
JackDunaway
-
Posts
364 -
Joined
-
Last visited
-
Days Won
40
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by JackDunaway
-

CTRL+SHIFT+ Shortcuts sometimes not working in LabVIEW
JackDunaway replied to JackDunaway's topic in LabVIEW General
Solved. Sincerely -- thank you! I will report this back via support channels to NI on this issue. -
CTRL+SHIFT+ Shortcuts sometimes not working in LabVIEW
JackDunaway replied to JackDunaway's topic in LabVIEW General
Still exists for me too. OS X 10.10.1 Parallels 10.1.1 (28614) All VMs, Win7 thru Win8.1 -
To carefully dereference "certain tool", if that refers to LVLIB, yes -- it's worth considering whether this tool belongs in our toolbox. If "certain tool" dereferences to LabVIEW -- LabVIEW as a language is excellent and certainly not worth abandoning. Conversely, it's worth considering if you're not already using it. LabVIEW has rooms for significant improvement, but its syntax is currently unparalleled in programming, period.
-
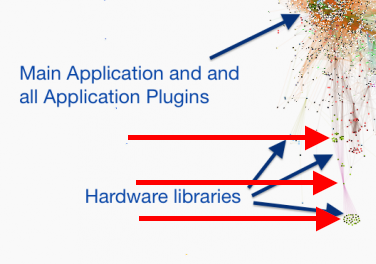
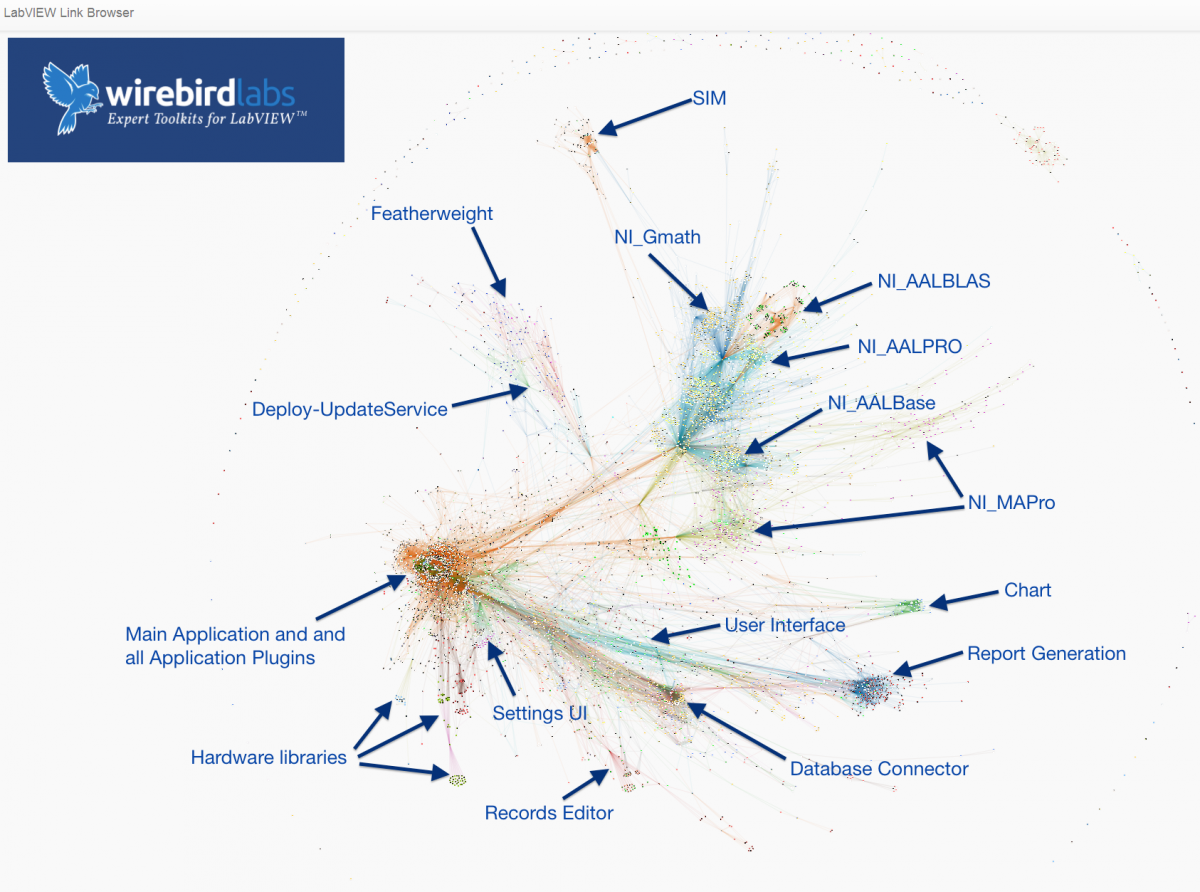
It's tenable at worst, desirable at best, for an LVCLASS and its members to be statically-linked. Any desire otherwise could be an indicator of class design or object model that could use refactoring, or a desire for more appropriate language facilities (more on that later). For an illustrated example, here's one annotated section of the diagram above: The top arrow shows methods from a third-party hardware driver that are required by the application, the middle arrow is very likely an LVCLASS or LVLIB, and the bottom arrow shows unreachable, unused dependencies -- portions of the hardware API that bloat the application. Although not ideal, this scenario of roughly ~30 unused source files may not be measurably bad. The birds-eye view of this application indicates ROI of refactoring this class probably isn't justified. Though, used in another application, that exact same library could cause problems (such as even further unwanted linkages, perhaps even some that break the application with unsatisfied dependencies such as uninstalled packages or platform-specificity). Different application space yields different polarizing filters through which we choose tradeoffs. As library designers, it's worthwhile to consider our responsibility to enable our developer-end-users, and explicitly avoiding designs which cause them heartache. -- I wasn't going to bring up Inheritance as another type of static linkage best cut with our figurative link scissors, but it's now relevant in the context of LVOOP. Inheritance, in and of itself in any language, represents a code smell worth investigating. But... Inheritance! Dynamic Dispatch! This example demonstrates precisely the value of traits/mixins in an OOP language. With traits/mixins, we can achieve all desirable outcomes discussed above in terms of higher cohesion and looser coupling (and re-use!), by eschewing 1) suboptimal/incorrect inheritance hierarchies, and 2) classes that do too much, even if there appears "good reason" for the monolithic library (Hardware APIs for LabVIEW are notorious for wrapping serial protocols as one-command-per-VI in monolithic libraries. There are thoughts/considerations of dynamic versus static programming as another solution, but that's another thread). Lacking Mixins in LVOOP, Inheritance sometimes is workably sufficient to describe and implement the real-world, but oftentimes it can't. Again, to be fair, it's healthier to focus on measurable negative value than pedantry, and oftentimes it's workable to incur these tradeoffs introduced by inheritance. @ShaunR, for this reason, I don't think LVCLASSes fall short in the way you might be describing. (Except for one debatable behavior in the IDE, where all classes in a hierarchy are broken if one is, and where the explanation as to why in that link is tenuous, where the more desirable behavior is to throw run-time exception in the scenario presented in that link) The way that LVCLASSes fall short is by lacking Mixins, which provide targeted and precise linkages to atomic units of relevant code. (for clarity, regardless whether industry is landing on the term Trait or Mixin, I support the construct that also provides extension of mutable state, not just method implementations, and certainly not just interfaces with no implementations. I think "Mixin" is most appropriate, its distinction from "Trait" being "Trait" might not connote further extension of state) tl;dr The design goal when designing an LVOOP object model is not necessarily to avoid all static links, but rather to intentionally design dependency vectors, especially recognizing and avoiding anomalies and incidental linkages that have detectable negative value. And, LVOOP needs Mixins.

