drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-

Code-Development collaboration through Bitbucket (GIT and Mercurial)
drjdpowell replied to Ton Plomp's topic in LAVA Lounge
Yes. Source code is on Bitbucket; it is the VIPM installers that are in the LAVA CR. One should also upload the installer to the files section of Bitbucket (though I often forget that). Source code should also be in an as early a LabVIEW version as reasonable (I use 2011), to maximize the number of people who can use it. -
You can also, BTW, take the property-node-in-array sections and put them in a subVI set to run in the UI thread. Running your VI in the UI thread reduced to “Grad” update time from 450 to 250ms (this is because property nodes run in the UI thread, and thread switching is part of the performance problem with property nodes).
-
All the cell color-formatting property node calls in the “Grad” event seems to be your main problem (takes 450ms on my computer). If you added a comparison and only updated changed cells you’d get much better performance.
-
New version posted in the CR. Includes a fix for empty objects.
-
Errors in initialization are passed back to the calling VI, with an error meaning that the actor failed to launch. This seems reasonable to me. And you can handle the error in “Pre Launch Init” if you prefer the actor to launch anyway (note that you can call “Handle Error” n “Pre Launch Init” if you want).
-
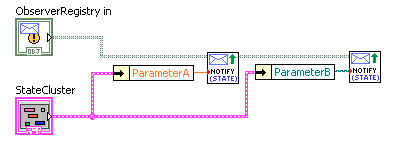
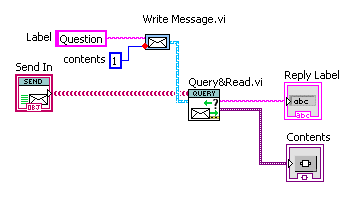
Yes, the main application of this feature is for publishing state information. I have a cluster already with meaningful names and can reuse those names as the message labels. Nice and clear. And I only have to name something in one place, rather than two. You can also use in other places where one is dealing in variants already. For example, the code below connects all controls on a Pane to a remote program via message. Any Value Change event on any control causes a message to be sent using the control name as label (one could use the control’s “Label.Text” property instead in this case, but at considerable property-node overhead). Drop a new control, label it the message label you need to send; job done, with no new coding required. I don’t feel it is worth it to introduce multiple versions, as I’m not likely to use this in 2011. A conditional disable structure was my first thought, until I found you can't currently disable based on LabVIEW version (kudoed your idea). That’s a good idea, though NI really should add a “LabVIEW version” condition (I don’t understand why there isn’t one already). I wouldn’t have agreed with you when the NI functions were 10 times slower than OpenG; but your right, they are getting improved.

-
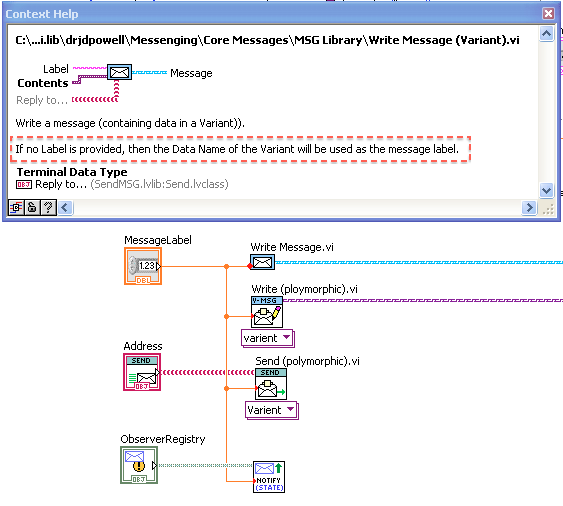
Hello, if anyone is using this package, what version of LabVIEW are you using? And in particular, are you using the feature where messages containing data in a Variant can optionally take the data name as the message label (as seen below)? I ask, because the (off-palette) NI “GetTypeInfo.vi" for determining data name is 10 times faster than OpenG’s “Get Data Name.vi" in LabVIEW 2013, but 10 times slower in 2011. As all my active projects are now in 2013, I am considering switching to using the NI VI (though I am staying with 2011 for package development).
