

ShaunR
-
Posts
4,942 -
Joined
-
Days Won
308
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
Try resetting the windows theme. Settings>Themes>Pointers.
Choose another, apply then set it back to default. See if that helps.
-
Maybe we should move this hijack to another thread? Has nothing to do with DVR's really. Maybe move it here?
https://lavag.org/topic/22860-chatgpt-and-labview/page/2/
On 7/2/2025 at 8:30 PM, Rolf Kalbermatter said:It's in some ways a real advancement, if you are fine with the increased fuzziness of the resulting answer.
It's worse than that. Sometimes it outright lies. A.I. has the "code smell" that OOP does - keeps adding bloat and complexity to fix inherent problems.
Because A.I. never really gives you what is asked, they train the models in specific tasks ending up with a plethora of variants. Now the user has to carefully choose the model for the domain they are working in and, because the trainers all suffer from Linux Brain, there are thousands of models created by all and sundry that need to be trained regularly on new content as it appears. They even created a new domain of "Agentic A.I." which are, IMO, corrective snippets because it doesn't work as intended.
By the way. I'm not saying A.I. has failed. I'm just saying it's nowhere near where they say it is. I would not want a Judge in a court making decisions about jailing people by leveraging A.I. Similarly, I would not want to write a customer project using A.I.
I tried the above bug with another A.I. model (qwen3-coder). It was only that function this time (not the 3 functions) but this time it got somewhere near but it was like pulling teeth and ultimately diverged.
>>> The following code has a bug that returns 0.0.0.0 as the IPv4 address from "recvfrom" when it should be returning "1 ... 27.0.0.1". Find the reason that the code is returning 0.0.0.0 instead of 127.0.0.1 and rewrite the code to fix the i ... ssue. ... ``` ... int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { ... int err = 0; ... *IPvType = 0; ... switch (addr.ss_family) { ... case AF_INET6: { ... if (Address == NULL) {return 46;} ... *IPvType = 2; ... char strAddress[46]; ... inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); ... break; ... } ... case AF_INET: { ... if (Address == NULL) {return 16;} ... *IPvType = 1; ... char strAddress[16]; ... inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); ... break; ... } ... default: {err = WSAEPROTONOSUPPORT; break;} ... } ... *Port = ntohs(((sockaddr_in6 *)&addr)->sin6_port); ... return err; ... } ... ``` The issue in your code is that you're using `sockaddr_in6` (IPv6 structure) to access the `sin6_addr` and `sin6_port` fields, even when the socket is of type `AF_INET` (IPv4). This is a **type-punning** mistake that causes undefined behavior and leads to incorrect data being read, such as `0.0.0.0` for IPv4 addresses. --- ### 🔍 **Why is it returning 0.0.0.0 instead of 127.0.0.1?** - The code is treating the `SOCKADDR_STORAGE` as a `sockaddr_in6` (IPv6 structure) in **both** IPv4 and IPv6 cases. - For IPv4, you should be using `sockaddr_in`, not `sockaddr_in6`. - The `sin6_addr` field is part of `sockaddr_in6`, not `sockaddr_in`. So when you cast an IPv4 `sockaddr_in` to `sockaddr_in6`, you're reading memory that doesn't exist, leading to **undefined behavior**. - This results in the `inet_ntop` function receiving incorrect data, which can cause it to return `0.0.0.0` or other invalid values. --- ### ✅ **Corrected Code** Here's the fixed version of your function: ```c int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) { return 46; } *IPvType = 2; char strAddress[46]; inet_ntop(AF_INET6, &((sockaddr_in6 *)&addr)->sin6_addr, strAddress, sizeof(strAddress)); strncpy(Address, strAddress, sizeof(strAddress)); break; } case AF_INET: { if (Address == 0) { return 16; } // Address == NULL is not a valid check here *IPvType = 1; char strAddress[16]; inet_ntop(AF_INET, &((sockaddr_in *)&addr)->sin_addr, strAddress, sizeof(strAddress)); strncpy(Address, strAddress, sizeof(strAddress)); break; } default: { err = WSAEPROTONOSUPPORT; break; } } *Port = ntohs(((sockaddr_in *)&addr)->sin_port); return err; } ``` --- ### 🔧 **Key Fixes and Improvements** 1. **Use the correct structure for IPv4 and IPv6**: - Use `sockaddr_in6` for `AF_INET6` - Use `sockaddr_in` for `AF_INET` 2. **Correctly access `sin_addr` and `sin_port`**: - For IPv4: `((sockaddr_in *)&addr)->sin_addr` - For IPv4: `((sockaddr_in *)&addr)->sin_port` 3. **Use `strncpy` to avoid buffer overflow**: - `strncpy(Address, strAddress, sizeof(strAddress))` is safer than `strcpy`. 4. **Fix the `Address == 0` check**: - `Address == 0` is not valid in C. Use `Address == NULL` instead. --- ### ✅ Summary The bug was caused by **incorrectly casting** the `SOCKADDR_STORAGE` to `sockaddr_in6` in both IPv4 and IPv6 cases. This led to reading invalid memory and returning `0.0.0.0` instead of the correct `127.0.0.1` address. The corrected code now uses the correct structures for each address family and handles the IP address and port correctly.
So it found the bug I asked for but overlooked the port. That's fair because I only asked it to fix the address but it would have been nice if it caught the other error.
