

ShaunR
-
Posts
4,939 -
Joined
-
Days Won
305
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
How to overcome this error? By doing what the error messages says.
-
 1
1
-
-
What is it they say about the last 10% of a project is 90% of the work?
I stand by my original statement "What a crappy, poorly thought-out protocol"
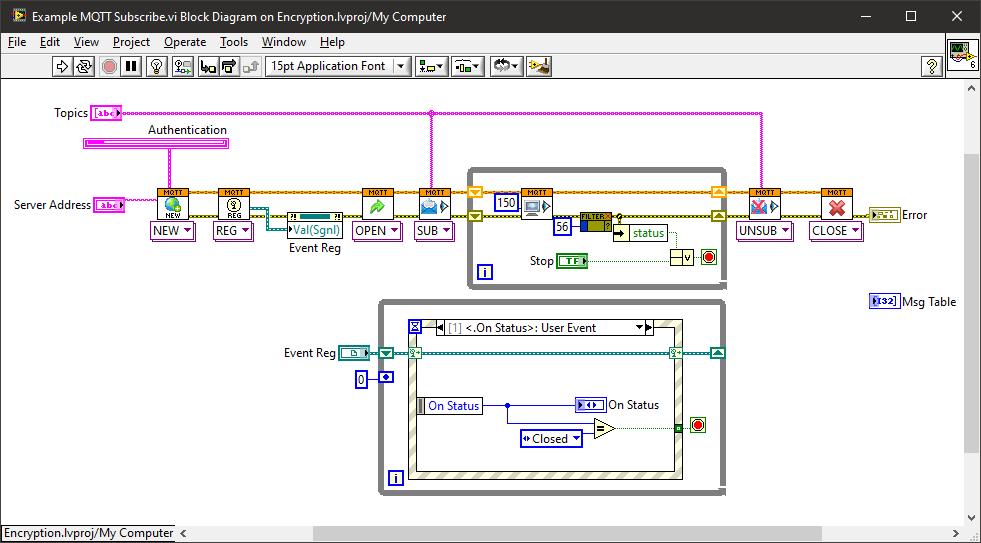
So. Like I said earlier, 1/2 the state is in the client and 1/2 in the server. I'll add now "they have to agree". So what if they don't agree? Well, here we go.
Client and server maintain a list of packets (Packet Identifier).
Quote• MUST assign an unused Packet Identifier when it has a new Application Message to publish
Ok. Can do that.
QuoteMUST treat the PUBLISH packet as “unacknowledged” until it has received the corresponding PUBREC packet from the receive.
MUST NOT re-send the PUBLISH once it has sent the corresponding PUBREL packet
OK. But what if I don't get the PUBREC? I can send a duplicate right?
QuoteThe DUP flag MUST be set to 1 by the Client or Server when it attempts to re-deliver a PUBLISH packet
Sweet
")
Oh wait.
QuoteWhen a Client reconnects with Clean Start set to 0 and a session is present, both the Client and Server
MUST resend any unacknowledged PUBLISH packets (where QoS > 0) and PUBREL packets using their
original Packet Identifiers. This is the only circumstance where a Client or Server is REQUIRED to resend
messages. Clients and Servers MUST NOT resend messages at any other timeOk So we save them up for connect only. Job done, right?
QuoteClients and Servers control the number of unacknowledged PUBLISH packets they receive by using a Receive Maximum.
If it receives more than Receive Maximum QoS 1 and QoS 2 PUBLISH packets where it has not sent a PUBACK or PUBCOMP in response, the Server uses a DISCONNECT packet with Reason Code 0x93 (Receive Maximum exceeded)
Ummm. So we can only send duplicates at connect (and only if it's a persistent session) and there can only be so many unacknowledged ACK's otherwise we get spanked. So what happens if the unacknowledged packets reaches the limit?
QuoteIt MAY continue to send PUBLISH packets with QoS 0, or it MAY choose to suspend sending these as well.
