

ShaunR
-
Posts
4,940 -
Joined
-
Days Won
306
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
No, 2012 is not a cut point, just the latest version at the time. We aim to maintain it as long as is practical, and we have at this point maintained backward load support longer than at any other time in LV's history, so far as I can tell. I suspect the current load support will go for quite some time because there's not really a problematic older feature that all of use in R&D want to stop supporting.
Phew. Many thanks for clarifying.

-
I think some people would be willing to pay for a nice 3rd party 2D graphics toolset.
-
We just last year walked a LV 4.0 VI all the way to LV 2012. It opened and ran just fine. You have to open it in LV 6.0, then LV 8.0 then LV 2012, as those are the defined load points, but the mutation paths have been fully maintained.
Off topic (apologies).
Is 2012 a load point? Or just that you loaded it finally in 2012? More generally. At what version is it planned that 2009 vis will not be loadable?
-
How can I test the DLL? We wanted to use it in our LabVIEW code so we would have a single DLL for everyone and like I said earlier, to make it easier to replace in the future if they decided to build a DLL in C. But it seems, from what I am reading, that this will be more pain than gain, right?
For everyone? Including Linux, Mac, Pharlap and VxWorks? If you are going to support all the platforms that labview supports, then you will need 6 dynamic libraries and you can't use labVIEW to create some of them. Two is just for windows.
However. If you are committed to making the labVIEW driver dependent on a dynamic library (which is the case if you plan to replace it later with a native C implementation) then you are unavoidably making a rod for your own back. Avoid dynamic libraries in LabVIEW if you can - here be monsters (at least you didn't say you wanted .NET or ActiveX ...
 ).
). -
Wait, I am building the DLL, does this mean that I have to build two versions of the DLL, one in a LabVIEW 32 bit version and one in a LabVIEW 64 bit version?
Well. You don't have to. But if you don't, then those with LabVIEW64 bit won't be able to use it (that's assuming you are only supporting windows
 ).
).You are much better off leaving the LabVIEW code for LabVIEW users (and then it will work on all platforms including Linux, Mac etc) and just compile a 32 bit DLL for non-LabVIEW people and worry about the 64 bit when someone (non-labview) asks/pays for it.
-
And make sure they supply you with the 32 bit & 64 bit versions. Most suppliers think that only the 32 bit is sufficient since 32 bit software can be used in windows. However. LabVIEW 64 bit cannot load 32 bit libraries!C calling convention it is and we won't try to get fancy with memory management.Thank you guys, I think we are going to learn a lot (probably more than what we wanted/expected) about DLLs
-
Eventually the DLL will do serial calls, so yes we will be dealing with byte arrays that might have null in between.
Make sure you specify to whoever is writing it that it must be "Thread-safe". Otherwise you will have to run it in the UI thread.
Actually using fully managed mode is even faster as it will often avoid the additional memory copy involved with the MoveBlock() call.But at least in C and C++ it's only an option if you can control both the caller and callee, or in the case of a LabVIEW caller, know exactly how to use the LabVIEW memory manager functions in the shared library.That probably limits it to just you then
-
Would defining the string as a "Pascal String Pointer" remove the need to know in advance how large the string needs to be
No, well. not really. It depends if you are going to have nulls in your data then you could use the C String and not worry about it. However. I'm guessing that because you are looking at string length bytes (pascal style strings can be no more than 256 bytes by-the-way) that you are intending to pass arbitrary length binary data that just happen to be strings..
.
There are two ways of transferring variable length data to/from a library.
- Memory is allocated by labview and the library populates this memory the data (library needs to know the size and the resultant data must be no more than that passed - create and pass array like the ol' for loop of bytes)
- Memory is allocated by the library and labview accesses this memory (Labview needs to know the size and the resultant data can be any size- moveblock ).
Either way. One or the other needs to know the size of the allocated memory.
The general method is case no.2 since this does not require pre-allocation, is unlikely to crash because the data is too big and only requires one call for allocation and size, You call the function and have the size as one of the returned parameters and a pointer (uintptr_t) as the other Then use Moveblock to get the data (since it will be known at that point by the size parm). You will also need a separate function to release the memory. This also happens to be the fastest

CDECL calling convention is the one of choice as the STDCALL is windows specific (you are intending to port this to other platforms.....right?)
