Darin
-
Posts
282 -
Joined
-
Last visited
-
Days Won
37
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Darin
-
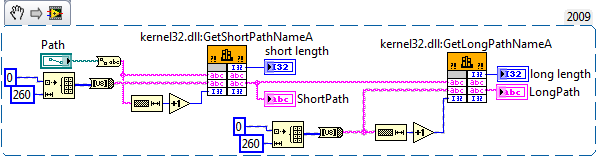
Assuming you meant GetLongPath. TestShortPathLongPath.vi

-
Absolute time display on xy graph - not enough info displayed
Darin replied to edk's topic in LabVIEW General
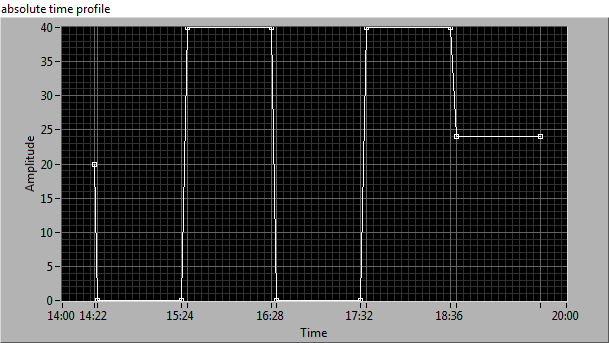
By coercing the Timestamp array to a DBL array and writing it to the X Axis MarkerVals[] property I could certainly get more than three points to show up on the axis:
-
For better or for worse (separate discussion), LV has no notion of a 'char', only strings or byte arrays. The selector has to be interpreted as a string, and therefore one of the limits must not be inclusive (upper one makes slightly more sense). Otherwise you would sometimes need to write the "biggest" string which starts with b, is it bzzz or bzzzz or bzzzzz.... This is also what currently precludes floats from the selector. I wish we could specify the inclusiveness of either bound using standard '[' versus '(' conventions. You could then write ["a".."c"] or ["a".."c") or ("a".."c"]. This would also allow floats to be used which would be very cool IMO, you could have NaN, +Inf, -Inf, [0..3), [3..6), cases.
-
Absolute time display on xy graph - not enough info displayed
Darin replied to edk's topic in LabVIEW General
Have you looked at the Display Format for the X-axis (Right-Click->Properties)? You can set the format of the time and date, I usually choose System Time and System Date formats. Your picture looks like it is set to 'Date Unused'. Is this what you mean by 'incomplete'? -
Just slap an 'Always Copy' node after the constant in the second case and it is all good (LV10). They should probably change the icon of that function to a band-aid. (Of course the number of places you need this is supposedly declining, but it is still good to know for those of us stuck with old versions).
-
How to call user32.dll:GetWindowRect? (and why I need to)
Darin replied to MartinMcD's topic in LabVIEW General
I would recommend downloading the examples from this page: https://decibel.ni.com/content/docs/DOC-2030 Inside the WINUTIL.LLB you will find the VIs you need to get the window handle and the window rect. -
The argument against Riffle is that it is not in the base package. That is why I considered alternatives. The fastest way if you want to use Riffle.vi is to live with the coercions and Riffle the byte array from the string directly. It would be nice if NI would provide a U8 instance of Riffle.vi. (Wow, I got to say Riffle four times (now five)).
-
I like how you posted that on a day where the month and day are degenerate.
-
Consider when the local variable is read and comparison is made.
-
The Keyed Sort is quite a slow way to perform the shuffle operation. The built-in riffle function is the fastest way. My next choice would have been the following: http://forums.ni.com...light/true#M462 Unfortunately, that creature has been returned to its cage. That leaves me with performing the good, old Fisher-Yates-Knuth shuffle, and I would probably just use the byte array instead of the char array. The section where I find a random integer between i and N-1 could certainly be replaced with the new OpenG function. Probably a modest hit in performance. The section labelled 'Knuth Shuffle' can be adapted very easily to any datatype. KnuthShuffleString.vi
-
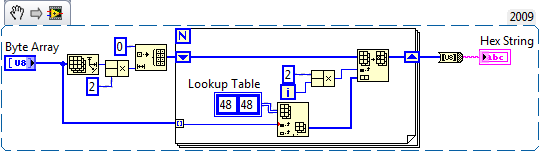
I like the direction Matt was headed, but I tend to find Case Structures a bit slow in tight loops so I would probably have done something like this instead. Over 4x faster than the built-in primitive (not often we can do that!). I suggest a new set of OpenG VIs to implement Integer Array to Hex String. I would simply use Split Number and the same lookup table for U16 and U32, etc.
-
Rewrote from scratch in LV9 (used native timing instead of OpenG). Array version now beats For Loop consistently by a healthy 20-50% margin. All is right with my world again, other than the annoying red dot. Same in LV10. Slightly puzzled by the initial results matching Ton's, I'll chalk it up to bad luck. I do not know if it matters here or not, but I tend to avoid wiring indicators inside a frame I am trying to benchmark.
