

ShaunR
-
Posts
4,942 -
Joined
-
Days Won
308
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
On 5/4/2025 at 1:28 PM, viSci said:
Nicely described approach Shaun. I am doing something similar with a lab automation project that involves vacuum chamber and multi-zone temperature control. Elected to use the messenger framework, which supports 'spinning up' instances and TCP capability for remote devices like cRIO. The messenger architecture also supports many types of asynchronous messaging beyond simple synchronous command/response. Your idea of decoupling EC sequencing logic is good, moving it out of the EC subsystem to allow synchronization with other subsystems during ramp/soak profiles. Hey remember Test Stand Lite? This is where an such a scripting component would really shine and be a great benefit to the community.
You can script with text files with #1. Just adding a feature to delay N ms gets you most of the way to a full scripting language (conditionals and for-loops are what's left but a harder proposition). However, for a more general solution I use services in #2 with queue's for inputs and events for outputs. There was a discussion ages ago at whether queues were needed at all since LabVIEW events have a hidden queue but you can't push to the front of them (STOP message
") ) and, at the time, you couldn't clear them so I opted for proper queues. So, architecturally, I use "many to one" for inputs and "one to many" for outputs.
) and, at the time, you couldn't clear them so I opted for proper queues. So, architecturally, I use "many to one" for inputs and "one to many" for outputs.
-
OK. This is how I design systems like this.
1. TCP. Each subsystem has a TCP interface. This allows spinning up "instances" then connecting to them even across networks. You can rationalise the TCP API and I usually use a thin LabVIEW wrapper around SCPI (most of your devices will support SCPI). You can also use it to make non SCPI compliant devices into SCPI ones (your Environmental Chamber - EC - is probably one that doesn't support SCPI). If you do this right, you can even script entire tests from a text file just using SCPI commands.
2. Services. Each subsystem offers services. These are for when #1 isn't enough and we need state. A good example of this is your Environmental Chamber. It is likely you will have temperature profiles that control signals and measurements need to be synchronized with. While services may be devices (a DVM, for example), services can also be synchronization logic that sequences multiple devices. If you put that logic in your EC code, it will fix that code for that specific sequence so don't do that. Instead use services to glue other devices (like the DVM and EC) into synchronization processes. Along with #1, this will form the basis of recipe's that can incorporate complex state and sequencing. In this way you will compartmentalize your system into reusable modules. First thing you should do is make a "Logging" service. Then when your devices error they can report errors for your diagnostics. The second thing should be a service that "views" the log in real-time so you can see what's going on, when it's going on. (This is why we have logging levels).
3. Global State. If you have 1 & 2 this can be anything. It can be a text file with a list of SCPI commands (#1). It can be a service you wrote in #2, Test Stand, web page or a bash/batch script. This is where you use your recipe's to fulfill a test requirement.
4. You will need to think carefully about how the subsystems talk to each other. For example. Using SCPI a MEAS :VOLT:DC? command returns almost instantly (command-response pattern). However for the EC you may want to wait until a particular temperature has been reached before issuing MEAS :VOLT:DC?. The problem here is that SCPI is command-response but the behavior required is event driven. One could make the the TCP interface (#1) of the EC accept MEAS :TEMP? where the command doesn't return unless the target setpoint has been reached. However, this won't work reliably and requires internal state and checks for the edge cases though. So it may actually be better in #2. There are a number of ways to address these things using #1, #2 or #3 and that is why you are getting the big bucks.
You will notice I haven't mentioned specific technologies here (apart for TCP). For #1 you shouldn't need anything other than reentrant VI's and VI Server. For #2 you can use your favourite foot-shooting method but notice that you are not limited to one type and can choose an architecture for the specific task (they don't all have to be QMH, for example). For #3 you don't even have to use LabVIEW.
-
3 hours ago, Rolf Kalbermatter said:
Well, except that LLBs only have one hierarchy level and no possibility to make VIs private for external users.
You actually have 2 levels with LLB's (semanticly) and that's more than enough for me.
