

ShaunR
-
Posts
5,033 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
39 minutes ago, Rolf Kalbermatter said:
A 18k VI project! That's definitely a project having grown out into a mega pronto dinosaur monster.
You may say that but ECL alone is about 1400 Vi's. If each DLL export is a VI then realising the entire export table of some DLLs can create hundreds of VI's, alone.
However. I think that probably the OP's project is OOP. Inheritance and composition exponentially balloon the number of VI's - especially if you stick to strict OOP principles.
-
19 hours ago, crossrulz said:
Yes, decoupling is a long process. I have been trying to do that with the Icon Editor. Not trying right now as other priorities with that project are more important. Do the process slowly and make deliberate efforts. You will eventually see the benefits.
Ooooh. What have you been doing with the icon editor?
-
58 minutes ago, Softball said:
Hi
NI has always tried to 'optimize' the compiler so the code runs faster.
In LabVIEW 2009 they introduced a version where the compiler would do extra work to try to inline whatever could be inlined.
2009 was a catastrophe with the compiler running out of memory with my complex code and NI only saved their reputation by introducing the hybrid compiler in 2010 SP1. Overall a smooth sailing thereafter up to and including 2018 SP1.
NI changed something in 2015, but its effect could be ignored if this token was included in the LabVIEW.in file : EnableLegacyCompilerFallback=TRUE.
In LabVIEW 2019 NI again decided to do something new. They ditched the hybrid compiler. It was too complex to maintain, they argued.
2019 reminded me somewhat of the 2009 version, except that the compiler now did not run out of memory, but editing code was so sloow and sometimes LabVIEW simply crashed. NI improved on things in the following versions, but they has yet to be snappy ( ~ useful ) with my complex code.
Regards
I still use 2009 - by far the best version. Fast, stable and quick to compile. 2011 was the worst and 2012 not much better. If they had implemented a benevolent JSON primitive instead of the strict one we got, I would have upgraded to 2013.
-
-
1 hour ago, Phillip Brooks said:
--insecure is a curl argument. You don't need to include that in the headers.
You can do the equivalent of --insecure by setting verify server to False when creating the HTTP session.
Should never do this. Anyone can sit between you and the server and decode all your traffic. The proper way is to add the certificate (public key) to a trusted list after manually verifying and checking it.
What's the point of using HTTPS if you are going to ignore the security?

-
14 hours ago, Mads said:
I had a brief look at the code when you first posted it and thought perhaps it could benefit by working more on U8 arrays directly instead of the boolean arrays, but sticking to U8 all the way would not be practical either, so after some minor test runs I left that trail
You can get some of the way like that but there are a couple of bits per byte that have to be concatenated. So at some stage you have to convert to bits. The speed of the encoding for-loops with shift was a surprise to me though.
14 hours ago, Mads said:imgs folder is placed incorrectly in relation to the Example, making the default path to image incorrect
Yup.
On 11/12/2025 at 9:35 AM, ShaunR said:Not even the superfluous length parameter or the example images in the wrong location?
14 hours ago, Mads said:The benchmark code, if it is going to be included in the release, might also look more logical if it was timing the individual steganography sub-components but with the contribution from other functions currently so small (relative to the current encode/decode functions at least) it has not much to say in practice.
