

Rolf Kalbermatter
-
Posts
3,909 -
Joined
-
Last visited
-
Days Won
270
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Rolf Kalbermatter
-
-
19 minutes ago, ShaunR said:
Just buying the shares isn't good enough. They have to first get the shareholders to revoke the trigger for dividends and that would probably take the agreement of more than one or two other major shareholders.
I'm fully aware of that. It just means that this could be an additional hurdle for them to take, not that it is the only one.
In terms of LabVIEW, what I think would happen, if they are successful is the same as has happened for HiQ, Lookout, Electronic Workbench/Ultiboard and a few others when NI took them over. They hailed the purchase as a great addition to their product portfolio, took out some of the IP to integrate in their own and then let it die. Trying to interface Emerson products with LabVIEW in the past simply gave you a blank stare from the Emerson people and the question: "Why would you want to do that when we have such nice software ourselves!"
-
43 minutes ago, X___ said:
They are trying their best to snap NI at a bargain price, knowing full well that the picture will completely change when LabVIEW 2023 Q4 will be released, instantly doubling the value of NI share price.
I assume you were looking for the ironic icon and couldn't find it? 🤑
-
41 minutes ago, ShaunR said:
And there we have it! They couldn't get them to sell, they tried maneuvering for a takeover (which was thwarted) and now all they can do is appeal to the shareholders.
Yep. But a very significant amount of shares (if not even a fully controlling amount) was at least until a few years held by the three founders and in the form of trusts through family members. So it will probably come down to the question if any of the heirs feels enough to sell their share to Emerson for some quick cash or not.
-
10 minutes ago, Neon_Light said:
One part which is outdated of the external code document is how to set up the environment in the IDE. At this time I am using VSC, as a IDE. Do you have a link to a VSC setup to develop a DLL for Labview?
The principle is still very much the same. The only thing that won't match are possible screen shots and maybe the naming is not always the same. DLL development was implemented with Windows 3.0 and has only changed VERY little over time. IDE settings may have changed somewhat more but it is not really feasible to make a new document for every new Visual Studio version. (And Visual Studio Code, and Intel C, and Bloodshed's DevC++, Watcom C++, Gnu C++, etc, etc).
-
14 minutes ago, jacobson said:
I mean stock perfectly reflect the underlying value of the company right?
It seems like $53 is a premium my any measurement but they do conveniently hide that when they offered $48 per share it was below the 12-month price target for NATI (pretty sure I have my timelines right).
And it of course shot to over 54 $ this morning to now settle around the Emerson bid price 🙂, while Emerson lost 5%. Of course that is speculation and market overreaction by trigger happy stock market cowboys.
-
9 minutes ago, jacobson said:
https://www.emerson.com/en-us/news/2023/emerson-national-instruments-announcement
Although all of this is through the lens of the group that wants to purchase NI so it's not surprising they don't think NI is being reasonable (though that may be true).
Well, they make it sound like it is a very bad decision not to want to sell to them, almost criminal. I always thought in a free market there wasn't any obligation to sell something to an interested party even if they offer a premium (which I'm not really sure they did). But they make it sound like that doesn't apply here. 😁
-
16 hours ago, Neon_Light said:
Well the header file I mention is from the wrapper someone else wrote. I have got some functions working from this wrapper. The only part I havent managed to get working is the part with the callback. So what you are saying I need a wrapper to use this wrapper because it uses a callback function? I will read the example you did provide thank you!
Do you have the source code of that wrapper? If so you can modify it, otherwise you will have to create a wrapper around this wrapper or around the original lower level API.
Or maybe that wrapper implements this callback functionality and the lower level API is simply a function API where the caller has to implement its own task handling. In that case it may be simpler to directly go to this lower level API and implement the parallel task doing the logging monitoring entirely in LabVIEW.
-
15 minutes ago, ShaunR said:
No that much of a surprise. Emerson have been eyeing NI for a long time. Here's something from 2015...
That was actually my first name I came up with when reading that press release from NI.
About the dilution of shares, it was exactly my understanding that this is to fight against a hostile takeover. But the rest of the press release does not sound like they are trying to fight to be taken over, rather the opposite, and that felt kind of contradictive.
