mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by mje
-
I'm mostly concerned with execution time from the triggering of the error state back to whatever layer in the call stack handles the error. I have analysis code which can run in the minute to hour timescale. If an error occurs after 30 seconds, I don't want to wait a half hour to reach my handler. So a lot of the code gets wrapped up in error cases even if it is primitive operations which are inherently incapable of generating an error conditions. I'll take a look at that exception code once I land in front of a PC. Sounds interesting.
-
Indeed. Without which LV2Gs could not exist.
-
I take this statement back. It would be fundamentally impossible without breaking the data-flow paradigm. Consider the screenshot below: The class returned from the VI is owned by a library, and the class is marked private. The screenshot demonstrates that the scope of the class isn't really private, as splitting the wire must produce a copy of the value. Conclusion: even marking a class private does not keep new instances of the value from being created (though it does make it harder to do since you can't pass the class to subVIs). So even if there was a way to mark a subVI as in-place (or a pair of connectors for that matter), the ability to simply split a wire would still work against the whole singleton idea as it would still be trivial to create multiple values of the singleton object.

-
In my opinion, a true singleton is not possible in LabVIEW. You simply can not enforce that only a single value of a given type ever exists. The only way to ensure you have control over the number of instances of a type is to exert control over creation of that type. In other languages, this is done via a private constructor for objects. This is not a problem because you can still pass pointers or references to a private type through function calls, allowing the functions to operate in place on another value. In LabVIEW we face a fundamental problem: constructors simply do not exist. You can get around the lack of constructors by placing your type in a wrapping library and making the type itself private, then creating a public API for accessing that type. However then another LabVIEW fundamental comes around to smack you in the face: defining the interface to a VI requires values to be instantiated for each type used in the interface. Said another way, you need to plop down controls for each type you want to wire up to your connector pane. If your type is private, you can't drop a control on a VI outside of the library. So if I adopt this method, I can't pass my singleton to sub VIs. This was brought up by Tomi in response to AQ's 2006 post, and the issue I believe still stands. Checking in the singleton only to recheck it out in the subVI is not an answer as it exposes your code to race conditions, the only way around is to wrap the call in yet another layer of mutual exclusion. AQ's 2009 post really is not a singleton. In fact I see the DVR as being completely superfluous: if you're just going to copy the value in to or out of the DVR, why not have the value in the LV2G instead of the DVR (the path value that is)? Its fraught with race conditions since there's no locking mechanism in place. Eliminate the DVR and you're left with a static class property via the unerlying LV2G. Replace the DVR with a SEQ, or simply operate directly on the DVR stored in the LV2G (get rid of the get/set methods which copy the value) and you have concurrency solved while you access that path value. But you still don't have a singleton. Nothing is stopping me from dropping another path constant on the diagram and going from there. I don't think it would be that hard to have a true singleton in LabVIEW if one change was made to how LabVIEW works. If you could somehow tag a VI as "in place" such that it would only operate on buffers that are owned by a parent VI. This ability seems to almost exist as of LabVIEW 2010 where you can tag a VI as inline, but correct me if I'm wrong, you still can't drop a private control on the front panel of an inline VI, as you are still able to run these VIs on their own. That is even for an inline VI, it still creates a buffer for whatever type such that the VI can be run via the panel. -m
-
Well, the error check is a single operation, so I wouldn't expect much difference in all but the simplest VIs. For me it's more of a consideration of what the proper logic to apply when presented with an error, and about allowing a fast route out of code to some block that will handle the error (oh how I wish there was a way to implement exceptions in data flow- not that unwinding the stack is without speed problems in procedural languages). What does surprise me is the need to wire up the cluster. Why should LabVIEW care if it is using the default buffer for the front panel or operating in place on a buffer owned by its caller? I wouldn't expect that to affect speed at all.
-
My general rule is VIs don't modify in-place data if an error is supplied: if a wire goes straight through my VI with an in-out style, unless stated otherwise, that VI will NOT modify any data on that wire if presented with an error. Every one of my VIs which has a set of error terminals (most of them) has a statement in the documentation that either says "This VI provides standard error I/O functionality", or it will explicitly state its error handling logic if it deviates from that behavior. I admit to being lazy though for getter/setter methods. This is another big consideration for me, but I never violate my first rule. Even if I save next to nothing processing time wise by checking for an error, if I modify in-out data, I wrap it up. In an error case structure that is... I often omit checking in getters too (unless there's an expensive look-up time), but I should be clear I still propagate the error in these cases. I should clarify the bit about getters though. I honestly almost never modify the default get/set properties for objects out of laziness. If it's a simple primitive, I figure the overhead in calling the VI, boxing and unboxing the actual Object etc is way more expensive than a simple case structure check. The opposite is if I have a potentially big buffer allocation due to a getter, I will always want to keep that wrapped up.The getter-style methods I often omit checking from are derived methods that usually simply return a primitive type. Maybe something that returns the size of an array, or does a trivial calculation. Mostly because in these cases I actually need to think about the code.