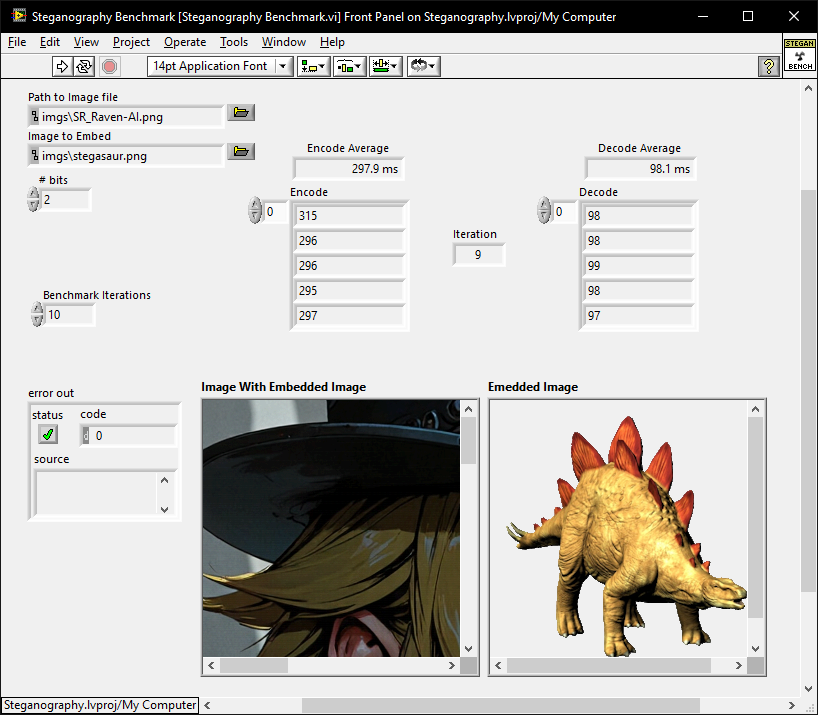
It was purely for relative performances and will not be included in the release proper. For this sort of thing I would rather deal with relative performance (removes differences between systems that they are bench-marked on). The in-built Performance>Profile Performance and Memory is better for identifying which individual components contribute what; so I would use that if someone found a better solution.
-
2 hours ago, Neil Pate said:
You might have more success posting this on the Discord. Most of the conversations happen there these days.
I don't do Discord. I don't even do Ni.com.
Feedback isn't really necessary. I only knocked it up because I went down a rabbit hole and wasn't impressed with the existing LabVIEW solutions. I thought I'd throw it in here to see if someone could improve it. My solution is optimised but there may have been a better alternative solution or maybe someone had a nice JPEG one (LSB doesn't survive JPEG compression).
You might get a mention in the readme just for responding

-
 1
1
-
-
Nothing? No improvements. No bugs?
Not even the superfluous length parameter or the example images in the wrong location?
I'll give it one more week then release the version 1.0.0
-
On 10/29/2025 at 7:57 PM, Bryan said:
With Win 10 support being terminated, and Win 11 essentially becoming "SpyWare!_OS", many people are switching to Linux distributions.
I only switched to Win10 3 years ago from Win 7 and that was only because I wanted encrypted SMB to my NAS.
I'll think about desktop Linux when they fix their application distribution methods
 . I dropped my Linux LabVIEW product support for a reason->my products broke every time someone else updated their product.
. I dropped my Linux LabVIEW product support for a reason->my products broke every time someone else updated their product.
-
 1
1
-
-
This all sounds very awkward for a home automation GUI.
Why would you compile software on the target? Surely all the devices are wifi with their own REST API so you only need an aggregating web server with pretty javascript front end. What am I missing?
-
27 minutes ago, Neil Pate said:
but not quite as punny... or am I just not smart enough to get that one?
Nah. It was just an icon I generated for an Ollama client.
-
17 hours ago, Neil Pate said:
Love the choice of embedded image 🙂
The llama is cuter

-
Hi all.
A bit of nerdy fun if you can spare some brain cycles.
")
I've written a Steganography API (0.9.0) and will be putting it on my site under a BSD-3 licence. It currently only uses the LSB method but I may do others if there is interest.
I've optimised it as much as I can but I expect that better people than I can improve it's performance. So. The task is to make it as fast as possible.
There is a benchmark with some images included so we can do comparative benchmarks. I'm looking forward to some innovative improvements. The winner gets a mention in the readme under SALUTATIONS.
If you can find the time and/or inclination then please post your times for the vanilla installation and then after any improvements as shown below.
Times to beat so far:
LabVIEW 2009 x64, Win10 Before Modification: Encode: 297.9 ms Decode: 98.1 ms After Modification: Encode: 297.9 ms Decode: 98.1 ms
Oh yes. And finally. If you find any bugs, let me know and I'll fix them.