-
2 hours ago, ShaunR said:
Interesting...
It's not the usual option for selling a company. You don't dilute your shares if you are going to sell. You normally do this sort of thing either if cashflow is a problem or you are facing a hostile takeover.
That were my thoughts too, but I read it on Yahoo. And while they don't usually tell total bullshit like some other news sources, their reporting is usually not very accurate.
-
14 hours ago, gleichman said:
Good news if you own NI stock. Not sure about customers.
I own some. But it has even in promilles of the outstanding stock way to many zeros after the decimal point. 😀
I didn't get them to get rich but because I believed at that time in the company to have good products and moral.
Who could want to buy them? No idea really, technically Keysight might be an option, politically I doubt that would work.
It's more likely that it is going to be either a hedge funds of some sort or one of those huge nameless engineering service conglomerates that nobody knows but everybody uses various things from but they are sold under a different name.
It's unlikely that any of those options cares about the products that NI made or the software portfolio. It's purely financial, buy theoretical market share, port as many customers as possible over to your own products and then close the operations.
And it is certainly not an overnight decision. That has been planned for quite some time, and really put in motion even before the last original founder retired.
I'm not sad that LabVIEW NXG was canceled, but the reason why it actually was, are in hindsight also very sad.
-
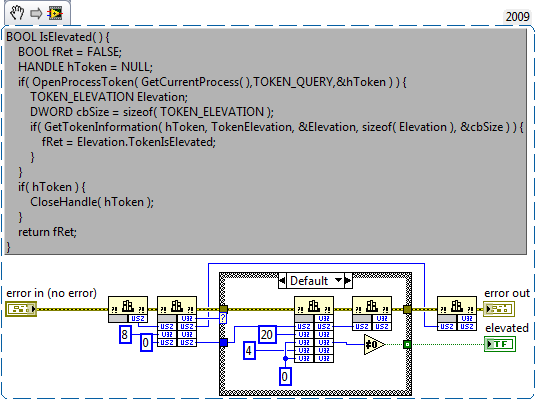
There is potentially a mixup somewhere with namings. It's a long long time ago that I looked at this and I'm not sure about the exact format of a PICC at this time. LabVIEW also has something that it calls pixmaps (and is in fact the Picture Control data format which has opcodes and parameters as can be seen when looking at the Picture Control VIs). It may technically not be the same as the PICC resource format, but I'm really not sure at this point and don't feel like doing that sort of archeology at this moment. There are in fact several different formats in LabVIEW for graphics. Some are LabVIEW native, some are bridges to platform specific formats. Some are pixel based and others are more vector based.
And if I had access to the source code of LabVIEW I would first fix some annoying bugs and shortcomings before looking at that sort of things.
-
1 hour ago, RomainP said:
OK, thank you. Please keep us informed.
I worked some on this over the holidays and made some more progress. Still quite a bit of cleanup to do, the underlaying code in the shared library was a bit a work in progress in several phases and there was some code duplication and inconsistencies. But I'm slowly getting there.
-
 1
1
-
-
1 hour ago, Antoine Chalons said:
i have ubuntu 20.04 and
I don't have gcc installed, is it required?i have gcc 9.4.0, shall i upgrade?
gcc should only be required if you intend to recompile the shared library yourself. However glibc compatibility between different compiler versions always is a pitta. Usually compiling with the oldest version you expect to be used is best.
-
16 minutes ago, Antoine Chalons said:
I can't get it to work on Ubuntu with LV 2020 SP1
LabVIEW won't accept the so file and keep asking me to point to the file.
I've already seen some weird behaviors with CLFN on Linux when feeding the library path on the diagram but if the case of your 64 so file, even if I create a new VI, place a new CLFN and try to link to libmuparser-x64-lv.so LabVIEW then prompts me to find 'libmuparser-x64-lv.so'
That means that your system misses some dependencies. To solve this we would need to have a list of possible dependencies and their version that this library may have. Aside from obvious dependencies that should be apparent to anyone having compiled this library you would also want to know the system and gcc version on which it was compiled. Depending on that there might be various other dependencies that your Ubuntu system may or may not come preinstalled with in the correct version.