-
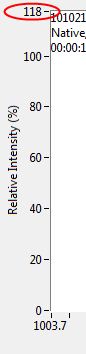
Thanks for confirming, jaegen. As for Shaun, nope doesn't work. I still want the range 0-118 displayed, I just don't want the 118 label to be shown.
-
I have a graph that where I want to explicitly set some scale markers via the Graph:YScale:MarkerVals[] array. Problem is LabVIEW seems to insist on displaying the labels for the limits of the scale as well: In this case it's displaying "118" despite me having only requested the {0, 20, 40, 60, 80, 100} values. Is there a way keep LabVIEW from adding the extra label? Other than kludging it with adding controls to hide it, etc...
-
Indeed, which is part of the reason this pursuit is entirely academic at this point. I don't have a use case for the entire lot of my discussion, but I've found myself having implemented parts of it entirely by accident. I have an application that interacts with other executables which I don't have control over. There are a lot of configuration options for these executables, and the user is will occasionally have to tweak them. Currently I allow the user to define an unbounded number of name/value pairs of configuration options which get passed to the executable when run. These settings are all bound at run-time, that is they don't map to fields which I've set out in the development environment: while I might know some of the possible configuration settings, I don't know them all and they are liable to change as the executables evolve. The implementation I have now simply keeps these settings in a dictionary, which becomes part of the application's data document and/or global configuration defaults depending on context. At this point I'm pretty much just implementing a late-bound enumerable interface. There is no type-safety, nor inheritance in the system (and there doesn't need to be, works fine the way it is). This just got my mind going as to what happens if I ever had a situation where I would have to start inheriting objects like this? What would the requirements be? I'd like to be able to define types for everything, and if so, I'd also like to ensure that those types are enforced at all levels of the hierarchy, hence my original post. Near as I can tell the only problem with what I've described is the underlying properties are always tied to the base class: there's never any knowledge of what class actually "owns" the property. But I'm not even sure such a distinction needs to ever be made, or even if it can.
-
Hah
-
Argh, my previous post half vanished... Guess I know what happened when I failed to edit my post: the server probably only got half of the content and truncated it. I've lost my train of thought, but as for the abandoned screenshot, I was saying one bit of code stands out: You might run into name collisions if you deal with multiple libraries. I'd recommend examining the flattened class data and extracting the PStrings that form the fully qualified name.
-
Well, works now. How odd. Something along the lines of complain and the problem will go away?
-
Is there an issue with the boards that keeps posts from being edited? The last few days I get timeouts whenever I try to modify my posts... crelf added this line mje tried to add this line...
-
OK, looking at your code now, I think I see where you're going. I get the idea of a RenameableMessage. Though it flies in the face of any usage I apply messaging to, I get why your message hierarchy would be built the way it is when I look at this class. In the case of your plain old Message class, I suppose where you're going is for type re-use. You want to be able to separate the actual message from the data type. At least it would keep things a little more light weight in that it would keep the number of classes down if you have multiple messages which have the same fundamental data components. In it's heart it's no different than cluster based systems where the message consists of some form of identifier, a data payload, and maybe other information
-
I've used several messaging models in my applications, but this comment and the next few posts confuse me if I'm reading them correctly. If I use an object as the message, I don't see a need to even have a message name (or enumeration, or any supplementary type information). The object itself is the type of message: having a message name from which I need to branch code off of seems to defeat the whole point of having an object message. When my message is an object, the executing code can be decided via dynamic dispatch. I don't have access to your code at the moment, so maybe I'm misinterpreting the previous few posts in the discussion?
-
Wait, how did I miss this? I was under the scope of LapDog was something else entirely more of a general framework. I really like it, well done!
-
Yes. I'll see if I can come up with a demonstration soon, probably will have to wait for the weekend though.
-
Dak, thanks for the quick feedback. I see how this could be ambiguous. Hence the need for discussion! What I meant was that if a class defines an LB property as a double, extending classes will have to honor that contract by only using that property only as a double. As you implied, even though the data is a variant, it has embedded type information. The idea of generating compiler errors in this case is impossible, since the evaluation of the existence of a given property won't be performed until run-time, hence we can only be dealing with run-time errors propagated through error clusters. Perhaps type safety is the wrong word? I'll also note that strict typing does not always equal type safety. Some languages such as javascript have strongly typed data, but do not enforce any form of safety: what used to be defined as a Number could be replaced with an Array or Function, for example. In a compiled language like LabVIEW the two properties are often inseparable because you always know the strict type ahead of time, but once you start doing run-time evaluation this assumption breaks down. However nothing is stopping an interface from enforcing consistent types at run-time once something has been defined.
