jdunham
-
Posts
625 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by jdunham
-
I don't know anything factual about the internals of labview, which is lucky for you, because if I did, I wouldn't be allowed to post this. So anyway, it's highly likely that the LV compiler generates executable clumps of code, and that each execution thread in labview is some array or FIFO queue of these clumps. The execution engine probably does a round-robin sequencing of each thread queue and executes the next clump in line. So when a clump contains a Dequeue Element function, and the data queue is empty, this clump's thread is flagged for a wait or more likely removed from some master list of active threads. Then some identifier for that thread or that clump is put in the data queue's control data structure (whatever private data LV uses to manage a queue). That part is surely true since Get Queue Status will tell you the number of "pending remove" instances which are waiting. In the meantime, that thread is removed from the list of threads allowed to execute and the engine goes off and keeps working on the other threads which are unblocked. There's no need to poll that blocked thread, because it's easier to just keep a list of unblocked threads and work on those. When data is finally enqueued, the queue manager takes the list of blocked threads and clears their flag or adds them back to the list of threads allowed to execute. No interrupts, no polling. Of course if all threads are blocked, the processor has to waste electricity somehow, so it might do some NOOP instructions (forgetting about all the other OS shenanigans going on), but you can't really call that polling the queue's thread. It's really cool that the implementation of a dataflow language can be done without a lot of polling. For the system clock/timer, that's surely a hardware interrupt, so that's code executed whenever some motherboard trace sees a rising edge, and the OS passes that to LV and then something very similar to the above happens. So that's not really polled either. OK, I had to answer this out of order, since it follows from the previous fiction I wrote above. Between each clump of code in a thread, there should be a data clump/cluster/list that contains the output wire-data from one clump to be used as the input wire-data of the next one. That's the low-level embodiment of the wire, and whether any C++ pointers were harmed in the making of it is not relevant. Now if the code clump starts off with a Dequeue function, it gets that data not from the dataflow data clump, but rather from the queue's control data structure off in the heap somewhere. It's from a global memory store, and anyone with that queue refnum can see a copy of it, rather than from the dataflow, which is private to the adjacent code clumps in the thread. Well anyway, they do undoubtedly use some pointers here so that memory doesn't have to be copied from data clump to data clump. But those pointers are still private to that thread and point to memory that is not visible to any clump that doesn't have a simple dataflow connection. I think your mental model of how the internals might work is actually getting in the way here. Yes Virginia, there *is* a wire construct in the execution environment. I grant that my mental model could be wrong too (AQ is probably ROTFLHAO at this point), but hopefully you can see why I think real dataflow is as simple as it looks on a diagram. Well we're not getting any closer on this. I still think that other stuff is not pure dataflow, and 'dataflow' is a very useful word. If you say that every iota of LabVIEW is dataflow, then the only place that word is useful is in the marketing literature, and I'm not willing to cede it to them. Maybe the key is adding a modifier, like 'pure', 'simple', or 'explicit' dataflow. Hey I'm learning too, and by the way I really want to try out the Lapdog stuff. I may come back to you for help on that.
-
Well it still seems sort of academic. The examples you show don't seem suitable for compiler optimization into "simple dataflow" constructions. In most non-trivial implementations you might end up with one of the queue functions in a subvi. Whether or not your queue is named, once you let that refnum touch a control or indicator, you are not deterministic. It's not that hard to write a dynamic VI which could use VI Server calls to scrape that refnum and start calling more queue functions against it. I know you're just trying to find an example, but that one doesn't go too far. I didn't quite get this The subvis will release their references to the queue, but they will still enqueue their elements first, and it will be as deterministic as any of your other examples. The queue refnums may be different, but they all point to the same queue, which will continue to exist until all references to it are destroyed or are automatically released when their callers go out of scope. Well, yes it's kind of murky, but the time functions are basically I/O ('I' in this case). They return the current state of an external quantity, injecting it into the dataflow. All I/O calls represent a local boundary of the dataflow world. In contrast, the queue functions (and globals, locals, etc.) transfer data from one labview dataflow wire to a totally unconnected labview dataflow wire. So I think that supports my saying that these break dataflow, while the timing functions don't. BTW, I don't believe the queues poll. I'm pretty sure AQ has said those threads "go to sleep" and it only took me a minute or two to figure out how to implement the wakeup without any polling. The NI guys are way smarter than me, so they probably figured it out too. Except when I call the strict by-value/deterministic stuff "pure dataflow" to my co-workers, they immediately understand what I am talking about, whereas I would constantly get quizzical looks if I switched over to saying "by-value construction" (even though they understand those words). Anyway, I'm fine with using your definitions within the scope of this thread, assuming I bore you all yet again with any more replies. Oh gosh, I found that disturbing. I think it was a mistake on NI's part to allow this in the language syntax.
