

ShaunR
-
Posts
5,029 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
Probably not the feedback you are expecting but we really should do something about the nasty root loop API calls in the input API.
I have somewhat progressed with this over the years and have the windows stuff all working for mouse and keyboard (and a little of the Linux) but I don't have a Mac so can't do anything on that. If there is some interest then let me know and I will see if I can allocate time to getting an API together.
-
 1
1
-
-
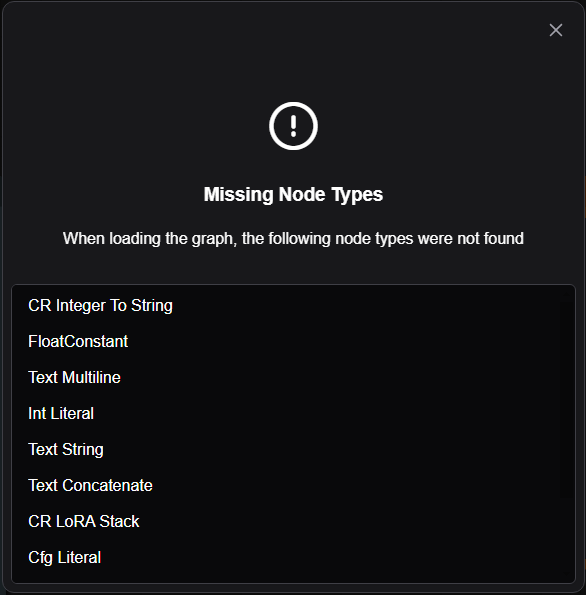
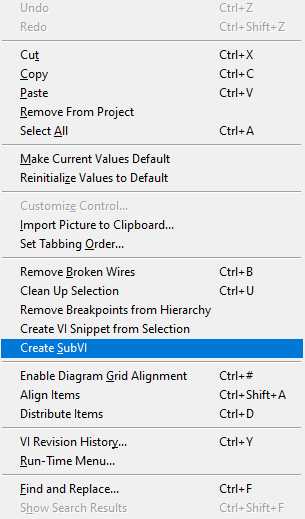
It's not April yet so I must have missed a memo somewhere.
How do I get For Loop conditional terminal back?

-
The boolean basically does:
-
I have similar problems now and again but it's not VIM's.
Some things to try to sniff out the problem:
Check project files and lvlibs with a text editor. If you have full file paths then that's a problem. File paths should be relative BUT! LabVIEW cannot always use a relative path (for example if it's on a network, different drives et.al.) Sometimes LabVIEW also gets confused but you need all paths to be relative even if it means reorganising how you structure your files.
Do the above and put all dependencies in VI.lib. If you are using source control, checkout dependencies to the VI.lib directory, not your own file organisational preferences (some people like to have them on a different drive, for example). The litmus test for this is that you should be able to move your project to different locations without getting the VI searching dialogue. The search will invariably put a full path in when it finds the file-don't let it.
Recursion breaks the project conflict resolution. If you have recursive functions, make sure they are not broken by manual isepction. The usual symptom is that there are no errors in the error dialogue but conflicts exist and VI's are broken somewhere.
Polymorphic VI's hate recursion. If you are using polymorphic VI's recursively, don't use the polymorphic container (the thing that gives you the drop-down selector)! Only use polymorphic VI's as interfaces to other code - not itself. If you are using the polymorphic VI recursively then use the actual VI not the polymorphic container. If something gets broken you will go round in circles never getting to the broken code and multiple things will be broken.
-
Nice.
If you replace the OpenG VI with the above then we don't need to install all those dependencies for your demo
")
What do you expect the cancellation behviour to be? Press escape while holding the mouse down? Mouse up cancels unless the dragged window is outside the main window? Both? Something else?
I wouldn't want this feature to be a "framework" though. It would need to be much easier than that. Maybe a VI that accepts control references and it just works like above on those controls?
-
You are probably getting a permissions error on the Open (windows doesn't ordinarily allow writing "c:") which will yield a null refnum and an err 8 on the open. Your err 5000 becomes a noop as does the write. You're then clearing that error so when you come to close the null refnum it complains it's an invalid parameter - equivalent to the following.