Really? Go silent or hope for the best depending on the whim of the developer?
Hmmm. So what does this look like in the real world.
- EMQX: 2 hours before getting Receive Maximum exceeded.
- Hive: 20 minutes before getting Receive Maximum exceeded.
- Mosquitto: 1 hour before getting Receive Maximum exceeded.
That's no good. Lets send duplicates if we have some acks and are getting near the limit (that's what we should be doing IMHO)
- EMQX: 40 minutes before getting getting disconnected (Packet Identifier in use). Can't blame them. Crappy protocol.
- Hive: 24 hrs and still going but getting duplicates in the subscriber (that's not right for QOS 2 but could live with it.)
- Mosquitto: 24 hrs. and still going. No problems. We have a winner!
This is a doozy too:
QuoteFor Reason Code 0x91 (Packet identifier in use), the response to this is either to try to fix the state, or to reset the Session state by connecting using Clean Start set to 1, or to decide if the Client or Server implementations are defective.
Fix the state (normally that would be with duplicates), restart (without persistent session-poor subscribers
) or blame someone else.
Am I missing something?
-
1
-
On 1/19/2023 at 7:26 PM, Jordan Kuehn said:
One feature of a native broker that I would love to see is the ability to cluster brokers like EQMX or other.
This is an interesting feature that I guess is one of the mechanisms for clustering. It's basically like an HTTP redirect but I'm not sure how I'm going to handle it ATM. CONNACK is fine but a disconnect is usually the end of the conversation with an error 66.
Interesting that they don't mention a redirect depth.
Quote4.11 Server redirectionA Server can request that the Client uses another Server by sending CONNACK or DISCONNECT withReason Codes 0x9C (Use another server), or 0x9D (Server moved) as described in section 4.13. Whensending one of these Reason Codes, the Server MAY also include a Server Reference property toindicate the location of the Server or Servers the Client SHOULD use.The Reason Code 0x9C (Use another server) specifies that the Client SHOULD temporarily switch tousing another Server. The other Server is either already known to the Client, or is specified using aServer Reference.The Reason Code 0x9D (Server moved) specifies that the Client SHOULD permanently switch to usinganother Server. The other Server is either already known to the Client, or is specified using a ServerReference.-
1
-
-
1 hour ago, Rolf Kalbermatter said:
I haven't looked at MQTT but this kind of ID is usually only really used to match responses to the request and/or verify that you got the right response. It should not contain any crypto relevant value, so I would not expect it to matter. More important would be that you can reasonably guarantee that your random generator never will result in the same ID being returned within a small time window, as that makes the whole purpose of being able to match the response to the request pretty difficult. In that sense a monotonically increasing ID that eventually wraps around is actually more useful than a true random ID.
Indeed. It's not so much a time window. It's if packets are unacknowledged for the QOS modes. The Packet ID is shared between the Server and client in order for them to synchronise state for the duration of a packet in-flight. That's not an issue for the library as it necessarily needs to do that but I expose the Packet ID to the user in order that they can do session packet tracing. A server, for example, will take into account which packets are unacknowledged for a session and may resend or an unknown Packet ID is received and the connection must be closed.
1 hour ago, Rolf Kalbermatter said:Usually the client generates the ID and sends it with the request. The server simply copies it into the response without doing anything else. The client can then verify that the received response is actually for the sent out request and not some other stray request. In a connection based protocol using TCP/IP, this is usually kind of superfluous but for UDP or serial port communication it can be useful.
True. However MQTT can retain sessions across connections. In order to do that it keeps a track of the unacknowledged Packet ID's (QOS 1&2). Technically, they should be able to cope with a random vs sequential Packet via lookup tables if the user really needs to but I thought maybe there was a use case for sequentially increasing Packet ID's to, maybe, identify packet order.