-
1 hour ago, viSci said:
Bridgeview? You must be old as the hills
I think if back then they had our modern DDS options We would have never had to suffer NSV’s and the product might be still viable today.
I couldn't see the hills because they were covered in glaciers.
-
1 hour ago, viSci said:
Remember the venerable DSC toolkit?
I even remember BridgeVIEW

-
On 9/30/2025 at 12:43 PM, hooovahh said:
can the tag be based on the Caption of the control not the label? That way it can change at runtime
Just be aware that the Caption property is often used for translations.
-
1 hour ago, BitPack Tools said:
By the way, could you share what exact problem you had with the temporary file?
No problem. I just hadn't created a TRUE boolean so that the image is returned (default is false). I usually expect indicators to return things, except if there is an error, and not be conditional on other inputs.
-
Nice.
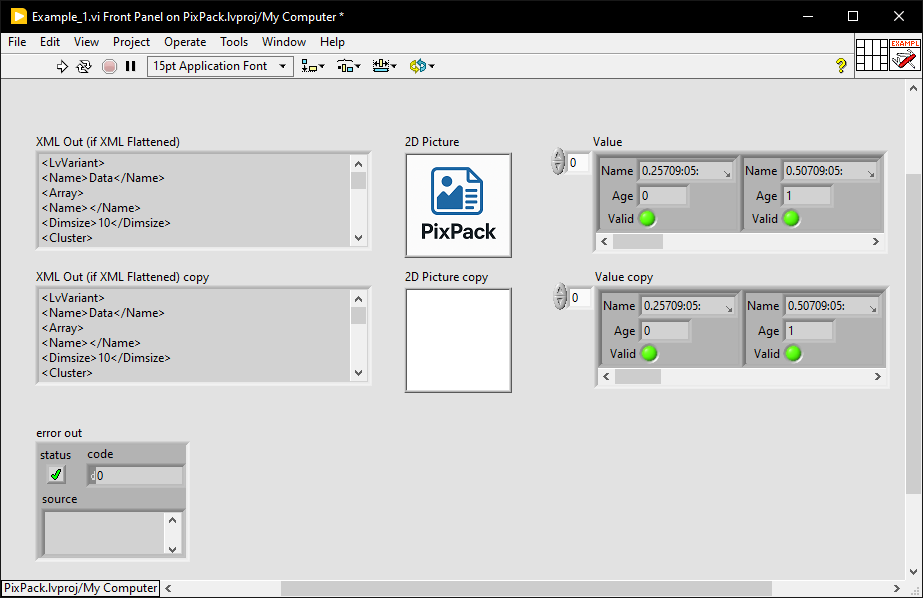
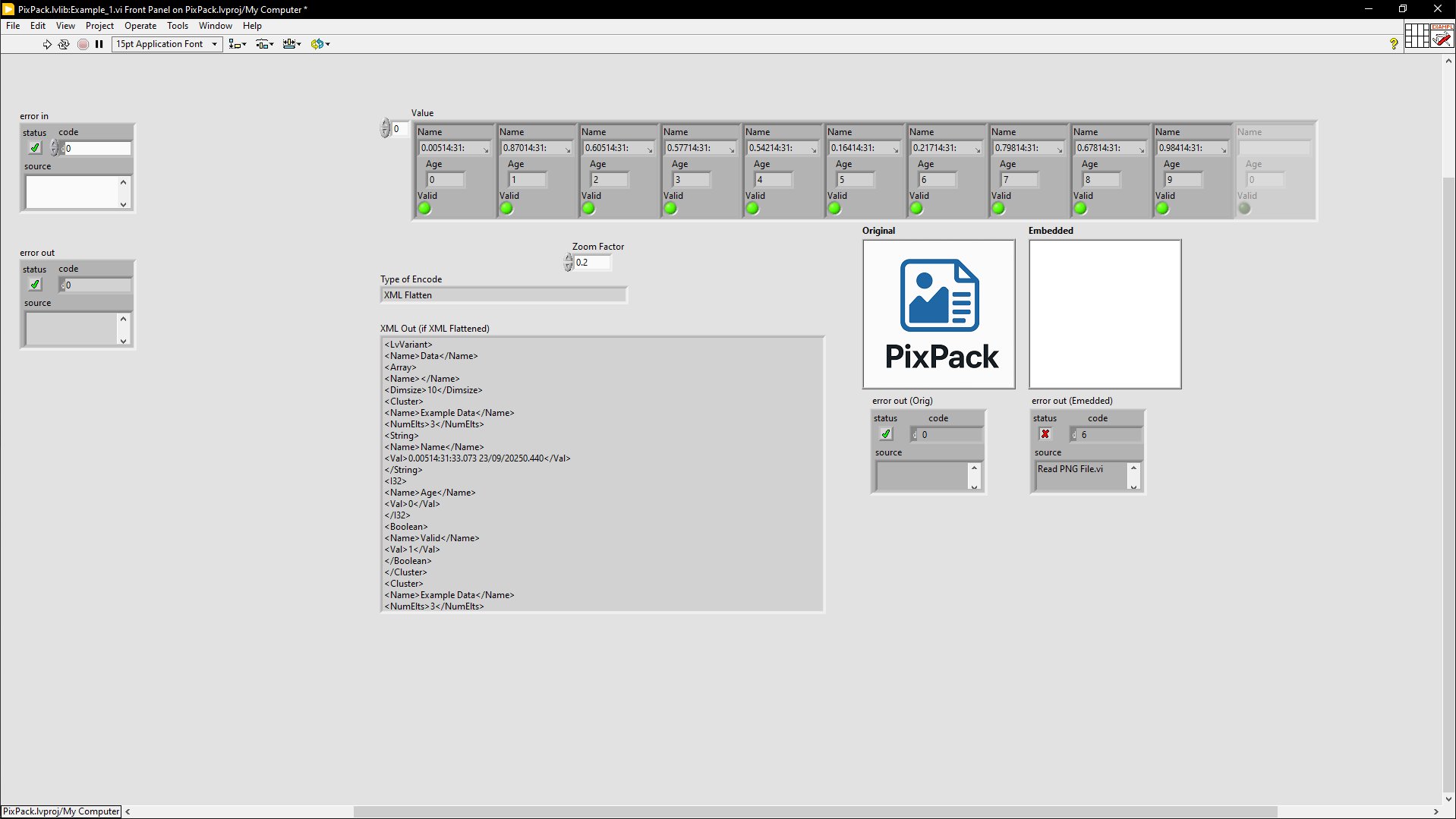
While I was trying to figure out why I wasn't getting the image (because there is a boolean to return it
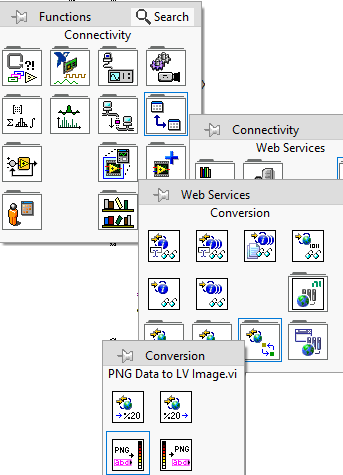
 ); I noticed you used a temporary file for the png image. There is a better option in the Web Services palette which means you can directly convert a byte string into a LV image without an intermediary file:
); I noticed you used a temporary file for the png image. There is a better option in the Web Services palette which means you can directly convert a byte string into a LV image without an intermediary file:
As you now have two different connector-panes for different modes of operation (text and file embedding), you might want to consider whether a polymorphic VI would be useful for their adapt-to-type feature.
Finally. If you are going to distribute the 7zip binary rather than requiring the end user to download it; don't forget to heed the copyright. They want you to add the actual LGPL text rather than reference a URL.
QuoteRedistributions in binary form must reproduce related license information from this file.
-
13 hours ago, BitPack Tools said:
I am fully aware of the drawbacks of this approach.
Your customers also need to be aware of any drawbacks and caveats. If the filename is used as a key for an encryption scheme then perhaps it should be mentioned in the documentation and, additionally, what scheme you are using. I think this will be the most common reason people will seek support from you.