Is it expected behaviour? Yes. Should it report a different error code? Maybe.
-
 1
1
-
-
10 minutes ago, Rolf Kalbermatter said:
Faster is a bit debatable. 😁 The scripting method took me less than half an hour to find out that it doesn't return what I want.
Faster execution than scripting. Scripting is incredibly slow.
-
On 12/5/2024 at 12:47 PM, Rolf Kalbermatter said:
No joy in trying to get the wildcard name. That's rather frustrating!
Well. You could get it from the file. It's under the block diagram heap (BDHP) which is a very old structure. I personally wouldn't bother for the reasons I stated earlier but it would be much faster than using scripting.
-
32 minutes ago, Rolf Kalbermatter said:
It depends what your aim is. If your aim is to get something working most of the time with as little modification as possible to the OpenG OGB library, then yes you want to guesstimate the most likely wildcard name, with some exception handling for specially known DLL names during writing back the Linker Info.
Yes. This is exactly what is required. The User32 problem can be resolved either with file path comparison (which you stated earlier) or a list of known DLL names. I could think of a few more ways to make it automatic but I would lean to the latter as the developer could add to the list in unforeseen edge cases. The former might just break the build with no recourse.
37 minutes ago, Rolf Kalbermatter said:If your aim is to use the information that LabVIEW is using when it loaded the VIs into memory, you want to get the actual Call Library Name.
You seem to have added that for no apparent reason, from what I can tell.
-
4 minutes ago, Rolf Kalbermatter said:
It does. The Call Library Node explicitly has to be configured as user32.dll or maybe user32.*. Otherwise, if the developer enters user*.*, it won't work properly when loading the VI in 64-bit LabVIEW.
This is the same as naming a DLL x32 or x64 with extra steps. You are now adding a naming convention to a read linker and a modify linker. It's getting worse, not better.
-
3 minutes ago, Rolf Kalbermatter said:
It's pretty simple. You want to get the real information from the Call Library Node, not some massaged and assumed file name down the path. Assume starts with ass and that is where it sooner or later bites you! 😀
The Call Library Node knows what the library name is that the developer configured. And that is the name that LabVIEW uses when you do your unit tests. So you want to make sure to use that name and not some guesstimated one.
That doesn't help you with user32.dll.
-
16 hours ago, Rolf Kalbermatter said:
Yes, my concern is this. It's ok for your own solution, where you know what shared libraries your projects use and how such a fix might have unwanted effects. In the worst case you just shoot in your own foot. 😀
But it is not a fix that could ever be incorporated in VIPM proper as there is not only no way to know for what package builds it will be used, but an almost 100% chance that an affected user will simply have no idea why things go wrong, and how to fix it. If it is for your own private VIPM installation, go ahead, do whatever you like. It's your system after all. 😀
That is a given. The only issue I would have there is when VIPM is updated.