-
CAR PLATE NUMBERING LOGGING AT CHECKPOINTS
jdunham replied to hookes2's topic in Machine Vision and Imaging
In your position, I think you should buy an off-the-shelf solution. Why do you expect us to do this work for you when you can just purchase such a system? http://www.eaglevision1.com/license-plate-recognition.htm Of course if this is educational, you're going to have to do the majority of the work yourself and show the work you've done so far before asking specific questions about how to reach the next step. Good luck! -
Well I just posted, and I feel like I didn't adequately answer your real question, so I'll try again. I would say that the Dequeue Element node is a special node that fires not when its input data is valid, but rather when an event occurs, like data is enqueued somewhere, or the queue is destroyed. So sure, technically it fires right away, and its function is to wait for the event, so it "starts executing" on the valid inputs but then it sits around doing nothing until some non-dataflow-linked part of your code drops an element into the queue. So that node (Dequeue Element) is executed under dataflow rules, like all LabVIEW nodes are, but what goes on inside that node is a non-dataflow operation, at least the way I see it. It's "event-driven" rather than "dataflow-driven" inside the node. Similarly a refnum is a piece of data that can and should be handled with dataflow, but the fact that a refnum points to some other object is a non-dataflow component of the LabVIEW language (we're not still calling it 'G', are we?).
-
Well I'm not going to google around for formal definitions of dataflow, but to me dataflow means that the order of operations is solely determined by the availability of input data. Of course most mainstream languages set operation order based on the position of the instruction in the source code text file, with the ability to jump into subroutines and then return, so that's the cool thing, dataflow is totally different than normal programming languages. (I know you knew that already) The basic syntax of LabVIEW is that data flows down a wire between nodes. I'm calling that "pure dataflow". Any time data goes from one node to another without a wire (via queue, notifier, global, local, shared variable, writing to disk then reading back, RT FIFO, DVR, etc) then you are not using pure dataflow. All those things are possible and acceptable in LabVIEW because it turns out that it's just too hard to create useful software with just pure dataflow LabVIEW syntax. One thing I do take as a LabVIEW axiom is "Always prefer a pure dataflow construction". In other words, don't use queues, globals, and all that unless there is no reasonable way to do it with just wires. Well anyway, that's what I meant. If you call your diagram "pure dataflow" then you don't have to agree with anything else I said. Of course your diagram is perfectly valid LabVIEW, because LabVIEW is not a pure dataflow language. It's a dataflow language with a bunch of non-dataflow features added to make it useful. You could say the data is "flowing through" the queue but for me the dataflow concept starts to lose its meaning if you bandy the term around like that. So my definition of pure dataflow is different from Steve's in the original post, but it's a definition that is more useful for me in my daily work of creating LV diagrams. Sorry for the confusion. Jason
-
LabVIEW Development System Has Stopped Working
jdunham replied to BobHamburger's topic in LabVIEW General
One option is MSDN Operating Systems, it's what I have, though it sounds like I could be leveraging it more. A $699 subscription gets you 10 license keys for testing for most OSes, and I think you can request more if you need it. It's meant for testing, not for sharing with friends, but that's exactly what you are doing. In addition, Microsoft has knowledgeable salespeople you can call on the phone (or with chat online). I think there are thousands of people who are doing the same thing with virtualization so they should be able to point you in the right direction. However you may get better results if you don't actually call them Nazis when you discuss your situation with them. -
I agree you could make LabVIEW "more dataflow" by changing the semantics of the language; that is, by changing the rule that a node with multiple outputs releases them all at the same time. However, i don't see it as being useful. So many of the advanced programming techniques like the queued message handler, notifiers, the event structure, and even the lowly global variable are useful in LabVIEW because they violate dataflow. If you could do it all with dataflow, you wouldn't have to fiddle with those advanced techniques. The dataflow paradigm is really great for LabVIEW, but in its pure state it doesn't really get the job done. I don't think any more purity would help.