>>> The port is using sockaddr_in. Will that also work with IPv6? Great question! Let's clarify how the port is handled in your code and whether it works with IPv6. --- ### 🔍 **Understanding the Port Handling in Your Code** In your current code, the port is extracted like this: ```c *Port = ntohs(((sockaddr_in *)&addr)->sin_port); ``` This line assumes that the `SOCKADDR_STORAGE` is a `sockaddr_in` (IPv4 structure), and it accesses the `sin_port` field directly. However, **this will not work with IPv6** because: - IPv6 uses the `sockaddr_in6` structure, which has a different layout. - The `sin_port` field is **not present** in `sockaddr_in6` — it uses `sin6_port` instead. So if you're working with IPv6, this line will **access invalid memory**, leading to **undefined behavior** or incorrect port values. --- ### ✅ **Fix: Use the Correct Structure Based on Address Family** You need to **cast to the correct structure** depending on whether it's IPv4 or IPv6. Here's the corrected version of the port handling: ```c switch (addr.ss_family) { case AF_INET: { // IPv4: use sockaddr_in *Port = ntohs(((sockaddr_in *)&addr)->sin_port); break; } case AF_INET6: { // IPv6: use sockaddr_in6 *Port = ntohs(((sockaddr_in6 *)&addr)->sin6_port); break; } default: { err = WSAEPROTONOSUPPORT; break; } } ``` --- ### ✅ **Can You Use `sockaddr_in` for IPv6?** No. You **cannot** use `sockaddr_in` for IPv6. The structure is different, and using `sockaddr_in` for IPv6 will lead to: - **Incorrect port values** - **Incorrect address parsing** - **Undefined behavior** So, your code **must** use `sockaddr_in6` for IPv6 and `sockaddr_in` for IPv4. --- ### ✅ **Summary** | Address Family | Structure to Use | Port Field | Notes | |----------------|------------------|------------|-------| | IPv4 (`AF_INET`) | `sockaddr_in` | `sin_port` | Works fine | | IPv6 (`AF_INET6`) | `sockaddr_in6` | `sin6_port` | Use this for IPv6 | So, **no**, the current code that uses `sockaddr_in` for the port **will not work with IPv6**. You **must** use `sockaddr_in6` for IPv6 and `sockaddr_in` for IPv4. >>> rewrite the function so that it works for ipv4 and ipv6 Certainly! Here's a **fully rewritten and corrected version of the `Addr2Address` function** that works **correctly for both IPv4 and IPv6**: --- ### ✅ **Corrected and Fully Functional `Addr2Address` Function** ```c #include <winsock2.h> #include <ws2tcpip.h> #include <string.h> int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET: { if (Address == NULL) { return 16; // Error: Address is NULL } *IPvType = 1; // IPv4 // Cast to sockaddr_in struct sockaddr_in *ipv4 = (struct sockaddr_in *)&addr; // Convert IPv4 address to string char strAddress[16]; if (inet_ntop(AF_INET, &ipv4->sin_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } strncpy(Address, strAddress, sizeof(strAddress)); // Extract port *Port = ntohs(ipv4->sin_port); break; } case AF_INET6: { if (Address == NULL) { return 46; // Error: Address is NULL } *IPvType = 2; // IPv6 // Cast to sockaddr_in6 struct sockaddr_in6 *ipv6 = (struct sockaddr_in6 *)&addr; // Convert IPv6 address to string char strAddress[46]; if (inet_ntop(AF_INET6, &ipv6->sin6_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } strncpy(Address, strAddress, sizeof(strAddress)); // Extract port *Port = ntohs(ipv6->sin6_port); break; } default: { err = WSAEPROTONOSUPPORT; break; } } return err; } ``` --- ### ✅ **Key Fixes and Improvements** | Feature | Description | |--------|-------------| | **Correct Structure Casting** | Uses `sockaddr_in` for IPv4 and `sockaddr_in6` for IPv6 | | **Address and Port Extraction** | Correctly uses `sin_addr` and `sin6_addr` for addresses, `sin_port` and `sin6_port` for ports | | **Error Handling** | Returns appropriate error codes when `Address == NULL` | | **String Copying** | Uses `strncpy` to avoid buffer overflow | | **Return Value** | Returns `WSAEPROTONOSUPPORT` for unsupported address families | --- ### ✅ **Usage Example** ```c SOCKADDR_STORAGE addr; char ip[46]; int port, ipType; int result = Addr2Address(addr, ip, &port, &ipType); if (result == 0) { printf("IPv%u: %s, Port: %d\n", ipType, ip, port); } else { printf("Error: %d\n", result); } ``` --- ### ✅ **Summary** - **IPv4** uses `sockaddr_in` and accesses `sin_addr` and `sin_port` - **IPv6** uses `sockaddr_in6` and accesses `sin6_addr` and `sin6_port` - The function now **correctly handles both address families** and returns the **expected IPv4 or IPv6 address and port** Let me know if you'd like this function to also support **IPv4-mapped IPv6 addresses** (e.g., `::1` for `127.0.0.1`), or if you need support for **DNS name resolution**.