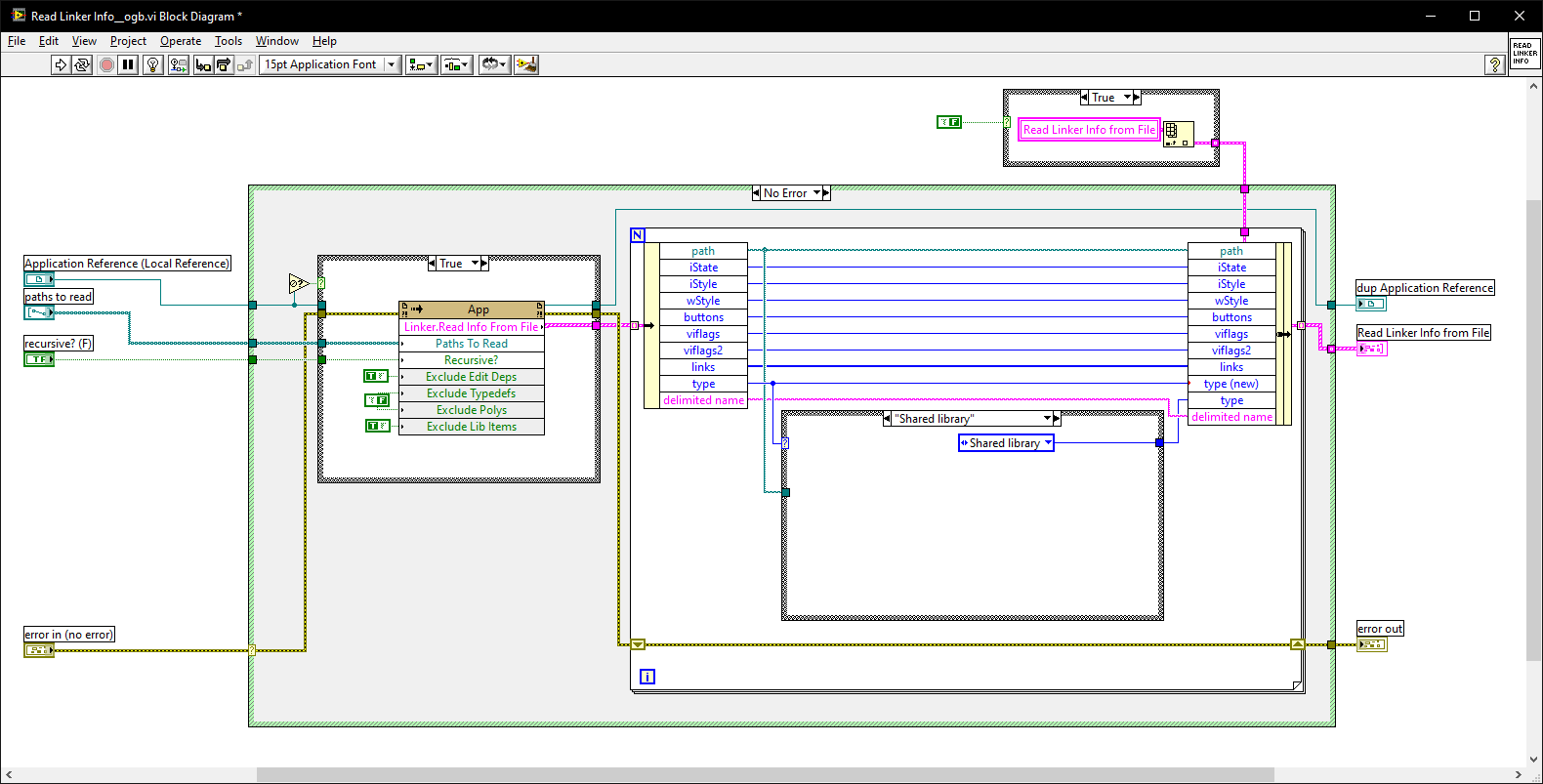
However, you still have not explained why the "Extract Resources Info From Linker Info.vi" needs modification if all modifications can be achieved in the "Copy Resource Files and Relink VIs__ogb.vi"
-
37 minutes ago, hooovahh said:
I wasn't suggesting you were whiners. If I ask for support from NI I don't think that makes me a whiner. I was suggesting the changes you are proposing are useful for everyone, and that if you have useful changes, all VIPM users can benefit from them by having JKI use what you've developed. Because you are a developer. I also asked that question because I wanted to know incite into why VIPM does what it does so I can be a better developer.
I think it was just tongue-in-cheek whimsy.
2 hours ago, Rolf Kalbermatter said:Actually I'm more inclined to hack things here:
I'm still not convinced it needs fixing around there at all. As far as I can tell, it only needs to be fixed at the original VI you proffered. The only issue you seemed to have is when a binary that isn't part of the developers distribution has a 32 or 64 on it (like user32.dll). I'd be more inclined to think of your initial suggestion of comparing paths to circumvent that though.
-
1 hour ago, Rolf Kalbermatter said:
This assumes that all the library paths are properly wildcard formatted prior to starting the build process as it will maintain the original library name in the source VIs.
That may be a problem and I don't really see why it needs to be so. Is this just to resolve files that are named like user32.dll?
