

ShaunR
-
Posts
4,942 -
Joined
-
Days Won
308
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
Well. What is your immediate pain? Can you elaborate?
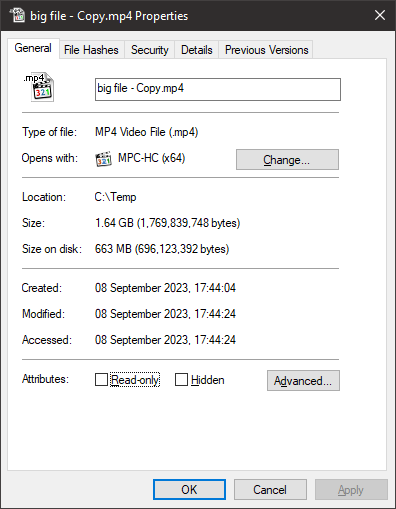
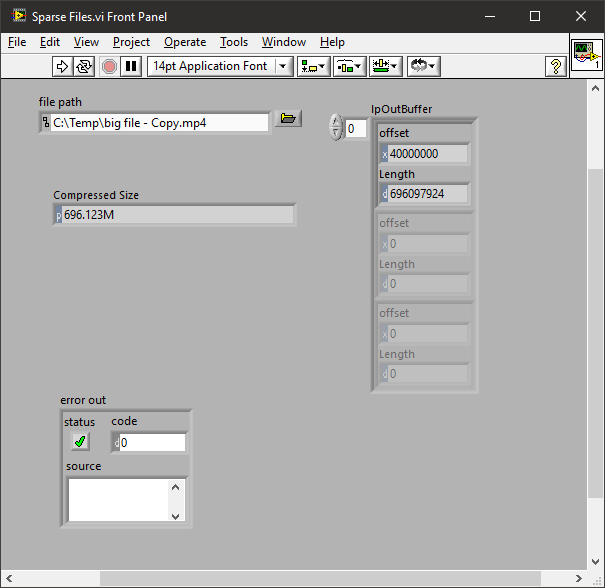
Here is an existing file with the first 0x40000000 (d:1073741824) bytes nulled.

You can see it only has about 600MB on disk.
If I query it I see that data starts at 0x40000000
Now I can do a seek to that location and read ~600 bytes. However. I'm guessing you have further restrictions. -
9 hours ago, GregSands said:
I'm guessing there must be more to your question, but based on your specs, I'd be asking whether it was worth spending time and effort deleting a relatively tiny part of a file. 100k out of tens of GB? I'd just leave it there and work around it!
It's a common requirement for video editing.
-
9 hours ago, Reds said:
Thanks for the Microsoft link to Sparse files. I"ll dig into that and learn more.
You can play with fsultil but Windows (A.K.A NTFS/ReFS) doesn't have the "FALLOC_FL_COLLAPSE_RANGE" like fallocate (which helps with programs that aren't Sparse aware).
-
1 hour ago, dadreamer said:
It is what I was thinking of, just in case with Memory-Mapped Files it should be a way more productive, than with normal file operations. No need to load entire file into RAM. I have a machine with 8 GB of RAM and 8 GB files are mmap'ed just fine. So, general sequence is that: Open a file (with CreateFileA or as shown above) -> Map it into memory -> Move the data in chunks with Read-Write operations -> Unmap the file -> SetFilePointer(Ex) -> SetEndOfFile -> Close the file.
Indeed. However. Hole punching is much, much faster. If you are talking terabytes, it's the only way really.
Set the file to be Sparse. Write 100k zero's to the beginning. Job done (sort of).
-
On 9/5/2023 at 11:19 AM, dadreamer said:
Not an issue for "100kB" views, I think. Files theirselves may be big enough, 7.40 GB opened fine (just checked).
A 100kB view will not help you truncate from the front. You can use it to copy chunks like mcduff suggested but
On 9/4/2023 at 7:41 PM, Reds said:A file so big that it won't fit into your PC RAM
The issue with what the OP is asking is to get the OS to recognise a different start of a file. Truncating from the end is easy (just tell the file system the length has changed). From the front is not unless you have specific file system operations. On Windows you would have to have Sparse Files to achieve the same as fallocate
-
 1
1
-
-
1 hour ago, Francois Aujard said:
Where else do you want to store? What do you mean by "relational database" ? Are you copying into a double array stored in a global variable ?