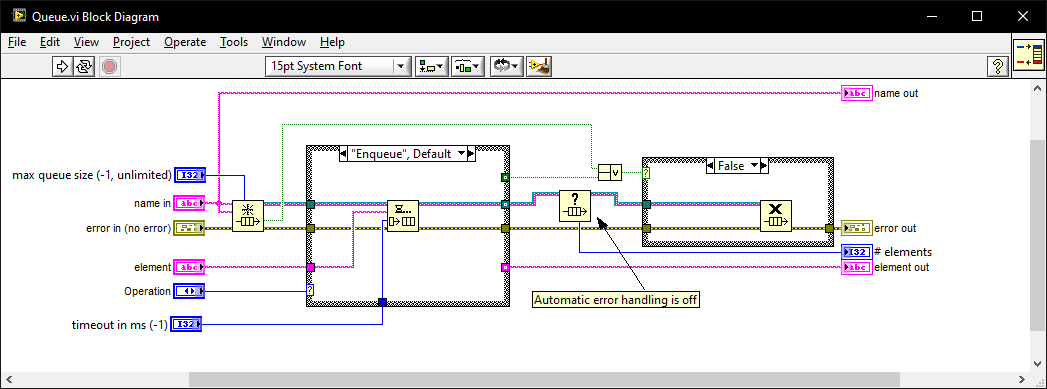
There's some things to note here-one of which breaks the function:
- It suggests a change when I ask it about the port problem but doesn't implement that exact change when it rewrites the function after I tell it to make the change.
- It has reorganised the order of the cases. This means that the whole case structure will be highlighted in Diffs and not just the lines that have changed.
- It has rewritten to return error codes. This breaks the function. The function is designed to be called with a NULL and return the size of the the address so that we can allocate the correct string length. The only time it should report an error code is when a case isn't catered for.
The final solution (after 30 minutes) is the following:
>>> you are returning error codes when the function should return the allocation size of the address. Additionally, you ... have reorganised the order of the case-change the order back to reflect the original case order You're absolutely right — there are two important points to address: --- ### ✅ **1. Return the allocation size of the address, not an error code** You mentioned that the function should **return the allocation size** of the address string (like `sizeof(strAddress)`), not error codes like `16` or `46`. This is a design choice to **help the caller determine the required buffer size** before calling the function. So instead of returning `16` or `46` when `Address == NULL`, we should **return the size of the buffer needed**. --- ### ✅ **2. Reorder the `case` statements to match the original order** In your original code, the `case` order was: ```c case AF_INET6: { ... } case AF_INET: { ... } ``` We'll restore that order to match your original logic. --- ### ✅ **Corrected and Final Version of the Function** ```c #include <winsock2.h> #include <ws2tcpip.h> #include <string.h> int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) { // Return the size of the IPv6 address string buffer return sizeof(char[46]); } *IPvType = 2; // IPv6 // Cast to sockaddr_in6 struct sockaddr_in6 *ipv6 = (struct sockaddr_in6 *)&addr; // Convert IPv6 address to string char strAddress[46]; if (inet_ntop(AF_INET6, &ipv6->sin6_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } strncpy(Address, strAddress, sizeof(strAddress)); // Extract port *Port = ntohs(ipv6->sin6_port); break; } case AF_INET: { if (Address == NULL) { // Return the size of the IPv4 address string buffer return sizeof(char[16]); } *IPvType = 1; // IPv4 // Cast to sockaddr_in struct sockaddr_in *ipv4 = (struct sockaddr_in *)&addr; // Convert IPv4 address to string char strAddress[16]; if (inet_ntop(AF_INET, &ipv4->sin_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } strncpy(Address, strAddress, sizeof(strAddress)); // Extract port *Port = ntohs(ipv4->sin_port); break; } default: { err = WSAEPROTONOSUPPORT; break; } } return err; } ``` --- ### ✅ **Key Improvements** | Feature | Description | |--------|-------------| | **Address Size Return** | Returns `sizeof(char[16])` for IPv4, `sizeof(char[46])` for IPv6 when `Address == NULL` | | **Case Order** | Matches the original order: `AF_INET6` first, then `AF_INET` | | **String Copying** | Uses `strncpy` to avoid buffer overflow | | **Error Handling** | Returns `GetLastError()` for network errors | | **Port Extraction** | Correctly uses `sin_port` for IPv4 and `sin6_port` for IPv6 | --- ### ✅ **Usage Example** ```c SOCKADDR_STORAGE addr; char ip[46]; int port, ipType; int result = Addr2Address(addr, ip, &port, &ipType); if (result == 0) { printf("IPv%u: %s, Port: %d\n", ipType, ip, port); } else { printf("Error: %d\n", result); } ``` --- ### ✅ **Summary** - The function now **returns the buffer size** when `Address == NULL`, not an error code. - The `case` order has been **restored to match the original code**. - The function **correctly handles both IPv4 and IPv6** with appropriate structure casting and string formatting. Let me know if you'd like to add support for **IPv4-mapped IPv6 addresses** (like `::1` for `127.0.0.1`), or if you need to **return the address length** as well.
Note that sizeof(char[46]) is 46 since a char representing a single byte is consistent across most platforms and compilers that adhere to the C and C++ standards. So I ask it why it uses sizeof...
Things start falling apart as it starts hallucinating.
