drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
Here is a demo button based on Silver buttons (instead of system buttons). No hover effects, but one can colour ON and OFF state differently, which you can't with system buttons. Flatline Non-hover button.vi
-
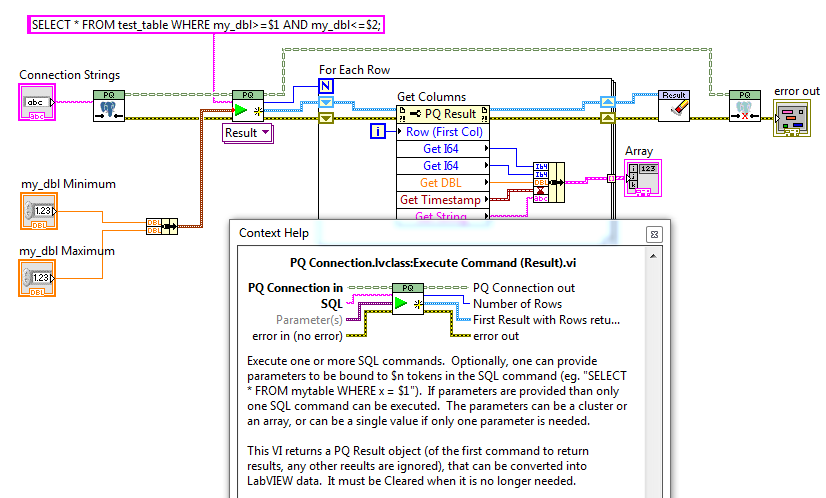
 Oh, that enumeration. Not sure that would be on the list as only one thing can be written to a file at one time, even by TDMS. SQLite is by default ACID compliant (now that would be on the list), but one can turn that off to get asynchronous disk writes, just like TDMS. And as long as you writes are faster than your busy-handler timeout (I set that at 5 seconds, adjustable) then there are no Busy(5) errors. The issue is just write speed, where TDMS wins.
Oh, that enumeration. Not sure that would be on the list as only one thing can be written to a file at one time, even by TDMS. SQLite is by default ACID compliant (now that would be on the list), but one can turn that off to get asynchronous disk writes, just like TDMS. And as long as you writes are faster than your busy-handler timeout (I set that at 5 seconds, adjustable) then there are no Busy(5) errors. The issue is just write speed, where TDMS wins. -
Sorry, what “enumeration”?
-
No, seems to work fine without that, as long as one reading, not writing.
-
Actually, at least up to the 2GB files I’ve tested, the SQLite file gets held in memory by Windows File Cache, so refreshing is fast (though the initial read will be slower with an HDD than an SSD, as will be writing).
-
TDMS is much more specialised than the more general-purpose SQLite. If your use case is well within what it is designed for (and it sounds like it is) then it is likely the better choice.
-
Open Source SW and mailicious intent
drjdpowell replied to Matthew Rowley's topic in OpenG General Discussions
You didn't make them from scratch; you used available components (such as lawnmowers, brakes, engines, etc.) all of which you accepted as not being sabotaged by someone who wanted to kill you. An MOT is a non-onerous test, involving a reasonable set of requirements, so that sounds like a good idea. It would be a LOT of work to pass an MOT without using components manufactured by other people. -
Open Source SW and mailicious intent
drjdpowell replied to Matthew Rowley's topic in OpenG General Discussions
Nobody makes their own car because no-one is trying to sabotage their car, and driving a car built by yourself is extremely dangerous. If you think someone might try to kill you, then you still don’t build your own car. Instead, you verify that no-one has tampered with your car. I was just wondering how that kind of analysis goes with software, and whether management, in it’s insistence on no open source or onerous verification requirements, is actually making the correct choice as far as minimizing risk. -
Open Source SW and mailicious intent
drjdpowell replied to Matthew Rowley's topic in OpenG General Discussions
But which is the bigger risk of this example: A) Someone will sell me a car that has been modified to crash and kill me. B) The car that I build from scratch will crash and kill me. Mitigating (A) by accepting (B) is not necessarily reducing your chance of death. -
Open Source SW and mailicious intent
drjdpowell replied to Matthew Rowley's topic in OpenG General Discussions
I’m not sure intuition is that reliable in such high-importance-but-low-likelyhood things. People die from mundane things like tripping over. -
Open Source SW and mailicious intent
drjdpowell replied to Matthew Rowley's topic in OpenG General Discussions
I wonder how large the risk of malicious code is relative to the risk of serious bugs in code implemented from scratch. -
database What Database Toolkit do you use?
drjdpowell replied to drjdpowell's topic in Database and File IO
Anybody using Postgres who would like to beta test my libpq-based library? It’s similar to my SQLite access library.
-
Search & replace string character without loops
drjdpowell replied to Ano Ano's topic in LabVIEW General
You’re running out of memory because you are copying the giant string somewhere. If you never alter the string, but instead work along it using the “offset” inputs on the string functions, then you can use all the loops you like. -
Oh that IS a use case. Though lookup is much slower than with a Variant-Attribute-based object, it is much faster than doing the initial conversion to that object, so one is well ahead overall if one only needs to do a few lookups.
-
Here's an alpha version to look at, with one example, just to show the API: jdp_science_jsontext-0.1.0.4.vip This is VERY untested.
-
Be careful if you use the NI function to get your binary data back, as it has bug in that will truncate the string at the first zero, even though that zero is properly escaped as \u0000. Png files might or might not have zeros in them, but other binary things do (flattened LVOOP objects, for example).
