

ShaunR
-
Posts
4,942 -
Joined
-
Days Won
308
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
Hi,
I need to stream 40 MBps to disk, .tdms, on a NI PXIe-8133, quad i7 1.73 GHz from 10 DIO cards. I understand that 40 MBps is roughly the max of what the SATA drive will do. I'm getting at least 30 MBps. Is the 40 MBps limit assumption good?
I think I should have a dedicated drive for the data instead of streaming to the controller drive. RAID is surely overkill. Has anyone connected an external drive to a NI controller with the ExpressCard slot? Any other ideas? I think my producer consumer code is ok.
cc
Depends on the drive.
SATA 1.5 theoritical max is 150 MB/s, SATA 2 300MB/s and SATA 3 is 600MB/s. I have a NAS box at home that easily does a sustained 60MB/sec over a 1Gb connection (with Jumbo frames).
NI PXI racks have pretty crappy hard drives as standard I would benchmark it with these
http://zone.ni.com/devzone/cda/epd/p/id/5348
.....then buy a decent one
-
Are the HTTPS VIs that are shipped with LabVIEW 2010 and later not of any use?
-
 1
1
-
-
I have an application that has several different data views, any number of which could be open at a time in their own window. Many views track mouse movements and display context information by showing small frameless panels, and hiding them when not relevant.
I'm having trouble though capturing mouse events when the cursor "leaves" a window by moving on top of other windows which are higher on the z-stack. Basically none of the control, pane, or VI mouse leave events fire since the mouse technically never left any of the respective boundaries, so I'm left with an orphaned tooltip window until the mouse happens to stray back to the window.
This video quickly demonstrates as much: http://www.screencast.com/t/aRCEDlqWVG
Now I can think of a few ways to fix this such as having each view broadcast an application level event to the effect of "Hey I have the cursor now so the rest of you hide your tooltips," but that seems inelegant. Surely there's a way to manage this locally without starting to throw around global brodcasts?
We want the tooltips to display even if the window does not have focus, so tracking focus is not really an answer.
Try using the "Mouse Leave" event of the pane? Although your last comment (tooltips display when it doesn't have focus) seems contradictory so that might not be what you are after.
-
1
-
-
I meant because you were already using Windows 8.

Not really using it (in fact I hate the Metro interface so won't be upgrading anytime soon). However I needed to test out IE10 so put it in a VM
-
Well, aren't you fancy?
I think there's supposed to be an attachment on your previous post, any chance you still have the relevant snippet?
Not that fancy (it's LabVIEW doing the work
)I had a clear out not so long ago, so no. I don't. But I imagine it was something like this:
-
Anyone know the string returned to OSName when the OS is Windows 8? I don't have a test system with W8 on it so can't verify it myself yet.
-
The JSON package currently depends on four OpenG packages: Data, Array, String, and Error. The array stuff is only used in one place that I’d like to rewrite anyway, so it is only three packages that are required. And the variant-handling stuff is widely applicable; if I wrote Variant-based APIs to be “self contained”, I would quickly wind up in a situation where I have multiple non-identicle sets of variant-handling VIs installed on my machine. Not ideal. Switching to using the off-palette VariantDataType VIs installed with LabVIEW is one option, but then if NI hasn’t put it on the palette, don’t you need to gain approval for that?
No. It doesn't matter. Only that it is an approved vendor (which NI must be otherwise they wouldn't be using LabVIEW).
But lets not run before we can walk. Lets get it all working properly first. As I seem to be the only one that suffers from this, I will gradually replace the dependencies and you can decide whether you want to update the main trunk with the branch as and when it happens. I have to do it anyway, but you don't need to.
-
Whether or not you store to disk is irrelevant as to whether you can track if a file is done. The Download File VI can still maintain a list of all the segments it expects and all the segments which have reported done. The Download File VI doesn't need to hang on to any of the actual data (let the segment downloaders write the file themselves, if you like). When the segment reports done, remove that segment from the working list of remaining segments.
Indeed. In fact. I would let the individual segment downloaders save the pieces, then probably get the download VI to sew them all together in the right order before sending the file name back to the main app.
Currently I store each segment to the HDD as it comes. This way I avoid memory issues when getting a large file. Each segment consists of few hundred KB but each file can be few hundred MB large, where a batch of files can be even bigger. So, everytime I <snip>
Sorry if I misunderstood your explanation, but if this is the case, would you be able to provide these two VIs? of course no coding required, I just want to see how you would re-arrange the queueing mechanism that you mentioned between these two VI's.