-
On 12/20/2022 at 9:02 AM, codcoder said:
Thanks for your answer!
So the hiding of community scoped vi's in LabVIEW is cosmetic only?
I guess it makes sense that a VI that must be accessible from something outside the library, let that be the end user through LabVIEW/TestStand or another library, will be treated diferently.
But I still think it's bad ux that TestStand doesn't hide the community scoped vi's like LabVIEW does.
It's guessing but I could imagine that there is actually a situation possible where the Test Stand Editor doesn't know about the Friendship of objects but the user may want to select a Community scoped class anyhow. If that class is then executed in a context that has friendship relationship it still succeeds. Otherwise it gives a failure.
Bad UX maybe. A feature that makes things possible that should be possible, quite likely. Fixing that may require to teach TestStand about LabVIEW implementation specific details and present its test adapters in a way that forces dependencies into the TestStand paradigma that it doesn't really care about otherwise. Likely weeks or months of extra work and a brittle interface that can fall flat on its nose anytime LabVIEW makes subtle changes to something in these implementation specific private features. Much safer to leave this inconsistency in there, save time, sweat and money and call it a day.
-
1
-
-
50 minutes ago, Porter said:
I have updated to muParser version 2.3.4.
Is anyone willing to give it a test on LV Linux 32-bit and 64-bit?
Here is the latest code: https://github.com/rfporter/LV-muParser/releases/tag/V2.1.0
The 32-bit version may be difficult to test. 2016 was the last version that had a 32-bit version of LabVIEW both on Mac and Linux. After that it was 64-bit only. Not sure how many people still have a 2015 or 2016 installation of those.
-
 1
1
-
-
-
9 hours ago, Thomas Granito said:
Hello, I wanted to ask if it is possible to extract all rows from a 2d array for example of size 10x6. If so, how can it be done? Thank you
I'm not sure what you want to do. All rows from a 2D array would sound like the whole 2D array to be. When you mean a particular column that contains values for every row, just check out the Index Array function. If you connect a 2D array to its input it will expand to have one index and one size input per dimension. Connect the index value you want to have for either a particular row or column to extract and leave the rest unconnected.
-
2 hours ago, CIPLEO said:
Hello,
I would like to know if it is possible to launch an executable via a VI and if it is possible to launch it as an administrator ? Or if it is possible that the VIPM launches my VI as an adminitrator after the installation of a packet ?
Thank you for your answer
No you can't launch VIs as administrator. You need to launch LabVIEW (or VIPM) as such in order to have a VI executed with administrator rights. Windows does not allow to change the privilege of a process after it is launched, respectively if you find a way to do that you found a zero day hacker exploit, that will be closed immediately as soon as Microsoft learns about it.
What you could do is to add an executable that was configured to need administrator rights through a manifest file to the installation package and then launch that. It will cause a privilege escalation dialog when you launch that, and require the user to enter the login credentials for an admin if he isn't already admin. The dialog will appear anyhow even if he is an admin already, but as admin the user won't have to enter the password again, but still confirm that he does want to have that executable launched.
-
On 12/8/2022 at 11:37 PM, rharmon@sandia.gov said:
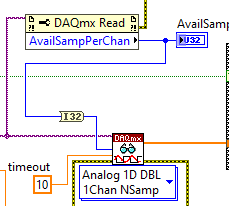
I've returned to continuous samples, I set my rate to 100000 and samples per channel to 1000 and on my DAQmx Read.vi I've hard-wired Number of Samples Per Channel = 10000 (1/10th of my rate) when I interject my own 90 usec pulse I catch every pulse.
But I'm worried, the only difference from my old setup which could run for months before getting a buffer overflow error is the hard-wired Number of Samples Per Channel = 10000.
In the past I used the DAQmx Read Property Node to check Available Samples Per Channel and would read that value instead of the now hard-wired value.

Does my current setup sound appropriate to catch the random 90 usec pulses?