-
I have only used it that way a bit. And that was basically for recording attributes of a dataset as it passed through a chain of analysis. I was only adding things at a few places before the result got saved to disk/database. The new JSONtext library has Insert functions to add/change values. These are slower than the old library, but not so much as to make up for the expensive conversion to/from LVOOP objects, unless one is doing hundreds of inserts. If someone is using LAVA-JSON objects in such a way, I would like to know about it.
-
I've had a client hand me a 4GB JSON array, so I'm OK for large test cases.
-
Only 125MB/sec, but I was testing calling 'SELECT json_extract($json,$path)' which has the extra overhead of getting the JSON string in and out of the db. I wish I could match 300MB/sec in LabVIEW.
-
I prototyped using an in-memory SQLite DB to do JSON operations, but I can get comparable speed by direct parsing. But using JSON support in a Database is a great option.
-
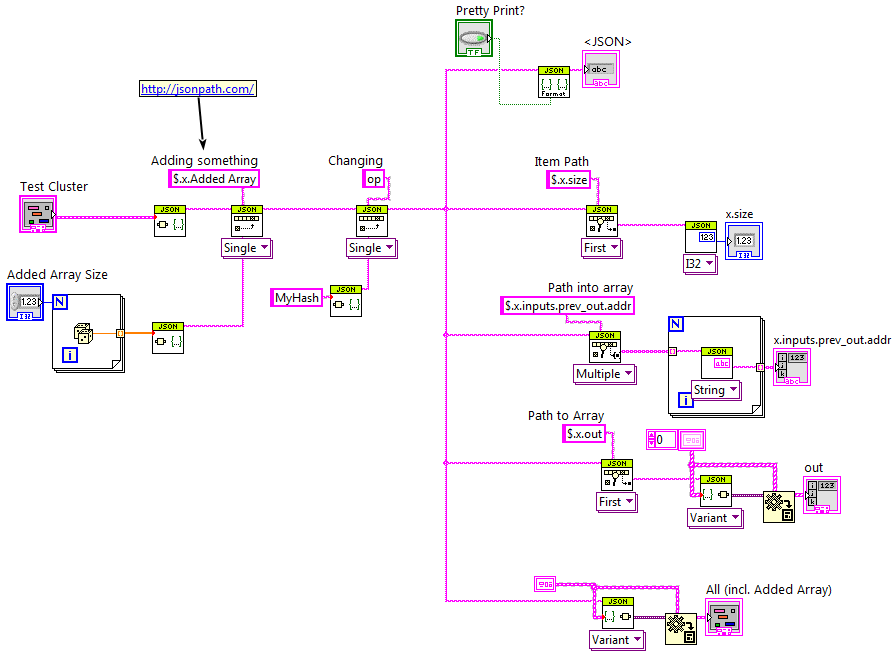
Some performance numbers: I took the "Message on new transaction" JSON from the blockchain.info link that Shaun gave, created a cluster for it, and compared the latest LAVA-JSON-1.4.1**, inbuilt NI-JSON, and my new JSONtext stuff for converting JSON to a cluster. LAVA-JSON: 7.4 ms NI-JSON: 0.08 ms JSONtext: 0.6 ms Then I added a large array of 10,000 numbers to bulk the array out by 50kB. If I add the array to the Cluster I get these numbers: LAVA-JSON: 220 ms NI-JSON: 5.6 ms JSONtext: 9.0 ms (I pass the large array to NI-JSON internally, which is why I'm closer) If I don't add the array to the cluster (say, I'm only interested in the metadata of a measurement): LAVA-JSON: 135 ms NI-JSON: 5.2 ms JSONtext: 1.1 ms The NI tools appear to vet everything very carefully, even unused elements, while I do the minimal checking needed to parse past the large array (in fact, if I find all cluster elements before reaching the array, I just stop, meaning the time to convert is 0.6 ms, as if the array wasn't there). **Note: earlier LAVA-JSON versions would be notably worse, especially for the large case.
-
I’d add: - Work on a stream (i.e. allow the JSON Value to be followed by something else, like the regular Flatten functions have a “Rest of String” output). - Give useful error messages that include where in the very long JSON text the parser had an issue. - Work with “sub”JSON. Meaning, “I know there is an “Options” item, but it can come in multiple forms, so just return me that item as JSON so I can do more work on it (or pass it on to an application subcomponent that does know what the form is). The library I’m working on, JSONtext, is trying to be sort of an extension to the inbuilt JSON primitives that adds all these features.
-
One of the performance advantages of working directly with JSON strings is that, when converting JSON to/from a Variant, one can use the NI primitives to handle large numeric arrays, without ever letting it see (and throw a fit over) the entire string. In fact, I can often pull out selected elements of a large JSON text faster than using the NI primitive’s “path” input (I think because the primitive insists on parsing the entire string for errors, while I don’t).
-
I’m working on a new JSON library that I hope will be much faster for my use cases. It skips any intermediate representation (like the LVOOP objects in the LAVA JSON API, or the Variants in some other JSON toolkits) and works directly on JSON text strings. I’d like to avoid making a tool just for myself, so I’d like to know what other people are using JSON for. Is anyone using JSON for large(ish) data? Application Config files? Communication with remote non-LabVIEW programs? Databases?
-
XControls don’t automatically save display properties of their contained controls; one has to explicitly save/load in special methods of the XControl. A big pain, given the large number of properties.