-
 1
1
- Memory is allocated by labview and the library populates this memory the data (library needs to know the size and the resultant data must be no more than that passed - create and pass array like the ol' for loop of bytes)
-
Apart from Daklus sound advice. You might also check that you are using the High Performance Ethernet driver. Not so much for bandwidth, but more for CPU usage.
Missing pieces of the image (or entire images) is usually due to bandwidth saturation/collisions. Just because a camera is capable of supplying images at a frame-rate and resolution doesn't mean that it can all be squirted over a LAN interface. You generally have to play with the camera settings to get things working nicely. Whilst the "theoretical" maximum of a 1 GbE is 125MB/s, in reality I have never achieved more than about 100MB/s reliably (assuming jumbo frames are enabled) and a 100Mb interface you will be lucky to get 10MB/s (rule of thumb is about 80% of interface speed).
If Jumbo frames aren't being used (default is usually 1500) or are not supported by the interface, then this is usually the bandwidth restriction and you will have to go down to lower resolutions and frame-rates as the packet overhead crucifies the performance (note that if you are going through a router or switch, jumbo frames will also have to be turned on for these devices and match the packet size of the LAN interface).
-
I choose to believe it's due to the overwhelming impact of my awesome.
In my case. I'm pretty sure it's my leopard-print lycra underpants with the elephant trunk codpiece.

-
I really don't want to see my fellow CLAs in lycra
Indeed.My brain shuts down contemplating Daklu
-
1
-
-
I'm still split on what to think about the summit. I completely understand wanting to up the ante with respect to who can attend otherwise the summit could blow up into something way out of hand, but part of me also is disgusted at the closed nature of the summit. I firmly believe it's not in anyone's best interest to keep these good ideas sealed behind an ivory tower.
Like Comic-con (nerds) without the babes in lycra
You shouldn't lose sleep over it -
I've done it many times, even to the point of a complete scripting language for one client. It works well as long as you don't have to handle state too much and it is sequential. You end up with files of the formShaun, I think you are getting at what I was actually just thinking. For instance, this is all VISA communication (for now, and I expect that won't change). I was thinking of having a file then if the device changed, just update the commands in a file for that device, point the software at the file to be read, then send out the commands through VISA. Now I don't need a class for each device, I can just have a "VISA black-box device" which has a read and write that just wraps the visa read/write functions and sends out the appropriate commandsCHECK_VOLTS, TCPIP->READ->MEAS:VOLT:DC?, %.2f Volts, 10, -10
-
Well. You haven't really given much detail since if a parent class is too much hassle. I would guess anything else would be too.
However. There are some simple edge-case scenarios where you can make a flexible system that can be extended without writing additional code at all.
Consider a DVM that is CMD->Response for all operations. By defining a "translation" file you can convert operations to commands (or a series of commands) and expected results so that you can use a simple parser and just choose the file dependent on device. If a new DVM is used (but the tests are the same) then you just create a new translation file. You can extrapolate this technique for the tests themselves too. However. It all depends on the system, what you need to do and the complexity/flexibilty required.
None of that has to do with classes or VIs, however. It's more a design choice to abstract away hw dependencies from the programming environment.
-
Of course. A polymorphic VI has the feature that although you must have identical conpane layouts and directions. You can have different terminal types and numbers of defined terminals. However, the info for selecting the method is by the type wired to it or selection by the developer. In my example, I would just be requiring that class behaves like a polymorphic VI at run-time and method selection is dependent on the object rather than the data type wired to it. (I in fact, see no semantical difference between a polymorphic VI and a DD class except the choice mechanism).Now, with "Must Implement", we have the ability to contractually require functionality in subclasses while maintaining the ability to extend parent class functionality, having acknowledged that Dynamic Dispatch is the incorrect tool when distinct function interfaces are desirable. -
Well. I would argue it does exist. A vi is calling the parent (the sub-vi). You just don't have your hands tied by the syntax of classes.Yet this "classic labview behaviour" does not exist as you suggest (in any manner other than adherence to convention), since there's no concept of the "Call Parent Method" node or an inheritance relationship defined. Call this pedantic, but those relationship/constructs/contracts do help establish intent for subclass design, and ensure certain essential parent abilities are called from the subclass.Is a vi not "inheriting" from a sub-vi (Create sub vi menu command)? Can you not "override" the sub-vi behaviour? Are you not "encapsulating" by using a sub-vi?. Can you not "compose" a sub-vis inputs/outputs?