Thanks
Kas
As Asbo says. You don't need to send the actual data back. The segment downloaders only need to send the filename of the segment they downloaded and saved to the Download VI.
I think this demonstrates it for you (quick and dirty though it is). Of course with these things there is little error checking and no limitation to the number of spawned sub-processes. But I think you'll get the idea.Some of your VIs were missing so I couldn't use those. But I made it download some URLs using the HTTP VIs instead. Exactly the same idea except instead of passing the HTML back, you will pass a filename.
-
1
-
-
A gopher?
Coffee, white, No sugar please

-
By this reasoning you wouldn't be able to add anything from lavag either including this library.
That's right (and I have never used any software from LavaG in a commercial application). However, it is much easier to gain approval for a single self contained API than it is for one that relies on another 20 (like the OpenG). The problem with the OpenG stuff is that you want one little VI and you have to get approval for 120. It's easier and quicker to write the bit you need yourself.
And no. My re-use libraries are not a problem as I am an approved vendor.
-
I am downloading multiple files at a time, where each file is made of multiple segments or parts to be downloaded.
That's the key, right there. You're only lacking encapsulation depth at the moment. The thing to remember about queues is that they are a "Many-To-One" paradigm. So you have Many segments to One file and Many Files to One Batch.
I would tackle it this way.........
Create a "Download File" VI (launched re-entrantly) which you pass all the segments (a list?) that are required for that file to. It, in turn, then launches the individual segment downloads (again re-entrantly) by iterating through the list. The last thing a segment download VI does just before it exits is to post the segment to the Download File vis queue (Which will be named something like Download File.vi:3 i.e the clone name). The "download File" vi receives all the segments (for that one file) and, when it has all of them, reports back to your main app. The main app just sits and waits for completed files to come in.
In terms of queues, you only really need the return queues. So the Download File vi creates a queue to receive the segments (using it's clone name) and also has a queue named, say, "~download_files~" that is used to send back to the main app. All the download VI clones share the latter queue. The Download Files VI passes it's clone named queue to each of the segment queues (or you could get fancy and calculate it from the caller) so that they can use it to report back the individual segments to it's parent (the Download VI clone that launched them).
-
1
-
-
Theoretically, the not-on-the-pallet VIs in vi.lib\Utility\VariantDataType should blow the OpenG stuff out of the water, as OpenG has to flatten the data to access it (expensive), but my only experience with the VariantDataType Vis is that they are glacially slow.
In theory. Practice and theory are the same. In practice, they are not

Historically the openG stuff is generally more performant since a lot of them perform the same functions as are available in LV, just optimised. Of course with the NI grown ones they can have C functions in the exe to do the heavy lifting, but usually they use nodes that run the the UI thread which mitigates any performance gained
Saying that. I use the vi.lib getTypeInfo,GetCluster/numeric etc but I haven't bench-marked them since they are "Hobsons Choice" for me.
-
OK, but to me it seems silly for anyone to avoid OpenG yet use this (far, far less tested through experience) third-party open-source software. I’d rather offer the whole package to OpenG.
I'm not opposed to that either but I thought Ton was talking about it going into the Lavag Tools Network..
Now, do it with higher performance and you’ll get me interested.
Yeah. Well its got LVPOOP in it so that's not an option.
-
Shaun,
I am looking at the VIPM package that Ton and I have put together. Shall we divide into two packages, one not dependent on OpenG and one that contains all the Variant stuff? So people who can’t use OpenG can still use the core functions or your extended API? I can do that just be replacing one OpenG function, Trim Whitespace, in the core (can we use your “Fast Trim” instead).
Ton,
You currently have the package installing under LAVA; don’t we need a LAVA tools approved package before doing that?
If you can wait until next weekend, I'll replace all the openG stuff so it's a self contained lib. Just a bit busy at the moment finalising the websocket demo, but that will be finished this week.
-
Get your IT department to handle all the internet stuff and inserted in a DB. Then just query the DB using the Database Toolkit. You won't have to worry about security, webservers and firewalls or have to maintain webpages, log-ins, registrations etc It will also be fully integrated with your corporate website. Your labview stuff will be safely isolated behind the corporate firewall.
-
Well. this is how it works at present.
— the string “Hello” as a DBL? Is this NaN, zero, or an error?
NaN (after all NAN= Not A Number)
What about as an Int32?
0
A timestamp?
Like I said. Odd one out since all the other LabVIEW "from Strings" have a default behavior defined (they don't return errors)
— for that matter, what about a boolean? Should anything other than ‘true’/‘false' be an error? Any non-‘null'/non-‘false' be true (including the JSON strings “null” and false”)? Or any non ‘true' be false (even the JSON string “true”)?