I won't harp on much more about the MGI licence but just say, finally, I don't think you fully understand the issue, which could have been completely avoided.
Just for reference, I have attached my test harness from above in LV2019.
-
2 hours ago, BitPack Tools said:
so there is no hidden copyright issue
There is. If they create an executable they need to add the copyright to their documentation or distribution in some way as the licence is contained in the MGI VI's description.
2 hours ago, BitPack Tools said:You also mentioned “Data does not survive a copy operation”. Could you clarify or give me an example? I’d like to reproduce that issue, since I haven’t encountered it myself.
-
OK. Now we're cooking with gas.
Some minor (and one major*) comments.
- Data does not survive a copy operation.*
- Error in (No error) shouldn't be required.
- Add a document that states the licence conditions that you are distributing under (e.g. MIT, BSD, Creative Commons etc)
- Use a Hex Encode and Decode you have written. Don't use the two MGI utilities.
-
Make your logo smaller.
With regards #4.
You are only using two MGI utils to convert to and from hex chars. That can easily be done natively without requiring installation of a 3rd party toolkit. Using those two requires the end user add an additional copyright statement to their binary distribution that they may not be aware of (were you?). Save them (and yourself) the copyright issues.
Quote* Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
If you are going to use 3rd party toolkit, require they install them as a dependency then you will not have copyright issues ... but you don't need it for this.
-
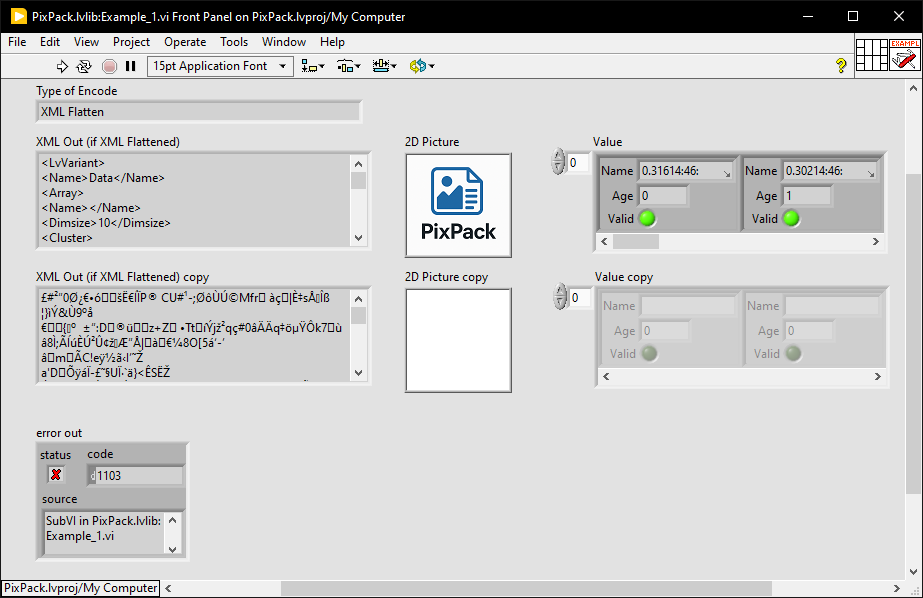
It doesn't seem to produce a valid png (either as XML or "not encoded").
I've changed the extension name of the produced file (.notaping) because the web interface will not allow uploading as a png.
-
2 hours ago, hooovahh said:
Here is the Community Edition announcement. https://www.jki.net/blog/news/vipm-2020-community-edition
Perfect for the OP if that suffices then.
-
13 hours ago, hooovahh said:
This feature is the VI Package Configuration (VIPC) and is free and included in the community version of VIPM.
Just download VIPM today and activate a 30day trial to try out VIPC files.
Pretty sure it is a pro feature. You may be able to use VIPC files in the Community version but I'm sure you can't create them without the pro version. Maybe it's changed since I last looked though.
LabVIEWs response time during editing becomes so long
in LabVIEW General
Posted
Yes. But not a good enough reason.