-
Please vote for conditional array indexing! http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Conditional-auto-indexing/idi-p/918682 http://forums.ni.com/t5/LabVIEW-Idea-Exchange/quot-Conditional-Append-quot-at-array-indexing-tunnel/idc-p/1116902 see also http://lavag.org/topic/7574-conditional-append/page__p__44719entry44719 There is an OpenG function which does this, a native polymorphic version would be so much better. A lot of times I have an array of clusters, and I want to filter the array by testing the value of one of the elements. This feature would really help clean up the code. Jason
-
I find it hard to believe that anyone claims never to overwrite errors. I'm not sure how you detect the presence or absence of a file without trying to open it, getting error 7 and then filtering it. I suppose you could list the containing folder, but that seems a lot harder. There's nothing wrong with the former method of generating an error and then clearing it. In addition there are plenty of routines that can throw a User Cancel error as a normal part of user interaction. So maybe the clarification is that you should never overwrite an unexpected error. We have a Filter Error function that is useful. I've never figured out why this hasn't been added to vi.lib. The clear errors function clears all errors, but you should only be clearing expected ones! As far as generating errors, we have one that dumps the calling path into the error source, which I'm sure is pretty common. What it also does is that you can wire anything into it, and it uses the OpenG Lvdata tools to serialize the arbitrary data to a string, and then you can get a data dump in the error message.
-
I still use TeraTerm, which is ancient but works just fine. http://en.sourceforge.jp/projects/ttssh2/ Jason
-
Best Practices in LabVIEW
jdunham replied to John Lokanis's topic in Application Design & Architecture
Thought of that too! Oh sure, that's what they all say... Anyway, as long as you understand the potential for quagmire, you are slightly better prepared to avoid it. Good luck! Jason -
Why does it take so long for LV to respond after dropping a VI?
jdunham replied to george seifert's topic in LabVIEW General
I have noticed that if I do a Find operation in the LabVIEW Project, and the project is large, then any change makes LabVIEW unresponsive for 30-120 seconds, and the Z-order of the open windows is shuffled around. This does not include "Find and Replace" (ctrl-F in a VI) or "Find All Instances (right-clicking on an icon) but does include "Find in Project" (Crtl-F in an open project) or "This VI in Project" (Ctrl-shift-E) in a VI. If I close LV and reopen it, the problem goes away until I use the Find function again (which I have learned not to do). It does not always happen, but if many windows are open, it is more likely to occur. I don't have a CAR # for this, because I can't always reproduce it. Bruce, does this match anything you experienced? -
There are some ideas at http://lavag.org/topic/13706-text-labels-on-x-axis-of-plot/ There are some ideas at http://lavag.org/topic/13706-text-labels-on-x-axis-of-plot/
-
In their infinite wisdom, Microsoft have determined that file extensions are too hard for you, so the default is to hide them and show you an icon instead. This is one of the first things I turn off on a new machine. In Windows Explorer menu (press "Alt" if no menu is showing, another dubious UI improvement), choose Tools -> Folder Options -> View -> Advanced Settings and uncheck "Hide extensions for known file types". Since the extension is really part of the file name, I don't understand where the obsession with hiding it comes from, but things will make more sense after you turn off that option.
