problem might go away depending on any number of random factors. Yes, that's the most professional and scientific answer I can muster for this one. Good luck?
-
You can use the image functions and associated indicator if you're willing to create all the drawing logic. Beware though that images in LabVIEW can get awfully slow if they're more than icon sized and you try to manipulate them quickly (tracking mouse movements, and animations, or anything similar) . Not sure if you could do any blurring or anti-aliasing without a lot of effort though.
-
I've seen this behavior in other circumstances, but never been able to pin it down. Often it's when creating a swathe of accessor methods for a new class when dozens of new VI windows are created. I then enter a mindless loop of Ctrl+W followed by Enter key strokes to close and save them all, but sometimes, the z-order gets all messed up and tracking down the new VIs becomes cumbersome. I've learned to modify my behavior since then, any time I'm mass creating methods, I close out everything save for the project explorer so my windows don't get lost. In other news, won't be long until the "Usability" 2011 IDE is out! I'll also point out that my previous project suffered from slow downs as well. It had (I think) 1800 VIs, and doing any diagram editing caused the IDE to lock up for just under a second. It was cumbersome. I'm only realizing now since I've moved on to another project and don't (yet) have the slow downs how much it affected my throughput. Also compile times are back down too! New projects are fun.