-
XY-graph: programmatically add point "labels"
drjdpowell replied to machyaer's topic in User Interface
Green icons are OpenG toolkit functions. You can install OpenG with VIPM. I just used annotations yesterday to mark things on a graph, and reacquainted myself with their limitations. I think I’ll try your picture solution. -
Powerpoint slides from a presentation I gave at the European CLA Summit: CLA Summit 2014 SQLite.pptx
-
need help dipping my toe into Actor programming
drjdpowell replied to jcarmody's topic in Application Design & Architecture
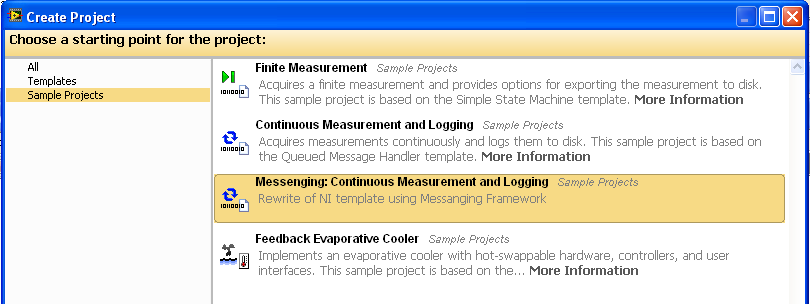
I have recently added a Sample Project to my “Messenging” package that reworks the NI standard sample “Continuous Measurement and Logging”. I didn’t do it to illustrate actors, per se, but perhaps the comparison will help. To me, the key point about “actors” is that they are parallel processes that only receive incoming information via a single communication point. No shared DVRs/FGVs/whatever. Actors are parallel processes, but with design restrictions, restrictions that are intended to make them more robust against the kind of bugs that can afflict multiple interacting parallel processes. -
If I were to spend some more time on probes, the next thing I might do is adapt my SQLite-backed logger to handle messages. That would give unlimited history with search functionality. My current probes do have variable history, but only to the extent of resizing the probe window (so not if you need quite a long history). I really should buildup the variant display to the level of Ton’s “Variant Probe”, but I find most “complicated data structures” in my code become objects, encapsulated against any probing. I also have a preference for small and simple probes, without a lot of controls that take up space or take time to configure, but a “pause” function does seem like a good idea. I have debated adding “trace” functionality into the “Send” function itself (and “Reply” and “Launch Actor”). Theoretically one could add lots of advanced features like tracing which message is in reply to which other message. But this would be a lot of work, and I shy away from loading down the basic framework (I would like the basic messages and messengers to be usable without the higher-level “actor” design). One can, as in this example, build up your own application trace window relatively easily, through having a message logging actor registered for all published information of your other processes. And, being custom, it can also be targeted; showing only a subset of the more significant messages. Thanks for the feedback. Have you considered posting your actor design as an example for others? — James
-
This sample project is now installed as part of version 1.2 of “Messenging”.