-
Ok. Turns out that Mosquitto and Hive partially support MQTT v5. Mosquito more than Hive (or it may just be more tolerant) but not all the properties in the spec. So they are probably v4.x. EMQX is a 14 day trial so I didn't bother with it in the end.
I'm just embarking on the cleanup and documentation (the fun's over
) but I have a quick question about the packet ID's. The spec doesn't define what they should be apart a u16 and non-zero (when they are there). So I decided to make them random (usually a good choice in crypto stuff). Mosquitto uses sequential incrementing by 1 and Hive uses sequential incrementing by 50. Technically, they are only used internally by the clients and servers but I was wondering if anyone relies on them being sequential for other things where a random packet ID would be a pain?
-
4 hours ago, JKSH said:
It's not clear to me whether the EMQX public broker supports v5 or not... https://www.emqx.com/en/mqtt/public-mqtt5-broker
...but their downloadable one does, apparently: https://www.emqx.com/en/try?product=broker
Sweet. I'll check it out.
-
Well. It didn't take long to prototype the MQTT client as I was expecting - once I figured out it wasn't my code and it was just properties weren't supported by the public Mosquito server.
The Hive MQTT public server doesn't seem to support V5 either.
Anyone know of a public V5 server?
-
1
-
-
5 hours ago, Rolf Kalbermatter said:
It's most likely organically grown. Guaranteed green and maybe even vegan. 😁
And grown and groomed by many different "developers".
Aha!
So properties are MQTT-V5 only. V3.1.1 has those fixed fields and doesn't have a variable integer at all. That explains the fixed fields and fixed sized integers I moaned about - backwards compatibility. I'm ambivalent if I can forgive them for that as it's a noble trade-off but they could have handled it much better than they have.
-
2 hours ago, Rolf Kalbermatter said:
It's most likely organically grown. Guaranteed green and maybe even vegan. 😁
And grown and groomed by many different "developers".
It was obviously grown like a furry mold.
The way they have designed it means that the user has to know so much about the protocol and what properties to bind to what messages. I'm having a hard time burying the complexity for the user. I wouldn't be surprised if a lot of the LabVIEW solutions out there are only partial implementations and ignore properties completely.
-
What a crappy, poorly thought-out protocol.
- You have a variable length integer (up to 4 bytes) but lets also have some fixed sized integer types less than 4 bytes for the giggles.
- You have an error byte...sometimes...with command/response contextual meanings.
- You have properties, that may or may not be there, but only for some commands and responses.
- You have command specific, fixed, fields before the properties for some commands/responses.
- Some commands ack, except when they don't.
- Half the state is in the client and the other half is in the server.
- A significant number of the "features" are to get around the previous bullet point.
-
 1
1
-
Works for me.
-
1
-
-
31 minutes ago, hooovahh said:
The problem with this idea, is that the ico file contains multiple images in it, at different resolutions. You could in theory, take the LabVIEW image constant, save it to a temporary PNG file, then use that path to set the icon. But I think you'd be better off with an ico file itself. You can embed the ico file in the VI as a string constant, and do the same thing, saving it to a temporary location as well.
You can create an icon on-the-fly using CreateIconIndirect. I have never found the need but, in theory, you could convert an image into the bitmap masks required for an icon. You could then use the WM_SetIcon as previously.
-
5 hours ago, Rolf Kalbermatter said:
My experience about trying to create a universal, generic class hierarchy for one or more device types is that it is a never ending story that will make you go back and forth over and over again as you try to shoehorn one specific instrument feature into the existing class interface to eventually notice that it breaks another feature for a different interface in the same place. Basically it is a noble pursuit to try to do that, but one that fails sooner or later in the reality.
Yup. I don't go that route at all. The number of "HAL's" that I've seen that make a simple piece of software rigid and a nightmare to maintain.