-
LLBs and LVLibs solve different problems (and create different problems), and are not interchangeable or really related beyond sharing the word "library" in their acronyms. Here are some characteristics and comparisons of the two: LLB provides physical packaging containment of members, and does not address namespacing (nor scoping). LVLIB provides namespace containment of members (and also scoping), and does not address physical packaging. Both LLB and LVLIB impose static linkages that can be incidental and undesirable. These negatively affect load times (IDE and run-time), build times, and compile times. Anecdotally, it's greater than O(n) time complexity, especially when circular linkages exist between multiple such hierarchies, and most especially if the library hierarchy is nested (e.g., LVCLASS within an LVLIB, or nested LVLIBs) An LVLIB can be built into an LVLIBP. An LVLIBP is different from an LLB in that an LLB packs writeable, cross-platform* VIs capable of mutating to future LabVIEW versions, while an LVLIBP is a read-only, platform- and version-specific byte code distributable (which may contain the block diagram for debugging, except still remaining platform- and version-specific). An LLB may be used to pack libraries/plugins for deployment as application plugins, or as reusable libraries in development. An LVLIBP effectively is only used for the former. Neither LVLIBP nor LLB can pack non-LabVIEW-source filetypes as resources. Be mindful to account for both renaming/name-mangling resources, and also changes in relative path. LVLIBs (and LVLIBPs) render nicely in the LVProj tree, while LLB members appear indistinguishable from POVIs (plain ol' VIs). LLBs cannot pack two VIs of the same filename. This prevents packaging multiple LVCLASS hierarchies that use dynamic dispatch methods. This represents a few LabVIEW design limitations: 1) LLB's lack of an internal directory hierarchy for organization and packing of two filenames, and 2) LVCLASS using OS filename as the only unique identifier for method identification in a class (filename represents a good default value, but we need one more degree of indirection as a field within the LVClass XML; it's another discussion why this is so highly desirable to decouple source from OS convention). For actively-developed libraries, LLBs are bad because they exist a monolithic binary file. LVLIBs are bad because there exists no diffing or merging capabilities (this also applies to LVPROJ, LVCLASS, XCTL, XNODE filetypes. This is especially insidious, because popular DVCS clients autodetect the file format as XML and think "Aw yeah dude, I got this!" MERGE FAIL. Corrupted source. Be sure to turn off this autodetection for these filetypes.) LVLIBs can apply icon overlays to members. LVLIBs may be carefully designed to include strategic static linkages, including non-LabVIEW source files. This is one strategy to avoid managing the "Always Include" section of AppBuilder for distributables, especially as a convenience for end-user-developers of re-use libraries. But this fails by default because of the setting "Remove unused members of project libraries". Unchecking that often causes failure to build for non-trivial-sized applications linking to gargantuan LVLIBs shipping in vi.lib and as add-ons. So, the strategy may or may not work (it's coupled to whether or not you're keenly aware of and properly managing all application static dependencies) The reason I want to like LLBs is their ability to provide packaging constructs that provide higher performance on actual hardware. It's faster to load 1 file of size 100 units than 100 files of size 1 unit. It's also a more convenient distribution format -- a single file. (Also, I can't think of another language that effectively enforces a 1:1 relationship between method and physical file. LabVIEW requires substantially more clerical work to develop and refactor, for this reason) The reason I want to like LVLIBs is to enable namespacing and scoping beyond the LVCLASS level. Though, this namespacing