I also don't agree with all the private stuff. Protected should be the minimal resolution so people can override if they want to but still be able to modify everything without hacking the base. This only really makes sense in non-LabVIEW languages though so protected might as well be private in LabVIEW. And don't get me started with all that guff on "Friends"

But in terms of containers, external users can call what they like as far as I'm concerned but just know only the published API is supported. So making stuff private is a non-issue to me. If I'm feeing generous and want them to call stuff then I make it a Top Level vi in the LLB. Everything else is support stuff for the top level VI's so call it at your peril.
I still maintain PPL's are just LLB's wearing straight-jackets and foot-shooting holsters.

-
On 4/11/2025 at 11:19 AM, Rolf Kalbermatter said:
Libraries are the pre-request to creating packed libraries
*prerequisite.
Packed libraries are another feature that doesn't really solve any problems that you couldn't do with LLB's. At best it is a whole new library type to solve a minor source code control problem.
-
There isn't anything really special about lvlibs. They are basically containers with a couple of bells and whistles. If you look at them with a text editor you will see it's basically a list of VI's in an XML format.
The main reason I use them is that they can be protected with the NI 3rd Party Activation Toolkit. A secondary reason I use them is for organisation and partitioning. It would be frowned upon by many but I use lvlibs for the ability to add virtual directories and self populating directories for organisation and contain the actual VI's in llb's for ease of distribution.
I don't see them as a poor-mans class, rather a llb with project-like features.
-
On 4/7/2025 at 6:38 PM, viSci said:
Asked GrokAI and got a working example...
This is the modern 2020's equivalent of "works for me".
-
 2
2
-
-
I find it interesting that spam really wasn't an issue until the forums were upgraded.

I run old software on my website and I've noticed a reduction in spam attempts as time goes on and the scanners update to newer exploits. I was getting spam through the on-site contact form as they were bypassing the CAPTCHA. It's prevented with a simple .htaccess RewriteCond but when I recently upgraded the website OS I turned it off. It took a month for a scanner to find it and start spamming and it only sent every hour. A few years ago it took something like 30 minutes and they sent every 5 minutes.
By far the most effective methods to stop spam are
- Checking for reverse DNS resolution.
- Checking against known blacklists (like spamhaus.org).
- Offering honeypot files or directories (spider traps).
#2 tends to have a low false positive rate but [IMHO] even 1 false positive is unacceptable for mail - although might be acceptable for a forum.
I also wrote a spam plugin for my CMS which basically did the above first 2 things and a couple of other things like checking against a list of common disposable email addresses, checking user agents and so on. The way those things work is they tend to ban the IP address for an amount of time but I didn't want to ban someone that was trying to send an message through the site maybe because an email had bounced ; so I turned it off.
-
58 minutes ago, Rolf Kalbermatter said:
The namespace of the subVIs themselves changes, so I'm afraid that separation of the compiled code alone is not enough. The linking information in the diagram heap has to be modified to record the new name which now includes the library namespace. As long as it is only a recompilation of the subVI, separation of compiled code in the caller indeed should not require a recompilation of the caller, but name changes of subVIs still do.
In fact the automatic relinking from non-namespaced VIs to library namespaced VIs is a feature of the development environment but there is no similar automatic reversal of this change.
If that's the case then is this just a one-time, project-wide, recompilation? Once relinked with the new namespaces then there shouldn't be any more relinking and recompiling required (except for those that have changed or have compiled code as part of the VI).
-
On 4/23/2024 at 8:52 AM, Rolf Kalbermatter said:
The change to "librarize" all OpenG functions is a real change in terms of requiring any and every caller to need to be recompiled. This can't be avoided so I'm afraid you will either have to bite the sour apple and make a massive commit or keep using the last OpenG version that was not moved to libraries (which in the long run is of course not a solution).
Wasn't separate compiled code meant to resolve this issue? Is it just that some of the VI's were created before this option and so still keep compiled code?
-
21 hours ago, hooovahh said:
and the automatic garbage collector takes care of it
There is no automatic garbage collector. It's an AQ meme that he used to rage about it.