MySQL, MariaDB, SQLite, PostGreSQL are examples of Relational Databases. They consist of tabular data that can be interrogated by their relationships. Key-Value (or Hash lookup) are another type of database and often referred to as NoSQL databases.
No global variables. You may think of the database as a global variable containing all information you have acquired or need to know (it's not really but it will suffice). If these concepts are new to you, then perhaps just concentrate on separating the analysis and display from the acquisition - that is the important part..
-
56 minutes ago, Francois Aujard said:
What is a VDM and IMO ?
Not sure about VDM but I did say DVM (Digital Volt Meter).
IMO - written abbreviation for "in my opinion": used when you tell someone your opinion, for example in an email.
SIC - sic erat scriptum, "thus was it written")[1] inserted after a quoted word or passage indicates that the quoted matter has been transcribed or translated exactly as found in the source text, complete with any erroneous, archaic, or otherwise nonstandard spelling, punctuation, or grammar. It also applies to any surprising assertion, faulty reasoning, or other matter that might be interpreted as an error of transcription.
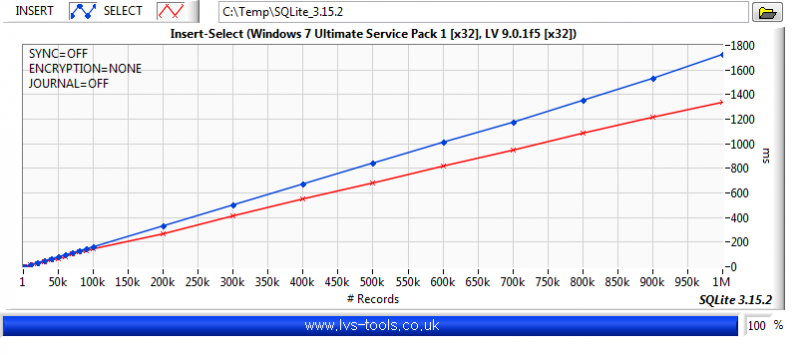
1 hour ago, Francois Aujard said:Database like SQL or other? No problem with recording speed ?
SQLite is pretty fast but huge amounts of raw data are better stored elsewhere and referenced from a relational database. Key-value stores have their place too.
-
15 minutes ago, dadreamer said:
I would suggest Memory-Mapped Files, but I'm a bit unsure whether all-ready instruments exist for such a task. There's @Rolf Kalbermatter's adaptation: https://forums.ni.com/t5/LabVIEW/Problem-Creating-File-Mapping-Object-in-Memory-Mapped-FIles/m-p/3753032#M1056761 But seems to need some tweaks to work with common files instead of file mapping objects. Not that hard to do though.
There is a limit to how much you can map into memory.
BTW. Here is a LabVIEW mmap wrapper for working with files on windows
-
What I'm about to say will either "click" or be totally meaningless with respect to what you are asking. But here we go.
The No.1 goal should to separate the user interface / analysis from the acquisition. That is, how the information is viewed should be completely divorced from how the information was acquired. To achieve that you will have a surprisingly few number of options with regards to a single, templated architecture. By far the most convenient way is via a database which isn't featured in any classical LabVIEW architectures..
So. We have decided to split the program into 3 halves [SIC
]. The first half (acquisition) will be any method we choose that populates the database with as much information as we need or can elicit. The second half will just be a UI and any analysis that executes queries on the the database and displays it. I am deliberately ignoring configuration but the database also solves this problem for us too.
So the acquisition is just a series of operations to populate the database. Our focus isn't on the LabVIEW architecture for achieving acquisition, it is a LabVIEW architecture for populating a database. How do we do that? It depends. It depends on whether in populating the database with a single piece of information we require more than 1 device to do so. For example. If we only have to read a DVM every 10 seconds then we can just call a VI to read the DVM and put the value in the database with the time . If we have to set a voltage, set a temperature, and then read a DVM then we require something more sophisticated to handle state and populate the database not only with the DVM reading and time , but with the voltage and temperature. However. We are not in the straight jacket of, say, Actor Framework or Producer Consumer et. al. To populate that information we can use any classical LabVIEW architectures for that database update.
