drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
Version 1.4.9
617 downloads
A package for creating custom probes with "history"; showing the last N values rather than just the latest. Values are displayed in a cyclic table, which wraps around automatically when it reaches the bottom of the display window. Developed to support messaging systems, where messages can be handled too quickly for the eye to see with a last-value probe. Included are some standard probes, for strings, variants, objects, and some numerics. Also included is a "Text Variant" probe, for messaging using a cluster of such, and a "JKI State Queue" probe for use in designs using the JKI "state machine" template (see image). But the expected use case is for very easily creating custom probes for whatever messages one is using (just modify one of the included probes). Also includes "Quick Timer" probes to rapidly time execution of portions of code to accuracies of as low as 10 microseconds. Now hosted on the LabVIEW Tools Network. JDP Science Tools group on NI.com. Requires VIPM 2017 or later for install. -
View File Cyclic Table Probes A package for creating custom probes with "history"; showing the last N values rather than just the latest. Values are displayed in a cyclic table, which wraps around automatically when it reaches the bottom of the display window. Developed to support messaging systems, where messages can be handled too quickly for the eye to see with a last-value probe. Included are some standard probes, for strings, variants, objects, and some numerics. Also included is a "Text Variant" probe, for messaging using a cluster of such, and a "JKI State Queue" probe for use in designs using the JKI "state machine" template (see image). But the expected use case is for very easily creating custom probes for whatever messages one is using (just modify one of the included probes). Also includes "Quick Timer" probes to rapidly time execution of portions of code to accuracies of as low as 10 microseconds. Now hosted on the LabVIEW Tools Network. JDP Science Tools group on NI.com. Requires VIPM 2017 or later for install. Submitter drjdpowell Submitted 11/16/2013 Category Custom Probes LabVIEW Version 2013 License Type BSD (Most common)
-

Factory pattern: delete child class from memory
drjdpowell replied to OldBoy's topic in Object-Oriented Programming
Try adding a method to your child classes. That seems to make them stay under “Dependancies>>items in memory”. -
Anyone get a chance to test the new modifications on a system experiencing 1097 errors? I’ve encountered no issues with the new package, so I’ll release it to the CR soon.
-
What's your favorite book/tutorial on PID tuning?
drjdpowell replied to Stobber's topic in LAVA Lounge
I like to go a step further and try and represent things graphically. For temperature control I plot the "Proportional Band”, the range of temperatures where the heater output would be between zero and 100%, on the same graph as the process variable. Tuning is still by intuition, but with more visual information to go on. You can see the effects of the PID parameters in the twists of the proportional band. -
Your device likely only has one ADC, with a multiplexed input, that can do 200kS/sec in total on all channels, or 200/16=12.5 kS/sec on each of 16 channelschannel.
-
Actually, turns out the client was running XP when they had an error. But, my XP is running on a virtual machine under Parallels on a Macbook, so perhaps that changes the memory protection and is why I have never had this error in testing.