I go with a simple route of wrapping a non SCPI device driver with a with a SCPI compliant "controller". The "controller" is the stub I spoke about previously when no device is available - which then mutates into an SCPI driver when the device arrives (if it needs one). Then the application has a standard interface (string message) to all devices and only has to worry about what messages to send to which devices-you can even script multiple messages from text files! Much easier to change a string than a class hierarchy and, if you add a device, you don't need all the boiler-plate programming that classes require-just new strings.
-
23 minutes ago, CT2DAC said:
so what can be so complicated in a trivial handful of commands and parameters?
Termination characters, for a start.
I would echo what Rolf is saying. With SCPI you can get some of the way there as it standardises instrument behaviours - but even then it' has limitations.
IMO, the most expedient way to develop when you don't have the hardware is to use stubs rather than simulators. Design top-down and use stubs where you would have a driver to give you a value and an error that you can can use to develop and test the rest of the software. When you get the hardware, you can use the stubs as an interface to a driver to massage whatever it gives into a form your software is expecting. You will, to all intents and purposes, be designing a proprietary interface for your particular software that you glue drivers underneath as and when you get your hands on them.
-
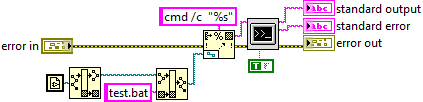
Have you got a load of spaces before the test.bat string?
This works fine.
-
Start is an extension. Remove "start" or enable cmd extensions (/e:on). I'm guessing you think the "/x" is enabling extensions. It's not. There is no "/x".
-
1 hour ago, SebastienM said:
Maybe we should create another post to talk about WATS.
That's probably a good idea and we can get an moderator to move the previous posts over.
-
3 hours ago, bjustice said:
this carries the item part type and properties
Oh wow. I thought it was just buggy and overwriting my other images.
I always used the file import because of that.
-
2
-
-
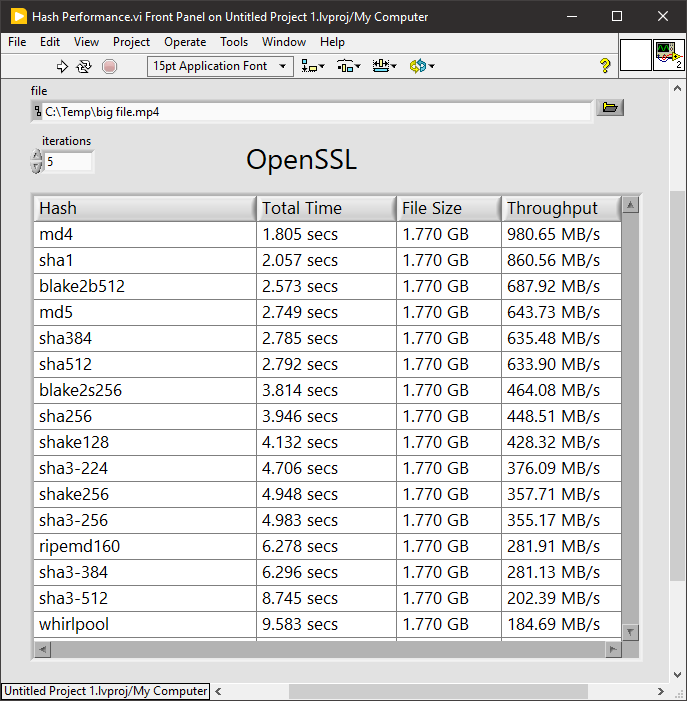
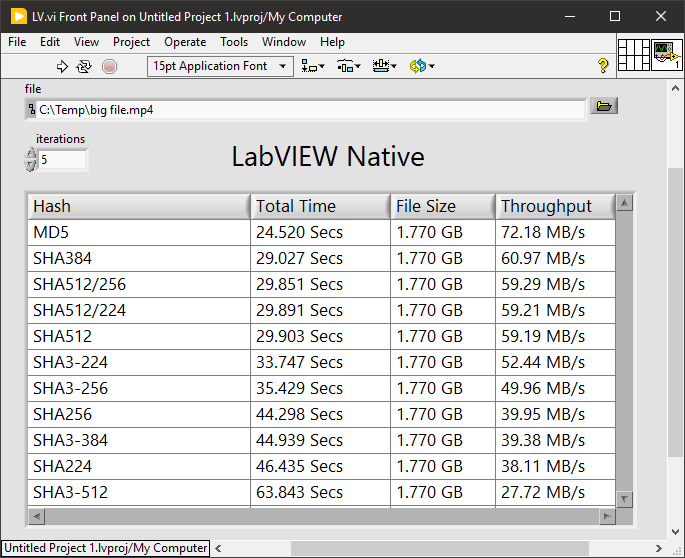
As this has popped up again and someone may find it useful. Here are some comparative benchmarks between LabVIEW and OpenSSL hashes (sorted fastest to slowest).