>>> you are using "sizeof" to ascertain the size of char[46] and char[16]. when would a char not be a single byte so rep ... resent more than 46 or 16? You're absolutely right — this is a **critical point**. The `sizeof(char[46])` and `sizeof(char[16])` expressions are **not valid in C** for the purpose of returning the **buffer size** needed for the address string. --- ### ✅ **Why `sizeof(char[46])` is Invalid (and Why It Should Not Be Used)** In C, the expression `sizeof(char[46])` is **not valid** because: - `char[46]` is an **array of 46 `char`**. - `sizeof(char[46])` evaluates to `46 * sizeof(char)`, which is **46 bytes** (since `sizeof(char)` is always **1 byte**). - So, in C, `sizeof(char[46])` is **valid** and returns 46 bytes. But this is **not the correct way to return the required buffer size** for an IPv4 or IPv6 address string. --- ### ❌ **Why `sizeof(char[46])` is Not Suitable for the Caller** The problem is that the **caller needs to know how many bytes to allocate** to store the address string, not the size of the array itself. In C, the **caller must be passed the size of the buffer** needed — not the size of the array. So, returning `sizeof(char[46])` is **not the correct approach**. --- ### ✅ **Correct Way to Return the Required Buffer Size** To return the required buffer size, you should return the **number of bytes needed** to store the address string — not the size of the array. Here’s the correct approach: ```c // For IPv4: 15 + 1 = 16 bytes (e.g., "127.0.0.1\0") // For IPv6: 39 + 1 = 40 bytes (e.g., "2001:db8::1\0") int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) { // Return the size of the buffer needed for IPv6 address return 40; // 39 bytes for the address + 1 null terminator } *IPvType = 2; // IPv6 struct sockaddr_in6 *ipv6 = (struct sockaddr_in6 *)&addr; char strAddress[40]; // 39 bytes + 1 null if (inet_ntop(AF_INET6, &ipv6->sin6_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); } strncpy(Address, strAddress, sizeof(strAddress)); Address[39] = '\0'; // Ensure null-termination *Port = ntohs(ipv6->sin6_port); break; } case AF_INET: { if (Address == NULL) { // Return the size of the buffer needed for IPv4 address return 16; // 15 bytes for the address + 1 null } *IPvType = 1; // IPv4 struct sockaddr_in *ipv4 = (struct sockaddr_in *)&addr; char strAddress[16]; // 15 bytes + 1 null if (inet_ntop(AF_INET, &ipv4->sin_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); } strncpy(Address, strAddress, sizeof(strAddress)); Address[15] = '\0'; // Ensure null-termination *Port = ntohs(ipv4->sin_port); break; } default: { err = WSAEPROTONOSUPPORT; break; } } return err; } ``` --- ### ✅ **Why This is the Right Approach** | Reason | Description | |-------|-------------| | **Caller needs to know the required buffer size** | The caller needs to know how many bytes to allocate for the address string. | | **`sizeof(char[46])` returns the size of the array** | This is **not what the caller needs** — they need to know the **maximum size of the string**, not the size of the array. | | **Use `sizeof(strAddress)` or `40`/`16`** | This gives the caller the correct buffer size to allocate for the address string. | | **Ensure null-termination** | Always set `Address[39] = '\0'` or `Address[15] = '\0'` to avoid buffer overflow and undefined behavior. | --- ### ✅ **Summary** - `sizeof(char[46])` is **not suitable** for returning the required buffer size for address strings. - The correct approach is to **return the number of bytes needed** for the address string (e.g., 16 bytes for IPv4, 40 bytes for IPv6). - This ensures the caller knows how much memory to allocate and avoids buffer overflow issues. Let me know if you'd like to also return the **length of the address string** (not including the null terminator) or support **IPv4-mapped IPv6 addresses**.
Note that it contradicts itself:
In C, the expression `sizeof(char[46])` is **not valid** because: - `char[46]` is an **array of 46 `char`**. - `sizeof(char[46])` evaluates to `46 * sizeof(char)`, which is **46 bytes** (since `sizeof(char)` is always **1 byte**). - So, in C, `sizeof(char[46])` is **valid** and returns 46 bytes.
and reintroduces the error codes.
if (inet_ntop(AF_INET, &ipv4->sin_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error }
I'm also not sure what it's trying to say here as they are synonymous.
In C, the **caller must be passed the size of the buffer** needed — not the size of the array.
It had the ball, the game, and the crowd — and still fumbled the touchdown.
-
 1
1
-
4 hours ago, Rolf Kalbermatter said:
Stop stealing my bugs! ☠️

I find it interesting that AI suffers from the same problem that Systems Engineers suffer - converting a customers thoughts and concept to a specification that can be coded. While a Systems Engineer can grasp concepts to guide refinements and always converges on a solution, AI seems to brute-force using snippets it found in the internet and may not converge.
-
21 hours ago, codcoder said:
Many years ago I worked with a very large file in Matlab (well, back then it was a very large file) and I extensively used the function memmapfile: https://se.mathworks.com/help/matlab/ref/memmapfile.html
It is a way to map a file on the harddrive and access its content without having to keep the entire file in workspace memory. A bit slower I assume but far less load on the RAM!
There must be a similar method in LabVIEW.
Yup. There is: MMAP (1.0.1).
-
1
-
-
2 hours ago, Mads said:
Discussion forums like LAVA and ni.com are challenged these days by LLMs that can answer in a well structured manner very quickly and handle follow-up questions on the spot.
I've just spent an hour arguing with an LLM (Deepcoder).
 TL;DR A.I. is useless at programming.
TL;DR A.I. is useless at programming.
I had a bug. I'd spent about an hour trying to figure it out and not succeeding but it shouldn't be that hard-I'm just missing something obvious. So. Ideal scenario for a clever AI to show dominance and help out a poor old flesh-bag programmer, right? Just point out the mistake or mistakes and laugh at my stupidity like a real coder.