The entry point for what you suggest seems to be here:
-
On 12/2/2024 at 4:04 PM, hooovahh said:
VIPM has the linking to a full path to the DLL, so renaming that linked path on install seemed like an easy way to make it work the way I wanted.
Yes. This is why we have the post install VI's. There are other edge-case issues too, that cannot be resolved just by renaming.
On 12/2/2024 at 4:04 PM, hooovahh said:A post install fixing the paths work as well, and in fact Jim posted a VI that can fix the paths on post install.
Yes. That is not a viable solution.
However, what we are talking about is modifying the og libraries that VIPM uses to build (they are distributed as source), and fixing the paths BEFORE VIPM adds it to the the install so we don't need the Post Install at all.
-
On 11/28/2024 at 7:59 AM, Stinus Olsen said:
As an experiment, this would be pretty cool - but quite an undertaking I think.
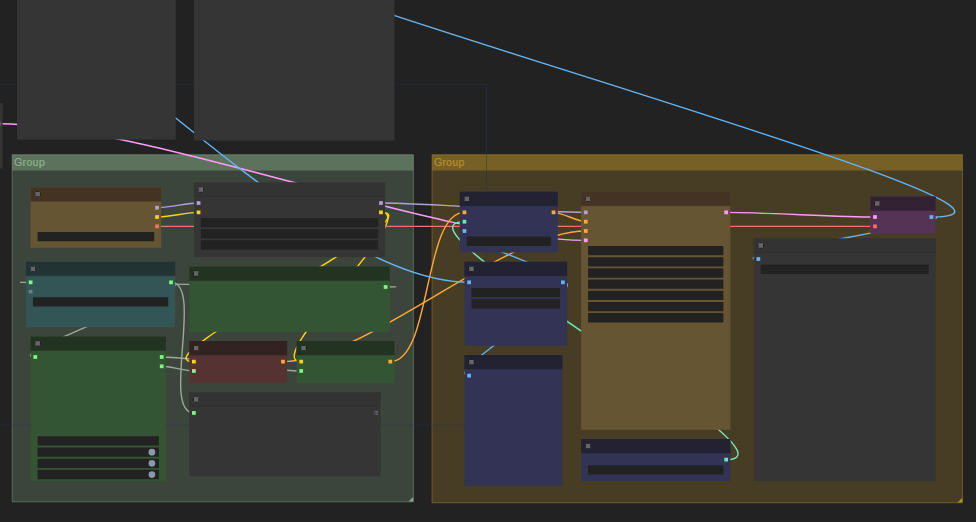
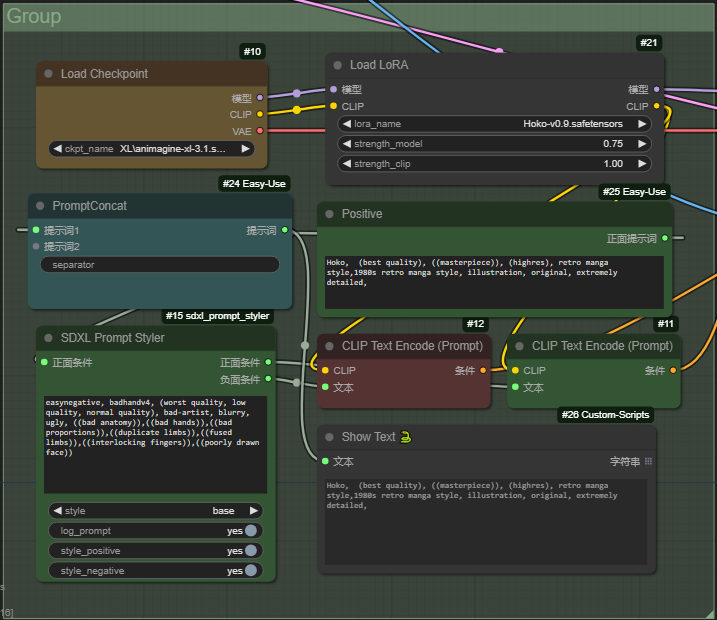
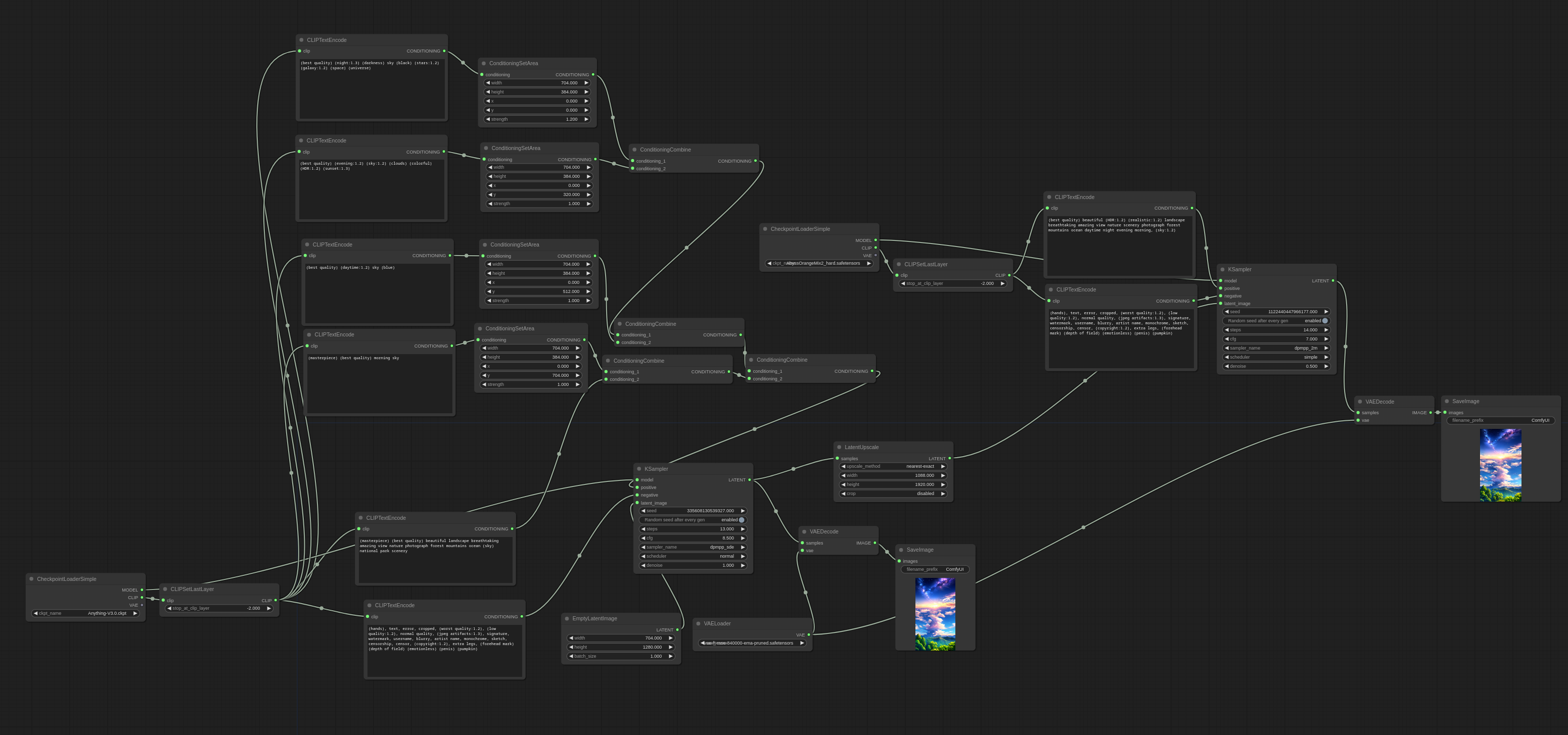
Personally though, I think I'll stick with using ComfyUI/A1111 and Kohya - they don't require me to install anything other than what I need for the task 😆ComfyUIs nodes are a bit more versatile than you would think at first glance.
I personally like to convert a lot of the frequent parameters I use into inputs and then minimize the remaining workflow nodes to not clutter up the interface.