-
Yeah, there's lots of suck to go around. One tip. If you when your open WinZip use "Run as Administrator" (it's in the right-click menus) and then you will be able to write into restricted folders such as \Program Files. Don't run 64-bit LabVIEW if you want to build EXEs which can be run on normal (32-bit) Windows.
-
Well that does look like a pretty sweet device. However, you're going to need three of them and a USB hub, so that's about $200, and you could have bought an NI 6601 ($400) , a $60 ribbon cable, and a cheap connector block from http://www.daqstuff.com/68_pin_daq.htm and be off to the races. That's a little more money, but you wouldn't have to write your own labview drivers for the device. Of course you'd still have to wire up your own differential level shifter chip, so you may have done the right thing after all. The NI should have much higher data rates but that may not be important for your project. Anyway, good luck with it.
-
Compelling introductory examples of OO LabVIEW?
jdunham replied to Stuart's topic in Object-Oriented Programming
Hi Stuart: One use for a plugin/OOP architecture is debugging/logging. I have a VI that I sprinkle around in my code that logs messages and errors to a text file. I think a lot of programmers have something like that, and I think your students can understand the value. So if you make it object oriented, it's much easier to change the way it behaves, like I have a version that emails me when there is an error. You could also use it to post status messages to a web page, or put up certain error codes in dialog boxes. But all the code that calls this logging VI has no need to know how it works. If I distribute the code, I just have to distribute the base class, and the user can ignore it or write their own descendants of the class to meet their own needs. For this implementation, I keep the object in a global, so that I don't have to pass the lvclass wire through all though hundreds of routines that call it. Jason -
that's double-clicking to be precise. That will also pan the block diagram s othat the terminal is on-screen rather than off to the side. You can exploit that by resizing the diagram window to a couple of centimeters on each side. Then when you double-click on the control, it will "zoom" right to the terminal location. Then you can restore the window size and see where the heck you are. If you see the marching ants, but the terminal is invisible, it may be behind the edge of a loop or structure. Those act like real-world glass windows where you can see stuff in the field of view, but other stuff in that universe which may be tucked off to the side is not visible until you move it into the "glass" part of whatever structure you are looking "through". Of course you probably have lots of structures within structures, which will add confusion but you should be able to work it out. Jason
-
So wait, why aren't you using an NI Counter/Timer card? They are awesome at this. Each encoder should be able to use one of the counters, and the other quadrature channel typically goes into the digital I/O port. Your local NI sales can usually do a much better job than I can of walking you through the nitty gritty of picking the right card and connectors. You may need a 422-TTL level shifter IC. You can either get one for $1.50 from digikey or if you are allergic to chips, you can get one packaged in a $45 device from B&B electronics, and get another $20 of connectors to make it work with your breakout box.
-
Consequences of unreliable run method
jdunham replied to Mads's topic in Application Design & Architecture
I don't know the details of your application, but is it necessary to run all your code together in the same application? Sure it would be nice if LabVIEW were re-architected to make this all work, but it shouldn't be necessary. You can run a separate instance of LabVIEW (copy the EXE to LabVIEW2.exe) and run your servers there, or just build them into a separate application. In the real world, your client/server should running as a service. We use FireDaemon to accomplish this for our client/server system which can accept an unlimited number of connections. Services generally don't provide a user interface directly, so it's not unreasonable for NI not to have planned for this. You have a manager or client app which uses files or a database or TCP/IP on the localhost to pass events and data to the server. In general this should make your application more robust. Edit: OK, I just read your posts over on the dark side. You already know all the stuff I wrote, and AQ told you that this is not going to change anytime soon. Why are we having this discussion? -
Error -603 is thrown when some LabVIEW code looks in the Windows Registry for a key and doesn't find it. Sounds like maybe the key names changed between versions. Hopefully you can look for registry access items within the LabIVEW source code and use regedit.exe to browse the registry and see whether the you can find the key it's looking for. Good luck.