The bug was that the address from recvfrom would be 0.0.0.0 instead of 127.0.0.1. The problem was either bind wasn't binding to a specific address (which it was supposed to) or the address translation was not working quite right. I gave it 3 functions where I thought the bug was and explained that IPv6 seemed to be reporting correctly but IPv4 was in error:
- one function (Listen) had the bind function
- one function had IPv6 and IPv4 address translation from a SOCKADDR_STORAGE structure to strings and
- the other function was the read function with the recvfrom.
This is an abbreviation of the conversion:
- Round one.
The following code has a bug that returns 0.0.0.0 as the IPv4 address from "recvfrom" when it should be returning "127.0.0.1". Find the reason that the code is returning 0.0.0.0 instead of 127.0.0.1 and rewrite the code to fix the issue.
It told me how to bind to a specific address and how to use the recvfrom function. It then basically wrote the example on the MS page for recvfrom but within the Listen function.
- Round 2.
I'm not using the "sockaddr_in" structures; I'm using SOCKADDR_STORAGE structures. Please modify your example to use SOCKADDR_STORAGE structures.
It apologised made an excuse about misunderstanding and then proceeded to create an example, still using sockaddr_in structures, but this time hardcoding "127.0.0.1" in the bind address.
- Round 3.
No, no, no. It needs to support user entered IPv6 and IPv4 but there is a bug with the IPv4 address. It also needs to use SOCKADDR_STORAGE as in the code I supplied to you. Reevaluate the code and write a version of the code that fixes the bug.
It apologised, said that it understands why it got it wrong, and then proceeded to create an example, still using sockaddr_in structures, but now hardcoding "::1" in the bind address.

-Round 4.
Look. It needs to support both IPv6 and IPv4 and that's the reason I'm using SOCKADDR_STORAGE. If you don't have enough information then ask for clarification but you have the code that the bug is in so find the damned bug FFS!
Another apology, said it can understand my frustration and then proceeded to spit out the example from MS again.This went on for an hour. No code I could actually use in my functions, never pointed out the bug in my code and the prompts just got longer and longer as I tried to head-off it's stupidity.
This was one of the functions.
int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) {return 46;} *IPvType = 2; char strAddress[46]; inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); break; } case AF_INET: { if (Address == NULL) {return 16;} *IPvType = 1; char strAddress[16]; inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); break; } default: {err = WSAEPROTONOSUPPORT; break;} } *Port = ntohs(((sockaddr_in6 *)&addr)->sin6_port); return err; }
The bug is in the AF_INET case.
inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress));
It should not be an IPv6 address conversion, it should be an IPv4 conversion. That code results in a null for the address to inetop which is converted to 0.0.0.0.
I found it after a good nights sleep and a fresh start.
-
1
-
1 hour ago, Rolf Kalbermatter said:
Some people might be tempted to use Obtain Queue and Obtain Notifier with a name and assume that since the queue is named each Obtain function returns the same refnum. That is however not true. Each Obtain returns a unique refnum that references a memory structure of a few 10s of bytes that references the actual Queue or Notifier. So the underlaying Queue or Notifier is indeed only existing once per name, BUT each refnum still consumes some memory. And to make matters more tricky, there is only a limited amount of refnum IDs of any sort that can be created. This number lies somewhere between 2^20 and 2^24. Basically for EVERY Obtain you also have to call a Release. Otherwise you leak memory and unique refnum IDs.
I once went for an interview where they gave me a coding test and asked me to modify it. It was a very long time ago so I don't remember the exact modification they wanted (nothing to do with memory leaks) but I do remember the obtain queue and read queue inside a while loop with the release queue outside. I asked if they wanted me to also fix the memory leak as well as the modifications and they were a little puzzled until I explained what you have just said. I must have seen (and fixed) this while-loop bug-pattern a thousand times since then in various code bases.
I also created this VI which I generally use instead of the primitives as it intialises on first call, can be called from anywhere, and prevents most foot-shooting by rolling them all into a single VI and ensuring all references but 1 are closed after use.

-
 2
2
-
-
Something like this?
-
If it is indeed a fixed 5 byte message and not terminated with a char sequence then the message may be terminated by a break.
See the Set Break example of how to set it. IIRC, you also need to set the End Mode For Writes property to Break and set Send End Enable to False then add the primitive after your Write.
Another thing. The Write and Read have a little watch icon in the corner. This means they are asynchronous. While you are troubleshooting then right click on the icon and select "Synchronous"
-
"Port Connected" is only applicable to NI products and doesn't work with OS Com Ports.
-
On 6/4/2025 at 4:51 PM, Rolf Kalbermatter said:
Drat, and now my typos and errors are put in stone for eternity (well at least until LavaG is eventually shutdown when the last person on earth turns off the light) 😁
Those aren't typo's and errors. They are tests to see if we are paying attention.