-
I'm looking into creating some kind of late-bound type reflection into some of my objects. For now I'm restricting myself to data fields, though there's no reason methods shouldn't be implementable as well. I'm wondering if anyone else has thought about this? If the buzzwords are foreign to you, I basically want to be able to determine what properties are defined in an object at run-time, and be able to query/change the values. This is explicitly not dynamic dispatching. I'm not looking to query the sum total of an object's interface, but have a class expose a subset of it's interface. A warning: I'm sort of thinking out loud here, I don't have anything at this point. I find discussions on lava help a lot, so hoping to get some feedback because there are some very well educated people here with regards to LabVIEW OOP. Requirements: the resulting interface should be enumerable, type safe, and extendable. Enumerability exists to allow code to be able to query the interface of the object and determine what can be operated on. The querying code could be completely foreign, or exist within an extending class. At this point I'm not sure if I want to force public visibility of the resulting data, or actually deal with public/protected/community level scopes somehow. Extendable is an obvious feature that is desired: if I have a class that defines an interface, any extending classes should be able to further extend or override members of that interface. So what are we to do? Invent an interface that essentially allows us to define another layer of interface. I've iterated through a few ideas, and this is where I've landed. Let's define the class LBObject (late-bound object). The heart of the implementation would be some sort of dictionary with the values of each item being stored as a variant: the variant allows for type information to be kept yet allows anything to be stored. The implementation details of the dictionary at this point is undefined. A pair of methods would exist to provide access to interface elements defined in this dictionary, and enumerating the interface is as simple as returning an array of names defined in the dictionary: Get(inout LBObject lbo, inout Error err, in string name, out variant value);Set(inout LBObject lbo, inout Error err, in string name, in variant value);GetNames(inout LBObject lbo, inout Error err, out string[] names); If visibility is to be considered, sets of these methods might need to exist for each protected, public, and community scope. The set method would be responsible for checking that the type of supplied value is consistent with the stored value, and would return an error if a particular name is not defined. Type safety would demand that some sort of contract be established ahead of time on what a default set of values are: [dynamic, protected] InitializeLBItems(inout LBObject lbo, inout Error err); This method would be called automatically by the LBObject methods any time an operation is requested for an uninitialized LBObject wire, the responsibility of override methods is to create their interface via another method: [protected] CreateLBItem(inout LBObject lbo, inout Error err, in string name, in variant value); The CreateLBItem is essentially a Set operation, but prior existence of the item is not verified, though type-consistency would be enforced for items already defined such that overrides don't mutate. An InitializeLBItems override should call their parent implementation, then operate on the object, thus allowing the interface to be extended or overriden. Implementing this doesn't seem like it will be to hard. The dictionary can be handled a few ways, I see the best way perhaps with a variant. The value of the variant can be a simple boolean indicating if the interface has been initialized. Any call to Get/Set/GetNames would check the initialization state and call InitializeLBItems if required. The dictionary entries would be stored as attributes in the variant. A class storing its data fields in the LBObject interface could still create properties via a pair of Get/Set VIs which simply call the LBObject accessors rather than accessing data in the class' private data cluster. The downside to all of this is obviously it will be slow compared to compiled code, but that's really a true of any late-bound mechanism. Ideas? -michael
-
Unfortunately no, this product will have a release date that predates the 2011 release, so I don't have that luxury.
-

Why does it take so long for LV to respond after dropping a VI?
mje replied to george seifert's topic in LabVIEW General
Yes, that's exactly what I'm seeing. For me though it happens regardless of VI complexity, though they always reside in a very complex project. It's becoming very frustrating. -
Interesting...thanks gang. Hopefully the returned U64 will always return a valid 32bit handle when working with the Win32 calls. Maybe I'll mask off the high words and return an error if they're ever non-zero. Further investigation seems to imply that my inability to find my hWnd using Win32 might also be related to the VI FP being a floating window, not only the lack of a title bar? Who knows, all I can say is FindWindow returns a null handle, but both of those properties work.
-
Thanks, Jarrod! I'll do some property node hunting and see what I come up with. I don't currently have scripting turned on, so hopefully this method will end up working in the RTE... If you track it down before me, please do post (if you can make that info public). Nice bug too, sounds like an odd one to track down!
-
I've run into a problem where I need to fetch the hWnd of a VI's front panel which has no title bar. Usually I just make a call to User32:FindWindow with a null class and the title bar string, but it seems if the title bar doesn't exist, FindWindow can't do it's job. I might be able to make the title bar visible, do the FindWindow call, then re-hide it, but I'm looking for something more elegant which won't introduce flicker, etc. Anyone have any ideas?
-
That would be ideal, maybe I should start locking my library VIs when I'm not explicitly modifying them. My current practice does not have them set to read-only. Yes, I was moving a property and associated methods from one class to a more generic class. In this case, the hierarchy looked like this (from least specific to most specific): Messaging:MessagePump < Messaging:View < HDXView < HDXMainView. Note the last two classes are not part of the re-use library. I removed an element from HDXMainView's data cluster, and put a replacement in HDXView (a literal cut and paste, if I recall). The element had static accessor VIs which defined a property, these were moved to the base class. Some dynamic dispatches had to be modified/deleted/added to either class. I'll point out that while the intermediate View class was not modified, it also doesn't implement any of the dynamic dispatches that were worked on, which might be a clue?