True/False, Yes/No, On/Off 0/>0 are catered for. anything else equates to False.,
— “1.2Hello” as a DBL? Is this 1.2 or an error?
NAN
— or just “1.2”, a JSON string, not a JSON numeric? Should we (as we are doing) allow this to be converted to 1.2?
1.2
These
— a JSON Object as an Array of DBL? A “Not an array” error, or an array of all the Objects items converted to DBL?
— a JSON Scalar as an Array of DBL? Error or a single element array?
— a JSON Object as a DBL? Could return the first item, but Objects are unordered, so “first” is a bit problematic.
These I see as purely internal representations (lazy typing-only define type when recovered)
And what if the User asks for an item by name from:
— an Object that doesn’t have that named item? Currently this is no error, but we have a “found” boolean output that is false.
— an Array or Scalar? Could be an Error, or just return false for “found”.
The default value and a warning?
Then for the JSON to Variant function there is:
— cluster item name not present in the JSON Object: an error or return the default value
The default value and a warning?
Personally, I think we should give as much “loose-typing” as possible, but I’m not sure where the line should be drawn for returning errors.
I don't think any typing should be contained in the objects at all. Only interpreted when recovered to the best of our ability (as it does at present). Why enforce typing internally when there is none in the Json objects. Type is purely a convenience for wiring up to indicators/controls
-
Timestamp is probably the "odd-one-out" since it can't be interpreted any other way apart from as a timestamp. All the numerics are currently coerced (and output default if coercion fails-NaN for doubles, 0 for others). If the input type is a String Array then the ouput is an array of one literal.
Are you suggesting that if the JSON stream has a double and an Int is requested then it should throw an error? I'm not sure I'd find that very useful (probably more of a pain in the backside) and if I wanted a U8 from an U64 (say to get rid of a coercion dot) then I would have to convert it manually.
-
Actually, another possible error choice is to basically never throw an error on “Get”; just return a “null” (or zero, NaN, empty string, etc.) if there is no way to convert the input JSON to a meaningful value of that type (this follows the practice of SQLite, which always provides value regardless of a mismatch between requested and stored data type). Then perhaps all “Get” instances should have a “found” boolean output.
Ton, Shaun, what do you think?
Not throwing an error makes it quite hard to find out what the problem is in even moderately sized streams. However. I'm of the opinion that it should at least try a best guess and raise a warning (preferably identifying where in the stream). Errors are a two edged sword since you can end up halting your program just because someone left off a quote (we are heavily reliant on quotes being in the right place).
I'm just waiting for Ton to give me a login the the repo since I've implemented the decoding of escaped chars (not unicode I might add-we need to think about that). It doesn't work for your modified JSON_Double[array] though, since it is utilised in the Get Item By Name rather than Get Text. I have, however, made it a VI so you can put it where you think best.
-
There's no VI that falls into that category. There's no DLL that isn't core to LV itself that falls into that category. In short, everything that currently ships with LV that falls in that category is installed by LV and thus requires no secondary notation from a user. A VI in vi.lib is not part of the runtime engine and so would require separate acknowledgement by any EXE that used that VI.
Well. Tell us which licence IS acceptable then. Alternatively, NI could create a licence (LabVIEW Open Source Licence?) that doesn't require giving up IP then everyone will be happy.
-
For goodness sake, Shaun, have you listened at all to my explanation for why the attribution requirement is a problem? It has *nothing* to do with NI and everything to do with the next user downstream. It's an impossible tracking problem.
“You seldom listen to me, and when you do you don't hear, and when you do hear you hear wrong, and even when you hear right you change it so fast that it's never the same.”
Marjorie Kellogg

As the NI run-time (for executables) or the development IDE must be distributed to use anything; from NI, that aspect is a bit moot. If it wasn't the case, and there weren't other examples that require attribution already shipped; then I would probably have agreed with you by now.
-
I was digging into the BSD license and exploring the reason for the attribution requirement.
The reason is credit where credit is due.
If someone wants to use some software and not even give the author credit for it (or even pretend they wrote it themselves). Then they really don't deserve to use the software.
You are obviously trying very hard to find a way through, but the real question to ask is "what is it about the Apache licence that allows NI to use software under that licence?". The Apache licence has far more restrictions than BSD (including attribution).
However, I think it is more a case of will than law or technicalities which is the stumbling block. And without a corporate lobotomy, that's gong to be hard to overcome.