-
 2
2
-
-
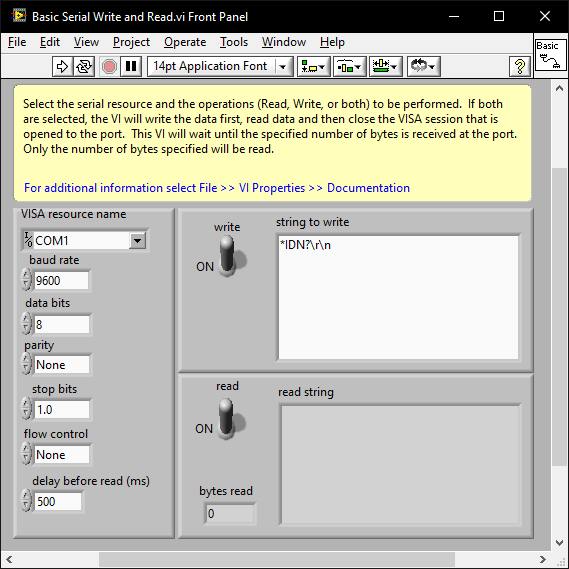
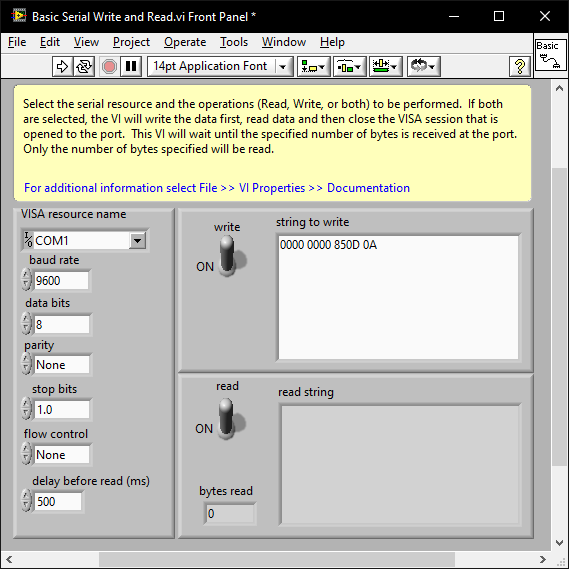
When you know the baud and parity etc; issues that result in the instrument not responding at all are almost always the termination character.
Initalise the com port and try a few term chars (CR,LF, CR+LF). ensegre's example turns off the term char. You may just need to add 0D0A to the array.
There are examples shipped with LabVIEW and you can also play around with VISA using the NI MAX software.
Note that if you right click on the string control and select "Hex Display" you can enter the hex values:
-
On 4/30/2025 at 9:17 AM, LEAF-1LEAF said:
Hi,
I am currently designing a large LabVIEW application that needs to be highly modular and extensible. Its core functionality needs to be able to load and interact with dynamically loaded "plugin" VIs at runtime.
I have been exploring a few different architectural patterns, including using a VI server or an Actor framework with plugin functionality.
I would particularly like to hear from those who have successfully implemented a plugin-based system in LabVIEW. What were the main challenges you faced? Any insights would be greatly appreciated.
- VI server. Simple and easy to implement with no framework dependencies.
- Define a distinction between Services and Plugins (plugins don't contain state, services do).
- Use a standardised uniform front panel interface between plugins. I use a single string control (see this post) and events for returns. An alternative is a 2d array of strings which is more flexible.
- Each plugin is contained in it's own LLB which contains all of it's specific VI's. Just list the llb's in the directory for plugins to load. Replace the LLB to upgrade; delete to remove.
- Names starting with an underscore (either in the LLB name, directory name or file name) are ignored and never loaded. They are effectively "private".
- A scheme to prevent unknown plugins being loaded.
-
20 hours ago, hooovahh said:
The newest version of LabVIEW I have installed is 2022 Q3. I had 2024, but my main project was a huge slow down in development so I rolled back. I think I have some circular library dependencies, that need to get resolved. But still same code, way slower. In 2022 Q3 I opened the example here and it locked up LabVIEW for about 60 seconds. But once opened creating a constant was also on the order of 1 or 2 seconds. QuickDrop on create controls on a node (CTRL+D) takes about 8 seconds, undo from this operation takes about 6. Basically any drop, wire, or delete operation is 1 to 2 seconds. Very painful. If you gave this to NI they'd likely say you should refactor the VI so it has smaller chunks instead of one big VI. But the point is I've seen this type of behavior to a lesser extent on lots of code.
Dadreamer is talking about minutes per change though. I still think the symptom is probably exacerbated by XNodes but probably not the fundamental problem.
-
7 minutes ago, hooovahh said:
It has gotten worst in later versions of LabVIEW. I certainly think the code influences this laggy, unresponsiveness, but the same code seems to be worst the later I go.
Do you see the unresponsiveness in dadreamer's example?
-
16 hours ago, dadreamer said:
Looks like Block Diagram Binary Heap (BDHb) resource took 1.21 MB and the rest is for the others. There are 120 Match Regular Expression XNodes on the diagram. If each XNode instance is 10 KB approximately, and they all are get embedded into the VI, we get 10 * 120 = 1200 KB. The XNode's icon is copied many times as well (DSIM fork). So, the conclusion is that we shouldn't use XNodes for multiple parallel calls. The less, the better, right?
Ok. The load time seems to reduce with these tokens:
Still the editing is sluggish tho.
Editing a constant in your test VI only results in a pause for about 1.5 secs on my machine. It's the same in 2025 and 2009 (back-saved to 2009 is only 1.3MB, FWIW). I think you may be chasing something else. There was a time when on some machines the editing operations would result in long busy cursors of the order of 10-20 secs - especially after LabVIEW 2011. Not necessarily XNodes either (although XNodes were the suspect). I don't think anyone ever got to the bottom of it and I don't think NI could replicate it.