always comes with the cost of static linking, which is perhaps the #1 problem for codebases of non-trivial size (do you see busy cursors while editing and wiring? long build times? load times? type prop errors? corruptions from application refactoring? heartache and heartburn generally?) Also, LVLIBP is neat in practice, but so narrowly scoped to specific deployment scenarios where it's acceptable to target version- and platform-specfic targets (version-specificity is definitely the bigger problem. every 12mo, we are afforded the opportunity to choose between obsolecense/migration/revalidation or just-plain-outdatedness). And without arbitrary namespace composition (namespace B and namespace C may both declare using namespace A; with namespace A unaware and none-the-wiser), it's not necessarily a compelling feature to begin with. (Corollary: an LVCLASS's ability to namespace and scope its members is desirable and good; but it becomes less necessary and more-likely-incorrect to continue namespacing and scoping at higher abstraction levels without namespace composition) Do LVLIBs Scale? Using LVLIBs in source on an actively-developed project raises barriers to both team scale and application scale. The cost of not using them is loss of scoping, which is avoided through communication and convention, and easily-detected if any actual problem were to exist. Another cost is loss of namespace, easily avoided through filenaming conventions (which is incidentally an industry standard on the web; prefixing library APIs with library-specific prefixes to avoid collision). Said another way, ROI diminishes and reverses to negative at scale, and opportunity cost has simple workarounds. I choose the opportunity cost. But... LVLIBPs! Another apparent opportunity cost of avoiding LVLIB in source is the inability to have LVLIBP as a distributable. Though, if you treat build/distribution as a second toolchain from the dev toolchain, the dev source can remain unencumbered by LVLIB, which is only added as part of the build process. I have mixed feelings on ROI here, but if LVLIBP makes sense for you, consider this strategy to make your dev experience noticeably more pleasant. Here's a real-world case study. This is from a Wirebird Labs client who gave permission to release this screenshot of a bird's eye view of their application analyzed using Links. What we're looking at in the screenshot below is an application with over 8000 application VIs (not including third-party dependencies). Libraries are identified by labels. Nodes represent a source file (mostly VIs, but also including LVLIB and LVCLASS and CTL), and connections between nodes represent static links as detected by the LabVIEW linker. This is a static screenshot of the application, but while running the physics engine lays out nodes as a force diagram. The strength of the force is based on number of static links existing between nodes, and a negative force is applied to nodes with no static links. This causes nodes to form clusters in space where strong coupling exists. What is the value of analyzing the application like this? Here is a list of issues we needed to solve: It took a long time to build. This made iterating costly, both in time and morale. Oftentimes, the build failed (anecdotally, a fresh warm boot of LabVIEW helped) The IDE was painfully slow during development; the cursor continually was "waiting" during wiring operations. The way we solved both problem was simply by taking a pair of "scissors" and snipping links between nodes. The types of links that we snipped were these incidental links introduced by packaging and namespacing facilities in LabVIEW: removing LVLIBs altogether removing VIs from LLBs calling concrete instances of polymorphic VIs rather than the parent removing public type definitions and utility VIs from LVCLASSes Within a couple days, we went from "kick off a build and go grab lunch" to "kick it off and get a coffee". The application and application framework had not changed to see these improvements; just the logical and physical packaging of dependencies. (In addition to solving the main performance pain points, additional areas for architectural consideration are easily visualized; that's beyond the scope of this conversation) Without LVLIBs, how do I avoid name collisions? I prefer this filenaming convention: Project-Class-Method.vi or Application-Class-Resource-Action.vi ... or generally, LeastSpecificNamespace-...