Rate = 100000
Samples per Channel = 1000
Hard-wired into the DAQmx Read.vi Number of Samples Per Channel = 10000 (1/10th of my rate)
Thanks,
BobWhile your previous approach might pose problems depending on what you intend to do with the data, as the number of read samples can be very variable, your current approach sounds honestly corner case. What do you mean samples per channel being 1000? Is that at the Create Task? This would be the hint for DAQmx about how much buffer to allocate and should be actually higher than the number of samples you want to read per iteration. My experience is that one read per 10 ms is not safe under Windows, but 1 read per 100 to 200 ms can sustain operation for a long time if you make the internal buffer big enough (I usually make it at least 5 times the intended number of read samples per interval).
-
1 hour ago, mcduff said:
I have not looked at the other sources on the GitHub page; not sure if the source code for the DLL is included on that site or not. I have only downloaded the DLLs.
It is not! All the language interfaces they have on that page are simply wrappers around the DLL. Some more complete than others. The C# one seems to import all the functions (well at least a lot), the LabVIEW wrapper is extremely minimalistic.
-
1
-
-
3 hours ago, ShaunR said:
Yup. this works too.
That loop looks nice, but I prefer to use Initialize Array. 😀
But I'm pretty sure the generated code is in both cases pretty similar in performance. 😁
-
2 hours ago, ShaunR said:
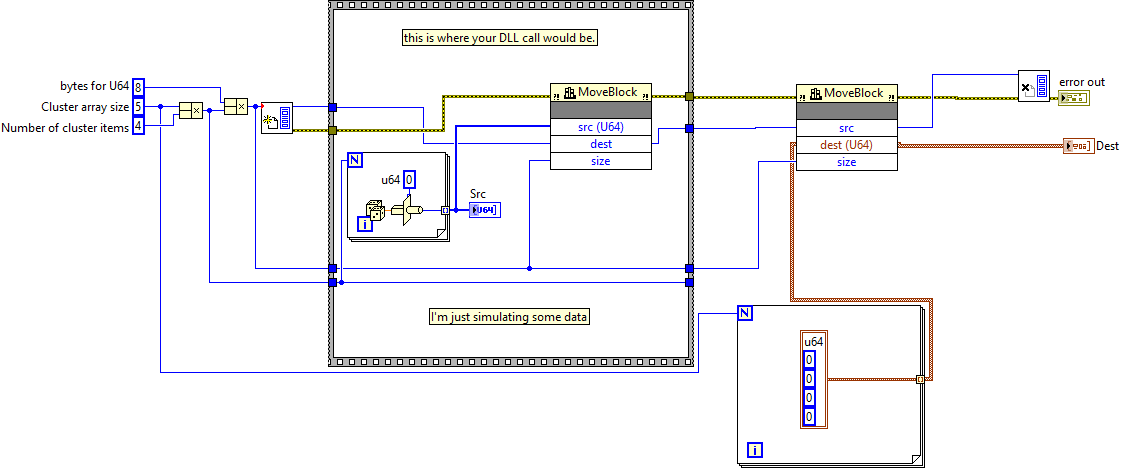
Yes. But he will be populating the array data inside the DLL so if he mem copies u64's into the array it's likely little endian (on Intel). When we Moveblock out, the bytes may need manipulation to get them into big endian for the type cast. Ideally, the DLL should handle the endianess internally so that we don't have to manipulate in LabVIEW. If I'm wrong on this then that's a bonus.
No! The DLL also operates on native memory just as LabVEW itself does. There is no Endianness disparity between the two. Only when you start to work with flattened data (with the LabVIEW Typecast, but not a C typecast) do you have to worry about the LabVIEW Big Endian preferred format. The issue is in the LabVIEW Typecast specifically (and in the old flatten functions that did not let you choose the Endianness). LabVIEW started on Big Endian platforms and hence the flatten format is Big Endian. That is needed so LabVIEW can read and write flattened binary data independent of the platform it works on. All flattened data is Endian de-normalized on importing, which means it is changed to whatever Endianness the current platform has so that LabVIEW can work on the data in memory without having to worry about the original byte order. And it is normalized on exporting the data to a flattened format. But all the numbers that you have on your diagram are always in the native format for that platform! Your assumption that LabVIEW somehow always operates in Big Endian format would be a performance nightmare as it would need to convert every numeric data every time it wants to do some arithmetic or similar on it. That would really suck great time! Instead it defines an external flattened format for data (which happens to be Big Endian) and only does the swapping whenever that data crosses the boundary of the currently operating system. That means when streaming data over some byte channel, be it file IO, or network or a memory byte stream.