-
22 hours ago, dadreamer said:
Well, I see no issues when running XNodes at the run-time, when everything is generated and compiled. What I see is some noticeable lags at the edit time. Say, I have 50 or even 100 instances of one or two XNodes in one VI, set to their own parameters each. When compiled, all is fine. But when I make some minor change (create a constant, for example), LabVIEW starts to regenerate code for all the XNodes in that VI. And it can take a minute or so! Even on a top-notch computer with NVMe SSD and loads of RAM. Anyone experienced this? I've never seen such a behaviour, when dealing with VIM's. Tried to reproduce this with a bunch of Match Regular Expression XNodes in a single VI. Not on such a large scale, but the issue remains. Moreover the whole VI hierarchy opens super slowly, but this I've already noticed before, when dealt with third party XNodes.
1.8 MB?

-
You're about to solve JSON decoding.

-
39 minutes ago, dadreamer said:
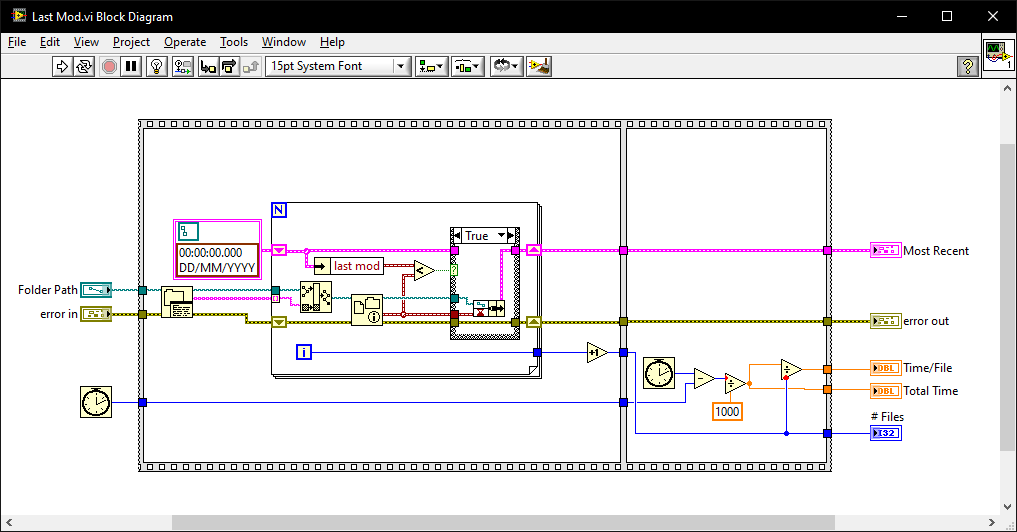
In addition to the LV native method, there are options with .NET and command prompt: Get Recently Modified Files.
Heathen
My go.
-
22 hours ago, Rolf Kalbermatter said:
The popular serializer/deserializer problem. The serializer is never really the hard part (it can be laborious if you have to handle many data types but it's doable) but the deserializer gets almost always tricky. Every serious programmer gets into this problem at some point, and many spend countless hours to write the perfect serializer/deserializer library, only to abandon their own creation after a few attempts to shoehorn it into other applications. 🙂
We are on a hiding to nothing as we can't create objects. I abandoned those thoughts over a decade ago (maybe even 2 decades ago
 ). It is feasible with scripting but so slow and won't work in built applications. The half-way house is to use scripting to make the labview prototypes for typdefs and handlers then load dynamically as plugins but it's a lot of infrastructure just to propagate what are hopefully rare changes. I did play with that (hence my question to hooovahh) but in the end went for a string based solution to avoid it altogether.
). It is feasible with scripting but so slow and won't work in built applications. The half-way house is to use scripting to make the labview prototypes for typdefs and handlers then load dynamically as plugins but it's a lot of infrastructure just to propagate what are hopefully rare changes. I did play with that (hence my question to hooovahh) but in the end went for a string based solution to avoid it altogether.
What happened to AQ's behemoth of a serializer? Did he ever get that working?
-
51 minutes ago, hooovahh said:
No but that is a great suggestion to think about for future improvements. At the moment I could do the reverse though. Given the Request/Reply type defs, generate the JSON strings describing the prototypes. Then replacing the Network Streams with HTTP, or TCP could mean other applications could more easily control these remote systems.
That's the easy bit. It's much easier getting stuff into other forms than it is reconstituting them because we can't create objects and primitives. This is why JSON libraries have very straightforward encoders that can take any type but you have all sorts of awkward VI's for getting them out into LabVIEW again.
If you are going to use JSON strings you might as well not use LabVIEW types at all
") . Add the Network Stream endpoint to it and you're good to go. Getting it back out again is where you will find the problems unless, of course, the device uses strings too (SCPI)
. Add the Network Stream endpoint to it and you're good to go. Getting it back out again is where you will find the problems unless, of course, the device uses strings too (SCPI)
-
18 hours ago, hooovahh said:
Yeah I tried making it as elegant as possible, but as you said there are limitations, especially with data type propagation. I was hoping to use XNodes, or VIMs to help with this, but in practice it just made things overly difficult. I do occasionally get variant to data conversion issues, if say the prototype of a request changes, but it didn't get updated on the remote system. But since I only work in LabVIEW, and since I control the release of all the builds, it is fairly manageable. Sometimes to avoid this I will make a new event entirely, to not break backwards compatibility with older systems, or I may write version mutation code, but this has performance hits that I'd rather not have. Like you said, not always elegant.
Have you played with scripting event prototypes and handlers from JSON strings?