-SpecificThing-...-VerbActingOnASpecificThing.vi For instance, Deploy-UpdateService-CheckForUpdates.vi or FTW-JSON-Deserialize.xnode. The name of the owning class just drops the -Method postfix. Is it ideal? It's neither terrible nor great. Some benefits are that filenames sort nicely, and it's easy to spot anomalous linkages. Semantic naming makes it easier for development tools outside the IDE (SCC client and provider, build toolchains). One downside is that your hand is forced on naming Dynamic Dispatch methods in classes (again, I desire to see this coupling separated by a degree of indirection in future LabVIEW versions). Conclusion? This area of LabVIEW does not have a general solution or general best practice. Be aware of tradeoffs of different strategies, and ensure they map successfully to your application space, stakeholder's needs, and team's sanity. Standing offer: Send me a message if you feel some of the scaling pain points: busy cursor while wiring build times lasting longer than 10min mass compile times lasting longer than 10min LVProj takes longer than 1min to load and within 2hrs of screensharing I reckon we could substantially improve your LV dev experience. I'm interested to further build tribal knowledge and provide feedback to NI on taking LabVIEW applications and teams to scale.
-
I did. (That is, after years and N00's hours investigating LVLIBs in the context of namespacing/distribution/building/linking/encapsulation/scoping/reuse/load time/dependency management and so forth. James, I am not surprised if you independently draw the same conclusion, and I'm interested to hear if you conclude otherwise.)
-
Greetings, wireworkers! Join us this week -- Wednesday, 24 September 2014, 12:00noon CDT (17:00GMT) for Episode 045: The Next Chapter. Michael and I will host previous guests Brian Powell, Justin Goeres, and Christopher G. Relf. Continuing our ongoing VI Shots Live theme of careers in LabVIEW, the conversation this episode focuses on transitions and step changes in your own individual business of software. Tune in Live at vishots.com/live, and come prepared to Ask Us Anything in the live chat!
-
Desktop Execution Trace Toolkit private context INI keys
JackDunaway replied to JackDunaway's topic in LabVIEW General
Generally, this is not recommended (or even useful at all!) unless developing IDE mods and/or XNodes.
-
To enable private context tracing in Desktop Execution Trace Toolkit, in the file %LocalAppData%\National Instruments\Desktop Execution Trace Toolkit\DETT.ini place the following: [Preference] ShowPrivateContext="True" It's important to ensure DETT is closed down when you change the file; on exit, DETT flushes to file it's currently loaded settings. (Placing this info here with some searchable terms, to save my future self that infrequent 20-minute spelunking exercise of finding it again)
-
-
LAVA BBQ 2014 Registration and Call for Door Prizes
JackDunaway replied to JackDunaway's topic in NIWeek
Regular admission ticket sales ends in less than 48hrs. Purchase tickets for yourself and your colleagues using the mobile-friendly registration form at lavag.org/bbq-tickets Wishing you all safe travels to Austin! -
LAVA BBQ 2014 Registration and Call for Door Prizes
JackDunaway replied to JackDunaway's topic in NIWeek
For those of you who indicated during registration that you are interested in sponsoring a door prize, please fill out the door prize sponsor registration form (http://wirebird.co/lava-bbq-door-prize). Thank you! You also would have received an email minutes ago with this request; bumping this thread also to catch the attention of those who have posted here already. -
Greetings, wireworkers -- new VI Shots Live Episode airing soon! Join us this upcoming week -- Wednesday, 30 July 2014, 12:00noon CDT (17:00GMT) for VI Shots Live: Top Things to Do at NIWeek 2014 Michael and I are joined by special guests and long-time NIWeek-goers Becky Linton and Darren Nattinger. We'll share our personal recommendations for sessions and tips on getting the best experience possible at NIWeek. Viewers of the live show can ask questions and share your own tips using the chat window. Visit vishots.com/live to join live next Wednesday and also to watch recordings of previous shows. Indeed! Apologies on my transcription error, and thank you for the correction; it's now fixed in the original link.