-
First thing we could use are functions to convert between JSON-format strings and regular LabVIEW Text (escaped characters, encoding, add/remove the quotes). I’m weak on regex.
I've already implemented the removal of quotes. The only escaped chars that I know "must" be escaped are unicode strings and I'm not sure what to do about that with LabVIEW not supporting Unicode without using OS dependent code.
-
I’ve added a new version to the CR (sorry Ton, I will need to learn how to use Github).
I added a JSON to Variant function. Note that I’m trying to introduce as much loose-typing as possible (very natural when going through a string intermediate), so the below example shows conversion between clusters who have many mismatched types, as well as different orders of elements. It would be nice to think about what type conversion should be allowed without throwing an error.
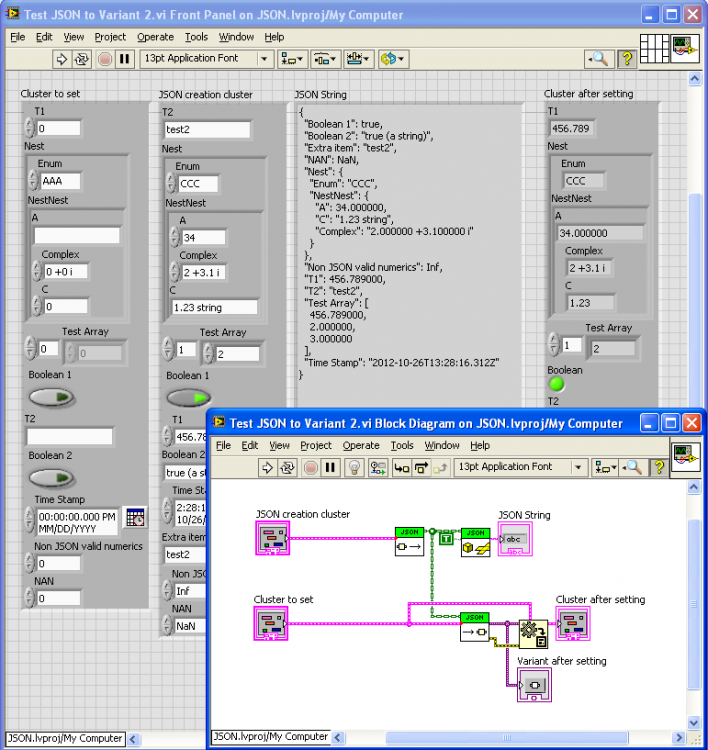
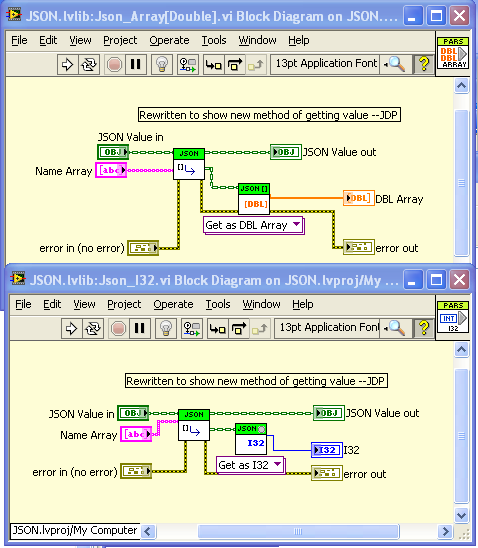
And I’ve started on a low-level set of Get/Set polymathic VIs for managing the conversion from JSON Scalers/Arrays to LabVIEW types (very similar to Shaun’s set but without the access by name array). I’ve reformatted two of Shaun’s VIs to be based of the new lower-level ones. The idea is to restrict the conversion logic (which at some point will have to deal with escaped characters, special logic for null (==NaN), Inf, UTF-8 conversion, allowed Timestamp formats, etc.) to be in only one clearly defined place. At some point, I will redo the Variant stuff to work off of these functions rather than relying on the OpenG String Palette as they do now).
Do you want to list out the tasks that need to be done so that we can apportion them between us?
-
Are you dynamically loading the addons using a path?
If so. You should be aware that when compiled into the exe the path changes so
c:\temp\myfile.vi
becomes
c:\temp\myexecutable.exe\myfile.vi

gesture recognition for any background using image processing
in Machine Vision and Imaging
Posted · Edited by ShaunR
This can be alleviated by using a camera with a shallow depth of field so that the hand is in sharp focus but a few inches back is totally out of focus. He will not be able to do that with a laptop cam however, but he might get away with a webcam with a manual focus ring if he is far enough away.