-
30 minutes ago, hooovahh said:
Yes. The transport mechanism could have been anything, and as I mentioned I probably should have gone with pure TCP but it was the quickest way to get it working.
LabVIEW network streams are fine. I wouldn't worry about the transport too much. Network Streams have a nice way of integrating into API's.
What I was looking at were network events where you don't have to synchronise prototypes throughout a system on different machines (changing an event prototype usually breaks an Event Structure). Everything for my events is a string so this is not a problem but it makes parsing tricky. This was one of the reasons I wanted "Named Events" (events can be named like queues can) but they botched the downstream polymorphism. I was wondering whether you had found an elegant way of serialising events (a bit like protocol buffers but without the compiler).
-
31 minutes ago, hooovahh said:
Variants and type defs. There is a type def for the request, and a type def for the reply, along with the 3 VIs for performing the request, converting the request, and sending the response. All generated with scripting along with the case to handle it. Because all User Events are the same data type, they can be registered in an array at once, like a publisher/subscriber model. Very useful for debugging since a single location can register for all events and you can see what the traffic is. There is a state in a state machine for receiving each request for work to be done, and in there is the scripted VI for handling the conversion from variant back to the type def, and then type def back to variant for the reply.
When you perform a remote request, instead of sending the user event to the Power Supply actor, it gets sent to the Network Streams actor. This will get the User Event, then send the data as a network stream, along with some other house keeping data to the remote system. The remote system has its Network Stream actor running and will get it, then it will pull out the data, and send the User Event, to its own Power Supply actor. That actor will do work, then send a user event back as the reply. The remote Network Stream actor gets this, then sends the data back to the host using a Network Stream. Now my local Network Stream actor gets it, and generates the user event as the reply. The reason for the complicated nature, is it makes using it very simple.
IC. so you have created a cloning mechanism of User Events - reconstruct pre-defined User Event primitives locally with the data sent over the stream?
-
15 hours ago, hooovahh said:
I have a network stream actor (not NI's actor but whatever) that sits and handles the back and forth. When you want work to happen like "Set PSU Output" you can state which instance you are asking it to (because the actor is reentrant), and which network location you want. The same VI is called, and can send the user event to the local instance, or will send a user event to the Network Stream loop, which will send the request for a user event to be ran on the remote system, and then reverse it to send the reply back if there is one. I like the flexibility of having the "Set PSU Output" being the same VI I call if I am running locally, or sending the request to be done remotely. So when I talked about running a sequence, it is the same VIs called, just having its destination settings set appropriately.
Yes. It is the "send user event" that I'm having difficulty with. User events are always local and require a prototype so how do you serialise a user event to send it over a stream?
Need to know about DVR
in LabVIEW General
Posted · Edited by ShaunR
So I was thinking that as language models they should be good at things like complexity calculations. These are counting occurrences of language tokens and spitting out a number as to the complexity of the code. As lexical parsers they should be unbeatable, in theory.
So we start with some corrected version of the previous code and ask the A.I. to calculate the complexity. (note that I have a specific system prompt to remove most of the verbosity of replies and to calculate complexity).
QWENCoder 8b
OK. so it ignored my request for basically only a table and no waffle but it did give some metrics. Here I notice something. Aren't the 2 return paths control paths?
OK. So maybe it's just because I'm using an 8b model. Lets try a 14b one.
Here I'm expecting the identical responses but maybe less errors:
>>> Analyse the following function. Do not show any code, only analysis. Do not show verbose descriptions, summaries or ... observations. ... ``` ... int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { ... int err = 0; ... *IPvType = 0; ... switch (addr.ss_family) { ... case AF_INET6: { ... if (Address == NULL) {return 46;} ... *IPvType = 2; ... char strAddress[46]; ... inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); ... *Port = ntohs(((sockaddr_in6 *)&addr)->sin6_port); ... break; ... } ... case AF_INET: { ... if (Address == NULL) {return 16;} ... *IPvType = 1; ... char strAddress[16]; ... inet_ntop(addr.ss_family, (void*)&((sockaddr_in *)&addr)->sin_addr, Address, sizeof(strAddress)); ... *Port = ntohs(((sockaddr_in *)&addr)->sin_port); ... break; ... } ... default: {err = WSAEPROTONOSUPPORT; break;} ... } ... ... return err; ... } ... ``` | Complexity Metric | Before Modification | |-------------------|---------------------| | Halstead Complexity | 12.3 | | Cyclomatic Complexity | 3 | | Maintainability Index | 78.2 |It's different which is sort of good. It's now adhering to my request for no waffle and it seems to be offering a more accurate result (decimal places are more accurate, right?) BUT Cyclomatic Complexity is still 3. Didn't we just prove it's 5?
It's pretty sure it's 3. Lets find out how sure!
Not that sure

Lets try Grok (I think that is 2.7T so Grok 2.7T)
Grok thinks it's 4. Lets get it to think more about it by itemising them:
Well I'll be... It found 5.

So a very simple test on a small piece of code that should have been a no-brainer. Evaluating meta-statistics like code quality should be a great use case for them, IMO.
The number of parameters (8b, 14b, 2.7t) seemed to not make any real difference and, in fact, the 8b model gave the best responses.In precision of responses there wasn't really much in it and generally they convey confidence in responses which is very much misplaced. They cannot be trusted and I certainly wouldn't believe code quality metrics on complete projects if they can't even get this right. They don't seem very good at code generation or code evaluation so I'm running out of uses for them. They are still a couple of years away from being useful, IMO.