Inputs to the left, output to the right 😉A fun fact is that if you save the generated images using the Image Save node instead of the Image Preview one, the workflow is stored alongside the image data stream inside the resulting PNG file.
This allows you to load anyone of your previously generated images and immediately retrieve your workflow from that image - not much unlike how VI snippets in LabVIEW works
Comfy UI is a mess and I never seem to have the GB of models, extensions, clips or whatever other voodoo a workflow demands
 . I actually use Forge UI. That's much more manageable.
. I actually use Forge UI. That's much more manageable.
Then you can add to that that the issue that all Stable Diffusion UI's have - 50 different people created their own flavour of a plugin on Github and half of them don't bother updating it anymore because they got a real job.

More seriously though...
With ComfyUI it is that you need to know a huge number of API's and, for want of a better description, the micro-workflows to use them. Those micro-workflows can be encapsulated just as we do a sub VI.
The main criticism I have with the ComfUI is its goups.
Why can't a group be represented as a control node? The groups are unrealised analogies to subVI's.
Where is my "Create Node" option?
-
On 11/27/2024 at 2:36 PM, hooovahh said:
I'm also in Windows only land, and renaming the DLLs in a Post Install has worked well enough so far. If we in a 64 bit LabVIEW for instance the post install looks for if there are DLLs named [X].dll but there exists an [X]64.dll. If so it will delete the [X].dll and rename [X]64.dll to [X].dll. This renaming bit also works in reverse looking for [X]32.dll if we are on a 32 bit version of LabVIEW. Development then is done in one bitness statically picking the correct DLL. I have no clue how difficult or complicated this gets supporting Linux.
I think we are talking past each other.
I don't have a problem with naming. That is just what the *.* stuff does. I'm interested in what Rolf is doing to put the *.* into the node paths. I have a problem with linking-the VI search popping up during installation, VIPM not compiling everything and asking the user to save after use. This is caused by VIPM setting in concrete, the full DLL path in the nodes when it builds and not compiling certain VI's after installation.
-
On 11/27/2024 at 3:16 PM, Rolf Kalbermatter said:
I'm not really sure anymore what made me decide to go with the 32/64 bit naming
- Both binaries can be in the same directory.
- No need for a Post Install or Post Uninstall.
- No code required to choose a 32 bit or 64 bit binary in the the different LabVIEW bitnesses.
There are excellent reasons to use this nomenclature but they are thwarted by VIPM.
-
18 minutes ago, Rolf Kalbermatter said:
You look for a way to hack VIPM to do something specific for your own shared libs and leave anything else to its own trouble.
Not quite. I asked about your code to solve my issue. I offered what I thought was an improvement based on my requirements and, as I don't support Linux or Mac anymore, you could migrate it to the other systems if it was viable.
You don't like it. Fine. It works great for me but for one edge case that you have pointed out that doesn't affect me. Assuming I cannot solve that one edge case, then I have a general Windows solution with one caveat that can go in the documentation. I'd call that progress
-
17 hours ago, Rolf Kalbermatter said:
But the main problem is that I do not see how that could work properly when trying to build on 32-bit LabVIEW for DLL files that should remain with 32 in their name.
It's not a problem I have. I name them x32 and x64, if necessary, so there is no issue with the likes of user32.dll.
What I do have a problem with is binaries which can be 32 or 64 bit but there is no indication in the name and the path gets "fixed" by VIPM (similar problem with TPLAT). In that scenario I want the ".*" on the end only. That is the problem it is solving and why I said I wasn't sure about the full path (I think I want just the filename). Until now I have had a similar solution to you (force changes in Post_Install and make LabVIEW search for the binaries so linking them on first load). The main difference in my solution is, perhaps, that Post_Install has the binaries in arrays on the BD and the correct bitness is saved out when installed by the user. I wanted something where I didn't update the Post_Install every time binaries changed.
Perhaps we are solving different issues due to different workflows. -
3 hours ago, Rolf Kalbermatter said:
Also don't try to read the file for the non-Windows cases as you don't do anything with that anyhow!
Feel free to add them in.
-
1 hour ago, codcoder said:
Doesn't sound too hard?