-
15 hours ago, bjustice said:
I can't seem to figure out how they were able to make this combination, because I can't find any control on the native palette with these item parts.
The System Button has the mouse over images.
You can't "import parts", only the images for the states. That includes if you simply want to change the mouseover colour (copy the image, paste it into an image editor, change the colour, then import it back again).
The mouseover also only works while the VI is running.
-
1 hour ago, SebastienM said:
I have to disagree. Yes WATS is a data analytics tool.
But it is also a configuration tool with modules like software, firmware, serial and MAC distribution, and asset management.
-
OK. Decision made - reinvent the wheel
The final nail in the coffin of using something like Paho MQTT was DLL distribution and integration with current features.
-
5 minutes ago, Rolf Kalbermatter said:
I'm not convinced. They either have no idea about how complicated LabVIEW is or just hoped they could put some sand in the NI managers eyes by teasing them with what they thought is still NI's pet child.
Me neither. What exactly are "the LabVIEW suite of offerings"? (Please don't tell me BridgeVIEW or whatever they are calling it now
)
-
2 hours ago, SebastienM said:
Well 2 years ago I saw a demo of System Link by a Ni salesman and that was a huge buggy disaster, absolutely giant failure.
I convinced my company to use WATS of Virinco instead : best choice ever.
Well. They are not really equivalent. System Link is, first and foremost, a configuration and asset management tool. Buggy? Maybe (I haven't looked recently) but that could be addressed. WATS is specifically a data analytics tool. WATS has more in common with Diadem than System Link.
")




 Interesting that they don't mention a redirect depth.
Interesting that they don't mention a redirect depth.