And yes, when writing a VI to disk (or streaming it over the network to download it to a real-time system for instance), all numeric data in it is in fact normalized to Big Endian, but when loading it into memory everything is reversed to whatever endianness format is appropriate for the current platform.
And even if you use Typecast it only will swap elements if the element size on the input side doesn't match the element size on the output. For instance Byte Array (or String, which unfortunately still is just a syntactic sugar to a Byte Array) to something else. Try a Typecast from an (u)int32 to a single precision float. LabVIEW won't swap bytes since the element size on both sides is the same! That even applies to arrays of (u)int32 to array of single precision (or between (u)int64 and double precision floats). Yes it may seem unintuitive when there is swapping or not but it is actually very sane and logical.
QuoteI think this can also be done directly by Moveblock using the Adapt to Type (for a CLFN) instead of the type cast but I think you'd need to guarantee the big endian and using a for loop to create the cluster array (speed?).
Indeed, and no there is no problem about Endianness here at al. The only thing you need to make sure is that the array of clusters is pre-allocated to the size needed to copy the elements into and that you have in fact three different size elements here:
1) the size of the uint64 array, lets call it n
2) the size of the cluster array, which must be at least n + (e - 1) / e, with e being the number of u64 elements in the cluster
3) the size of bytes to copy which will be n * 8
-
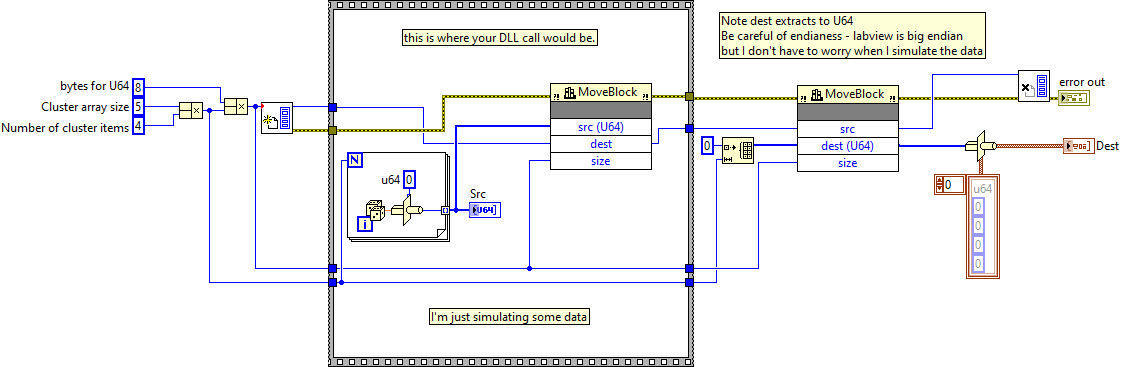
2 hours ago, ShaunR said:
You can forget about that comment about endianess. MoveBlock is not endianess aware and operates directly on native memory. Only if you incorporate the LabVIEW Typecast do you have to consider the LabVIEW Big Endian preference. For the Flatten and Unflatten you can nowadays choose what Endianess LabVIEW should use and the same applies for the Binary File IO. TCP used to have an unrealeased FlexTCP interface that worked like the Binary File IO but they never released that, most likely figuring that using the Flatten and Unflatten together with TCP Read and Write does actually the same.
PS: A little nitpick here: The size parameter for MoveBlock is defined to be size_t. This is a 32-bit unsigned integer on 32-bit LabVIEW and a 64-bit unsigned integer on 64-bit LabVIEW.
-
1
-
Including solicitation of interest from potential acquirers
in LAVA Lounge
Posted
https://www.emerson.com/en-us/automation/automation-and-control