As the program evolves, the reusable portions will reveal themselves and a particular classical architecture will become dominant based not only the demands of acquisition but the preferences of the designer (you). However. We are not limited to that one architecture. This process produces an Emergent Architecture and is greatly expedited by experience. It is what Agile development tries (and fails, IMO) to capture.
So:
QuoteFor a TCP-IP communication with 5 sensors, is it preferable to make a Vi that communicates with everyone, or 1 Vi re-entering with 5 instances in memory?
To populate the database if the 5 sensors are identical then you could use "1 Vi re-entering with 5 instances in memory"
To populate the database if the 5 sensors are all different then you could "make a Vi that communicates with everyone" (especially if they are SCPI compliant).
But there are other options....
To populate the database then you could launch an Actor for each device.
To populate the database then you message a Producer Consumer service that handles that device type.
--------------------------------------------------------
Now. Because we have separated the UI and analysis from the Acquisition, you can play with the acquisition implementation details or re-architect/reorganise the acquisition without affecting the analysis and presentation, So if you are operating in an agile environment, the acquisition can go through many tight iterations of the acquisition code and still maintain black-box test integrity for regression testing.
Other options are also valid such as "everything is an object so do POOP"
-
8 hours ago, X___ said:
Here is ChatGPT's answer:
You can delete part of a file without loading it entirely into RAM by using the
ddcommand. This command can be used to move the contents of the file up by a specified number of bytes, effectively deleting the specified number of bytes from the beginning of the file1. Here is an example script that you can use to delete a specified number of bytes from the beginning of a file:
Copy#!/bin/bash size=$(stat -c %s "$2") dd bs=$1 if="$2" skip=1 seek=0 conv=notrunc of="$2" dd bs=$((size - $1)) if="$2" skip=1 seek=1 count=0 of="$2"You can call this script as
./truncstart.sh 2 file.dat, where2is the number of bytes to delete from the beginning offile.dat1. However, please note that this solution is not robust in case of an unplanned outage, which could occur part-way throughdd’s processing; in which case the file would be corrupted1. Is there anything else you would like to know? 😊Linux only huh? No mention of fallocate?
Why do people keep posting junk from ChatGPT? At this point I consider it spam.
-
 2
2
-
-
First point is it looks like it is a 32 bit DLL. Are you using 32 bit LabVIEW? (LabVIEW 64 bit for 64 bit DLL's)
If you are using LabVIEW 32 bit for the 32 bit DLL then check all dependencies are available using something like "Dependency Walker". It will tell you what is missing or cannot be found for LabVIEW to load the DLL.
-
- Popular Post
- Popular Post
15 minutes ago, Bryan said:I may be dating myself a bit here, but I remembered that from the original Simpson's episode. I don't recall if the meme or the episode would be older. Would that still check out? LOL!
-
 3
3
-
1 hour ago, Bryan said:
"In Soviet Russia, moon hit you!"
-
2
-
-
1 hour ago, jcarmody said:
Did ChatGPT make a passable TL;DR?
Nope. All structure, no content.
-
I'm surprised it works at all tbh.
The Intialise is in side the while loop but the close is outside. Either move the initialise to outside the loop or the close to the inside.
You start to read when there are greater than 0 bytes (1 or more), but you want 23 bytes. Either accumulate bytes as they come in until you have 23 and then decode into the numerics and strings or wait until there are 23 bytes at the serial port (rather than greater than zero) then decode.
See how far those changes get you.
-
26 minutes ago, Rolf Kalbermatter said:
The only improvement I could think of nowadays is to allow to hide the right side terminals!
How about giving us the ability to define right side terminals (like "Panel Close?") and give us the ability to allow an event case behave like a callback? That'd be a fantastic improvement.
-
15 hours ago, Darren said:
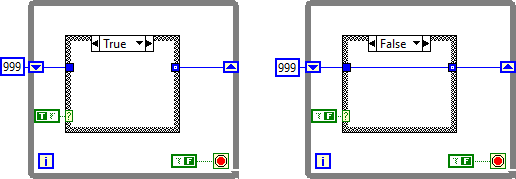
Antoine is correct, those diagrams should function identically.