-
10 hours ago, BTS_detroGuy said:
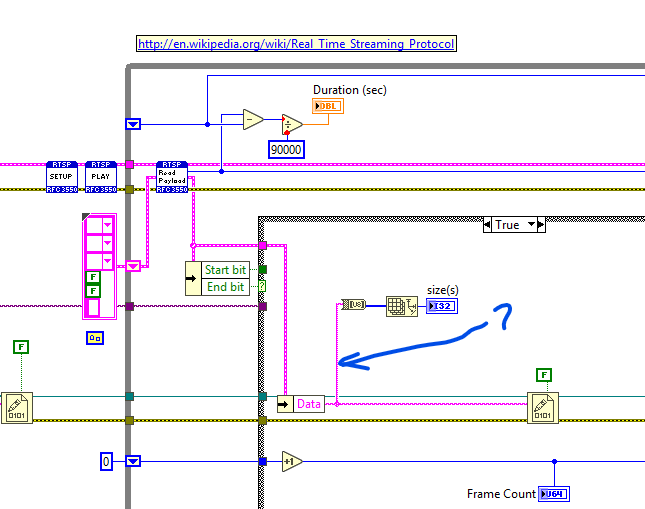
ShaunR, To my surprise the PURE LABVIEW solution is working great for reading and logging the video stream. Unfortunately two issues i am facing.
1) The video stream it's saving to Disk is not saving the audio data. However i can play the muted video in VLC player after the file is finalized.
2) I have not been able to parse the 'Data' to extract the video and audio data for live display.
I found another solution that uses FFMPEG but it seem to corrupt the first few frames. I will keep trying.
I liked the RTSP solution better (compared to VLC DLL based solution) because it provides the TCP connection ID. I am hoping to use it for sending the PTZ commands once i figure out the right ones.

Indeed. It's not a full solution as it doesn't support multiple streams, audio or other encoding types. But if you want to get the audio then you need to add the decoding case (parse is the nomenclature used here) for the audio packets in the read payload case structure.
-
 1
1
-
-
IIRC there are a couple of RTSP libs for around (a while ago now). Some are based on using the VLC DLL's and I even saw one that was pure LabVIEW. Might be worth having a look at them for "inspiration".
-
1
-
-
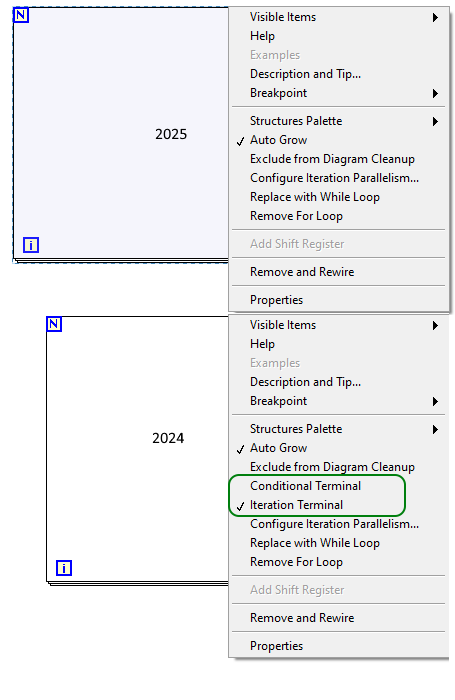
Makes sense.
It just goes to show how ingrained workflows are and little things can trip you up. I was right-clicking over the N, over the I. Right clicking 2 pixels down/up from the edge. Top edge, bottom edge, left right.
-
1
-
-
Probably not the feedback you are expecting but we really should do something about the nasty root loop API calls in the input API.
I have somewhat progressed with this over the years and have the windows stuff all working for mouse and keyboard (and a little of the Linux) but I don't have a Mac so can't do anything on that. If there is some interest then let me know and I will see if I can allocate time to getting an API together.
-
1
-
-
It's not April yet so I must have missed a memo somewhere.
How do I get For Loop conditional terminal back?
-
The boolean basically does:
-
I have similar problems now and again but it's not VIM's.
Some things to try to sniff out the problem:
Check project files and lvlibs with a text editor. If you have full file paths then that's a problem. File paths should be relative BUT! LabVIEW cannot always use a relative path (for example if it's on a network, different drives et.al.) Sometimes LabVIEW also gets confused but you need all paths to be relative even if it means reorganising how you structure your files.