-
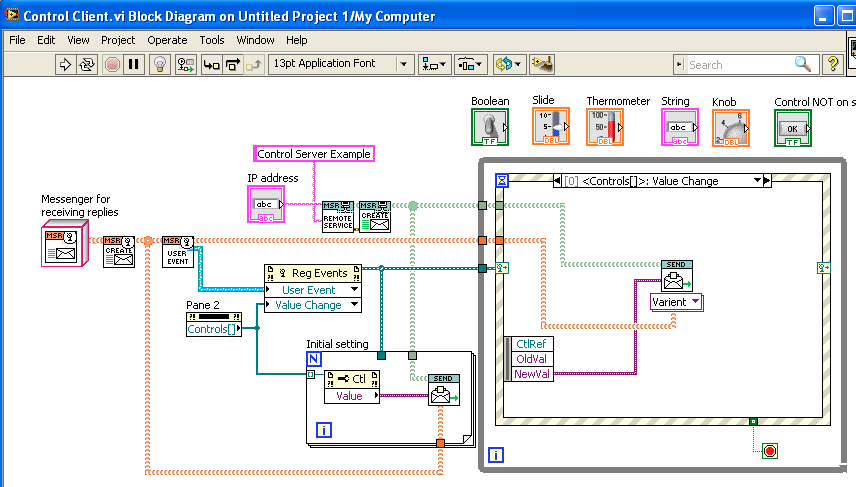
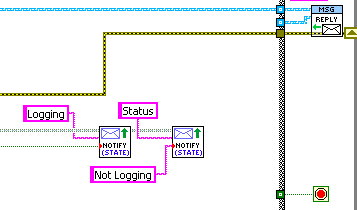
Version 1.2 has the following changes/additions: 1) A sample project that is a rework of an NI standard sample project, to illustrate the differences with using Messenging (original conversation): 2) New polymorphic VIs for writing messages and synchronous “queries” (send message and wait for reply). The new write VI is smaller and lacks error terminals. The new “Query&Read” VI allows immediate reading of the reply message. I deprecated the original “Query” polymorphic VI because of non-consistant error handling. When error messaged are “read”, they return the error cluster through the "error out” terminal; some of “Query”’s instances read the message, and some just returned the unread message. The most common use of “Query” I have found is to issue a command and wait to be sure it has completed without error, so it is desirable to consistently return the error cluster. 3) An internal change; the “ObserverRegister” publication system has been switched from an asynchronous helper actor to a synchronous DVR-based solution. This is to prevent messages sent by “notify” from arriving AFTER later messages sent by “reply” (because notifications goes via the helper actor while replies go direct to final recipient). For example, in the code below from the new sample project, the “Logging” and “Status” messages used to arrive after the “Reply” message.
-
Attached is Version 1.2 with all new features. I will add this to the CR in a few days if there are no objections. Please run this version with your projects to test for errors. lava_lib_json_api-1.2.0.22.vip
-
Could you save it in LabVIEW 2011 please.
-
I have added this to Bitbucket but I have not tested it much. Do you have a Test VI that we can add to the test suite?
-
Perhaps. But most types can be meaningfully converted. A SGL can be a DBL. The number 5.6 can be the string “5.6”. Even the string “Hello” can be returned as a valid DBL (NaN). But returning a Queue refnum as a User Event refnum is invalid. That may not be that important, since the invalid User Event will just throw an error when used,
-
The distinction between reference numbers and reference strings is unimportant; they are references. I’m not sure if it is valuable to include reference type information in the JSON serialization, but if we do, it would be best to do this a JSON Object, rather than special string formatting. Nothing in that case, other than type-checking and some human readability of the JSON. Same as the original encoding one. Why wouldn’t it be?
-
Sticking with the JSON spec, it might be better to encode LabVIEW refnums as JSON Objects: { "DAQmx Refnum": {ref:”SampleTask”, LVtype:”UserDefinedRefnumTag"}, "File Refnum": {ref:-16777216, LVtype:”ByteStream"}, } On converting back, we should throw and error on any type mismatch. This is rather verbose, but encoding refnums should be a rare use case, limited to “tokens” that are passed back to the original sending application where the refunms are valid.
-
Looks like it:
-
I have a fix and will post a VIPM package in a moment. The problem results from converting 8 and 16-bit types to 32-bit, and relying on the OpenG functions to down convert. This works, but when we have empty arrays, they are left as the default type, leading to arrays of variants that are mixed in bit length, which the OpenG function can’t handle. So I added explicate type-casts for the 8 and 16-bit integers. ... Here it is lava_lib_json_api-1.1.3.21.vip I have not fully tested, so this may not be the only issue; could you run your tests please? — James
-
Could you reattach with the control values saved as default?
-
If you attach a small project showing the problem, I can take a look at it.
-
I’m snowed under with work and about to go on holiday for two weeks, but people can check out the bitbucket repo and build the VI package to test it if they want (the VIPM build file is in the repo).
-
I have zero time to look at it at the moment, but it isn’t clear to me how one would use the 2013 JSON primitives dynamically. If I have static clusters defined it should be hopefully much faster, but what if I haven’t got static clusters? How do I take JSON configuration objects from several modules and combine them into a top-level JSON “config” object, without the top level code having the link-to and explicitly use the type-deffed clusters of all the modules?