-
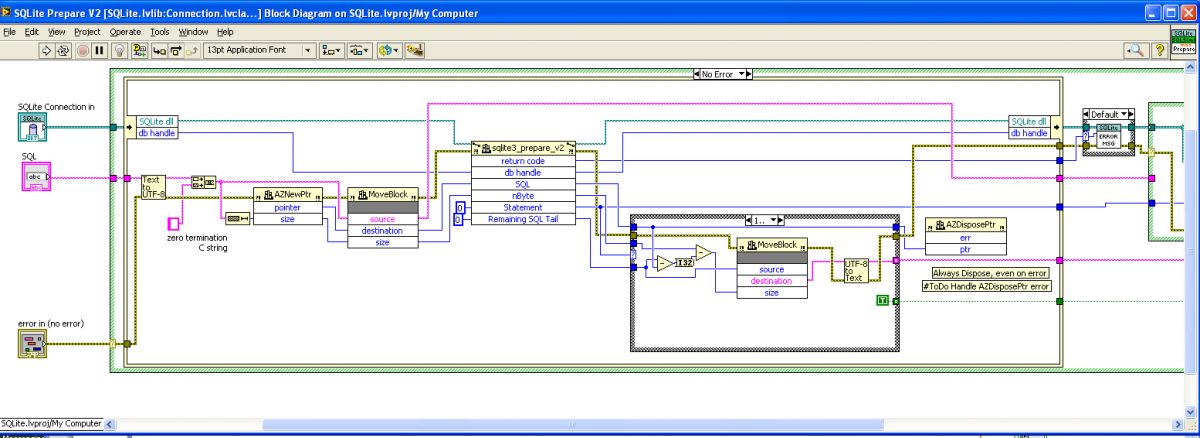
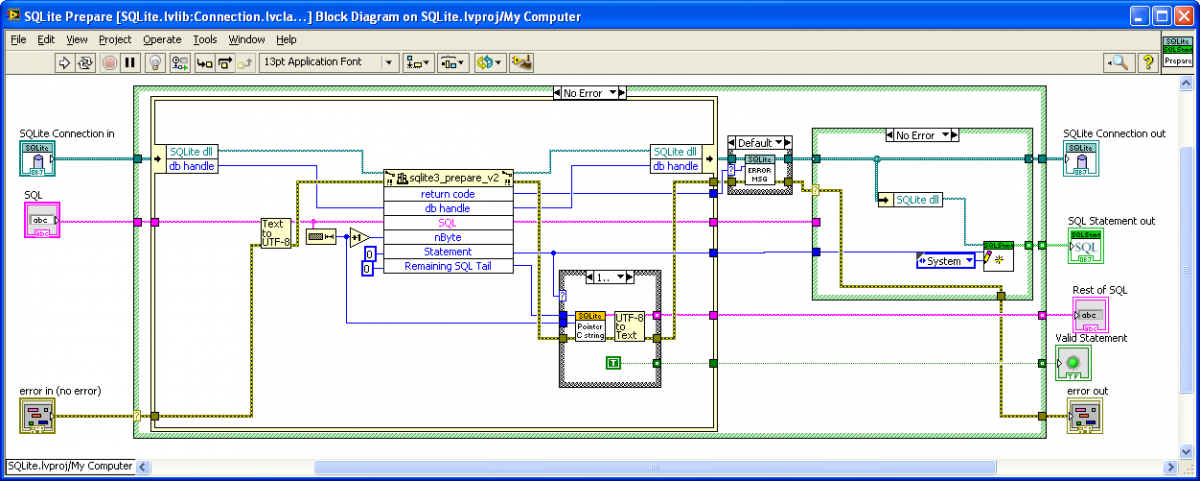
Attached is a new VIPM package (beta) with modifications to how “Prepare" works to avoid reading outside the allocated memory. I do not know if this will solve the problem, but as an added benefit the new method will give improved performance of “Execute SQL” for multiple SQL statements. Please give this a try and report if it eliminates the 1097 errors. drjdpowell_lib_sqlite_labview-1.2.0.28.vip
-
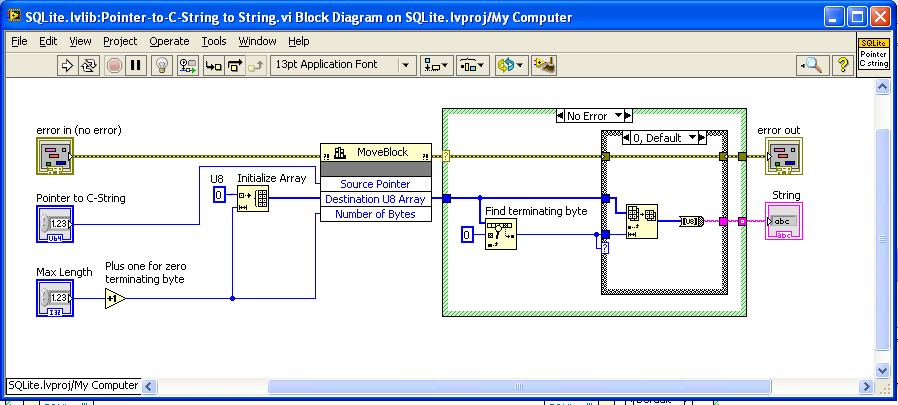
“Badly formed query”? Excuse me?!? Yes, that comment form is valid SQL. Beta version, seems to be working: Does the LabVIEW string to C string conversion explicitly, allowing the difference between the two pointers to be used to calculate the number of bytes of remaining SQL.