-
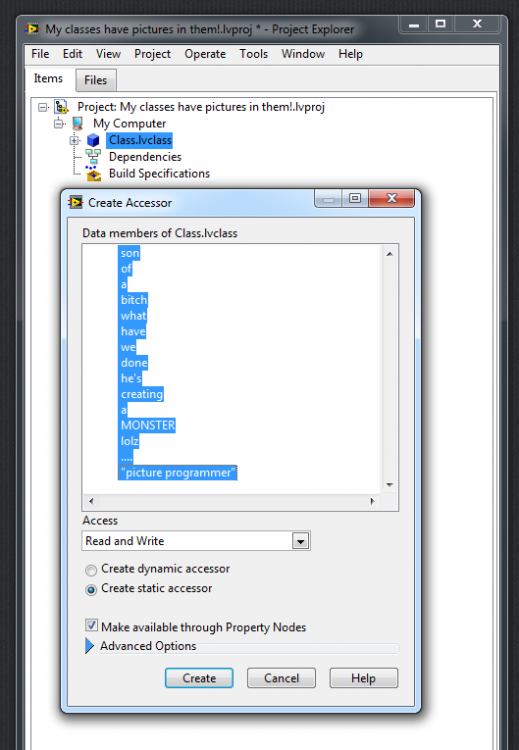
[Re: LVClass Property Nodes] Performance aside -- if we agree that our codebases are liabilities, not assets -- in what universe does 16kB file per accessor make sense?* A long time ago in a galaxy far away, I agreed spiritually with the decision behind the design to require explicit UDClass methods for accessors (quote: "These are major advantages of class data encapsulation, and we want to encourage people to design software that naturally has this advantage. By not supporting public or protected data, we eliminate a potentially confusing computer science concept from the language (at the very least, we cut out one more thing that needs explanation) and drive people toward a better architecture.") Four years ago, after a year of novice learning, I questioned the design in the form of a feature request. A year and a half ago, I confirmed that was not just a naïve opinion that should have fizzled with experience. Today: confident enough to call LVOOP Property Accessors an incorrect language feature, and substantially painful enough to warrant redesign. A correct, desirable solution facilitates and promotes painless, seamless, intelligent design of class member scope. The design below, currently implemented and shipping for years now, needs to be removed. It's a clunky method of spewing liability and naïvete all over yourself and your project: So, this weird-ass helpful-looking scripty-thing in the IDE is a "facility" to the uninitiated and eager, an "exsanguinator" to the initiated and burned, and it provides a UI affordance that pointedly enables and encourages the precise opposite of the decisions behind the design. To sum up, we LabVIEW users are given 1) a document that posits we Picture-Programming Mouth Breathers don't need and can't be trusted with sharp instruments, and 2) a sharp instrument only good for cutting ourselves and nothing else. Wut? The self-fulfilling prophecy of ignorant software design given poor language facilities is publicly frustrating to me. As a side-topic, I strongly desire opening the conversation about unifying the type system of LabVIEW, this being one topic of usability-versus-problems with accessors, and as a case study comparing accessor syntax of typedefs to the other walled-garden composite types. (To expand, it's worthwhile to unify by-ref built-in classes like FileIO/VIServer/VISA/DAQ; STL-like reference designs such as Queue/Event; type definitions; .NET objects; and then our only "officially supported" integration point for types, the neglected bastard UDClass). New keywords for classes that guarantee immutability would be cool, providing safe read-only access for object members (e.g., the ctor is the only setter allowed by the compiler). A sane ontological relationship, such as a Trait would be phenomenal (when, neither inheritance nor composition fit; which is, like, a lot. nailing the object model itself resolves some data access deficiencies at the root!). Let's pick up stone and throw it in any direction to pick a conversation about how to improve LVClasses, except in the direction of UDAccessors. Those categorically remain 16-thousand byte liabilities, and let's just put to bed the syntax burden ought to belong in language-land, not user-land. Yes, got sidetracked onto LVOOP generally rather than staying on the LVOOP Property Node topic, but for an important reason. I'm not riled up here because LVOOP Property Nodes ended up as a bad idea with an imperfect execution. Like, whatever, k? We can fix that, a bit inconvenient, but no prob, we can work together. The fundamental source of angst is that LVOOP is not appreciably better than when it first debuted nearly a decade ago. And maybe, in some existential and puny way, if we declare a cease and desist on LVOOP Property Accessors, LVOOP gets better? I dunno man. Seems tenuous. Let's close out here. Remember kids -- friends don't let friends use LVOOP Property Accessors. Next week's topic: namespacing and source file formats (generally, linker questions like "who relates to who, how?", which makes this accessor conversation look like polite chatter in the grocery line) * To you -- yes you, with the $/GB or €/TB figure on your Casio solar-power display -- you're handy at maths, help me with this. What are the opportunity and actual costs of maintaining one LVOOP Property Accessor? Does that scale linearly with multiple accessors? Multiple classes? Number of collaborators? How much time does it add to the build, type-propping and compiling, opening the LVProj, closing the LVProj, committing to SCC, diffing or merging on conflict, run-time performance (before it's loaded into memory, not after), debugging, when spanning across multiple targets, when spanning multiple release versions, when developing subclasses, when refactoring to add superclasses, when moving some data from sub- and some to super-classes, when explaining to your colleagues how "it must have been labview fault I just effed up the build" (punch line: you're right), when explaining that to your boss (who is sometimes the customer), when coming home late and explaining to your family (punch line: being right doesn't matter here; being good matters), when inheriting code from some trigger-happy accessor-scripting-chump, when you unknowingly run into one at least a few known vectors for insidious corruptions and bad behaviors with LVOOP property nodes? Cost certainly does not have "bytes" in the units, but certainly does have units of $$ and faith and morale. My experience, including many reboots of faith and second-third-fourth chances with LVOOP property nodes, is now converged to categorically default them as "too costly". You: "but..." Me: "Have at it; go crazy."