-
Re-use and hierarchy strategy
jdunham replied to InsaneObject's topic in Application Design & Architecture
Whoops, I screwed that up as well! Right, but you should at least consider using the packager to distribute your own tools between your projects, or be ready to come up with an equivalent workflow. It's OK, I'm just being snarky. Have fun! -
Re-use and hierarchy strategy
jdunham replied to InsaneObject's topic in Application Design & Architecture
Well I think you've figured out that you want to keep your library code in a separate folder and keep it under managed development with the help of a source code control system. I use Subversion, but I don't think the choice of system matters all that much. Where the real problem arises is making sure that improvements to your library don't break your old projects. Even if you think it won't happen, it certainly will, and Murphy's law dictates that it will happen in some dangerous or at least embarrassing way. So what is important is a workflow where you link your active projects to your main library "trunk" code, and then when your projects are feature-complete and headed into a predominantly testing phase, you freeze a version the library code used in that project into its own branch. Then if you do find a problem in the frozen branch and you fix it there, you have to remember to merge it back to the trunk and any other project which might be vulnerable, and don't forget that merging really sucks in any language and is truly awful with LabVIEW. Or else you have to have the self-control to fix it in the library and push new versions of just those libraries you fixed into the otherwise frozen code. If you don't have granularity in your library versioning, then you're back into the risk of fixing one thing and breaking two more. Of course as you push a fix into your frozen code, you should check the check-in logs and make sure you understand all the other changes you've made to the library's trunk and decide whether the other changes are putting your code at risk. Obviously the amount of effort you put into all of this is dependent on the risk tolerance of your project, but you are better off enforcing good discipline in your workflow before you start programming the reactor core control rods than after. If you're unlucky enough to be a freelance consultant, you'll probably end up having active projects stuck in different versions of LabVIEW, which will just make the problem worse. Either you stick with developing library code in the oldest extant version (which is a bummer) or else you get even more careful about handling your changes. So I think VIPM (google it!) is supposed to help quite a bit with this, and I'm sure the JKI guys will pipe up with more insight. Sheepishly I admit that I don't yet use it for my own reusable code. However I would say that using any tool is not as important as understanding the basic problems around versions and reliability and backwards compatibility and unintended consequences. The point is acknowledging that copies of your library code will proliferate and managing that, rather than pretending it won't happen because you're such an awesome coder and your designs come out so well the first time. Jason -
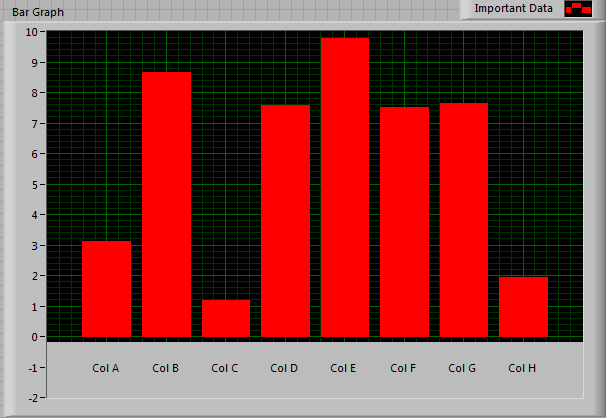
You could also use graph cursors or annotations, and position them just under your bars. That would look decent enough if you set the Yscale min to -1 rather than zero, and then you could put the labels at Y = 0.5 or something. You'd fill the bars down to zero rather than down to -infinity. You would have a few compromises with the appearance, but the zooming &c.would all work. Bar Graph With X Labels.vi

-
Compatible with LabVIEW support requirements for free products
jdunham replied to rdr's topic in LAVA Lounge
What if the metric were the actual percent of requests handled within 2 days or some similar metric? I bet LAVA would score well without anyone having to give a future commitment on support, which is not really feasible with open software.