-
Well, this has just become a lot more relevant for me as a customer just emailed me this: First time I’ve seen it. I use Windows XP while the client uses Windows 7; I wonder if 7 is more unforgiving of “reading someone else’s memory”?
-
In this code I had the problem that the SQL statement is passed into the “prepare” dll function by pointer, but I don’t have access to that pointer, so I can’t calculate the length of the remaining part of the statement. So I instead copy the maximum amount, including any invalid junk off the end, and then walk the string till I hit the null terminating byte (done inside “pointer to C string”, where the junk bytes are discarded). Can “reading someone else’s memory” cause an exception? If so, I’m surprised I’ve never had this error myself. If someone can confirm this as the problem, then I can rewrite “Prepare” to convert the LabVIEW string to a pointer first, then do things by pointer.
-
I still cannot see what might be causing this error. You should defiantly have a shift register in your code, to guard against the case where the for loop is called zero times (is there any LabVIEW developer out there who didn’t learn this the hard way?). But I can’t see how this could cause the described error. Here is the code of the “Prepare” method: The error can only happen if: 1) sqlite3_prepare_v2 dll call runs without error. 2) “Statement” handle is returned greater than zero. 3) “Remaining SQL tail” pointer returns zero or invalid. I would expect most problems (invalid dll path, for example) to violate (1) or (2).
-
Do you use multiple levels of abstract classes? File.lvclass<— LVfile.lvclass<— VI.lvclass, for example? A HasBlockDiagram method would be defined in the LVfile class (default result FALSE) and would be overridden in VI.lvclass to return TRUE (but not overridden in LVLIB.lvclass).
-
Updating a middle element of a variant tree
drjdpowell replied to John Lokanis's topic in Application Design & Architecture
Funny, I use variant attributes for much the same thing, and asked about copies in this conversation. I also allow new subscribers to get a copy of the most recent message on subscription (though not always; I distinguish between “State” notifications (save the most recent message) and “Event” notifications (don’t save). I’ve long been meaning to improve the performance, but haven’t got round to it. -
Updating a middle element of a variant tree
drjdpowell replied to John Lokanis's topic in Application Design & Architecture
Another idea is to keep all data in a single flat structure such as an array, with the index to that structure stored in the variant tree. Lookup the index then index the array in place. Then at least all the copying will be of small integers. Or one could try a tree containing DVR references. But if we are taking very large data sizes then mje’s ultimate solution of a database might be best. I’ve even considered using in-memory SQLite databases in place of variants for small data structures, just to have the increased flexibility of SQL, but the performance is significantly worse than variants when the data size is small. -
Updating a middle element of a variant tree
drjdpowell replied to John Lokanis's topic in Application Design & Architecture