-
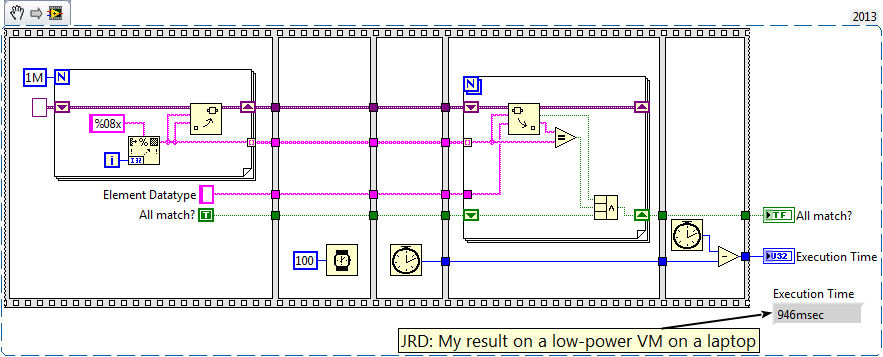
There's the red flag; that's a couple order magnitudes lower from gut instinct. I suspect one of two compiler optimizations due to the benchmark harness: 1) loop invariance that's applied on inlined but not detected for non-inlined VIs, or 2) dead code elimination, from not accessing the contents of the attribute I hear this as excellent news, that your the XNode is just as performant as a "regular" VI! To substantiate, here's a harness that shows 1,000,000 accesses in a loop that exhibits no potential loop invariance or dead code -- on my machine, it takes roughly ~900msec:
-
Turns out, typing that was neither the expensive part nor the bottleneck in being able to relay this information. Hope it helps :-]
-
Neil, I've found this procedure to fix this problem, and a host of other issues with source/object code asynchronization: Ensure you have no outstanding changes in your working copy; everything is committed to the repo Ensure for multi-developer teams you effectively have a mutex on the entire repo; you're likely about to make a widespread commit that touches lots of source. It's especially imporatant to have no outstanding changes on .lvclass, .ctl, .xctl, .lvlib, .xnode, or .lvproj files, because these cannot be readily diffed or merged in LabVIEW. (Perhaps a good time to do this is on the weekend, where all team members know to have changes committed before then.) Shut down LabVIEW completely Open all classes in XML Editor (on windows, Notepad++ is good, associating lvclass files as XML in the Style Configurator) Find the <Property> tag for "NI.LVClass.Geneology". Delete this entire tag. This removes any stale mutation history. **Careful here!** The entire tag is likely to span 9 lines. Be sure to delete them all. (I've not yet found or developed a reliable API for this operation; lemme know if one exists.) Find the <Property> tag for "NI.Lib.Version" -- reset this to the value 1.0.0.0 Open LabVIEW to the Getting Started Window; "Tools >> Advanced >> Clear Compiled Object Cache ..." then clear the cache for both User and App Builder Shut down LabVIEW completely Open the project and offending VIs to see if this fixes things. Maybe so, but you're not done yet. If you have not done this yet, ensure every single source file is marked as source-only (e.g., not a unifile). Right-click the root node of the project, "Properties" menu item, "Project" config page Ensure "Separate Compiled Code from new project items" is checked "Mark Existing Items..." button, select all items in the tree, then "Mark Selected Items". Wait for the operation to complete, then close this dialog. Open this dialog once more; visually scan the entire list, ensuring all statuses are "marked" Right click on the root node and "Find Missing Items". Resolve these bad linkages, probably by just deleting them from the project. If you have not done this yet, find all diagram disable structures in your project (this is simple if all VIs are in LVClasses -- since all VIs are in memory -- or with the legacy VI Tree hack). One way or another, ensure all VIs are in memory, find all disable structures, and analyze the disabled cases for links to missing VIs. Do that again for Conditional Disable Structures. Mass compile the project (from right click context menu from root node of project tree) Might as well take the opportunity to fix all the errors that are returned by the mass compile. If you have insanities, search the phrase "labview heap peek insane" for instructions how to fix these. If you can't get the keyboard commands for heap peek to work (e.g., if you're developing in a VM), there exists an undocumented VI Server App method to toggle heap peek visibility. Shut down LabVIEW completely Goto Step 7; rinse and repeat until zero errors are returned Ensure the application still runs from source; e.g., you've not accidentally broken something. If this smoke test passes, commit all changes to your local repo. This is your first checkpoint. Goto Step 7, and follow all steps again back to here. If some source files have been modified (e.g., there exist modifications in your working copy), this means will probably benefit from cross-link and circular-link tips below. Especially, if during the mass compile, you see the dialog repeating what appears to be the exact same operation over, and over, and over, and over, and over, and over, and over, and over ... Try implementing the tips below. Goto Step 7 Goto Step 3, and