I have always argued that the only thing LV classes bring to the table above and beyond classic labview is Dynamic Dispatch and a way of organising that makes sense to OOP mindsets. If you are not using DD, then all you have is a different project style and a few wizards that name sub vis for you..
If you look at your example, then you are simply calling a sub-vi. However. You are restricted in doing so by a peculiarity of the implementation as a class.
-
I'm still not getting this (emphasis added by me)
These two issues would be addressed by a "Must Implement" feature, shown below (note: this is not valid syntax with LabVIEW today, but through image manipulation we're able to demonstrate the proposed syntax)
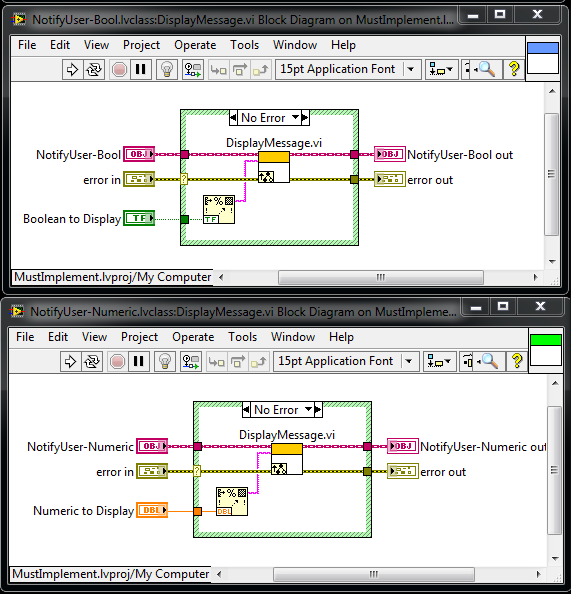
It is valid syntax if you don't use classes since it is simply calling a common sub-vi. You seem to be (in this example) arguing for classic labview behaviour (which already exists).
-
This crusade is for a desire to minimize mutable state. Reduce asynchronization between an object's cached state with the subject's physical state. Reduce cognitive overhead of understanding systems (i.e., reading code). Increase opportunities for parallelizability.
-
Indeed, the zlib library or more generally the zip addition to it do not use mbcs functions. And that has a good reason, as the maintainers of that library want to make the library compilable on as many systems as possible including embedded targets. Those often don't have mbcs support at all.
However I'll be having a look at it, since the main part of the naming generation is actually done on the LabVIEW diagram, and that may be in fact more relevant here than anything inside zlib. There might be a relatively small fix to the LabVIEW diagram itself or the thin zlib wrapper that could allow for MBCS names in the zip archive.
And 64 bit support?
-
I'm not aware of any conditions that would disallow transfering the ownership of a LabVIEW license to someone else. And in most places such a provision in the license agreement would be null and void.
However you need to make sure that you do get the ownership. Simply buying a CD ROM and a license serial number from anywhere might not really give you any rights. I would insist on a document that names the serial number, states the previous owner and also grants an irrecoverable transfer of ownership of that license and serial number to you. Otherwise you may try to register the software at NI and then get told that you are not the rightful owner and when disputing that, the previous owner suddenly may claim to still own the license.
I do know for sure that NI does actually care about ownership and has in the past contacted us about licenses that we have originally purchased and sold as part of a whole project, when the actual end user did register the serial number as their own, since the registering entity did not match the purchasing entity.
Transfer. If you have a named user license, computer based license, debug license, or if the SOFTWARE is
Multiple Access Software, you may transfer the SOFTWARE to a third party provided that you notify NI in writing
of such transfer (including the name and location of such third party), such third party accepts the terms and
conditions of this Agreement, and after such transfer, you do not retain any copies of the SOFTWARE (including
all Upgrades that you may have received) nor retain any of the written materials accompanying the SOFTWARE.