Should they?
18 hours ago, hooovahh said:There are some behaviors in LabVIEW that either weren't well defined, or up for interpretation on how it should work.
How about this?
I have expected this argument to be made (for events) for a few years now. It would break almost all event structure code if it were changed to be in line with the other structures.
-
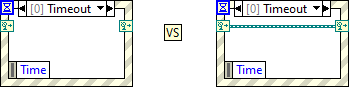
quick straw poll....
What's the difference in behaviour (connected dynamic terminals vs unconnected)?
-
57 minutes ago, Rolf Kalbermatter said:
That would be a management nightmare. There would be no possibility to handle more than one event registration to subscribe to the same even generator without very involved buffer management. By placing the event queue into the event registration object it is fairly simple.
1) Hey here is my event queue, post any event you get to it.
2) I only have to check that queue to see if there is any event to handle. Not some other queue that might or not might have events present that I already processed but need to remain in it because not all event registrations have yet gotten to read that event.
There is a relatively cheap check needed in the event generator to see if the event registration queue is still valid before trying to post a new event to it but that’s much easier than turning the single.queue into a pseudo random access buffer for use with multiple registrations.
Similarly the event registration needs to check that the event generator is still valid when trying to deregister itself from it on its own destruction but that’s again a fairly simple Is Not an Object/Refnum check.
I'm not really sure what we are arguing about here. I like events as they are (and have said so) and only said that I hope they don't change it the more general view of the LabVIEW API's. If you want me to seethe with indignation about implementations, then talk to me about reading an end of file as an error
-
14 hours ago, Rolf Kalbermatter said:
That event queue is owned by the registration refnum
It is indeed. But it doesn't have to be They could have decided it should behave like Queue's and an Event Reg merely creates a reference to the internal queue. IMO, Darren's nugget is a side effect of an implementation peculiarity (which you have explained in exquisite detail) rather than a philosophical design - a peculiarity I hope never changes
.
-
57 minutes ago, Rolf Kalbermatter said:
It's not a bug and there is nothing that could be fixed here.
Oh I don't know. They could delete the registration queues of any registration that referenced the event that was destroyed - they have to delete the registration queue at some point, right?. Luckily, that hierarchy isn't implemented and hopefully it would be too tiresome to implement.
57 minutes ago, Rolf Kalbermatter said:The event registration is special
I love LabVIEW events. I rate them alongside Dataflow, sliced bread and putting men on the moon.
-
30 minutes ago, Jordan Kuehn said:
Thank you for sharing! I would have never seen it since I'm rarely on those forums.
The link is broken, but here is the darkside link: https://forums.ni.com/t5/LabVIEW/Darren-s-Occasional-Nugget-08-07-2023/td-p/4321488
I fixed the link. Not sure what happened there.
-
I don't post on the dark-side but I thought Darren's Occasional Nugget 08/07/2023 was a nugget well worth commenting on over here.
I have used this behaviour for a very, very long time. Every time I use it, I always have to convince myself that NI will not "fix the bug" like they did with events and tunnels. I always thought it was an anomaly when compared to the other API's-but a very welcome one which, as Darren rightly says, "this behavior makes event programming more straightforward than other APIs".