follow all steps again back to here. You should be able to complete this entire process with zero modifications to the codebase. Commit changes to local repo. Goto Step 3, and follow all steps again back to here. If you're happy, push to central repository. Have all developers/contributors clear their compile object caches. No really; witness that operation. It's vital. Have all developers pull the project. Ensure no corruptions exist; ensure the project can be opened and closed immediately with no "dirty dots". If these dots exist, your environments are somehow different (different versions of LabVIEW?), and should probably be resolved. I've tried to codify this procedure accurately above, but drop a line if it doesn't work or correct it with a response to this thread. Tips for the future to avoid these problems (from extensive at-scale experience with LVOOP spanning LV2009-2013SP1f2+): Refactor to avoid all typedef'd clusters in Class Private Data definitions. If they must exist, ensure that if they ever recompile, all LVClasses linking to the type are also saved to disk, especially if it's just one of those 'recompiles' that we've conditioned ourselves to ignoreOne overlooked place that typedef'd clusters can hide is as sub-types to some native labview objects, such as Queues, Events, etc... Avoid type defining primitive types such as strings/numerics/bools (You:"but..." me: "I know, me too. But it is what it is.") If you are using reference types (e.g., .NET) as elements in your class private data, you may run into unique issues that require other resolutions. One resolution is storing the reference as a flattened type, then creating accessors that cast to/fro the desired type. (Avoid even having elements in your class private data. Statelessness and immutability are desirable anyway for a functional style and synchronous dataflow.) When refactoring and changing the scope of types, ensure that both owning library files (lvclass, lvlib, xnode, xctl) are saved to disk. Else, corruption, sometimes tough to detect immediately, and may not even show up until build-time. Usage of LVOOP property nodes voids the warranty of LabVIEW altogether for applications of non-trivial scale. Don't use them in any version up to the time of writing, 2013SP1f2+ (You:"but..." me: "Good luck with that") Avoid circular linkages between classes. It's not uncommon for the type-propper to give up recursing if too many circular linkages exist, sometimes ending in a "VI failed to compile" error.To analyze these linkages, open classes one-by-one in an empty project. Inspect the "Dependencies". Click on classes/libraries and say "Why is this item in Dependencies?" to highlight the static link. Though, on codebases that have hidden corruption, this feature crashes LabVIEW -- instead, "Find Callers", which is slightly less convenient because it may highlight other Dependencies. To fix the dependency vector, refactor. Strictly avoid nesting of lvclasses within lvlibs; consider avoiding lvlibs altogether. The problems they can cause (edit/build/load/run-time performance, accidental corruption) are typically not worth the benefits (scoping/namespacing, common icon, LVProj loading members for API convenience...) (This is one key offender for the "endless" loops while mass compiling, and can drastically degrade edit/build/load/run-time performance.) Avoid polymorphic VIs; these "convenience" wrappers are just overloaded functions that carry static linkages to stuff you don't need to be linked to. (This is one key offender for the "endless" loops while mass compiling.) XNodes are a better alternative, but quite tricky to develop. The moment you or a developer colleague says to the other "i'm not seeing that in my environment", clear both your compiled object caches and re-start whatever you were first talking about. (Mass compiling is not sufficient, since the cache is not always invalidated when it should be, but this has gotten steadily better from 2009-2013) To sum up; avoid static linkages, and ensure dependency vectors between all code modules are unidirectional and don't form cycles. For multi-developer teams and/or codebases of non-trivial size; may the force be with you. And may you have an experienced colleague or consultant periodically auditing and transparently fixing the codebase to keep all productive and healthy and happy. Open offer: if you've ended up on this thread at your wit's end, send me a message and let's screenshare and fix it.