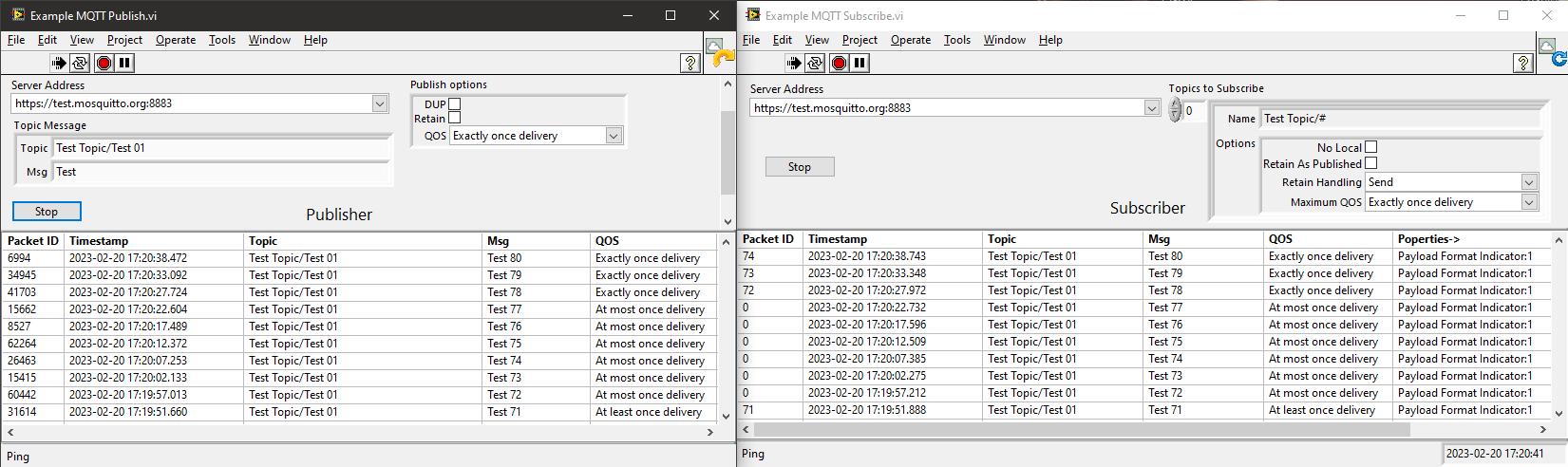
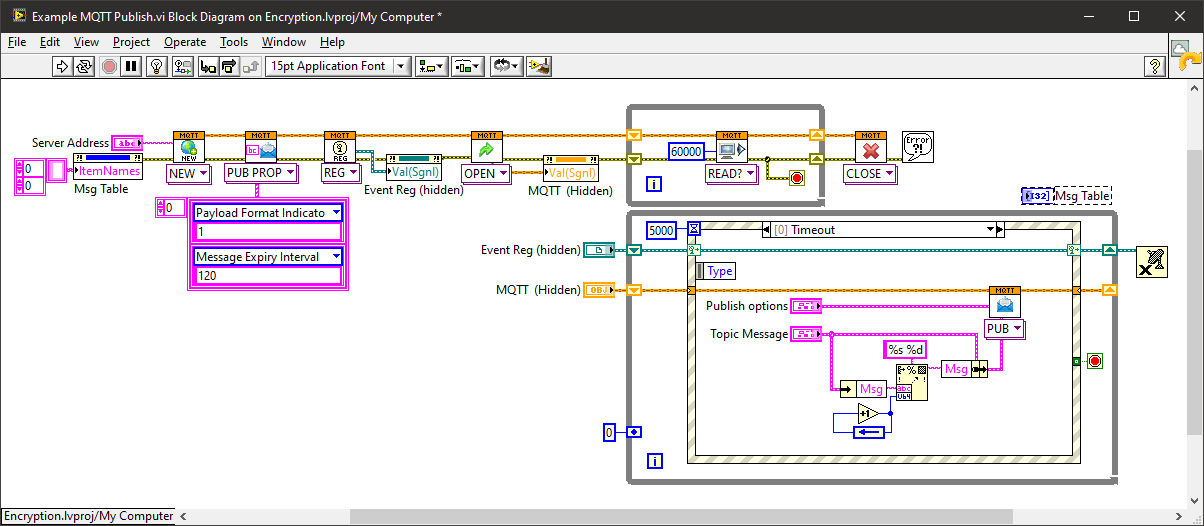
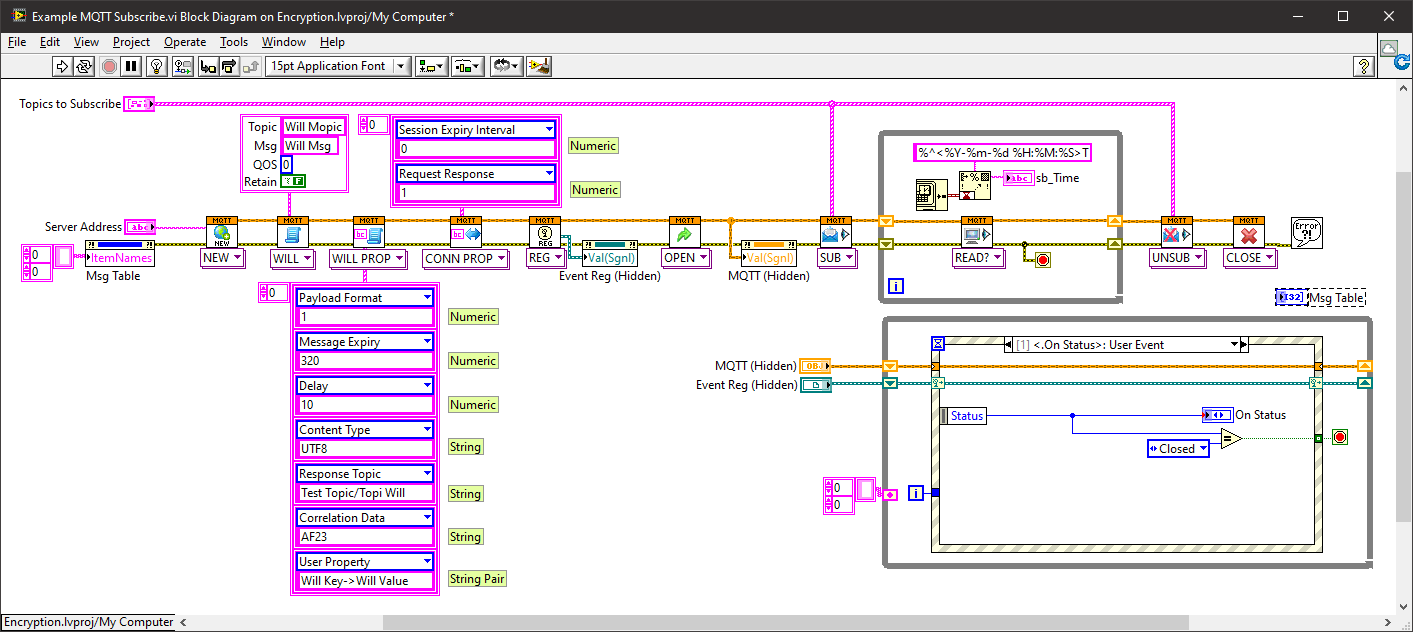
 The Hive MQTT public server doesn't seem to support V5 either.
The Hive MQTT public server doesn't seem to support V5 either.
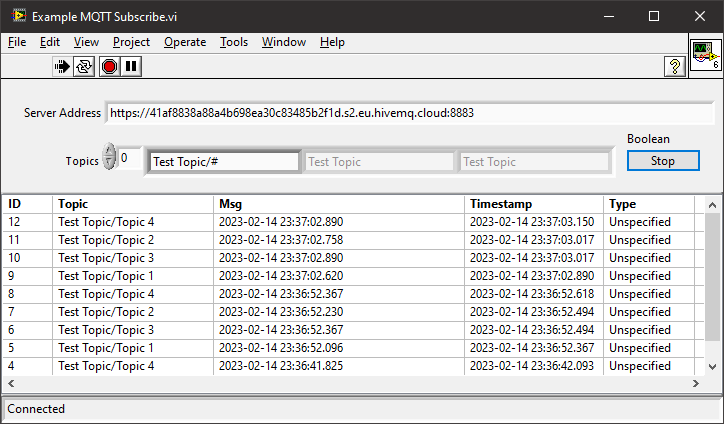


")
 )
)
LV 2021 thick line decoration changed
in LabVIEW General
Posted · Edited by ShaunR
I've no idea if they introduced an an ini setting for aliasing or a real solution for this but a classic, flat, square, button can be collapsed to 5px and, if you make the border transparent (which is 1px), it looks like a 3px line. However it won't do arbitrary angles-horizontal and vertical only.
You may have to rethink how you display your fluid with either the picture control or jpg/png images copy and pasted to the FP, if it's a real issue. I'm not sure how you are using to display a fluid (reveal behind a progress bar?). I've never used decorations as they are so limited.