The comfyUI nodes are described by JSON in files called "Workflows" so we could import them and use scripting to create nodes. That's if we want parity. But we could support nesting which ComfUI wouldn't understand.
The WebUI's are just interfaces to create REST requests which we can easily do already. I'm just trying to find a proper API specification or something that enables me to know the JSON format for the various requests. Like most of these things, there are just thousands of Github "apps" all doing something different because they use different plugins. Modern programmers can do wonderful things but it's all built on tribal knowledge which you are expected to reverse engineer. The only proper API documentation I have found so far is for the Web Services which isn't what I want - I'm running it locally.
-
1
-
-
I've been playing around with an A.I. Imaging software called Stable Diffusion. It's written in Python but that's not the part that interests me...
There are a number of web browser user Interfaces for the Stable diffusion back-end. Forge, Automatic 1111, Comfy UI - to name a couple - but the last one, comfy UI, is graphical UI.
The ComfyUI block diagram can be saved as JSON or within a PNG image. That's great. The problem is you cannot nest block diagrams. Therefore you end up with a complete spaghetti diagram and a level of complexity that is difficult to resolve. You end up with the ComfyUI equivalent of:
The way we resolve the spaghetti problem is by encapsulating nodes in sub VI's to hide the complexity (composition).
So. I was thinking that LabVIEW would be a better interface where VI's would be the equivalent of the ComfyUI nodes and the LabVIEW nodes would generate the JSON. Where LabVIEW would be an improvement, however, would be that we can create sub VI's and nest nodes whereas ComfyUI cannot! Further more, perhaps we may have a proper use case for express VI's instead of just being "noob nodes".
Might be an interesting avenue to explore to bring LabVIEW to a wider audience and a new technology.
-
1
-
-
On 11/19/2024 at 11:48 AM, Rolf Kalbermatter said:
It just occurred to me that there is a potential problem. If your DLLs are always containing 32 in their name, independent of the actual bitness, as for instance many Windows DLLs do, this will corrupt the name for 64-bit LabVIEW installations.
I haven't checked if paths to DLL names in the System Directory are added to the Linker Info. If they are, and I would think they are, one would have to skip file paths that are only a library name (indicating to LabVIEW to let the OS try to find them through the standard search mechanism).
This of course still isn't fail proof:
DLLs installed in the System directory (not from Microsoft though) could still use the 32-bit/64-bit naming scheme, and DLLs not from there could use the fixed 32 naming scheme (or 64 fixed name when building with VIPM build as 64-bit executable, I'm not sure if the latest version is still build in 32-bit).
I've modified your sub vi to check the actual file bitness (I think). If you target user32.dll, for example, the filename out is user32.* - which is what's expected. I need to think a bit more about what I want from the function (I may not want the full path) but it should fix the problem you highlighted (only in Windows
 ).
).
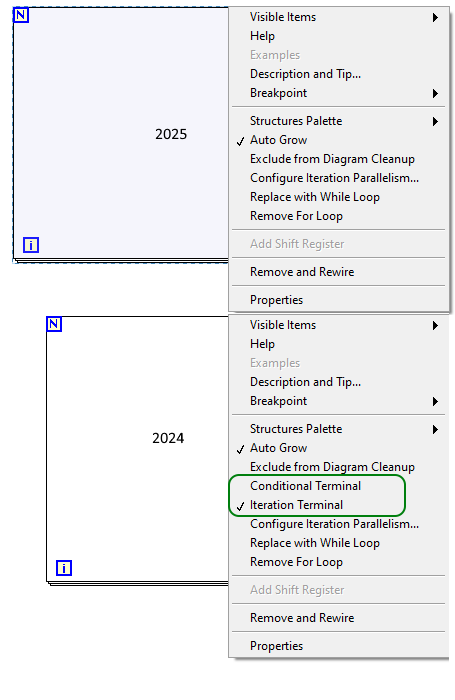

Where'd the conditional terminal go?
in Development Environment (IDE)
Posted
Makes sense.
It just goes to show how ingrained workflows are and little things can trip you up. I was right-clicking over the N, over the I. Right clicking 2 pixels down/up from the edge. Top edge, bottom edge, left right.