- 17 replies
-
- 10
-

-
LAVA BBQ 2014 Registration and Call for Door Prizes
JackDunaway replied to JackDunaway's topic in NIWeek
Early-Bird pricing ends today -- register at: http://lavag.org/bbq-tickets And, hearty thanks to our door prize sponsors so far. -
RT @sustrik: Most of the complexity in code is direct consequence of not acknowledging the complexity of the problem being solved.
-
LAVA BBQ 2014 Registration and Call for Door Prizes
JackDunaway replied to JackDunaway's topic in NIWeek
Bumping this topic as a reminder -- Early-Bird pricing ends tomorrow -
Can Event Structures Handle Big-Data Display Updates?
JackDunaway replied to AlexA's topic in User Interface
Briefly, the LabVIEW Event API is incredibly performant, and even provides optimizations for sharing references to published events for multiple subscribers. This Github repo shows 13 separate demonstrations and benchmarks of the Events API. Performance is relative, but my instinct is that your throughput described above is well-within the LabVIEW Events capabilities as a transport mechanism. If your application never needs to scale beyond a single LabVIEW application instance/context, the Events API will work well for all but the most extreme performance requirements; else, consider ØMQ or nanomsg or similar for more features and interoperability. -
Join us this week -- Wednesday, 24 June 2014, 12:00noon CDT (17:00GMT) for Episode 006: XNodes (Part 1). Michael and I are excited to host Gavin Burnell and Jonathan Kokott who have both used XNodes to redefine what �reusable code� means in LabVIEW. Even though the creation of XNodes is not officially supported, they power some important shipping abilities such as Timed Loops and the Error Ring Node, and we'll dive into benefits and caveats of using and creating XNodes. This will be our first show with technical screensharing demos! As a viewer, come prepared with questions, and we look forward to having you join this month at vishots.com/live.
-
Greetings Friends of LAVA, colleagues, cohorts, and Wireworkers Extraordinaire -- it's LAVA BBQ time! click here >> LAVA BBQ 2014 Event Page: Register and purchase tickets today Date: Tuesday, 05 August 2014 Time: 7:00-10:00pm CDT (after the NIWeek Block Diagram Party) Timestamp for your ISO-8601-compliant robots: {"BBQBeginTimestamp":"2014-08-06T00:00:00.000Z"} (API note: we have switched from XML to JSON since last year) Location: Scholz Garten, 1607 San Jacinto Blvd, Austin, TX 78701 (1 mile from Convention Center) Meal Options: standard meal is your choice of brisket, ribs, or chicken, with sides of beans, cole slaw, and potato salad. A vegetarian option is available to select during registration on the event page. Cash bar. Cost: $30 Early Bird (until July 11th) $35 Regular Admission (Until Aug 4th) $40 At the door Who: Everyone is welcome, including spouses traveling to Austin with you. Even if it�s your first time, expect to recognize many faces/names from the forums and NI R&D What to wear: Informal attire, but come as you are. (We'll see everything from suits to flip-flops, though consider changing at the hotel to clothes suited for the 1mile 95�F 7pm walk or bike ride.) Reimbursements/Expensing: If you need a receipt to turn in to your employer, request a receipt by sending a private message to Hooovahh. We are using a new system and may have difficulty getting receipts so please be patient. If you plan to sponsor a Door Prize, specify this during registration on the event page, and also optionally reply to this thread to announce the door prize. Example door prize announcements from last year: "Be creative! By donating a prize you and your company will receive free advertising in this thread and bragging rights on the night, so what are you waiting for? Check out the cool prizes below (knowing there will be more added to this thread as NIWeek approaches), and try to top them. If you would like to donate (please do, we really appreciate the LAVA-love) feel free to add a prize below with the details." We'll touch base with you later to collect "blurbs" to be read aloud. Hope to see you there! Chime in on this thread (and the comments section of the Event Page) once you buy tickets to let everyone know you're coming. LAVA BBQ 2012 in the Scholz Garten Biergarten (Photo by Norm Kirchner)
-
[Re: 2014 tickets] stay tuned for an announcement next week for ticket sales
-
Are you using URI filenames? Try that, with the most conservative flagset of SQLITE_OPEN_URI | SQLITE_OPEN_FULLMUTEX | SQLITE_OPEN_PRIVATECACHE and also the most permissive permissions SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE then deprivileging with the "mode" parameter on the URI. You'll also need to call sqlite3_open_v2 rather than sqlite3_open My hunch is that these settings could be sufficient without recompiling SQLite.