LVOOP objects are just a (nice) wrapper; you still need an underlying storage method. -
Updating a middle element of a variant tree
drjdpowell replied to John Lokanis's topic in Application Design & Architecture
Oh yeah, duh. I’m working too hard. Liking my original suggestion better. -
Updating a middle element of a variant tree
drjdpowell replied to John Lokanis's topic in Application Design & Architecture
I’m confused because I couldn’t get the IPE to work with a variant for the type input (LabVIEW 2011); I have to supply the actual type (which limits its applicability). Using a variant only works on variants inside variants (did you unknowingly do that? would reduce performance). BTW, the first “Get Attribute” that is copying an entire branch of your tree, so that’s also needs to be inplace (if you can get that solution to work). -
Updating a middle element of a variant tree
drjdpowell replied to John Lokanis's topic in Application Design & Architecture
I believe attributes come out ordered, so name your content attribute a single zero byte (Hex 00) and it will always be the first element (which can be skipped at minimal cost with an array subset). -
Updating a middle element of a variant tree
drjdpowell replied to John Lokanis's topic in Application Design & Architecture
Another thing to look into is the In-Place Structure’s Variant To/From Element structure, which does preserve attributes. But I think it allows one to change the type of the Element. -
Updating a middle element of a variant tree
drjdpowell replied to John Lokanis's topic in Application Design & Architecture
Make sure you’ve kudoed "In Place Element Structure Support for Variant Attributes”. It’s the copy at the first “Get Attribute” that is killing you. One way around this is to not use the actual value of your storage variants at all; instead keep the "content" of that tree node as a “NodeContent” attribute. Then your above code becomes just a “Set Attribute”. -
Reference casting dance sanity check
drjdpowell replied to todd's topic in Application Design & Architecture
Seems to work, at least in LabVIEW 2012. -
Dataflow outputs and ParameterDirectionKind
drjdpowell replied to PaulL's topic in Object-Oriented Programming
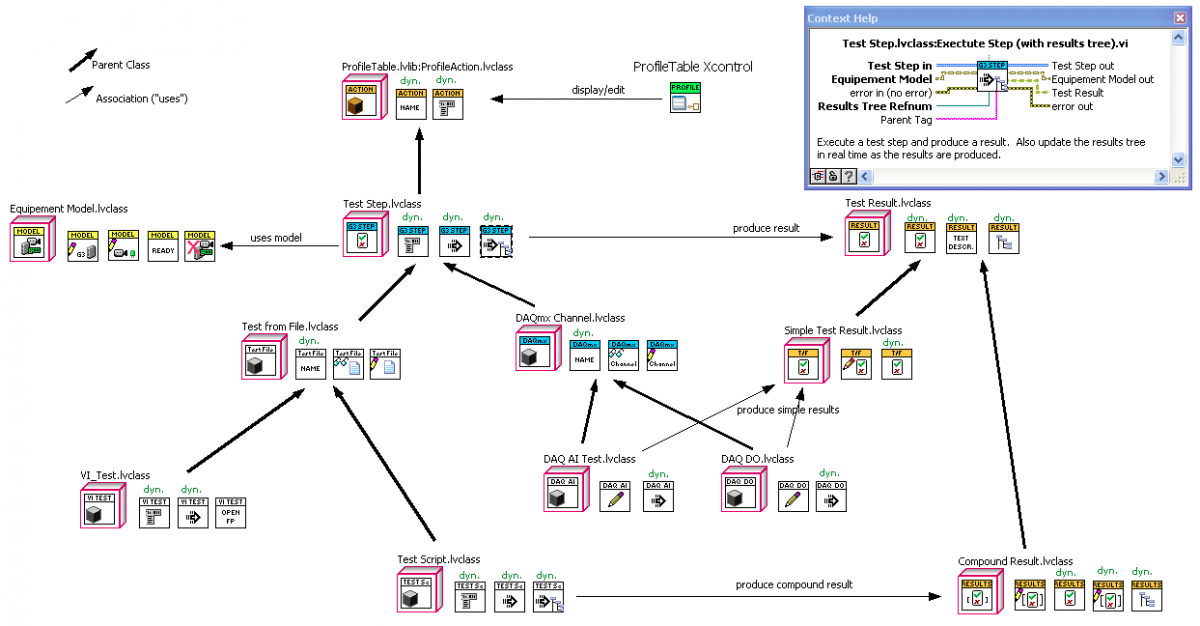
An experiment in crude pseudo-UML using the IDE (for a selection of classes, and subset of methods, in my current project):
-
Dataflow outputs and ParameterDirectionKind
drjdpowell replied to PaulL's topic in Object-Oriented Programming
I have not. I should have a look -
Dataflow outputs and ParameterDirectionKind
drjdpowell replied to PaulL's topic in Object-Oriented Programming
Oh, I didn’t mean to cast doubt on the use of modeling; just noting the handicaps of using tools designed for languages with an X=F(A,B,..) syntax. It would be very nice if there where a UML tool that could interface with LabVIEW to present a class with all the methods as icons, with ctl-H bringing up the standard window showing terminals and descriptions. Modeling before coding might be slower, as you’d had to create shell VIs with terminals and rough-draft icons, but at least this will save you time when it comes to actually coding. And in return you get a much clearer visual diagram.