NI may, in its discretion, charge you a fee for the transfer of the SOFTWARE. If you have a VLP License, a
Surviving VLP License, a concurrent use license, an academic license (including a student edition license), a
Measurement Studio compile-only, or a debug license, the license is non-transferable and you may not, without
the prior written consent of NI or its affiliates, distribute or otherwise provide the SOFTWARE to any third party or
(with respect to a VLP License or a Surviving VLP License) to any of your sites or facilities not expressly
identified in the applicable documents from NI. If you have any licenses under the EP, such licenses are
non-transferable and you may not, without the prior written consent of NI or an authorized NI Affiliate distribute or
otherwise provide the SOFTWARE to any third party or to any of your sites or facilities other than an EP
Location.
(emphasis added)
-
One can have a “Hardware” actor, that is the only process to actually communicate with the actual hardware. That actor pulls from the hardware, but pushes status changes to other actors. [AQ may be thinking of this “Hardware” actor rather than the actual hardware.]
Indeed. So you are getting the status directly from the device as and when you need it rather than "remembering" state in the software. It doesn't matter what the method of transmission through the software is (actors, events, queues, notifiers or whatever-a good point to again whinge about not being able to hook up VISA refs to the event structure
). -
Agree with Intaris, though I prefer push over pull:
I don't encourage interrogating the HW. Instead let it push changes up to the UI when they happen. The UI just announces "I am connecting" or "I am disconnecting". After that, it is the HW's job to tell the UI about state changes. The benefit here is that you, the designer, do not ever get in the mindset of your UI holding and waiting for information from the HW, which leads to long pauses in your UI responses.
Unless your hardware uses push streaming (rare as rocking-horse droppings). The hardware cannot tell the UI since it will be CMD->RESP.
-
Thank you todd!
Hooovahh, another question for you. Why did you include a "stop" event case? Couldn't you have just wired the stop button to the "or" function outside the event structure, but inside the while loop? Just to be clear, I'm not criticizing, just curious. Maybe I'm missing something is all haha.
To paraphrase Hoover............
With a stop button only. If you click the X button on the form (as users have been trained to do). Your panel will disappear (so can't get to the stop button) but your VI will still be running.
-
ShaunR - How do you know that math there? Also, I'm more or less using a range (halfway between each semitone +/- 1 Hz) to show the note. Sounds a little weird maybe, but I usually keep my guitar in tune but don't always know what note I play. So there's a chance that these notes played won't be EXACTLY what the frequency of a note actually is. So how can I use this math to keep my ranges?
Google is your friend
But looking at the javascript source here should help you out As for ranges. Well. They key is to convert your measured frequency to numbers of semitones from a base frequency. You are not counting in frequency, rather, semitones so round up or down fractions of semitones/crotchets/quavers/lemons/whatever (just be consistent).
@Hoover.
Glad I don't work for you.lol.
Help on building a DLL in LabVIEW and then calling the same DLL in LabVIEW
in Calling External Code
Posted · Edited by ShaunR
I think I ought to clarify this. I assume you came to this conclusion from Rolfs comparison with panel-removed VIs. It's not actually as bad as that, Dynamic libraries in themselves aren't so much version specific but they are platform specific.
A dynamic library can be loaded in any version of LabVIEW with a caveat.
IF the library was written purely in C. You could load it in any version of LabVIEW and you wouldn't need the LV run-time for non-LabVIEW users (this you know).
If you create the library using the LabVIEW build process, then the user should have that version of the run-time. The main reason for this, however, is more to do with the supported features that you may put in the dynamic library rather than the compilation process (although NI tends to use different compilers with each version - so it is also a safer bet for that reason). Therefore it is possible to load a LabVIEW 2009(32 bit,) built library in an executable built in LabVIEW 2012(32 bit) with the 2012 run-time, but it will not be possible to load a 2012 built one in 2009 with the 2009 run-time if you have used features that are unavailable. This just pushes the maintenance overhead downstream to the installer. Similarly, a dynamic library built in 2009 can be loaded in the IDE of, say, 2012. If you do this,however, you need to test, test, and test some more.