Do the above and put all dependencies in VI.lib. If you are using source control, checkout dependencies to the VI.lib directory, not your own file organisational preferences (some people like to have them on a different drive, for example). The litmus test for this is that you should be able to move your project to different locations without getting the VI searching dialogue. The search will invariably put a full path in when it finds the file-don't let it.
Recursion breaks the project conflict resolution. If you have recursive functions, make sure they are not broken by manual isepction. The usual symptom is that there are no errors in the error dialogue but conflicts exist and VI's are broken somewhere.
Polymorphic VI's hate recursion. If you are using polymorphic VI's recursively, don't use the polymorphic container (the thing that gives you the drop-down selector)! Only use polymorphic VI's as interfaces to other code - not itself. If you are using the polymorphic VI recursively then use the actual VI not the polymorphic container. If something gets broken you will go round in circles never getting to the broken code and multiple things will be broken.
-
Nice.
If you replace the OpenG VI with the above then we don't need to install all those dependencies for your demo
What do you expect the cancellation behviour to be? Press escape while holding the mouse down? Mouse up cancels unless the dragged window is outside the main window? Both? Something else?
I wouldn't want this feature to be a "framework" though. It would need to be much easier than that. Maybe a VI that accepts control references and it just works like above on those controls?
-
You are probably getting a permissions error on the Open (windows doesn't ordinarily allow writing "c:") which will yield a null refnum and an err 8 on the open. Your err 5000 becomes a noop as does the write. You're then clearing that error so when you come to close the null refnum it complains it's an invalid parameter - equivalent to the following.
Is it expected behaviour? Yes. Should it report a different error code? Maybe.
-
 1
1
-
-
10 minutes ago, Rolf Kalbermatter said:
Faster is a bit debatable. 😁 The scripting method took me less than half an hour to find out that it doesn't return what I want.
Faster execution than scripting. Scripting is incredibly slow.
-
On 12/5/2024 at 12:47 PM, Rolf Kalbermatter said:
No joy in trying to get the wildcard name. That's rather frustrating!
Well. You could get it from the file. It's under the block diagram heap (BDHP) which is a very old structure. I personally wouldn't bother for the reasons I stated earlier but it would be much faster than using scripting.
-
32 minutes ago, Rolf Kalbermatter said:
It depends what your aim is. If your aim is to get something working most of the time with as little modification as possible to the OpenG OGB library, then yes you want to guesstimate the most likely wildcard name, with some exception handling for specially known DLL names during writing back the Linker Info.
Yes. This is exactly what is required. The User32 problem can be resolved either with file path comparison (which you stated earlier) or a list of known DLL names. I could think of a few more ways to make it automatic but I would lean to the latter as the developer could add to the list in unforeseen edge cases. The former might just break the build with no recourse.
37 minutes ago, Rolf Kalbermatter said:If your aim is to use the information that LabVIEW is using when it loaded the VIs into memory, you want to get the actual Call Library Name.
You seem to have added that for no apparent reason, from what I can tell.
-
4 minutes ago, Rolf Kalbermatter said:
It does. The Call Library Node explicitly has to be configured as user32.dll or maybe user32.*. Otherwise, if the developer enters user*.*, it won't work properly when loading the VI in 64-bit LabVIEW.
This is the same as naming a DLL x32 or x64 with extra steps. You are now adding a naming convention to a read linker and a modify linker. It's getting worse, not better.
-
3 minutes ago, Rolf Kalbermatter said:
It's pretty simple. You want to get the real information from the Call Library Node, not some massaged and assumed file name down the path. Assume starts with ass and that is where it sooner or later bites you! 😀
The Call Library Node knows what the library name is that the developer configured. And that is the name that LabVIEW uses when you do your unit tests. So you want to make sure to use that name and not some guesstimated one.
That doesn't help you with user32.dll.


Software architecture for modular measurement system in a battery and electronics testing laboratory
in Application Design & Architecture
Posted
How does this work?