-
Very interesting results from some quick testing. The first time I run the test the Array method is as fast or faster than the for loop. For all subsequent tests the For Loop is much faster (10X). Ctrl-Run then the array wins the first race again.
-
I seem to remember that Floats are coerced to 64 bit integers, so I am guessing that the default input type is U64 for arrays. It seems silly to not have an explicit [u8] input for the primitive instead of blowing up [u8] to [u64]. I am curious if you could check the performance with different integer array types and find one with a smaller time differential between the two methods. A very useful rule-of-thumb for optimization is that the more code you push into a primitive, the faster it will be. This bug(?) breaks that rule so it is very annoying on many levels.
-
closed review String To Character Array (String Package)
Darin replied to Wouter's topic in OpenG Developers
Just so we are all on the same page, the change is not as small as advertised (not that it is that big a deal). The number of iterations must be calculated, handling the case where the data size is not commensurate with the chunk size (padding or clipping). The offset must be multiplied by the chunk size as well. These changes add significant overhead to the single char case, too much to justify a simple change IMO. You could add a comparison and handle the single char case separately. A Chunking tool would be useful but it should be polymorphic IMO. Certainly a candidate for an XNode, but my philosophy is that XNodes are fun to play with, but they have a lot of baggage when it comes to distributing them. Someday NI may allow us to place one at the top level in a Packed Project Library (that would be sweet) so we could distribute them as a single file. I would suggest a simple polymorphic VI that handles the usual suspects (strings, ints, floats, booleans). I lean against bloating this one. I was already less enthused about it once I determined that the obvious method was also the most efficient. -
I would try out SketchBook Express and if you really like it the pro version is not so expensive.
-
Considering the alternatives, yes. I would be very tempted to make that connection optional. Well then try not to let that happen again. Upon closer inspection I see you use Match Pattern now, I saw the word Regex thrown around which to me means PCRE (Perl compatible..). The '$' character means different things between the two functions, with MP it should be fine.
-
The Strict Case? input looks fine to my eye, although it appears to be required now. Clearly you are not digging too deeply into what makes a valid MD5 hash, but the current version will allow mixed cases with Strict Case = False. I do not see myself using a function like this, so I will merely point this out without further comment. jgcode, on 19 September 2011 - 06:30 AM, said: Even if it was string in / string out if you check the first three String functions (top row) they don't match (offset vertically). Just because NI f'ed up bad with those functions does not mean we have to.
-
closed review String To Character Array (String Package)
Darin replied to Wouter's topic in OpenG Developers
Don't say I didn't tell you a way to make it faster. Personally I would not use subroutine priority in either case, I typically am satisfied with disabling debugging. I do however benchmark code using that setting, I found it to be the fairest and most consistent comparison. In completed code, I almost always find myself wanting to run subVIs standalone at some point. -
closed review String To Character Array (String Package)
Darin replied to Wouter's topic in OpenG Developers
I use the benchmarking code provided in the Trim Whitespace thread. So I found that the fastest times for String Subset are roughly 3x (2.6 once I made both subroutine priority) faster than the fastest Byte Array times. -
closed review String To Character Array (String Package)
Darin replied to Wouter's topic in OpenG Developers
I have also been told that fools seldom differ. -
closed review String To Character Array (String Package)
Darin replied to Wouter's topic in OpenG Developers
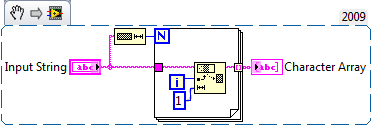
Simple String Subset is almost 3X faster in this case. Subroutine priority makes it slightly faster as well. To Character Array_DK.vi
-
I used to use Riffle for this, but now I sometimes look for excuses to use the following since it is so darned cool: http://forums.ni.com/t5/LabVIEW-Developers-Feature/Now-available-for-download-quot-Randomize-1D-Array-vi-quot-that/m-p/1159329/highlight/true#M462 Can't help but feel like NI is taunting us though...
-
I once benchmarked a variety of VIs to implement the simple Array Max/Min. Obviously the built-in function reigns supreme (otherwise somebody is not doing their job). G equivalents were about 50%-200% slower than the native function depending on the sophistication of the algorithm. An implementation with native recursion was about 30 times slower than the primitive, the VI server equivalent was about 30 times slower than native recursion (when it worked) and crashed for arrays larger than 1000 elements. My own opinion is that the beauty, simplicity and overall coolness justifies [native] recursion in many instances. Especially true for many parsing applications since it seamlessly handles nesting and very few instances require more than a few layers. VI Server recursion should not be used, ever. What you gain in readability by going to recursion is instantly lost, so you are usually much better off implementing the iterative solution.
-
The check is really simple, after you make the selection use the SelectionList[] property of the TopLvlDiag. Use a For Loop to compare each object to the Wire reference (Equals? is very handy when dealing with refs). If it is not equal, use the Remove From Selection Method (TopLvlDiag). If you are nudging a wire you can sometimes get away with selecting the entire wire, but it can be handy to move a single bend around.