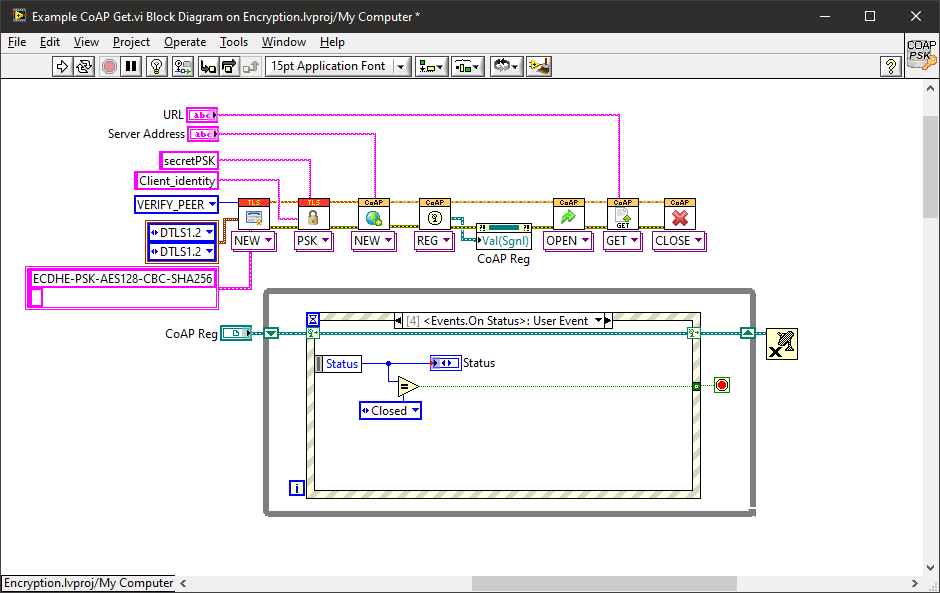
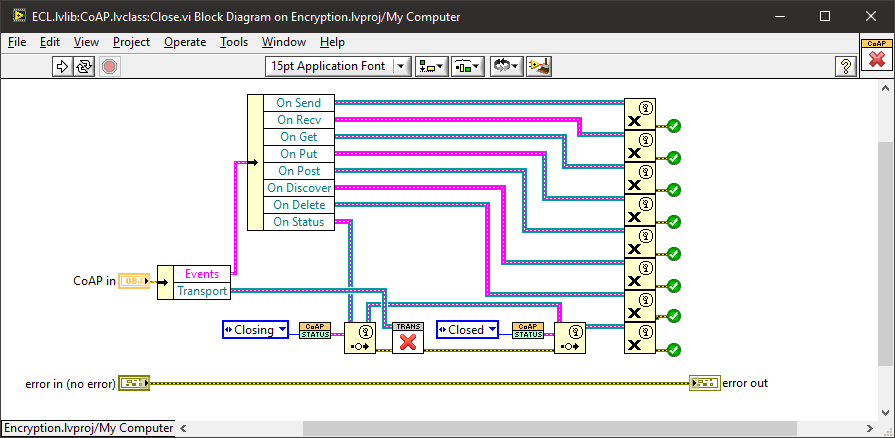
Darren's example may seem a bit contrived and convoluted so I would like to add a real-world, concrete, practical example which would not work correctly without this behaviour.
The example (which is one of many that use this behaviour) relies on the "On Status" event being fired after the the event reference is destroyed in the "Close" function. Actually it is fired twice. Once for "Closing" and once for "Closed".
If the event on the structure's queue was not retained and actioned after destruction, then the "Closing" and "Closed" events may never reach the loop - it may not terminate. There would be a high probability that a "Closed" status may not be received and it would be a race between the event structure executing and the "Close". A specific "shutdown" event would have to be added and managed - greatly increasing the diagram complexity. (this one reason why "Tunnels" and "Actor Framework" are so complex).
But it gets better. Regardless of the Destroy primitives, all data and status' from the "Get" function, in the executed order, are also maintained independent of the speed of execution of the event structure. This means that when in debugging mode we can see all the events' data and execution even after the Destroy function has been executed in the "Close". As Darren has pointed out, a queue reference would not behave in this way and report "Refnum No Longer Valid" making debugging a much more difficult task.
-
1
-
-
Try asking on a Python forum. This is a LabVIEW forum.
 ]. The first half (acquisition) will be any method we choose that populates the database with as much information as we need or can elicit. The second half will just be a UI and any analysis that executes queries on the the database and displays it. I am deliberately ignoring configuration but the database also solves this problem for us too.
]. The first half (acquisition) will be any method we choose that populates the database with as much information as we need or can elicit. The second half will just be a UI and any analysis that executes queries on the the database and displays it. I am deliberately ignoring configuration but the database also solves this problem for us too.

") .
.
Editing a Very Large File
in LabVIEW General
Posted
Indeed.
Which is what you need.